 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning a Single Neuron for Non-monotonic Activation Functions
Feb 16, 2022
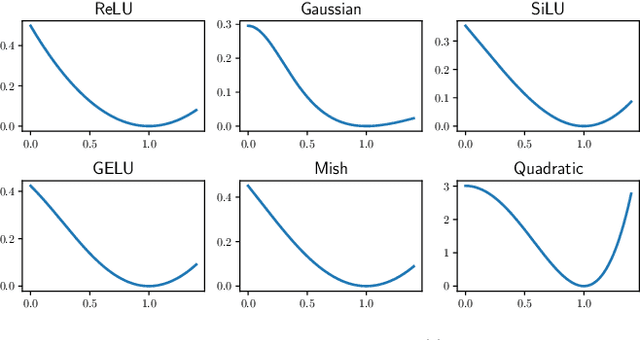
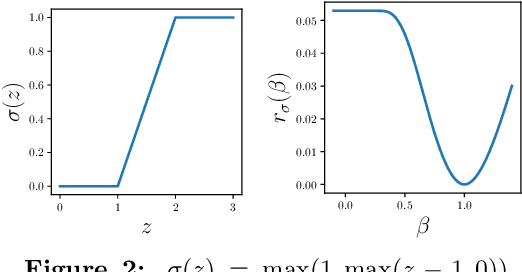
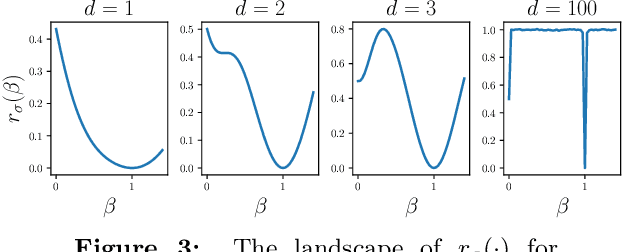
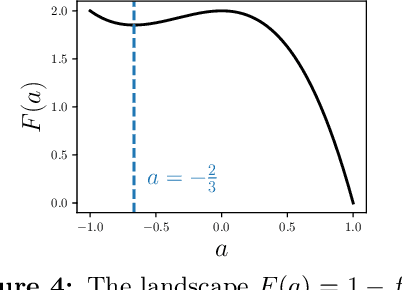
We study the problem of learning a single neuron $\mathbf{x}\mapsto \sigma(\mathbf{w}^T\mathbf{x})$ with gradient descent (GD). All the existing positive results are limited to the case where $\sigma$ is monotonic. However, it is recently observed that non-monotonic activation functions outperform the traditional monotonic ones in many applications. To fill this gap, we establish learnability without assuming monotonicity. Specifically, when the input distribution is the standard Gaussian, we show that mild conditions on $\sigma$ (e.g., $\sigma$ has a dominating linear part) are sufficient to guarantee the learnability in polynomial time and polynomial samples. Moreover, with a stronger assumption on the activation function, the condition of input distribution can be relaxed to a non-degeneracy of the marginal distribution. We remark that our conditions on $\sigma$ are satisfied by practical non-monotonic activation functions, such as SiLU/Swish and GELU. We also discuss how our positive results are related to existing negative results on training two-layer neural networks.
Random Access with Massive MIMO-OTFS in LEO Satellite Communications
Feb 26, 2022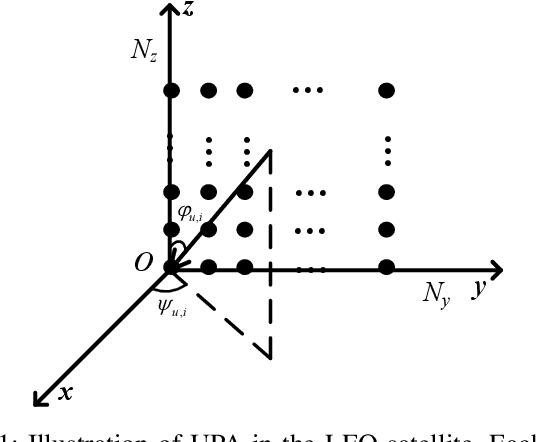
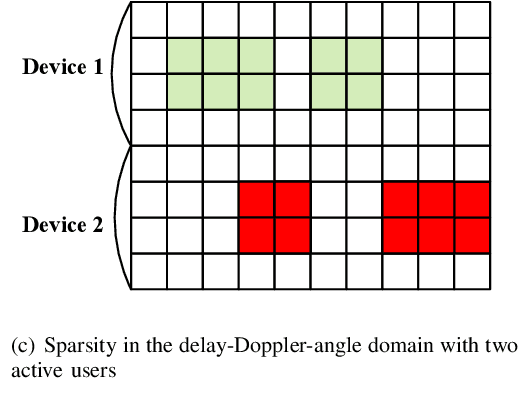
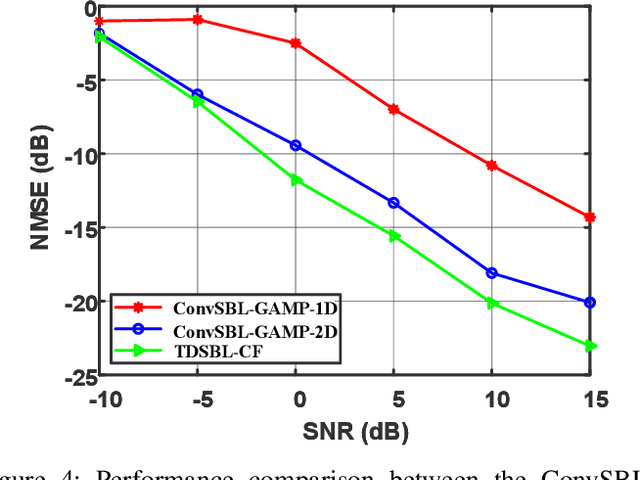
This paper considers the joint channel estimation and device activity detection in the grant-free random access systems, where a large number of Internet-of-Things devices intend to communicate with a low-earth orbit satellite in a sporadic way. In addition, the massive multiple-input multiple-output (MIMO) with orthogonal time-frequency space (OTFS) modulation is adopted to combat the dynamics of the terrestrial-satellite link. We first analyze the input-output relationship of the single-input single-output OTFS when the large delay and Doppler shift both exist, and then extend it to the grant-free random access with massive MIMO-OTFS. Next, by exploring the sparsity of channel in the delay-Doppler-angle domain, a two-dimensional pattern coupled hierarchical prior with the sparse Bayesian learning and covariance-free method (TDSBL-FM) is developed for the channel estimation. Then, the active devices are detected by computing the energy of the estimated channel. Finally, the generalized approximate message passing algorithm combined with the sparse Bayesian learning and two-dimensional convolution (ConvSBL-GAMP) is proposed to decrease the computations of the TDSBL-FM algorithm. Simulation results demonstrate that the proposed algorithms outperform conventional methods.
Reproducing Personalised Session Search over the AOL Query Log
Jan 21, 2022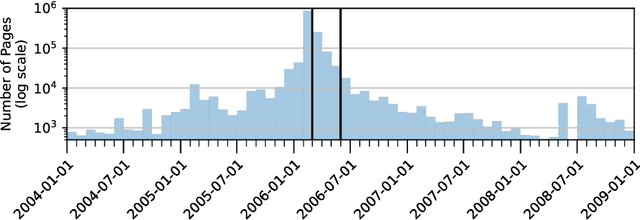
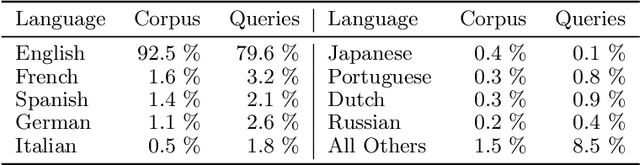
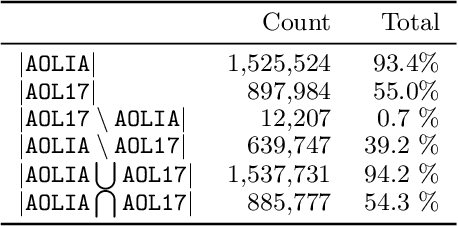
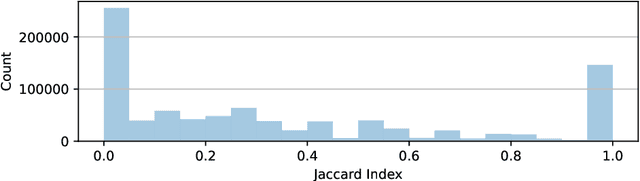
Despite its troubled past, the AOL Query Log continues to be an important resource to the research community -- particularly for tasks like search personalisation. When using the query log these ranking experiments, little attention is usually paid to the document corpus. Recent work typically uses a corpus containing versions of the documents collected long after the log was produced. Given that web documents are prone to change over time, we study the differences present between a version of the corpus containing documents as they appeared in 2017 (which has been used by several recent works) and a new version we construct that includes documents close to as they appeared at the time the query log was produced (2006). We demonstrate that this new version of the corpus has a far higher coverage of documents present in the original log (93%) than the 2017 version (55%). Among the overlapping documents, the content often differs substantially. Given these differences, we re-conduct session search experiments that originally used the 2017 corpus and find that when using our corpus for training or evaluation, system performance improves. We place the results in context by introducing recent adhoc ranking baselines. We also confirm the navigational nature of the queries in the AOL corpus by showing that including the URL substantially improves performance across a variety of models. Our version of the corpus can be easily reconstructed by other researchers and is included in the ir-datasets package.
Anomaly Detection at Scale: The Case for Deep Distributional Time Series Models
Jul 30, 2020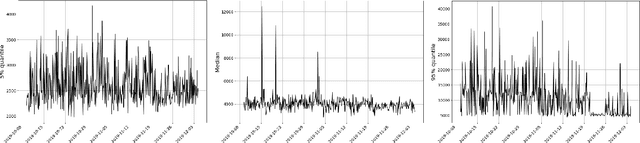

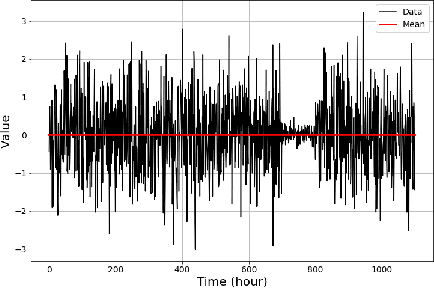
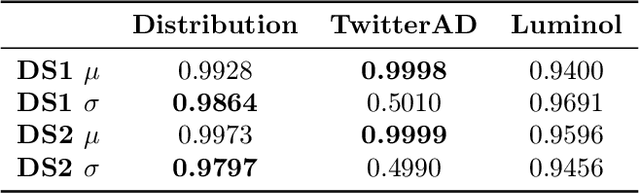
This paper introduces a new methodology for detecting anomalies in time series data, with a primary application to monitoring the health of (micro-) services and cloud resources. The main novelty in our approach is that instead of modeling time series consisting of real values or vectors of real values, we model time series of probability distributions over real values (or vectors). This extension to time series of probability distributions allows the technique to be applied to the common scenario where the data is generated by requests coming in to a service, which is then aggregated at a fixed temporal frequency. Our method is amenable to streaming anomaly detection and scales to monitoring for anomalies on millions of time series. We show the superior accuracy of our method on synthetic and public real-world data. On the Yahoo Webscope data set, we outperform the state of the art in 3 out of 4 data sets and we show that we outperform popular open-source anomaly detection tools by up to 17% average improvement for a real-world data set.
QoS-SLA-Aware Artificial Intelligence Adaptive Genetic Algorithm for Multi-Request Offloading in Integrated Edge-Cloud Computing System for the Internet of Vehicles
Jan 21, 2022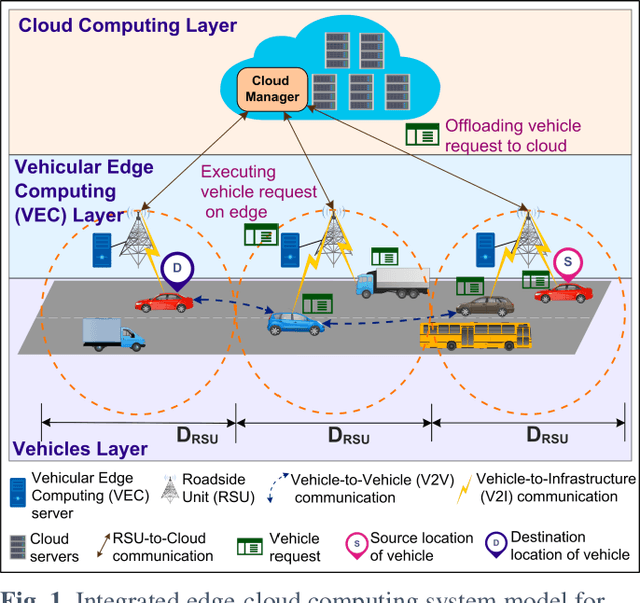
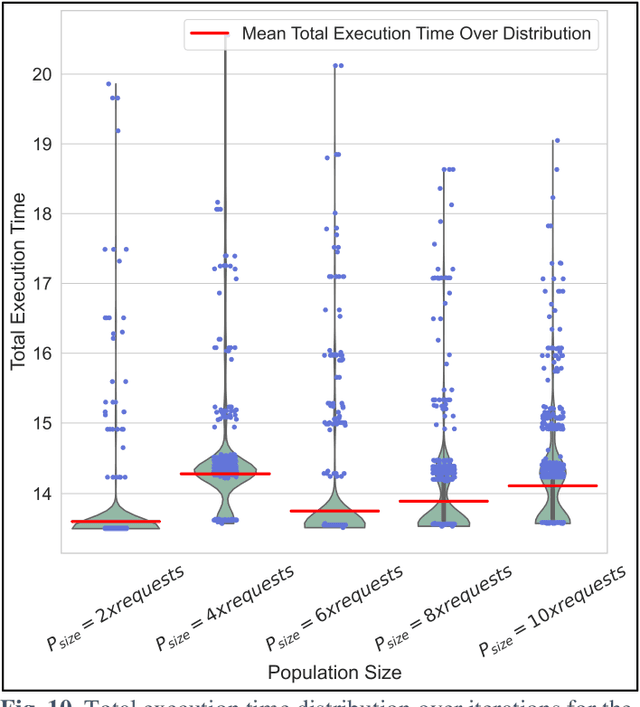
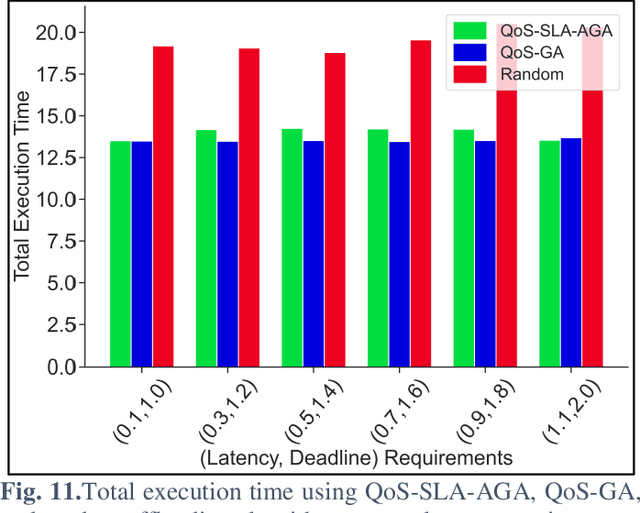
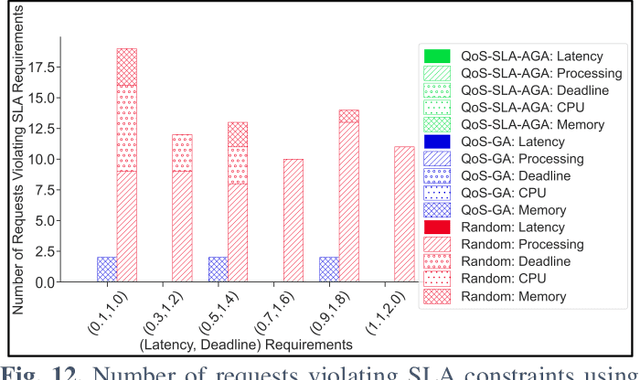
Internet of Vehicles (IoV) over Vehicular Ad-hoc Networks (VANETS) is an emerging technology enabling the development of smart cities applications for safer, efficient, and pleasant travel. These applications have stringent requirements expressed in Service Level Agreements (SLAs). Considering vehicles limited computational and storage capabilities, applications requests are offloaded into an integrated edge-cloud computing system. Existing offloading solutions focus on optimizing applications Quality of Service (QoS) while respecting a single SLA constraint. They do not consider the impact of overlapped requests processing. Very few contemplate the varying speed of a vehicle. This paper proposes a novel Artificial Intelligence (AI) QoS-SLA-aware genetic algorithm (GA) for multi-request offloading in a heterogeneous edge-cloud computing system, considering the impact of overlapping requests processing and dynamic vehicle speed. The objective of the optimization algorithm is to improve the applications' Quality of Service (QoS) by minimizing the total execution time. The proposed algorithm integrates an adaptive penalty function to assimilate the SLAs constraints in terms of latency, processing time, deadline, CPU, and memory requirements. Numerical experiments and comparative analysis are achieved between our proposed QoS-SLA-aware GA, random, and GA baseline approaches. The results show that the proposed algorithm executes the requests 1.22 times faster on average compared to the random approach with 59.9% less SLA violations. While the GA baseline approach increases the performance of the requests by 1.14 times, it has 19.8% more SLA violations than our approach.
NLX-GPT: A Model for Natural Language Explanations in Vision and Vision-Language Tasks
Mar 09, 2022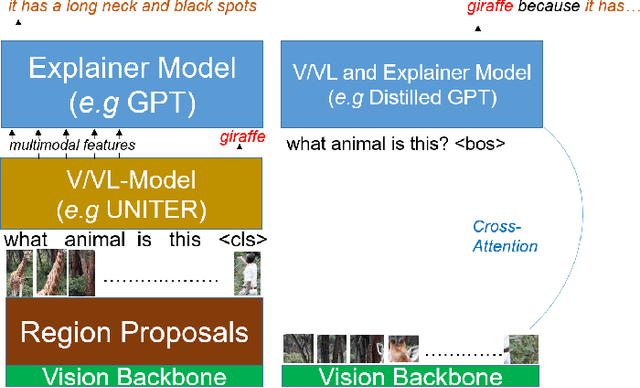


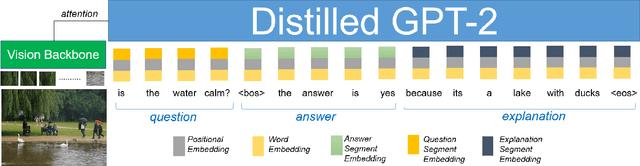
Natural language explanation (NLE) models aim at explaining the decision-making process of a black box system via generating natural language sentences which are human-friendly, high-level and fine-grained. Current NLE models explain the decision-making process of a vision or vision-language model (a.k.a., task model), e.g., a VQA model, via a language model (a.k.a., explanation model), e.g., GPT. Other than the additional memory resources and inference time required by the task model, the task and explanation models are completely independent, which disassociates the explanation from the reasoning process made to predict the answer. We introduce NLX-GPT, a general, compact and faithful language model that can simultaneously predict an answer and explain it. We first conduct pre-training on large scale data of image-caption pairs for general understanding of images, and then formulate the answer as a text prediction task along with the explanation. Without region proposals nor a task model, our resulting overall framework attains better evaluation scores, contains much less parameters and is 15$\times$ faster than the current SoA model. We then address the problem of evaluating the explanations which can be in many times generic, data-biased and can come in several forms. We therefore design 2 new evaluation measures: (1) explain-predict and (2) retrieval-based attack, a self-evaluation framework that requires no labels. Code is at: https://github.com/fawazsammani/nlxgpt.
A density peaks clustering algorithm with sparse search and K-d tree
Mar 02, 2022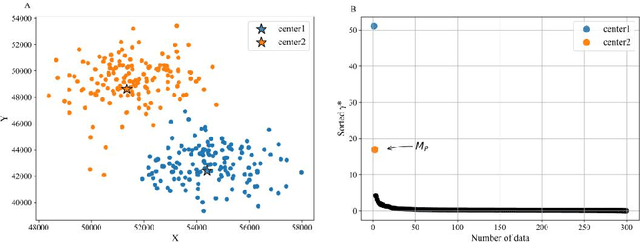
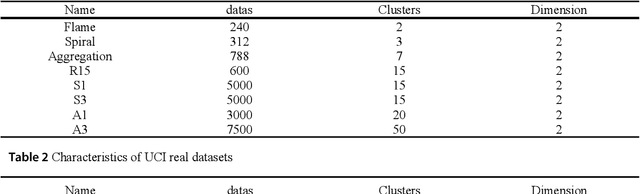
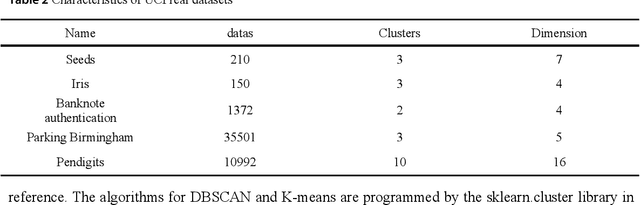
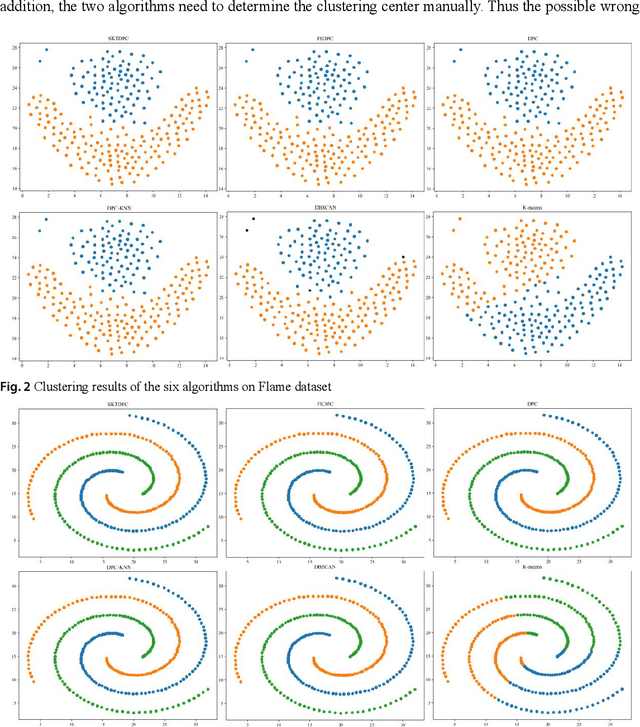
Density peaks clustering has become a nova of clustering algorithm because of its simplicity and practicality. However, there is one main drawback: it is time-consuming due to its high computational complexity. Herein, a density peaks clustering algorithm with sparse search and K-d tree is developed to solve this problem. Firstly, a sparse distance matrix is calculated by using K-d tree to replace the original full rank distance matrix, so as to accelerate the calculation of local density. Secondly, a sparse search strategy is proposed to accelerate the computation of relative-separation with the intersection between the set of k nearest neighbors and the set consisting of the data points with larger local density for any data point. Furthermore, a second-order difference method for decision values is adopted to determine the cluster centers adaptively. Finally, experiments are carried out on datasets with different distribution characteristics, by comparing with other five typical clustering algorithms. It is proved that the algorithm can effectively reduce the computational complexity. Especially for larger datasets, the efficiency is elevated more remarkably. Moreover, the clustering accuracy is also improved to a certain extent. Therefore, it can be concluded that the overall performance of the newly proposed algorithm is excellent.
DiSECt: A Differentiable Simulator for Parameter Inference and Control in Robotic Cutting
Mar 19, 2022
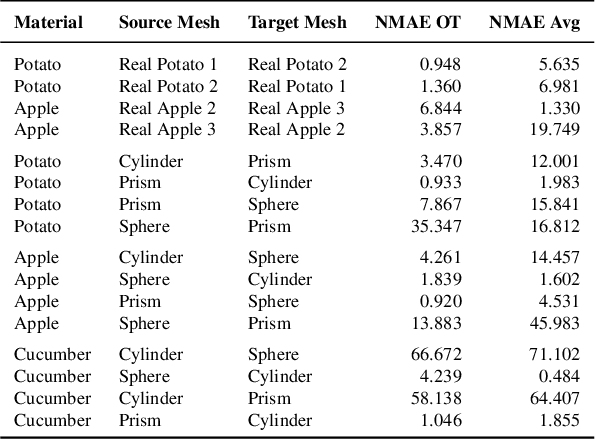

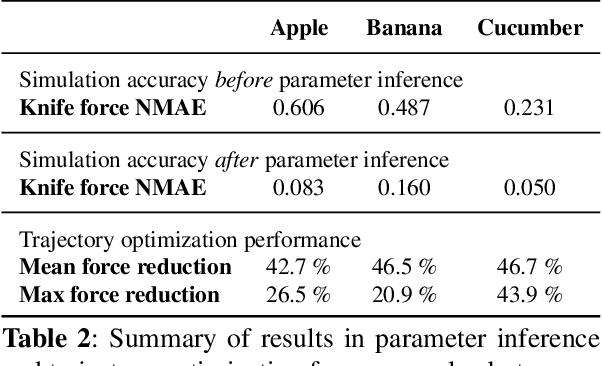
Robotic cutting of soft materials is critical for applications such as food processing, household automation, and surgical manipulation. As in other areas of robotics, simulators can facilitate controller verification, policy learning, and dataset generation. Moreover, differentiable simulators can enable gradient-based optimization, which is invaluable for calibrating simulation parameters and optimizing controllers. In this work, we present DiSECt: the first differentiable simulator for cutting soft materials. The simulator augments the finite element method (FEM) with a continuous contact model based on signed distance fields (SDF), as well as a continuous damage model that inserts springs on opposite sides of the cutting plane and allows them to weaken until zero stiffness, enabling crack formation. Through various experiments, we evaluate the performance of the simulator. We first show that the simulator can be calibrated to match resultant forces and deformation fields from a state-of-the-art commercial solver and real-world cutting datasets, with generality across cutting velocities and object instances. We then show that Bayesian inference can be performed efficiently by leveraging the differentiability of the simulator, estimating posteriors over hundreds of parameters in a fraction of the time of derivative-free methods. Next, we illustrate that control parameters in the simulation can be optimized to minimize cutting forces via lateral slicing motions. Finally, we conduct experiments on a real robot arm equipped with a slicing knife to infer simulation parameters from force measurements. By optimizing the slicing motion of the knife, we show on fruit cutting scenarios that the average knife force can be reduced by more than 40% compared to a vertical cutting motion. We publish code and additional materials on our project website at https://diff-cutting-sim.github.io.
ViT-HGR: Vision Transformer-based Hand Gesture Recognition from High Density Surface EMG Signals
Jan 25, 2022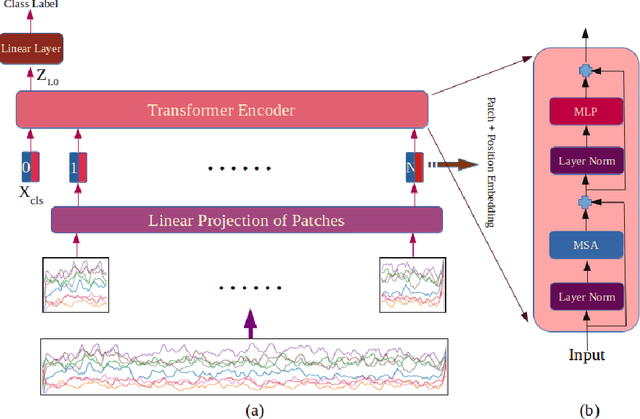
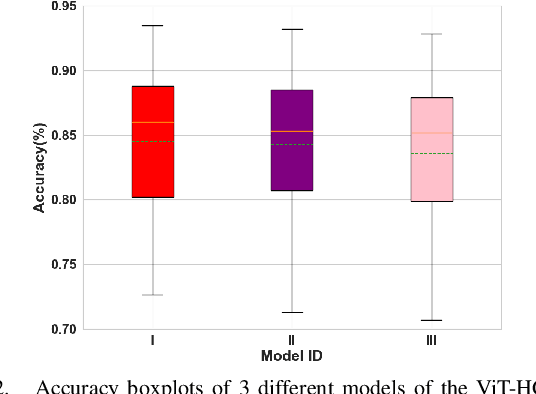
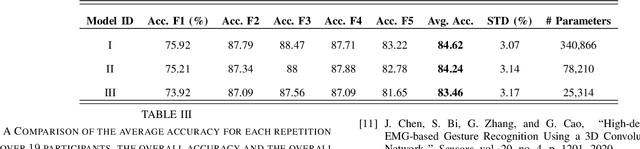
Recently, there has been a surge of significant interest on application of Deep Learning (DL) models to autonomously perform hand gesture recognition using surface Electromyogram (sEMG) signals. DL models are, however, mainly designed to be applied on sparse sEMG signals. Furthermore, due to their complex structure, typically, we are faced with memory constraints; require large training times and a large number of training samples, and; there is the need to resort to data augmentation and/or transfer learning. In this paper, for the first time (to the best of our knowledge), we investigate and design a Vision Transformer (ViT) based architecture to perform hand gesture recognition from High Density (HD-sEMG) signals. Intuitively speaking, we capitalize on the recent breakthrough role of the transformer architecture in tackling different complex problems together with its potential for employing more input parallelization via its attention mechanism. The proposed Vision Transformer-based Hand Gesture Recognition (ViT-HGR) framework can overcome the aforementioned training time problems and can accurately classify a large number of hand gestures from scratch without any need for data augmentation and/or transfer learning. The efficiency of the proposed ViT-HGR framework is evaluated using a recently-released HD-sEMG dataset consisting of 65 isometric hand gestures. Our experiments with 64-sample (31.25 ms) window size yield average test accuracy of 84.62 +/- 3.07%, where only 78, 210 number of parameters is utilized. The compact structure of the proposed ViT-based ViT-HGR framework (i.e., having significantly reduced number of trainable parameters) shows great potentials for its practical application for prosthetic control.
Shape-CD: Change-Point Detection in Time-Series Data with Shapes and Neurons
Jul 29, 2020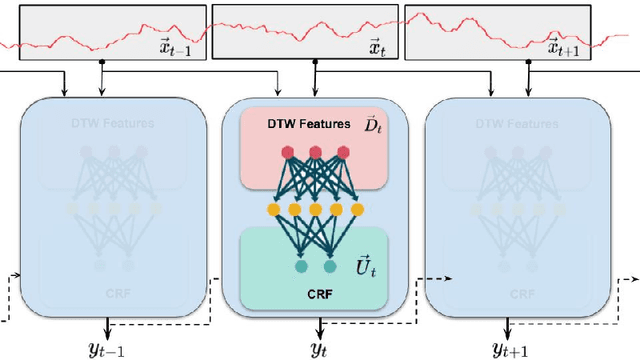
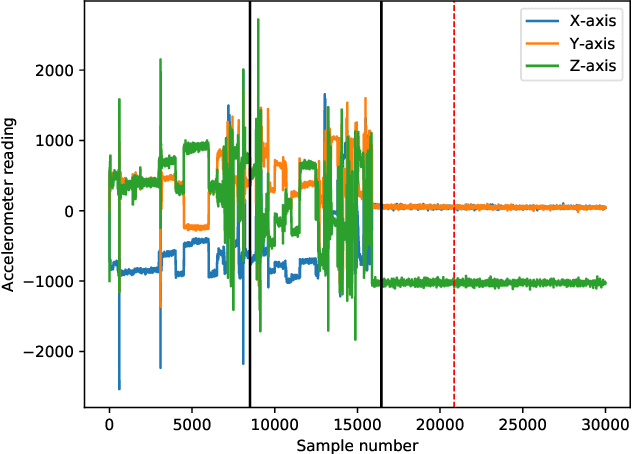
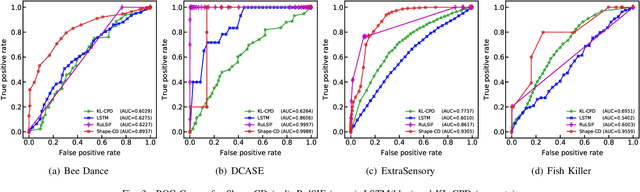
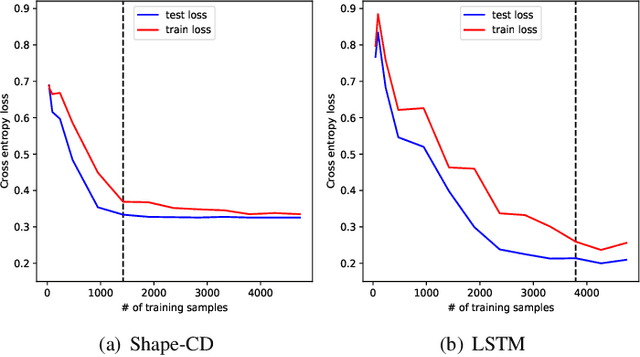
Change-point detection in a time series aims to discover the time points at which some unknown underlying physical process that generates the time-series data has changed. We found that existing approaches become less accurate when the underlying process is complex and generates large varieties of patterns in the time series. To address this shortcoming, we propose Shape-CD, a simple, fast, and accurate change point detection method. Shape-CD uses shape-based features to model the patterns and a conditional neural field to model the temporal correlations among the time regions. We evaluated the performance of Shape-CD using four highly dynamic time-series datasets, including the ExtraSensory dataset with up to 2000 classes. Shape-CD demonstrated improved accuracy (7-60% higher in AUC) and faster computational speed compared to existing approaches. Furthermore, the Shape-CD model consists of only hundreds of parameters and require less data to train than other deep supervised learning models.