 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning for Real-Time Optimization of Pumps in Water Distribution Systems
Oct 13, 2020
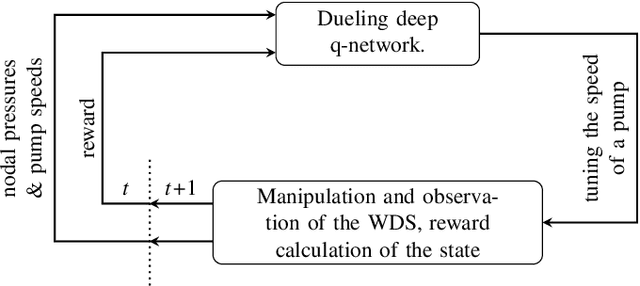


Real-time control of pumps can be an infeasible task in water distribution systems (WDSs) because the calculation to find the optimal pump speeds is resource-intensive. The computational need cannot be lowered even with the capabilities of smart water networks when conventional optimization techniques are used. Deep reinforcement learning (DRL) is presented here as a controller of pumps in two WDSs. An agent based on a dueling deep q-network is trained to maintain the pump speeds based on instantaneous nodal pressure data. General optimization techniques (e.g., Nelder-Mead method, differential evolution) serve as baselines. The total efficiency achieved by the DRL agent compared to the best performing baseline is above 0.98, whereas the speedup is around 2x compared to that. The main contribution of the presented approach is that the agent can run the pumps in real-time because it depends only on measurement data. If the WDS is replaced with a hydraulic simulation, the agent still outperforms conventional techniques in search speed.
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
Jan 18, 2022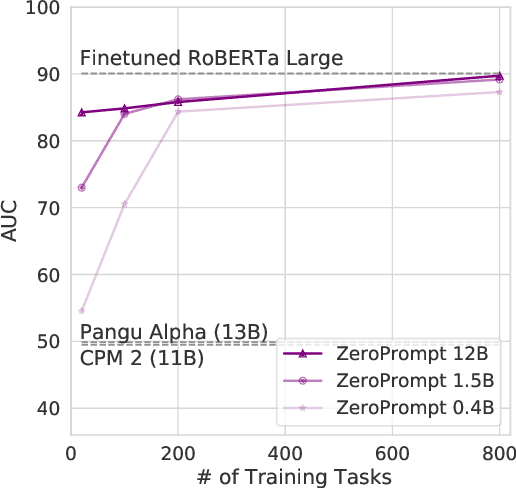

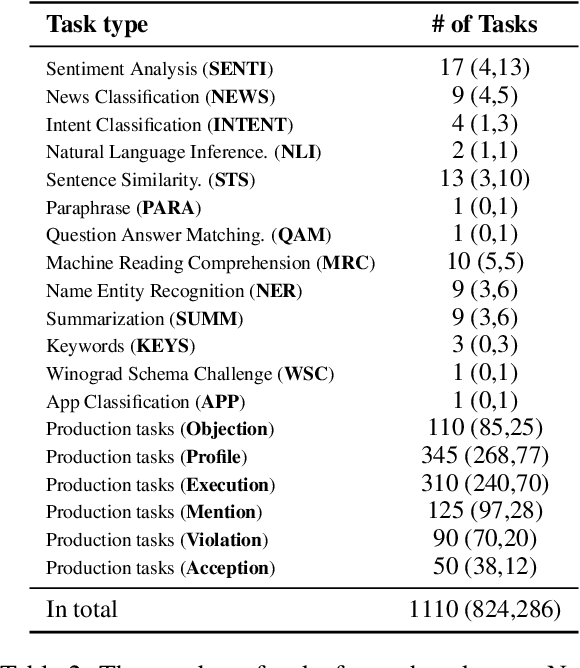
We propose a multitask pretraining approach ZeroPrompt for zero-shot generalization, focusing on task scaling and zero-shot prompting. While previous models are trained on only a few dozen tasks, we scale to 1,000 tasks for the first time using real-world data. This leads to a crucial discovery that task scaling can be an efficient alternative to model scaling; i.e., the model size has little impact on performance with an extremely large number of tasks. Our results show that task scaling can substantially improve training efficiency by 30 times in FLOPs. Moreover, we present a prompting method that incorporates a genetic algorithm to automatically search for the best prompt for unseen tasks, along with a few other improvements. Empirically, ZeroPrompt substantially improves both the efficiency and the performance of zero-shot learning across a variety of academic and production datasets.
IDP-Z3: a reasoning engine for FO(.)
Feb 11, 2022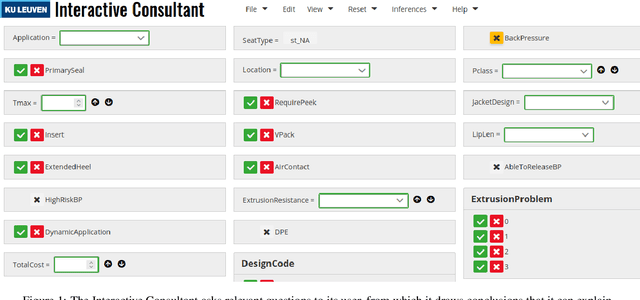



An important sign of intelligence is the capacity to apply a body of knowledge to a particular situation in order to not only derive new knowledge, but also to determine relevant questions or provide explanations. Developing interactive systems capable of performing such a variety of reasoning tasks for the benefits of its users has proved difficult, notably for performance and/or development cost reasons. Still, recently, a reasoning engine, called IDP3, has been used to build such systems, but it lacked support for arithmetic operations, seriously limiting its usefulness. We have developed a new reasoning engine, IDP-Z3, that removes this limitation, and we put it to the test in four knowledge-intensive industrial use cases. This paper describes FO(.) (aka FO-dot), the language used to represent knowledge in the IDP3 and IDP-Z3 system. It then describes the generic reasoning tasks that IDP-Z3 can perform, and how we used them to build a generic user interface, called the Interactive Consultant. Finally, it reports on the four use cases. In these four use cases, the interactive applications based on IDP-Z3 were capable of intelligent behavior of value to users, while having a low development cost (typically 10 days) and an acceptable response time (typically below 3 seconds). Performance could be further improved, in particular for problems on larger domains.
Auto-X3D: Ultra-Efficient Video Understanding via Finer-Grained Neural Architecture Search
Dec 09, 2021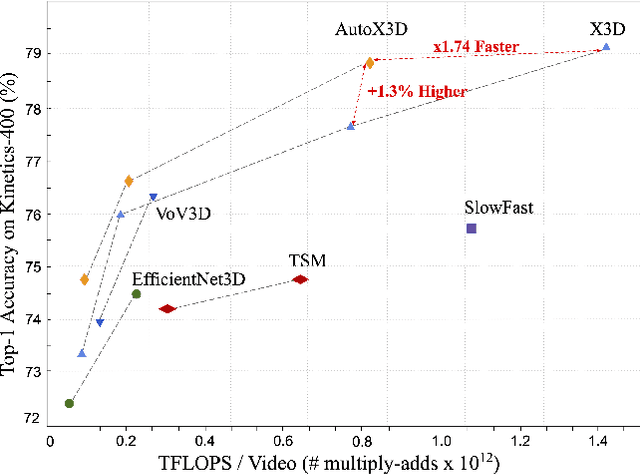

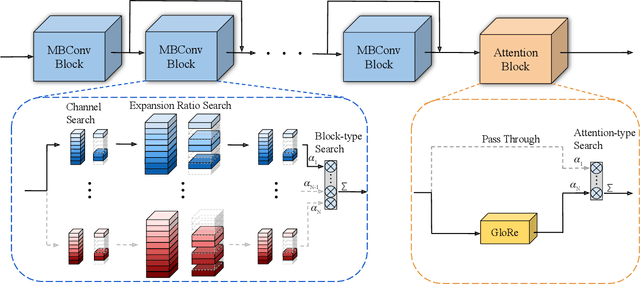
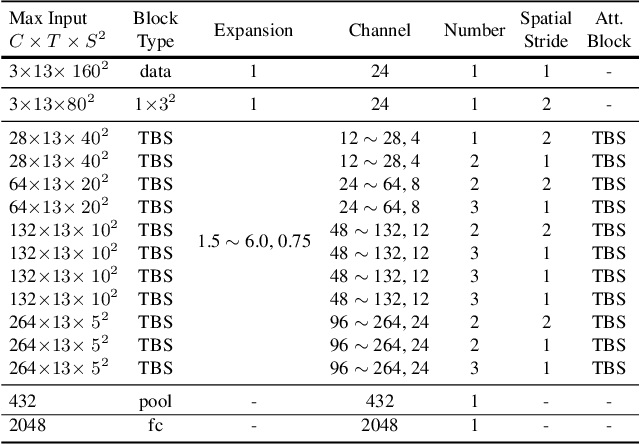
Efficient video architecture is the key to deploying video recognition systems on devices with limited computing resources. Unfortunately, existing video architectures are often computationally intensive and not suitable for such applications. The recent X3D work presents a new family of efficient video models by expanding a hand-crafted image architecture along multiple axes, such as space, time, width, and depth. Although operating in a conceptually large space, X3D searches one axis at a time, and merely explored a small set of 30 architectures in total, which does not sufficiently explore the space. This paper bypasses existing 2D architectures, and directly searched for 3D architectures in a fine-grained space, where block type, filter number, expansion ratio and attention block are jointly searched. A probabilistic neural architecture search method is adopted to efficiently search in such a large space. Evaluations on Kinetics and Something-Something-V2 benchmarks confirm our AutoX3D models outperform existing ones in accuracy up to 1.3% under similar FLOPs, and reduce the computational cost up to x1.74 when reaching similar performance.
Large-scale Personalized Video Game Recommendation via Social-aware Contextualized Graph Neural Network
Feb 07, 2022
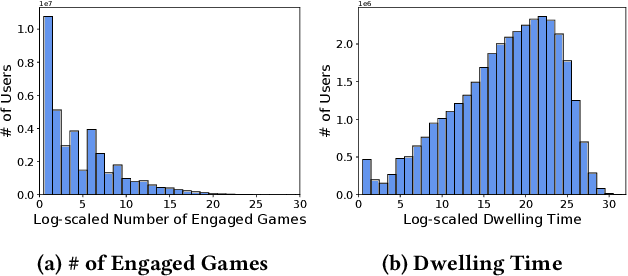
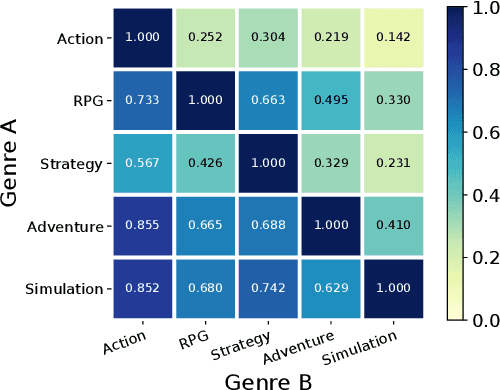
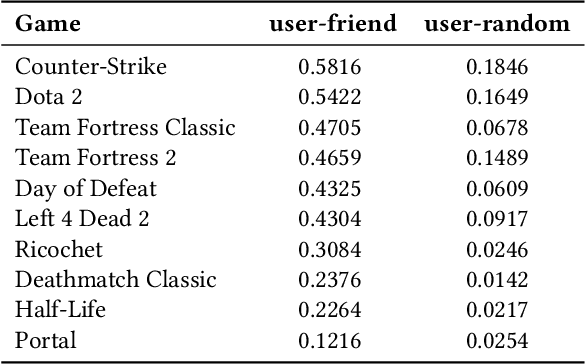
Because of the large number of online games available nowadays, online game recommender systems are necessary for users and online game platforms. The former can discover more potential online games of their interests, and the latter can attract users to dwell longer in the platform. This paper investigates the characteristics of user behaviors with respect to the online games on the Steam platform. Based on the observations, we argue that a satisfying recommender system for online games is able to characterize: personalization, game contextualization and social connection. However, simultaneously solving all is rather challenging for game recommendation. Firstly, personalization for game recommendation requires the incorporation of the dwelling time of engaged games, which are ignored in existing methods. Secondly, game contextualization should reflect the complex and high-order properties of those relations. Last but not least, it is problematic to use social connections directly for game recommendations due to the massive noise within social connections. To this end, we propose a Social-aware Contextualized Graph Neural Recommender System (SCGRec), which harnesses three perspectives to improve game recommendation. We conduct a comprehensive analysis of users' online game behaviors, which motivates the necessity of handling those three characteristics in the online game recommendation.
An Efficient and Accurate Rough Set for Feature Selection, Classification and Knowledge Representation
Jan 12, 2022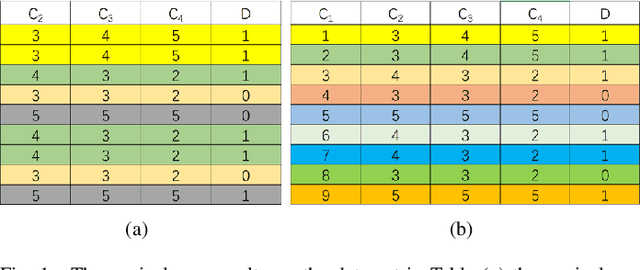
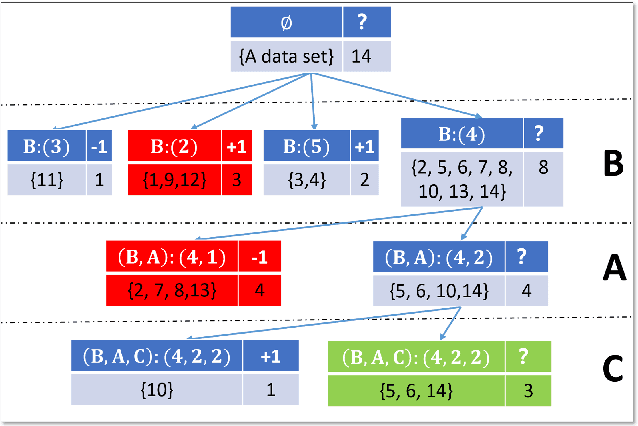
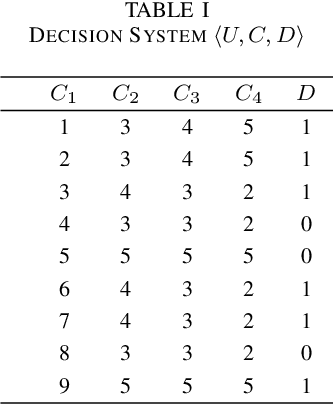
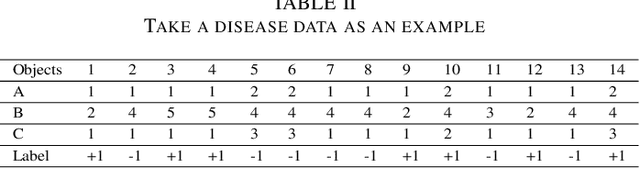
This paper present a strong data mining method based on rough set, which can realize feature selection, classification and knowledge representation at the same time. Rough set has good interpretability, and is a popular method for feature selections. But low efficiency and low accuracy are its main drawbacks that limits its application ability. In this paper,corresponding to the accuracy, we first find the ineffectiveness of rough set because of overfitting, especially in processing noise attribute, and propose a robust measurement for an attribute, called relative importance.we proposed the concept of "rough concept tree" for knowledge representation and classification. Experimental results on public benchmark data sets show that the proposed framework achieves higher accurcy than seven popular or the state-of-the-art feature selection methods.
AutoMC: Automated Model Compression based on Domain Knowledge and Progressive search strategy
Jan 24, 2022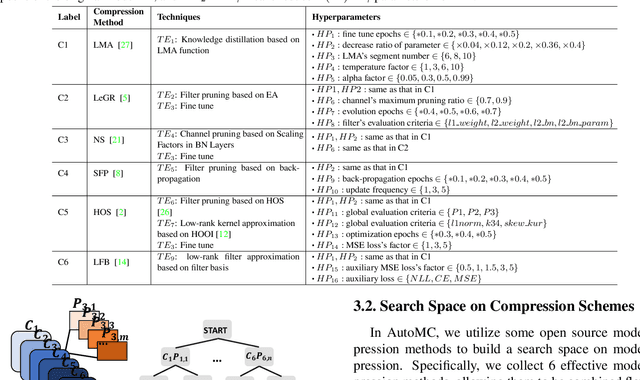
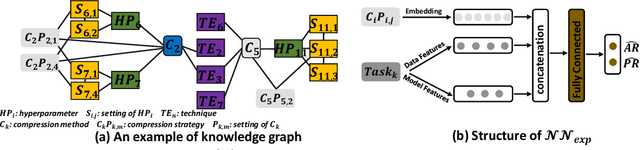
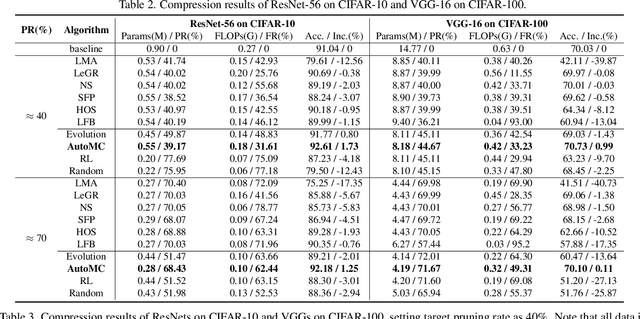
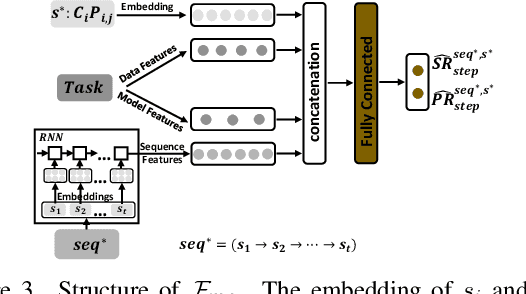
Model compression methods can reduce model complexity on the premise of maintaining acceptable performance, and thus promote the application of deep neural networks under resource constrained environments. Despite their great success, the selection of suitable compression methods and design of details of the compression scheme are difficult, requiring lots of domain knowledge as support, which is not friendly to non-expert users. To make more users easily access to the model compression scheme that best meet their needs, in this paper, we propose AutoMC, an effective automatic tool for model compression. AutoMC builds the domain knowledge on model compression to deeply understand the characteristics and advantages of each compression method under different settings. In addition, it presents a progressive search strategy to efficiently explore pareto optimal compression scheme according to the learned prior knowledge combined with the historical evaluation information. Extensive experimental results show that AutoMC can provide satisfying compression schemes within short time, demonstrating the effectiveness of AutoMC.
An efficient label-free analyte detection algorithm for time-resolved spectroscopy
Nov 15, 2020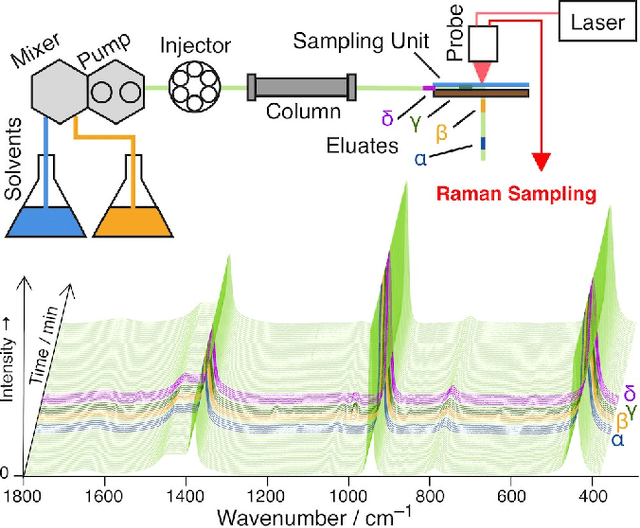
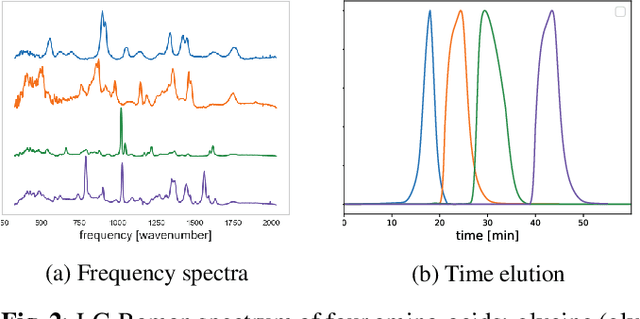
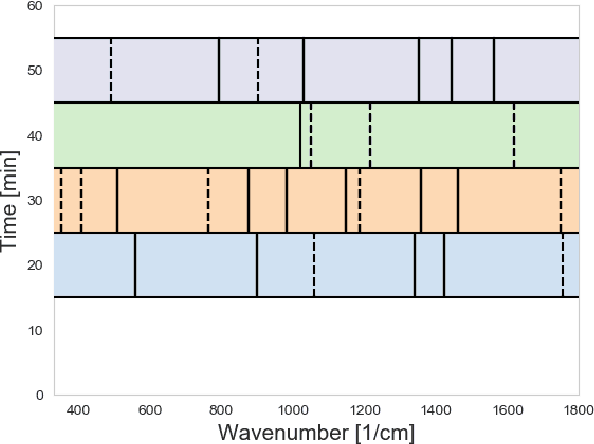
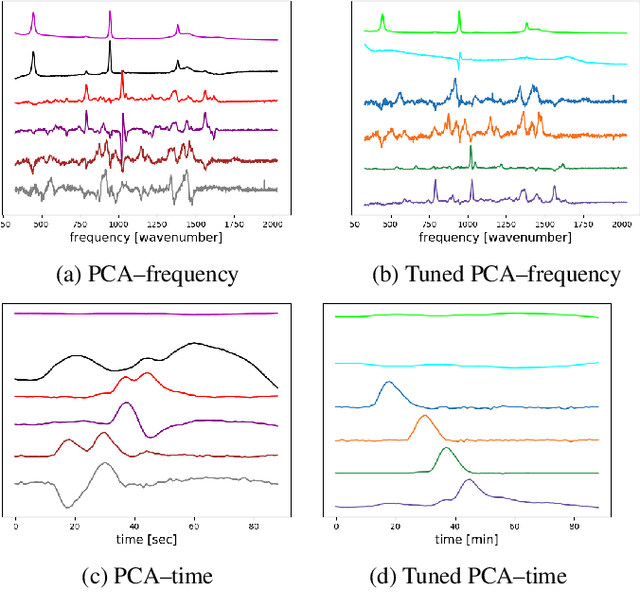
Time-resolved spectral techniques play an important analysis tool in many contexts, from physical chemistry to biomedicine. Customarily, the label-free detection of analytes is manually performed by experts through the aid of classic dimensionality-reduction methods, such as Principal Component Analysis (PCA) and Non-negative Matrix Factorization (NMF). This fundamental reliance on expert analysis for unknown analyte detection severely hinders the applicability and the throughput of these such techniques. For this reason, in this paper, we formulate this detection problem as an unsupervised learning problem and propose a novel machine learning algorithm for label-free analyte detection. To show the effectiveness of the proposed solution, we consider the problem of detecting the amino-acids in Liquid Chromatography coupled with Raman spectroscopy (LC-Raman).
Optimal Localization with Sequential Pseudorange Measurements for Moving Users in a Time Division Broadcast Positioning System
Feb 01, 2021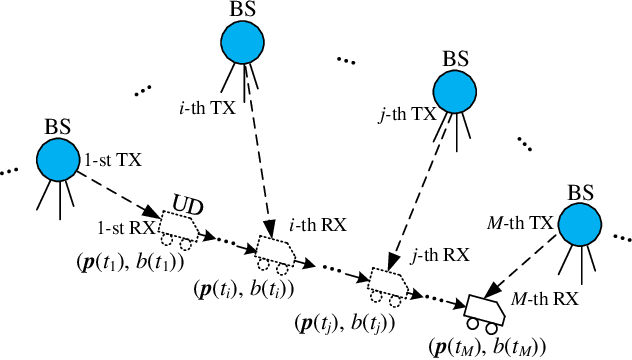
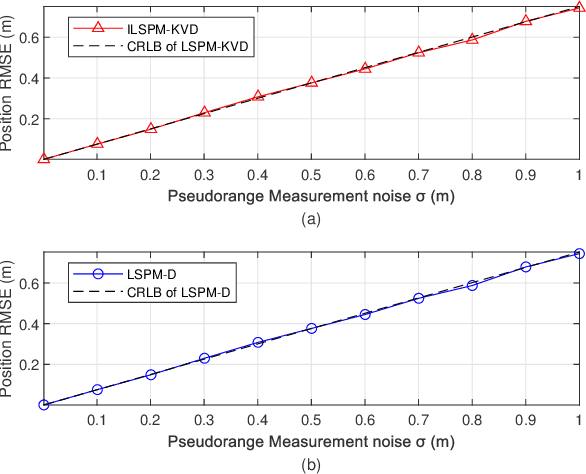
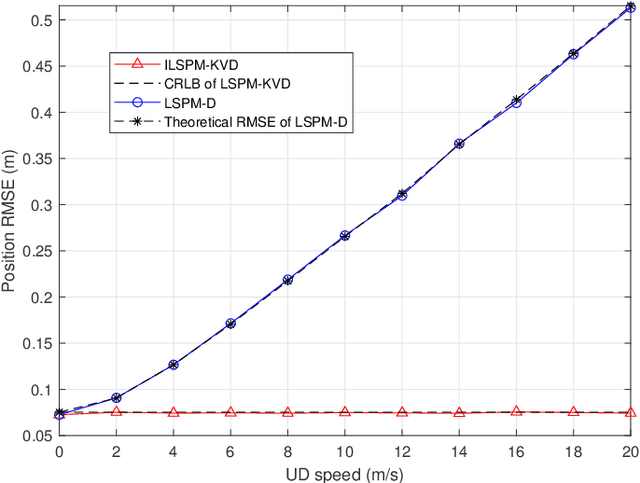
In a time division broadcast positioning system (TDBPS), a user device (UD) determines its position by obtaining sequential time-of-arrival (TOA) or pseudorange measurements from signals broadcast by multiple synchronized base stations (BSs). The existing localization method using sequential pseudorange measurements and a linear clock drift model for the TDPBS, namely LSPM-D, does not compensate the position displacement caused by the UD movement and will result in position error. In this paper, depending on the knowledge of the UD velocity, we develop a set of optimal localization methods for different cases. First, for known UD velocity, we develop the optimal localization method, namely LSPM-KVD, to compensate the movement-caused position error. We show that the LSPM-D is a special case of the LSPM-KVD when the UD is stationary with zero velocity. Second, for the case with unknown UD velocity, we develop a maximum likelihood (ML) method to jointly estimate the UD position and velocity, namely LSPM-UVD. Third, in the case that we have prior distribution information of the UD velocity, we present a maximum a posteriori (MAP) estimator for localization, namely LSPM-PVD. We derive the Cramer-Rao lower bound (CRLB) for all three estimators and analyze their localization error performance. We show that the position error of the LSPM-KVD increases as the assumed known velocity deviates from the true value. As expected, the LSPM-KVD has the smallest position error while the LSPM-PVD and the LSPM-UVD are more robust when the prior knowledge of the UD velocity is limited. Numerical results verify the theoretical analysis on the optimality and the positioning accuracy of the proposed methods.
Motion Correction and Volumetric Reconstruction for Fetal Functional Magnetic Resonance Imaging Data
Feb 11, 2022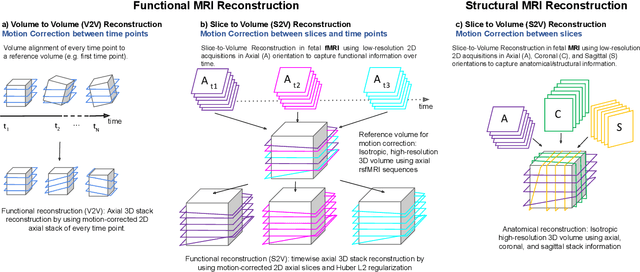
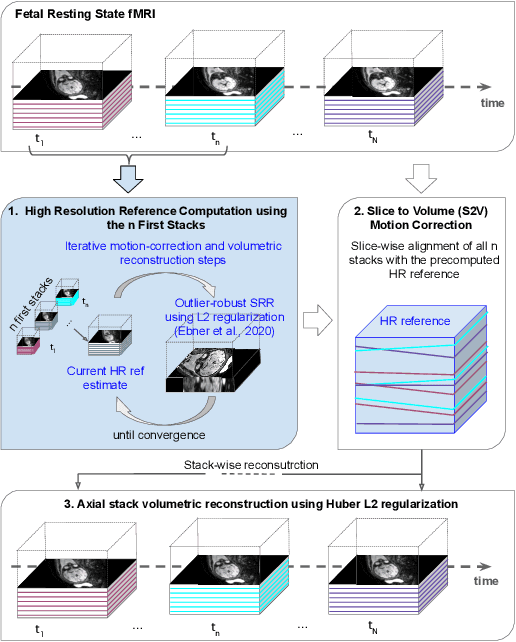
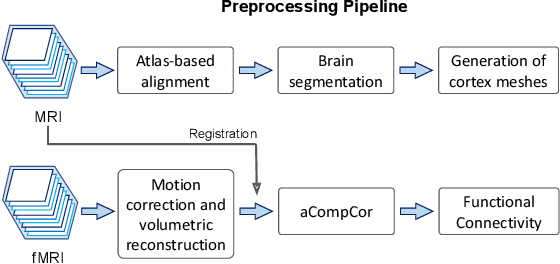
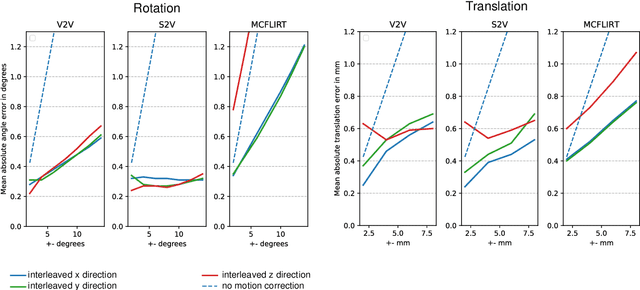
Motion correction is an essential preprocessing step in functional Magnetic Resonance Imaging (fMRI) of the fetal brain with the aim to remove artifacts caused by fetal movement and maternal breathing and consequently to suppress erroneous signal correlations. Current motion correction approaches for fetal fMRI choose a single 3D volume from a specific acquisition timepoint with least motion artefacts as reference volume, and perform interpolation for the reconstruction of the motion corrected time series. The results can suffer, if no low-motion frame is available, and if reconstruction does not exploit any assumptions about the continuity of the fMRI signal. Here, we propose a novel framework, which estimates a high-resolution reference volume by using outlier-robust motion correction, and by utilizing Huber L2 regularization for intra-stack volumetric reconstruction of the motion-corrected fetal brain fMRI. We performed an extensive parameter study to investigate the effectiveness of motion estimation and present in this work benchmark metrics to quantify the effect of motion correction and regularised volumetric reconstruction approaches on functional connectivity computations. We demonstrate the proposed framework's ability to improve functional connectivity estimates, reproducibility and signal interpretability, which is clinically highly desirable for the establishment of prognostic noninvasive imaging biomarkers. The motion correction and volumetric reconstruction framework is made available as an open-source package of NiftyMIC.