 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Paradox of Choice: Using Attention in Hierarchical Reinforcement Learning
Jan 24, 2022
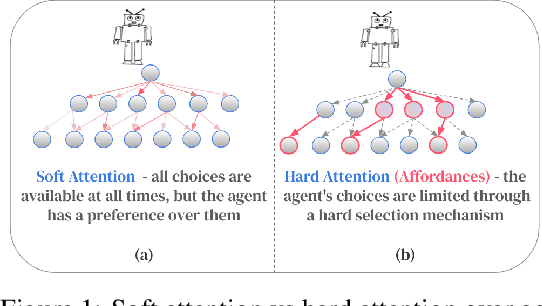
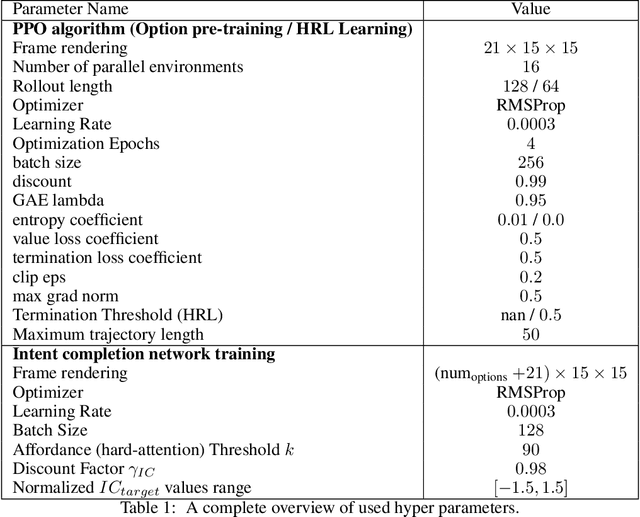
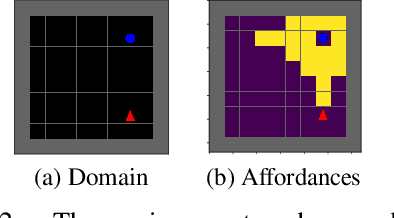
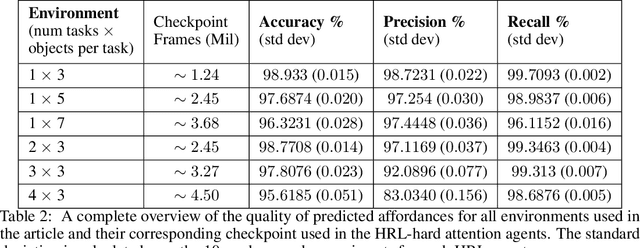
Decision-making AI agents are often faced with two important challenges: the depth of the planning horizon, and the branching factor due to having many choices. Hierarchical reinforcement learning methods aim to solve the first problem, by providing shortcuts that skip over multiple time steps. To cope with the breadth, it is desirable to restrict the agent's attention at each step to a reasonable number of possible choices. The concept of affordances (Gibson, 1977) suggests that only certain actions are feasible in certain states. In this work, we model "affordances" through an attention mechanism that limits the available choices of temporally extended options. We present an online, model-free algorithm to learn affordances that can be used to further learn subgoal options. We investigate the role of hard versus soft attention in training data collection, abstract value learning in long-horizon tasks, and handling a growing number of choices. We identify and empirically illustrate the settings in which the paradox of choice arises, i.e. when having fewer but more meaningful choices improves the learning speed and performance of a reinforcement learning agent.
Merging Subject Matter Expertise and Deep Convolutional Neural Network for State-Based Online Machine-Part Interaction Classification
Dec 08, 2021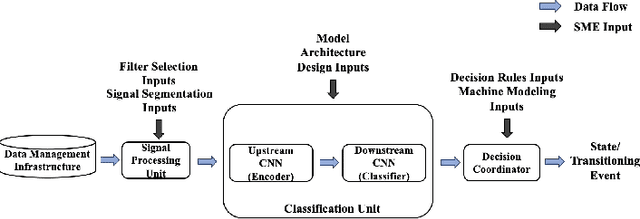
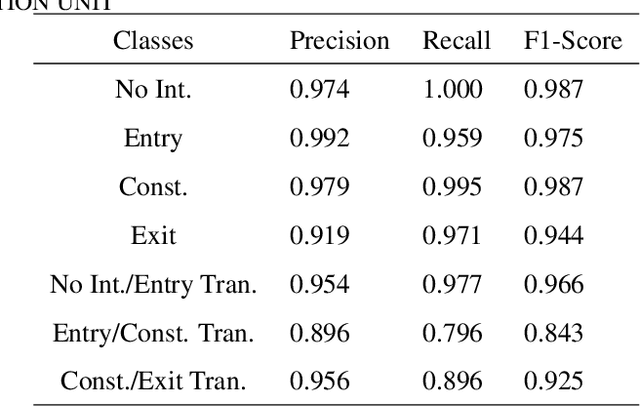
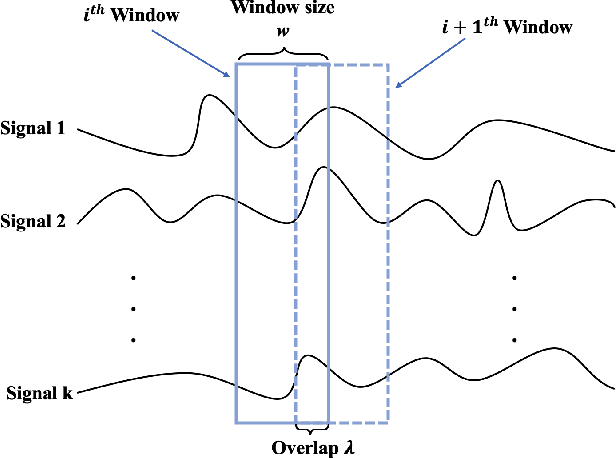
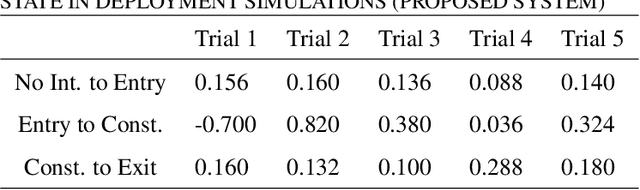
Machine-part interaction classification is a key capability required by Cyber-Physical Systems (CPS), a pivotal enabler of Smart Manufacturing (SM). While previous relevant studies on the subject have primarily focused on time series classification, change point detection is equally important because it provides temporal information on changes in behavior of the machine. In this work, we address point detection and time series classification for machine-part interactions with a deep Convolutional Neural Network (CNN) based framework. The CNN in this framework utilizes a two-stage encoder-classifier structure for efficient feature representation and convenient deployment customization for CPS. Though data-driven, the design and optimization of the framework are Subject Matter Expertise (SME) guided. An SME defined Finite State Machine (FSM) is incorporated into the framework to prohibit intermittent misclassifications. In the case study, we implement the framework to perform machine-part interaction classification on a milling machine, and the performance is evaluated using a testing dataset and deployment simulations. The implementation achieved an average F1-Score of 0.946 across classes on the testing dataset and an average delay of 0.24 seconds on the deployment simulations.
Surveying 5G Techno-Economic Research to Inform the Evaluation of 6G Wireless Technologies
Jan 06, 2022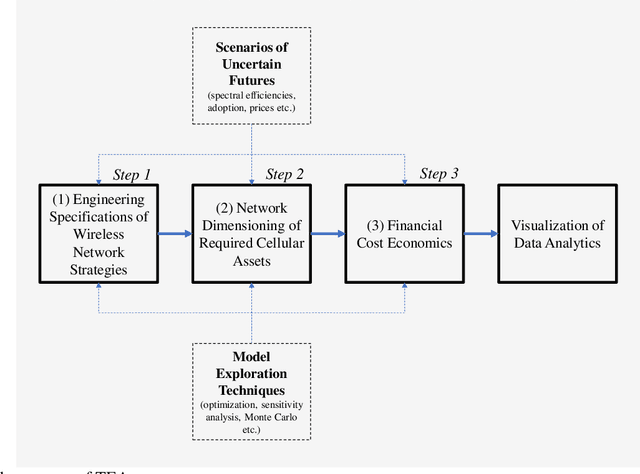
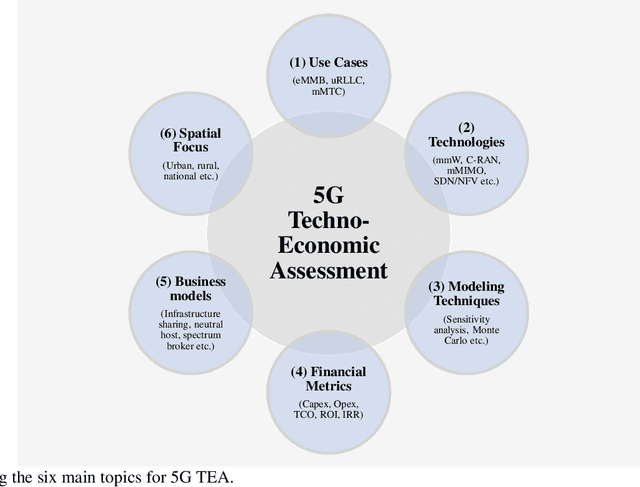
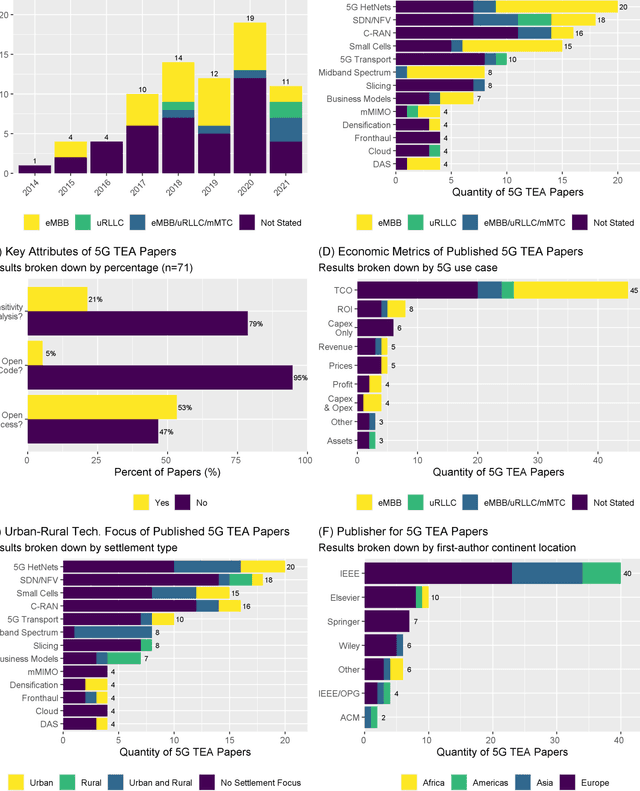
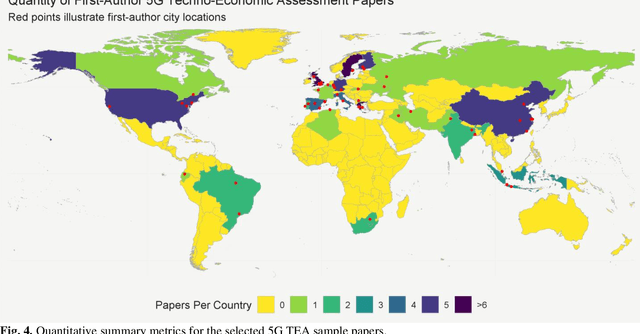
Techno-economic assessment is a fundamental technique engineers use for evaluating new communications technologies. However, despite the techno-economics of the fifth cellular generation (5G) being an active research area, it is surprising there are few comprehensive evaluations of this growing literature. With mobile network operators deploying 5G across their networks, it is therefore an opportune time to appraise current accomplishments and review the state-of-the-art. Such insight can inform the flurry of 6G research papers currently underway and help engineers in their mission to provide affordable high-capacity, low-latency broadband connectivity, globally. The survey discusses emerging trends from the 5G techno-economic literature and makes six key recommendations for the design and standardization of Next Generation 6G wireless technologies.
Approaches and Applications of Early Classification of Time Series: A Review
May 06, 2020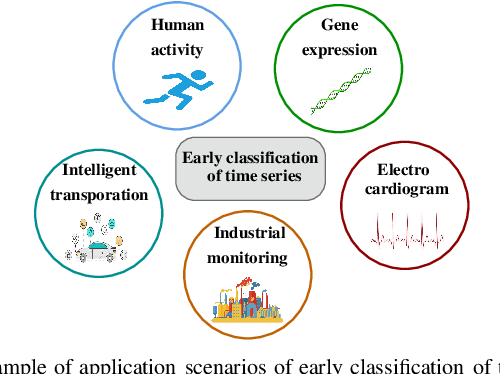
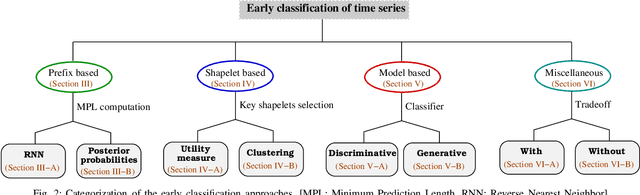
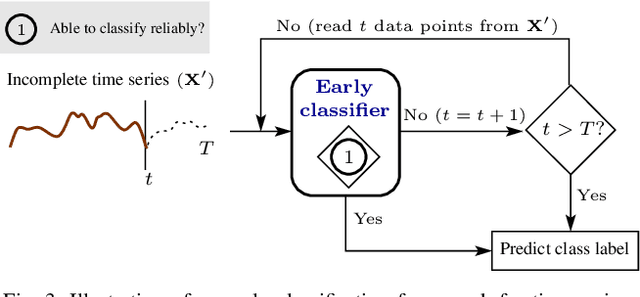
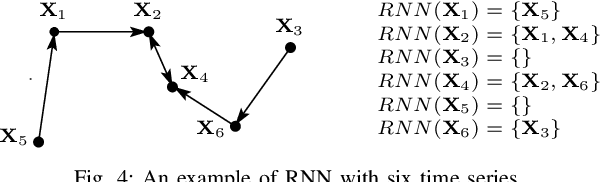
Early classification of time series has been extensively studied for minimizing class prediction delay in time-sensitive applications such as healthcare and finance. A primary task of an early classification approach is to classify an incomplete time series as soon as possible with some desired level of accuracy. Recent years have witnessed several approaches for early classification of time series. As most of the approaches have solved the early classification problem with different aspects, it becomes very important to make a thorough review of the existing solutions to know the current status of the area. These solutions have demonstrated reasonable performance in a wide range of applications including human activity recognition, gene expression based health diagnostic, industrial monitoring, and so on. In this paper, we present a systematic review of current literature on early classification approaches for both univariate and multivariate time series. We divide various existing approaches into four exclusive categories based on their proposed solution strategies. The four categories include prefix based, shapelet based, model based, and miscellaneous approaches. The authors also discuss the applications of early classification in many areas including industrial monitoring, intelligent transportation, and medical. Finally, we provide a quick summary of the current literature with future research directions.
A Multi-Domain VNE Algorithm based on Load Balancing in the IoT networks
Feb 07, 2022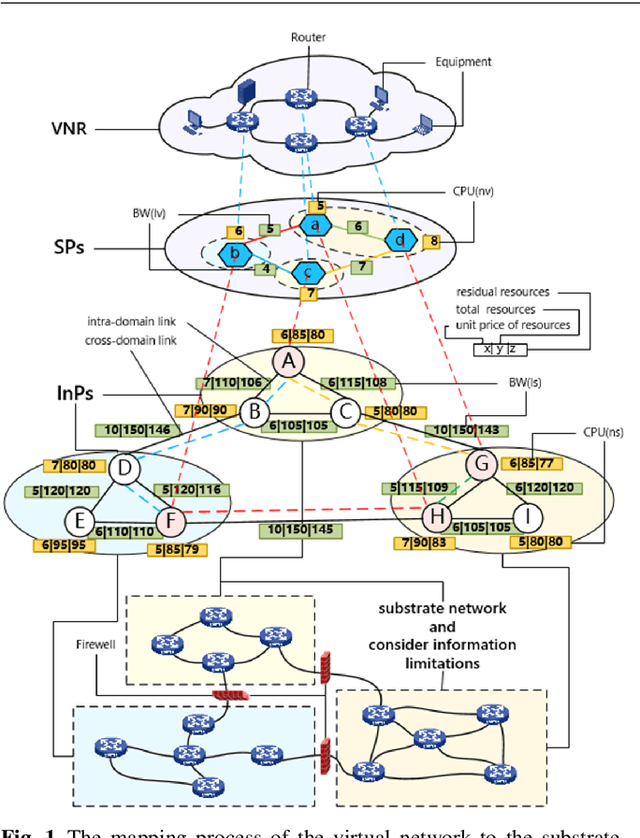

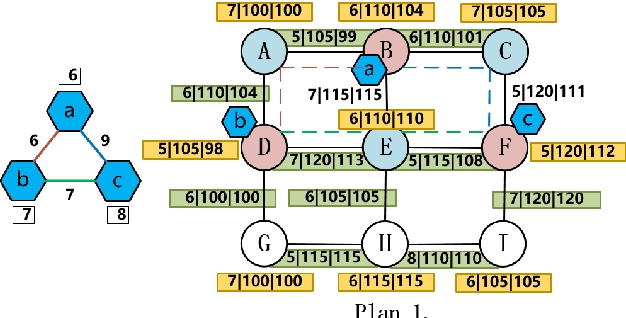

Virtual network embedding is one of the key problems of network virtualization. Since virtual network mapping is an NP-hard problem, a lot of research has focused on the evolutionary algorithm's masterpiece genetic algorithm. However, the parameter setting in the traditional method is too dependent on experience, and its low flexibility makes it unable to adapt to increasingly complex network environments. In addition, link-mapping strategies that do not consider load balancing can easily cause link blocking in high-traffic environments. In the IoT environment involving medical, disaster relief, life support and other equipment, network performance and stability are particularly important. Therefore, how to provide a more flexible virtual network mapping service in a heterogeneous network environment with large traffic is an urgent problem. Aiming at this problem, a virtual network mapping strategy based on hybrid genetic algorithm is proposed. This strategy uses a dynamically calculated cross-probability and pheromone-based mutation gene selection strategy to improve the flexibility of the algorithm. In addition, a weight update mechanism based on load balancing is introduced to reduce the probability of mapping failure while balancing the load. Simulation results show that the proposed method performs well in a number of performance metrics including mapping average quotation, link load balancing, mapping cost-benefit ratio, acceptance rate and running time.
Multiway Spherical Clustering via Degree-Corrected Tensor Block Models
Jan 19, 2022



We consider the problem of multiway clustering in the presence of unknown degree heterogeneity. Such data problems arise commonly in applications such as recommendation system, neuroimaging, community detection, and hypergraph partitions in social networks. The allowance of degree heterogeneity provides great flexibility in clustering models, but the extra complexity poses significant challenges in both statistics and computation. Here, we develop a degree-corrected tensor block model with estimation accuracy guarantees. We present the phase transition of clustering performance based on the notion of angle separability, and we characterize three signal-to-noise regimes corresponding to different statistical-computational behaviors. In particular, we demonstrate that an intrinsic statistical-to-computational gap emerges only for tensors of order three or greater. Further, we develop an efficient polynomial-time algorithm that provably achieves exact clustering under mild signal conditions. The efficacy of our procedure is demonstrated through two data applications, one on human brain connectome project, and another on Peru Legislation network dataset.
Coordinated Multi-Robot Trajectory Tracking over Sampled Communication
Dec 03, 2021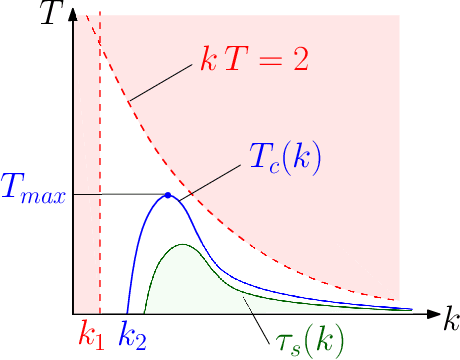
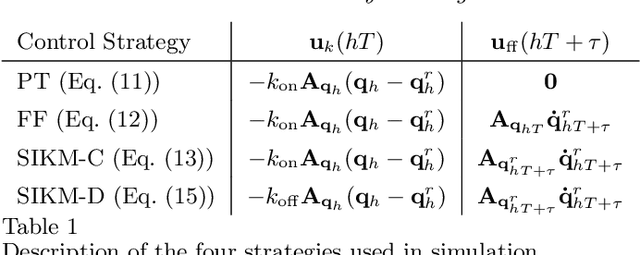
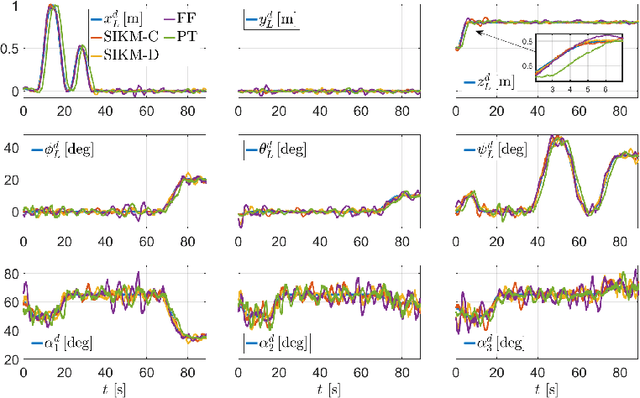
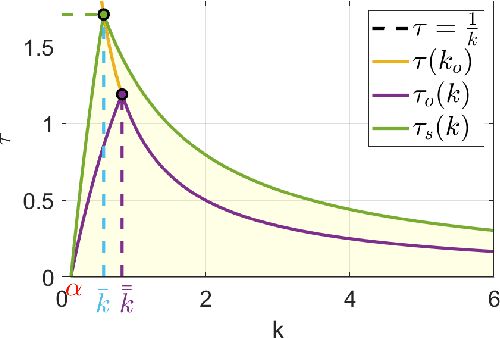
In this paper, we propose an inverse-kinematics controller for a class of multi-robot systems in the scenario of sampled communication. The goal is to make a group of robots perform trajectory tracking {in a coordinated way} when the sampling time of communications is non-negligible, disrupting the theoretical convergence guarantees of standard control designs. Given a feasible desired trajectory in the configuration space, the proposed controller receives measurements from the system at sampled time instants and computes velocity references for the robots, which are tracked by a low-level controller. We propose a jointly designed feedback plus feedforward controller with provable stability and error convergence guarantees, and further show that the obtained controller is amenable of decentralized implementation. We test the proposed control strategy via numerical simulations in the scenario of cooperative aerial manipulation of a cable-suspended load using a realistic simulator (Fly-Crane). Finally, we compare our proposed decentralized controller with centralized approaches that adapt the feedback gain online through smart heuristics, and show that it achieves comparable performance.
A Pragmatic Machine Learning Approach to Quantify Tumor Infiltrating Lymphocytes in Whole Slide Images
Feb 14, 2022
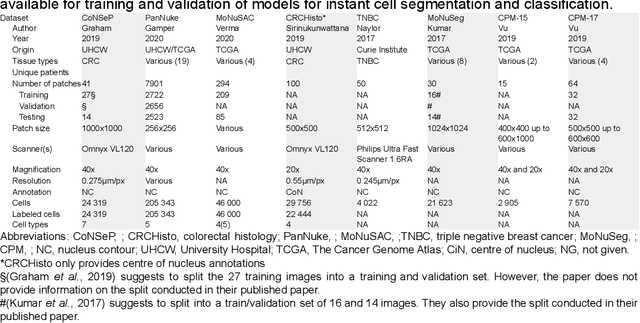
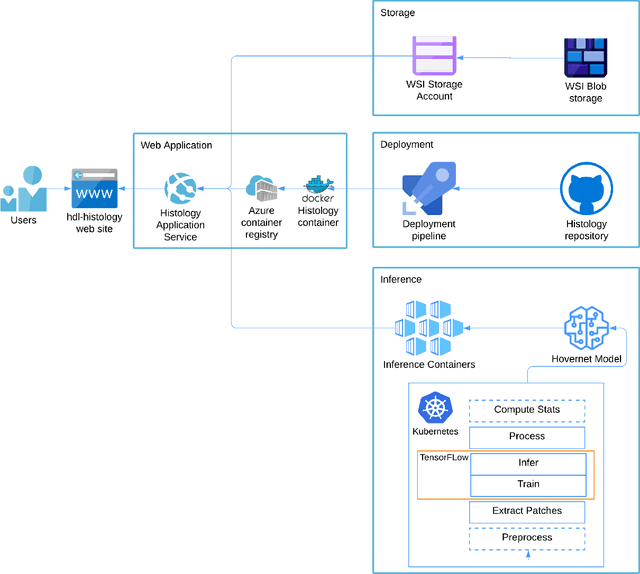
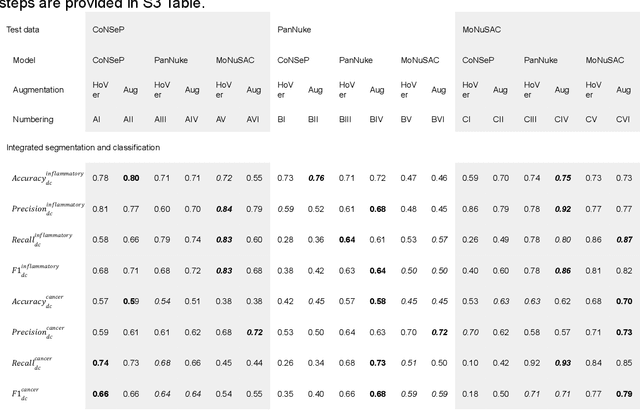
Increased levels of tumor infiltrating lymphocytes (TILs) in cancer tissue indicate favourable outcomes in many types of cancer. Manual quantification of immune cells is inaccurate and time consuming for pathologists. Our aim is to leverage a computational solution to automatically quantify TILs in whole slide images (WSIs) of standard diagnostic haematoxylin and eosin stained sections (H&E slides) from lung cancer patients. Our approach is to transfer an open source machine learning method for segmentation and classification of nuclei in H&E slides trained on public data to TIL quantification without manual labeling of our data. Our results show that additional augmentation improves model transferability when training on few samples/limited tissue types. Models trained with sufficient samples/tissue types do not benefit from our additional augmentation policy. Further, the resulting TIL quantification correlates to patient prognosis and compares favorably to the current state-of-the-art method for immune cell detection in non-small lung cancer (current standard CD8 cells in DAB stained TMAs HR 0.34 95% CI 0.17-0.68 vs TILs in HE WSIs: HoVer-Net PanNuke Aug Model HR 0.30 95% CI 0.15-0.60, HoVer-Net MoNuSAC Aug model HR 0.27 95% CI 0.14-0.53). Moreover, we implemented a cloud based system to train, deploy and visually inspect machine learning based annotation for H&E slides. Our pragmatic approach bridges the gap between machine learning research, translational clinical research and clinical implementation. However, validation in prospective studies is needed to assert that the method works in a clinical setting.
Pseudo-Labeled Auto-Curriculum Learning for Semi-Supervised Keypoint Localization
Jan 24, 2022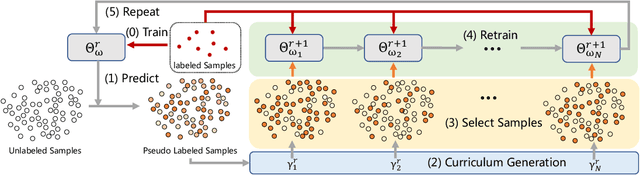
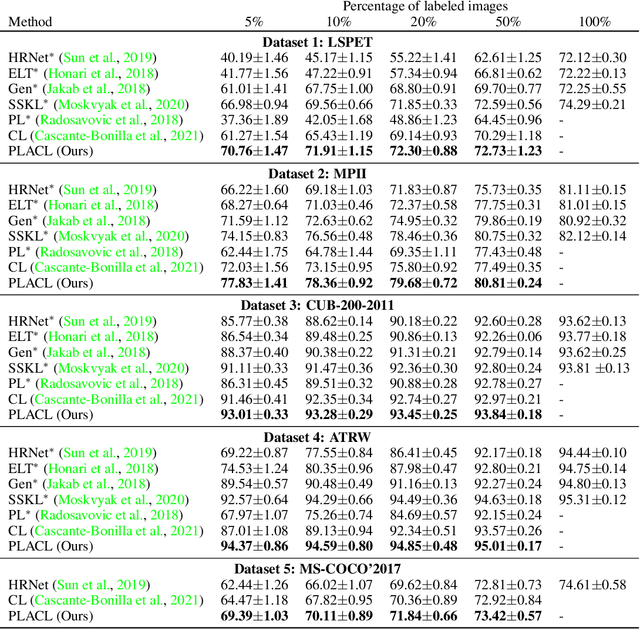
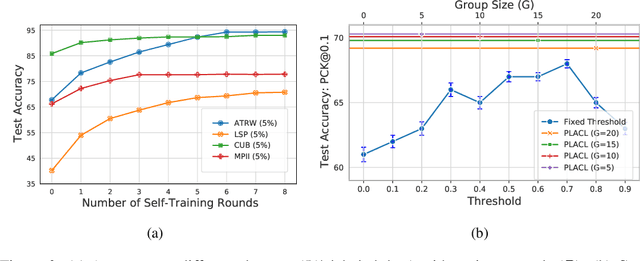
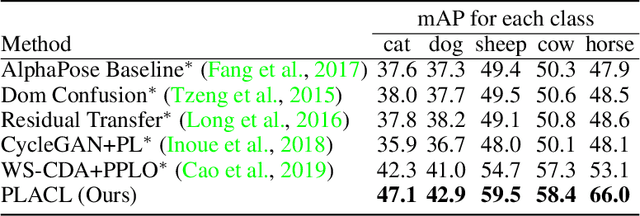
Localizing keypoints of an object is a basic visual problem. However, supervised learning of a keypoint localization network often requires a large amount of data, which is expensive and time-consuming to obtain. To remedy this, there is an ever-growing interest in semi-supervised learning (SSL), which leverages a small set of labeled data along with a large set of unlabeled data. Among these SSL approaches, pseudo-labeling (PL) is one of the most popular. PL approaches apply pseudo-labels to unlabeled data, and then train the model with a combination of the labeled and pseudo-labeled data iteratively. The key to the success of PL is the selection of high-quality pseudo-labeled samples. Previous works mostly select training samples by manually setting a single confidence threshold. We propose to automatically select reliable pseudo-labeled samples with a series of dynamic thresholds, which constitutes a learning curriculum. Extensive experiments on six keypoint localization benchmark datasets demonstrate that the proposed approach significantly outperforms the previous state-of-the-art SSL approaches.
EMT-NET: Efficient multitask network for computer-aided diagnosis of breast cancer
Jan 13, 2022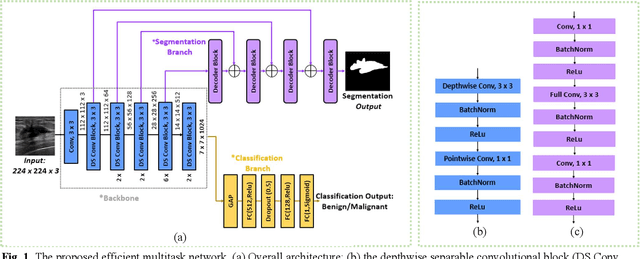
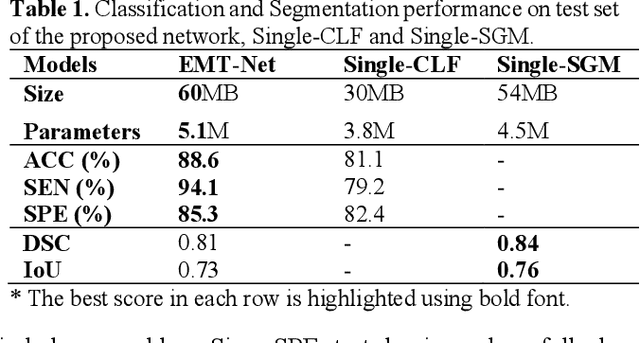
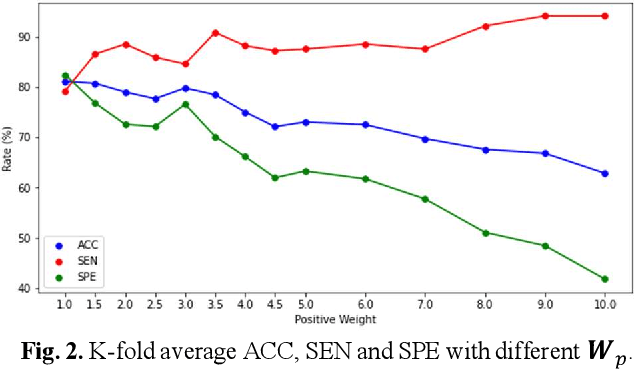
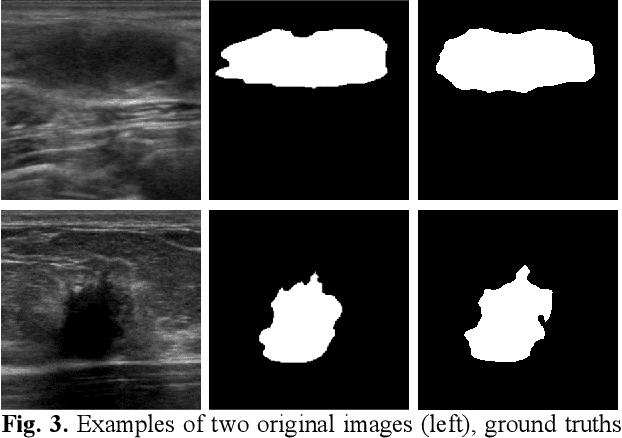
Deep learning-based computer-aided diagnosis has achieved unprecedented performance in breast cancer detection. However, most approaches are computationally intensive, which impedes their broader dissemination in real-world applications. In this work, we propose an efficient and light-weighted multitask learning architecture to classify and segment breast tumors simultaneously. We incorporate a segmentation task into a tumor classification network, which makes the backbone network learn representations focused on tumor regions. Moreover, we propose a new numerically stable loss function that easily controls the balance between the sensitivity and specificity of cancer detection. The proposed approach is evaluated using a breast ultrasound dataset with 1,511 images. The accuracy, sensitivity, and specificity of tumor classification is 88.6%, 94.1%, and 85.3%, respectively. We validate the model using a virtual mobile device, and the average inference time is 0.35 seconds per image.