 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Quality Assessment as Ranking with Listwise Rewards
Apr 27, 2026We reformulate explanation quality assessment as a ranking problem rather than a generation problem. Instead of optimizing models to produce a single "best" explanation token-by-token, we train reward models to discriminate among multiple candidate explanations and learn their relative quality. Concretely, we construct per-instance candidate sets with graded quality levels and train listwise and pairwise ranking models (ListNet, LambdaRank, RankNet) to preserve ordinal structure and avoid score compression typical of pointwise regression or binary preference objectives. We observe three findings: First, ranking losses consistently outperform regression on score separation across all domains tested. Second, the optimal ranking loss depends on data characteristics: listwise objectives excel with well-separated quality tiers, while pairwise methods are more robust to noisy natural annotations. Third, when trained on carefully curated and well-structured data, small encoder models can match models that are orders of magnitude larger, suggesting that data quality matters more than model scale. Finally, when used as rewards in policy optimization, ranking-based scores enable stable convergence in settings where regression-based rewards fail entirely. Code and data are available at: https://github.com/Tankiit/PPO_Learning_to_rank
Credal Concept Bottleneck Models for Epistemic-Aleatoric Uncertainty Decomposition
Apr 27, 2026Concept Bottleneck Models (CBMs) predict through human-interpretable concepts, but they typically output point concept probabilities that conflate epistemic uncertainty (reducible model underspecification) with aleatoric uncertainty (irreducible input ambiguity). This makes concept-level uncertainty hard to interpret and, more importantly, hard to act upon. We introduce CREDENCE (Credal Ensemble Concept Estimation), a CBM framework that decomposes concept uncertainty by construction. CREDENCE represents each concept as a credal prediction (a probability interval), derives epistemic uncertainty from disagreement across diverse concept heads, and estimates aleatoric uncertainty via a dedicated ambiguity output trained to match annotator disagreement when available. The resulting signals support prescriptive decisions: automate low-uncertainty cases, prioritize data collection for high-epistemic cases, route high-aleatoric cases to human review, and abstain when both are high. Across several tasks, we show that epistemic uncertainty is positively associated with prediction errors, whereas aleatoric uncertainty closely tracks annotator disagreement, providing guidance beyond error correlation. Our implementation is available at the following link: https://github.com/Tankiit/Credal_Sets/tree/ensemble-credal-cbm
Credal Concept Bottleneck Models: Structural Separation of Epistemic and Aleatoric Uncertainty
Feb 11, 2026Decomposing predictive uncertainty into epistemic (model ignorance) and aleatoric (data ambiguity) components is central to reliable decision making, yet most methods estimate both from the same predictive distribution. Recent empirical and theoretical results show these estimates are typically strongly correlated, so changes in predictive spread simultaneously affect both components and blur their semantics. We propose a credal-set formulation in which uncertainty is represented as a set of predictive distributions, so that epistemic and aleatoric uncertainty correspond to distinct geometric properties: the size of the set versus the noise within its elements. We instantiate this idea in a Variational Credal Concept Bottleneck Model with two disjoint uncertainty heads trained by disjoint objectives and non-overlapping gradient paths, yielding separation by construction rather than post hoc decomposition. Across multi-annotator benchmarks, our approach reduces the correlation between epistemic and aleatoric uncertainty by over an order of magnitude compared to standard methods, while improving the alignment of epistemic uncertainty with prediction error and aleatoric uncertainty with ground-truth ambiguity.
MODE: Multi-Objective Adaptive Coreset Selection
Dec 24, 2025We present Mode(Multi-Objective adaptive Data Efficiency), a framework that dynamically combines coreset selection strategies based on their evolving contribution to model performance. Unlike static methods, \mode adapts selection criteria to training phases: emphasizing class balance early, diversity during representation learning, and uncertainty at convergence. We show that MODE achieves (1-1/e)-approximation with O(n \log n) complexity and demonstrates competitive accuracy while providing interpretable insights into data utility evolution. Experiments show \mode reduces memory requirements
The STOIC2021 COVID-19 AI challenge: applying reusable training methodologies to private data
Jun 25, 2023Challenges drive the state-of-the-art of automated medical image analysis. The quantity of public training data that they provide can limit the performance of their solutions. Public access to the training methodology for these solutions remains absent. This study implements the Type Three (T3) challenge format, which allows for training solutions on private data and guarantees reusable training methodologies. With T3, challenge organizers train a codebase provided by the participants on sequestered training data. T3 was implemented in the STOIC2021 challenge, with the goal of predicting from a computed tomography (CT) scan whether subjects had a severe COVID-19 infection, defined as intubation or death within one month. STOIC2021 consisted of a Qualification phase, where participants developed challenge solutions using 2000 publicly available CT scans, and a Final phase, where participants submitted their training methodologies with which solutions were trained on CT scans of 9724 subjects. The organizers successfully trained six of the eight Final phase submissions. The submitted codebases for training and running inference were released publicly. The winning solution obtained an area under the receiver operating characteristic curve for discerning between severe and non-severe COVID-19 of 0.815. The Final phase solutions of all finalists improved upon their Qualification phase solutions.HSUXJM-TNZF9CHSUXJM-TNZF9C
Representation Learning with Information Theory for COVID-19 Detection
Jul 04, 2022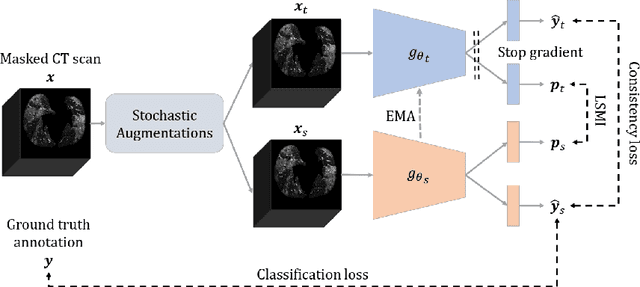
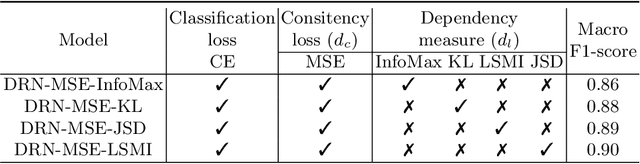
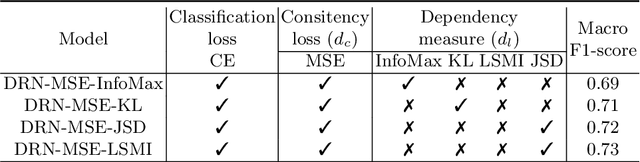
Successful data representation is a fundamental factor in machine learning based medical imaging analysis. Deep Learning (DL) has taken an essential role in robust representation learning. However, the inability of deep models to generalize to unseen data can quickly overfit intricate patterns. Thereby, we can conveniently implement strategies to aid deep models in discovering useful priors from data to learn their intrinsic properties. Our model, which we call a dual role network (DRN), uses a dependency maximization approach based on Least Squared Mutual Information (LSMI). The LSMI leverages dependency measures to ensure representation invariance and local smoothness. While prior works have used information theory measures like mutual information, known to be computationally expensive due to a density estimation step, our LSMI formulation alleviates the issues of intractable mutual information estimation and can be used to approximate it. Experiments on CT based COVID-19 Detection and COVID-19 Severity Detection benchmarks demonstrate the effectiveness of our method.
NLX-GPT: A Model for Natural Language Explanations in Vision and Vision-Language Tasks
Mar 09, 2022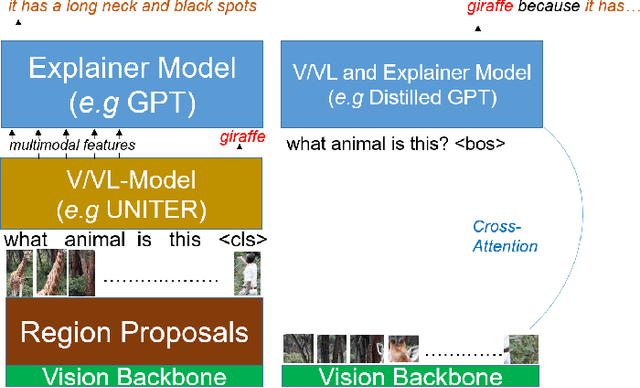


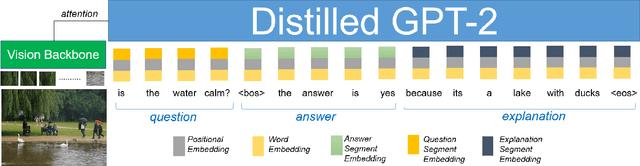
Natural language explanation (NLE) models aim at explaining the decision-making process of a black box system via generating natural language sentences which are human-friendly, high-level and fine-grained. Current NLE models explain the decision-making process of a vision or vision-language model (a.k.a., task model), e.g., a VQA model, via a language model (a.k.a., explanation model), e.g., GPT. Other than the additional memory resources and inference time required by the task model, the task and explanation models are completely independent, which disassociates the explanation from the reasoning process made to predict the answer. We introduce NLX-GPT, a general, compact and faithful language model that can simultaneously predict an answer and explain it. We first conduct pre-training on large scale data of image-caption pairs for general understanding of images, and then formulate the answer as a text prediction task along with the explanation. Without region proposals nor a task model, our resulting overall framework attains better evaluation scores, contains much less parameters and is 15$\times$ faster than the current SoA model. We then address the problem of evaluating the explanations which can be in many times generic, data-biased and can come in several forms. We therefore design 2 new evaluation measures: (1) explain-predict and (2) retrieval-based attack, a self-evaluation framework that requires no labels. Code is at: https://github.com/fawazsammani/nlxgpt.
Deep Matching Autoencoders
Nov 16, 2017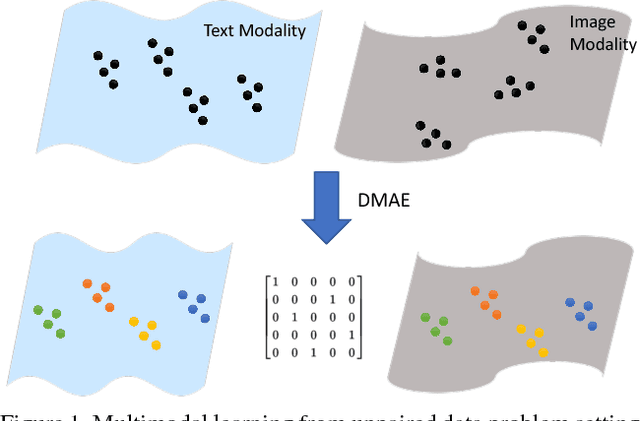
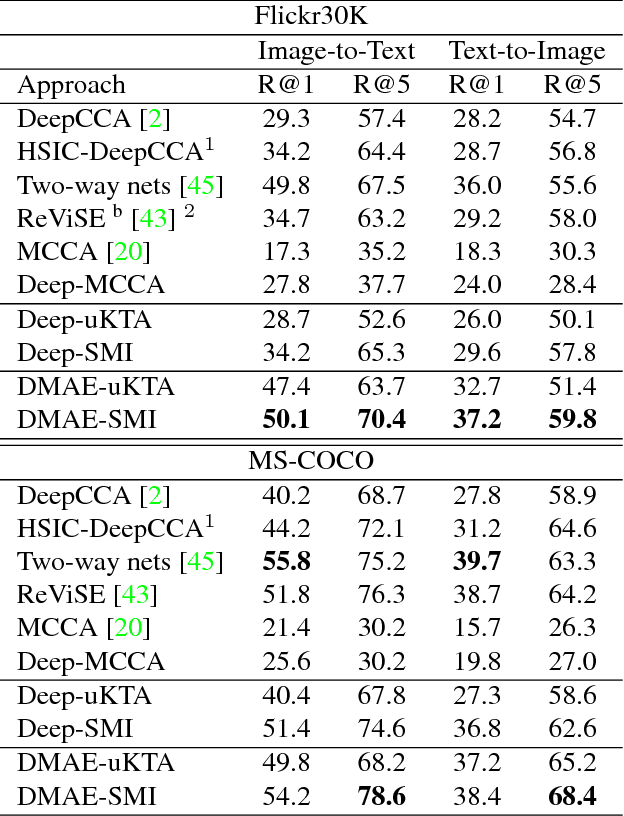
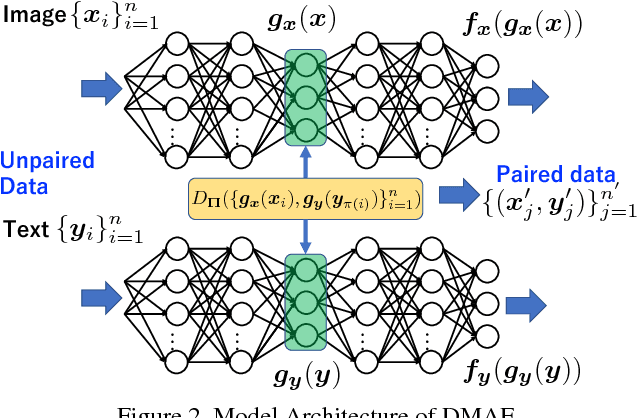
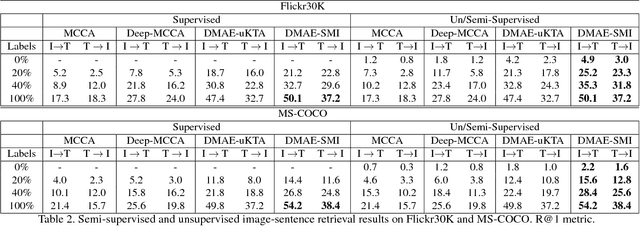
Increasingly many real world tasks involve data in multiple modalities or views. This has motivated the development of many effective algorithms for learning a common latent space to relate multiple domains. However, most existing cross-view learning algorithms assume access to paired data for training. Their applicability is thus limited as the paired data assumption is often violated in practice: many tasks have only a small subset of data available with pairing annotation, or even no paired data at all. In this paper we introduce Deep Matching Autoencoders (DMAE), which learn a common latent space and pairing from unpaired multi-modal data. Specifically we formulate this as a cross-domain representation learning and object matching problem. We simultaneously optimise parameters of representation learning auto-encoders and the pairing of unpaired multi-modal data. This framework elegantly spans the full regime from fully supervised, semi-supervised, and unsupervised (no paired data) multi-modal learning. We show promising results in image captioning, and on a new task that is uniquely enabled by our methodology: unsupervised classifier learning.