 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hierarchical Clustering using Auto-encoded Compact Representation for Time-series Analysis
Jan 11, 2021
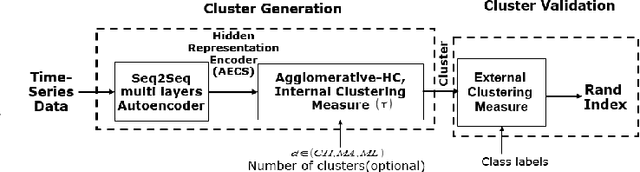
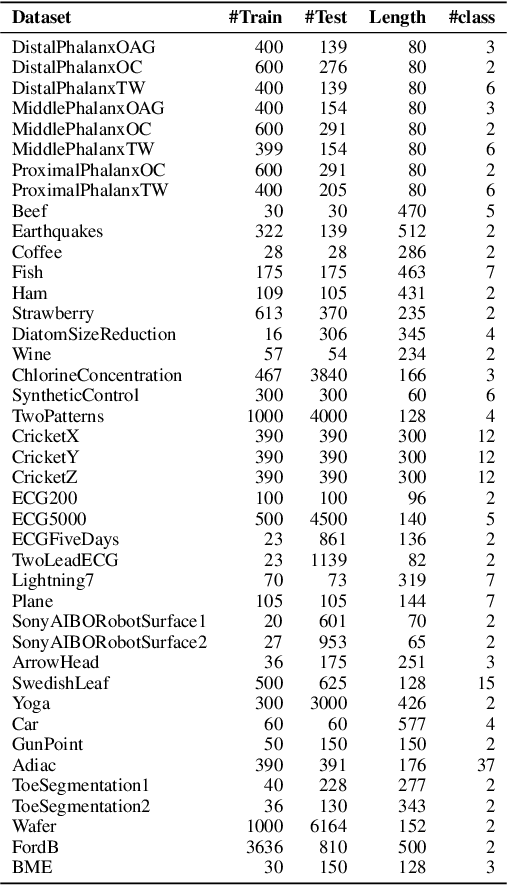
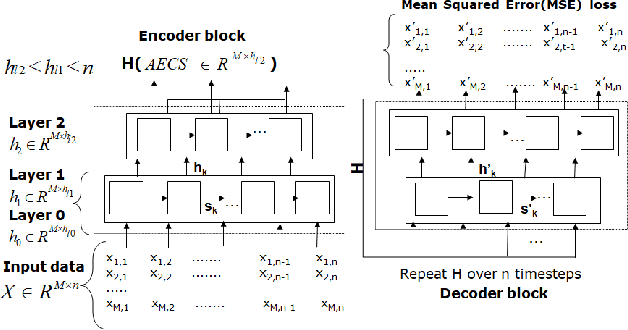
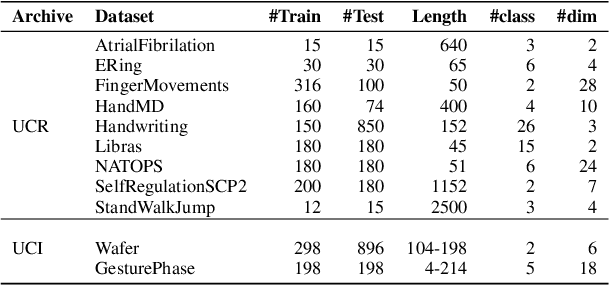
Getting a robust time-series clustering with best choice of distance measure and appropriate representation is always a challenge. We propose a novel mechanism to identify the clusters combining learned compact representation of time-series, Auto Encoded Compact Sequence (AECS) and hierarchical clustering approach. Proposed algorithm aims to address the large computing time issue of hierarchical clustering as learned latent representation AECS has a length much less than the original length of time-series and at the same time want to enhance its performance.Our algorithm exploits Recurrent Neural Network (RNN) based under complete Sequence to Sequence(seq2seq) autoencoder and agglomerative hierarchical clustering with a choice of best distance measure to recommend the best clustering. Our scheme selects the best distance measure and corresponding clustering for both univariate and multivariate time-series. We have experimented with real-world time-series from UCR and UCI archive taken from diverse application domains like health, smart-city, manufacturing etc. Experimental results show that proposed method not only produce close to benchmark results but also in some cases outperform the benchmark.
Greedy-GQ with Variance Reduction: Finite-time Analysis and Improved Complexity
Mar 30, 2021



Greedy-GQ is a value-based reinforcement learning (RL) algorithm for optimal control. Recently, the finite-time analysis of Greedy-GQ has been developed under linear function approximation and Markovian sampling, and the algorithm is shown to achieve an $\epsilon$-stationary point with a sample complexity in the order of $\mathcal{O}(\epsilon^{-3})$. Such a high sample complexity is due to the large variance induced by the Markovian samples. In this paper, we propose a variance-reduced Greedy-GQ (VR-Greedy-GQ) algorithm for off-policy optimal control. In particular, the algorithm applies the SVRG-based variance reduction scheme to reduce the stochastic variance of the two time-scale updates. We study the finite-time convergence of VR-Greedy-GQ under linear function approximation and Markovian sampling and show that the algorithm achieves a much smaller bias and variance error than the original Greedy-GQ. In particular, we prove that VR-Greedy-GQ achieves an improved sample complexity that is in the order of $\mathcal{O}(\epsilon^{-2})$. We further compare the performance of VR-Greedy-GQ with that of Greedy-GQ in various RL experiments to corroborate our theoretical findings.
Robotic Planning under Uncertainty in Spatiotemporal Environments in Expeditionary Science
Jun 03, 2022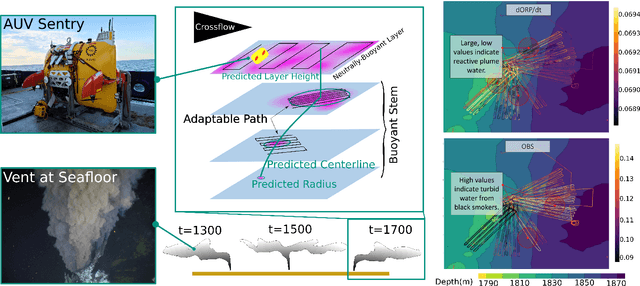
In the expeditionary sciences, spatiotemporally varying environments -- hydrothermal plumes, algal blooms, lava flows, or animal migrations -- are ubiquitous. Mobile robots are uniquely well-suited to study these dynamic, mesoscale natural environments. We formalize expeditionary science as a sequential decision-making problem, modeled using the language of partially-observable Markov decision processes (POMDPs). Solving the expeditionary science POMDP under real-world constraints requires efficient probabilistic modeling and decision-making in problems with complex dynamics and observational models. Previous work in informative path planning, adaptive sampling, and experimental design have shown compelling results, largely in static environments, using data-driven models and information-based rewards. However, these methodologies do not trivially extend to expeditionary science in spatiotemporal environments: they generally do not make use of scientific knowledge such as equations of state dynamics, they focus on information gathering as opposed to scientific task execution, and they make use of decision-making approaches that scale poorly to large, continuous problems with long planning horizons and real-time operational constraints. In this work, we discuss these and other challenges related to probabilistic modeling and decision-making in expeditionary science, and present some of our preliminary work that addresses these gaps. We ground our results in a real expeditionary science deployment of an autonomous underwater vehicle (AUV) in the deep ocean for hydrothermal vent discovery and characterization. Our concluding thoughts highlight remaining work to be done, and the challenges that merit consideration by the reinforcement learning and decision-making community.
Deployment of Energy-Efficient Deep Learning Models on Cortex-M based Microcontrollers using Deep Compression
May 20, 2022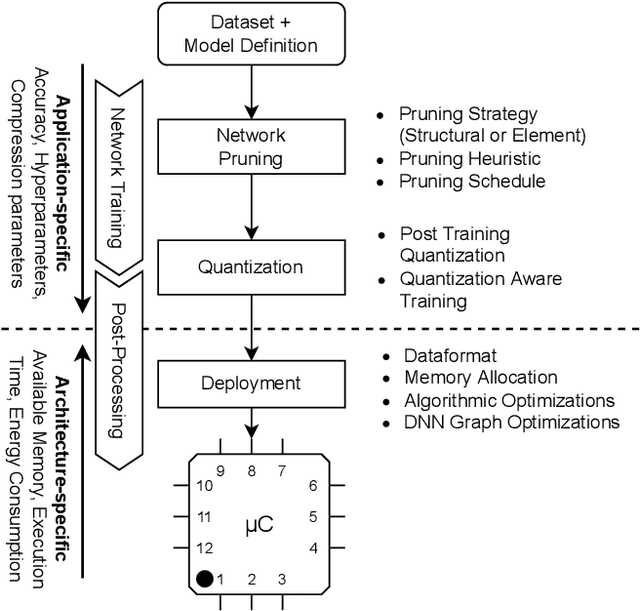
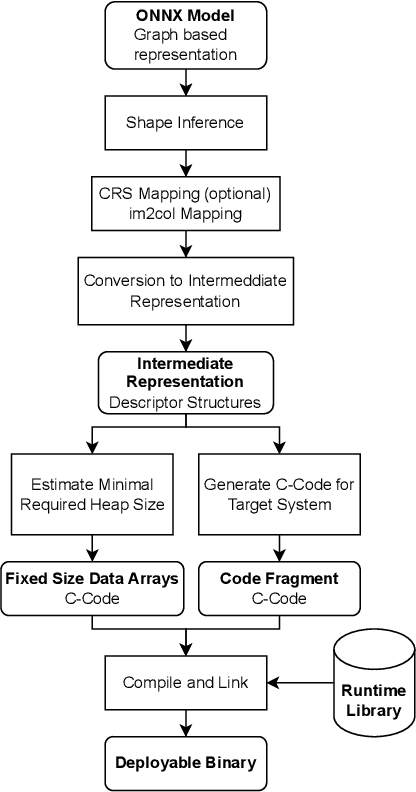

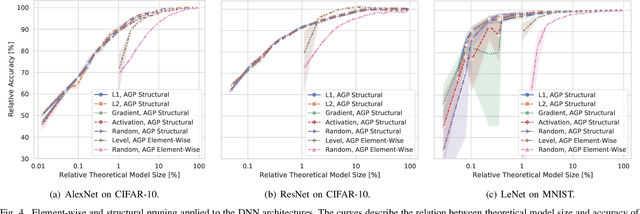
Large Deep Neural Networks (DNNs) are the backbone of today's artificial intelligence due to their ability to make accurate predictions when being trained on huge datasets. With advancing technologies, such as the Internet of Things, interpreting large quantities of data generated by sensors is becoming an increasingly important task. However, in many applications not only the predictive performance but also the energy consumption of deep learning models is of major interest. This paper investigates the efficient deployment of deep learning models on resource-constrained microcontroller architectures via network compression. We present a methodology for the systematic exploration of different DNN pruning, quantization, and deployment strategies, targeting different ARM Cortex-M based low-power systems. The exploration allows to analyze trade-offs between key metrics such as accuracy, memory consumption, execution time, and power consumption. We discuss experimental results on three different DNN architectures and show that we can compress them to below 10\% of their original parameter count before their predictive quality decreases. This also allows us to deploy and evaluate them on Cortex-M based microcontrollers.
Towards Lossless ANN-SNN Conversion under Ultra-Low Latency with Dual-Phase Optimization
May 16, 2022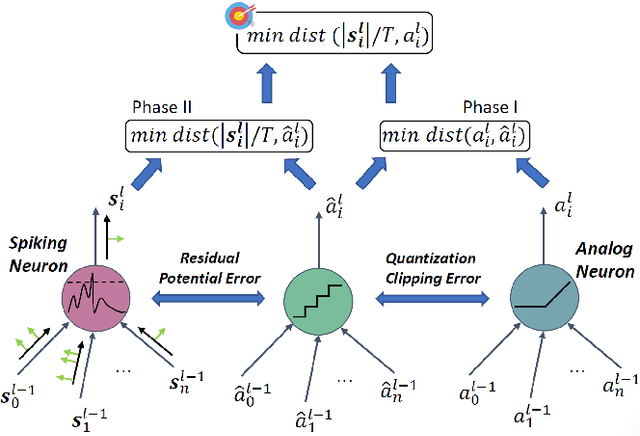
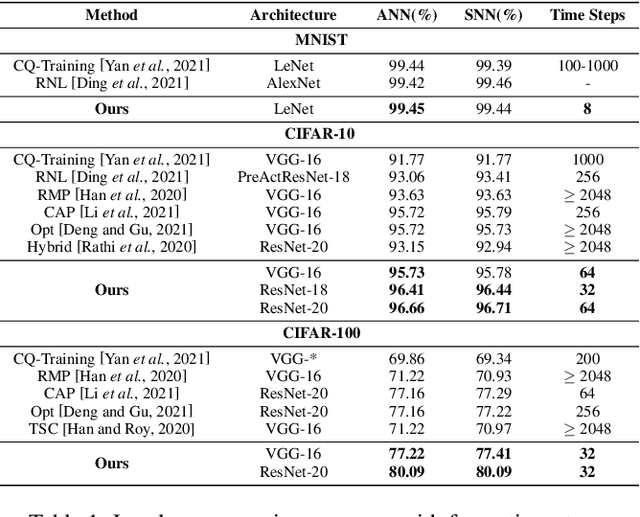
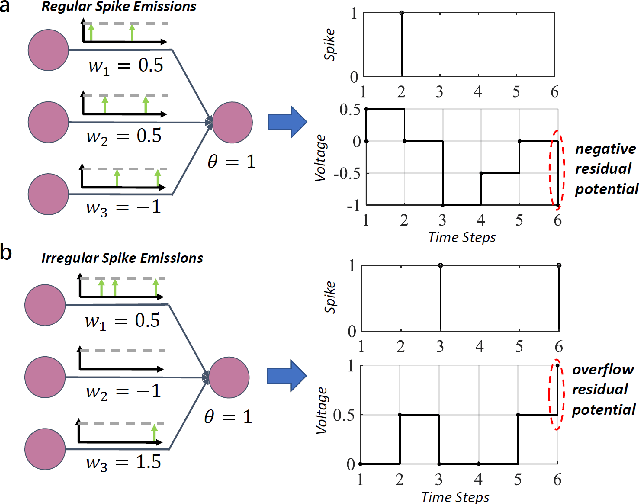
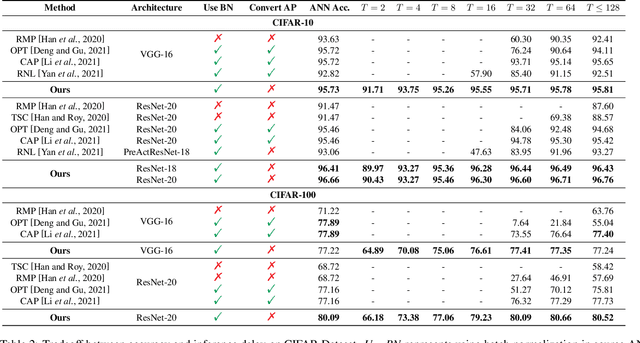
Spiking neural network (SNN) operating with asynchronous discrete events shows higher energy efficiency. A popular approach to implement deep SNNs is ANN-SNN conversion combining both efficient training in ANNs and efficient inference in SNNs. However, the previous works mostly required thousands of time steps to achieve lossless conversion. In this paper, we first identify the underlying cause, i.e., misrepresentation of the negative or overflow residual membrane potential in SNNs. Furthermore, we systematically analyze the conversion error between SNNs and ANNs, and then decompose it into three folds: quantization error, clipping error, and residual membrane potential representation error. With such insights, we propose a dual-phase conversion algorithm to minimize those errors. As a result, our model achieves SOTA in both accuracy and accuracy-delay tradeoff with deep architectures (ResNet and VGG net). Specifically, we report SOTA accuracy within 16$\times$ speedup compared with the latest results. Meanwhile, lossless conversion is performed with at least 2$\times$ faster reasoning performance.
Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
May 06, 2021
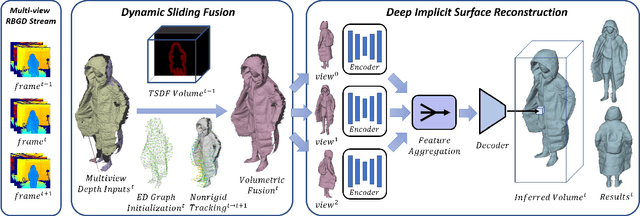

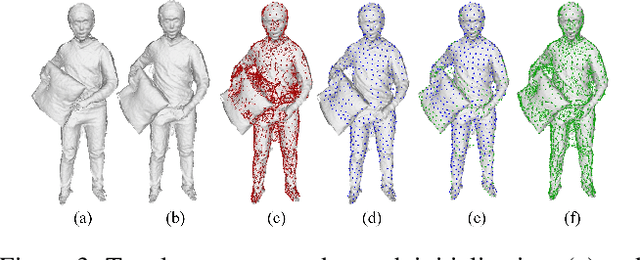
Human volumetric capture is a long-standing topic in computer vision and computer graphics. Although high-quality results can be achieved using sophisticated off-line systems, real-time human volumetric capture of complex scenarios, especially using light-weight setups, remains challenging. In this paper, we propose a human volumetric capture method that combines temporal volumetric fusion and deep implicit functions. To achieve high-quality and temporal-continuous reconstruction, we propose dynamic sliding fusion to fuse neighboring depth observations together with topology consistency. Moreover, for detailed and complete surface generation, we propose detail-preserving deep implicit functions for RGBD input which can not only preserve the geometric details on the depth inputs but also generate more plausible texturing results. Results and experiments show that our method outperforms existing methods in terms of view sparsity, generalization capacity, reconstruction quality, and run-time efficiency.
Reconstructing common latent input from time series with the mapper-coach network and error backpropagation
May 05, 2021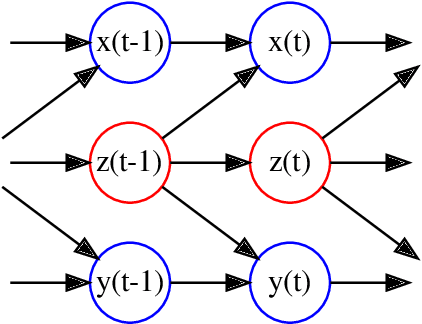
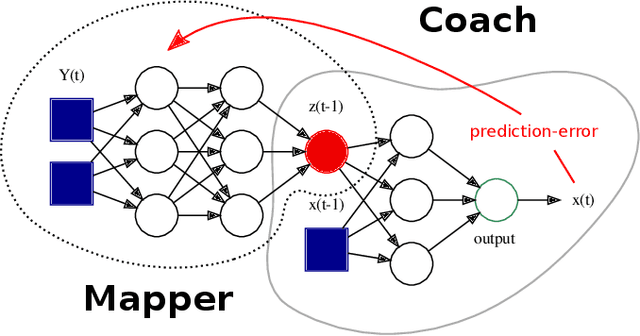
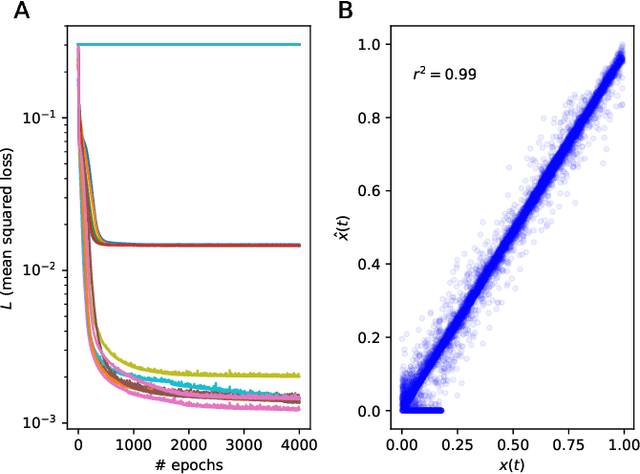
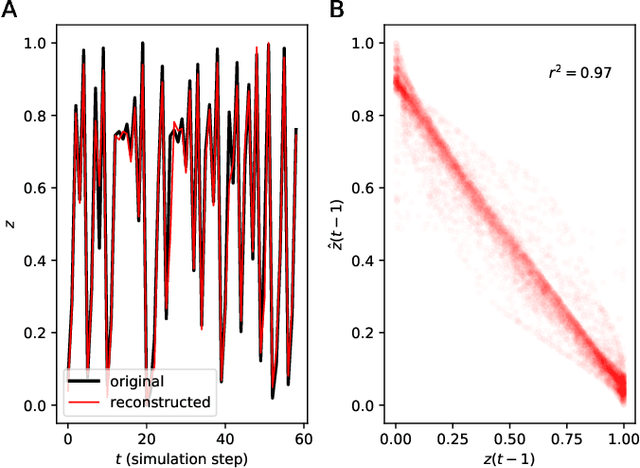
A two-module, feedforward neural network architecture called mapper-coach network has been introduced to reconstruct an unobserved, continuous latent variable input, driving two observed dynamical systems. The method has been demonstrated on time series generated by two chaotic logistic maps driven by a hidden third one. The network has been trained to predict one of the observed time series based on its own past and on the other observed time series by error-back propagation. It was shown, that after this prediction have been learned successfully, the activity of the bottleneck neuron, connecting the mapper and the coach module, correlates strongly with the latent common input variable. The method has the potential to reveal hidden components of dynamical systems, where experimental intervention is not possible.
AmbiPun: Generating Humorous Puns with Ambiguous Context
May 04, 2022
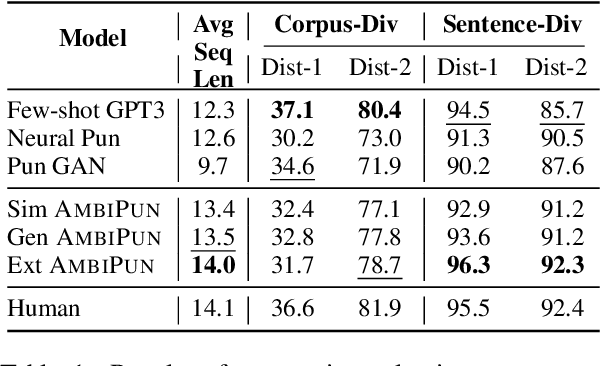

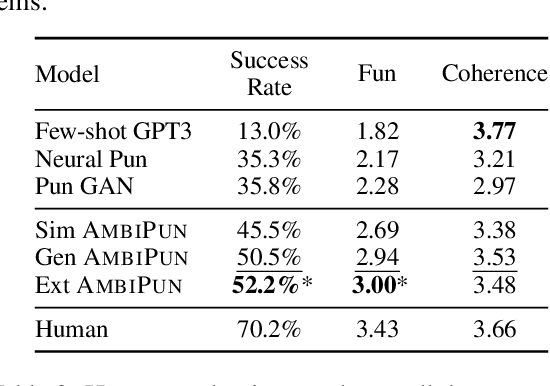
In this paper, we propose a simple yet effective way to generate pun sentences that does not require any training on existing puns. Our approach is inspired by humor theories that ambiguity comes from the context rather than the pun word itself. Given a pair of definitions of a pun word, our model first produces a list of related concepts through a reverse dictionary. We then utilize one-shot GPT3 to generate context words and then generate puns incorporating context words from both concepts. Human evaluation shows that our method successfully generates pun 52\% of the time, outperforming well-crafted baselines and the state-of-the-art models by a large margin.
DPSNN: A Differentially Private Spiking Neural Network
May 24, 2022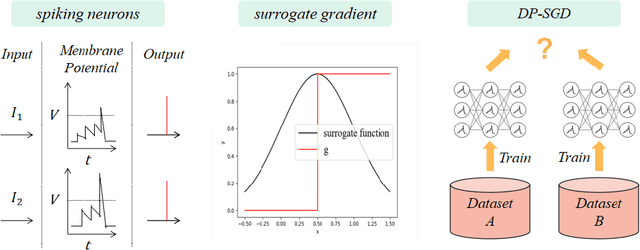

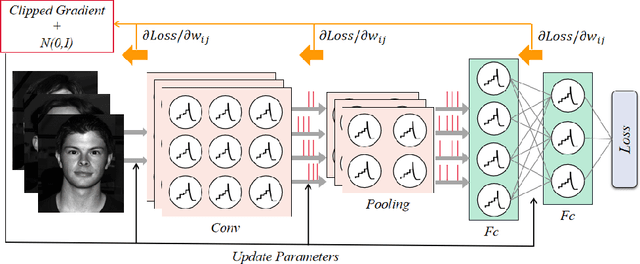
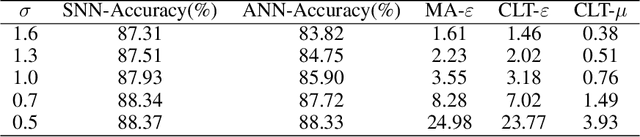
Privacy-preserving is a key problem for the machine learning algorithm. Spiking neural network (SNN) plays an important role in many domains, such as image classification, object detection, and speech recognition, but the study on the privacy protection of SNN is urgently needed. This study combines the differential privacy (DP) algorithm and SNN and proposes differentially private spiking neural network (DPSNN). DP injects noise into the gradient, and SNN transmits information in discrete spike trains so that our differentially private SNN can maintain strong privacy protection while still ensuring high accuracy. We conducted experiments on MNIST, Fashion-MNIST, and the face recognition dataset Extended YaleB. When the privacy protection is improved, the accuracy of the artificial neural network(ANN) drops significantly, but our algorithm shows little change in performance. Meanwhile, we analyzed different factors that affect the privacy protection of SNN. Firstly, the less precise the surrogate gradient is, the better the privacy protection of the SNN. Secondly, the Integrate-And-Fire (IF) neurons perform better than leaky Integrate-And-Fire (LIF) neurons. Thirdly, a large time window contributes more to privacy protection and performance.
Continuous Dynamic-NeRF: Spline-NeRF
Mar 25, 2022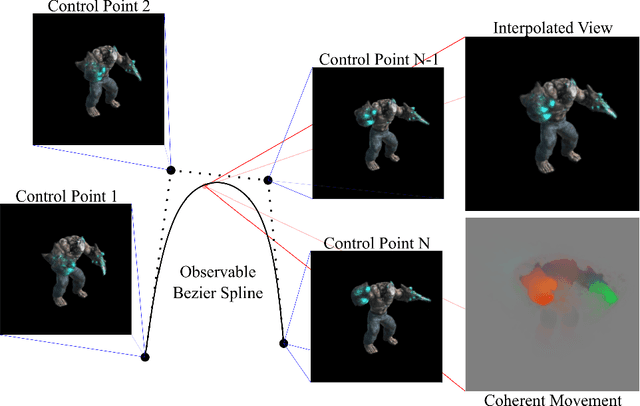
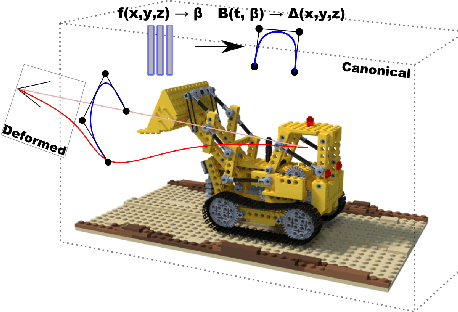
The problem of reconstructing continuous functions over time is important for problems such as reconstructing moving scenes, and interpolating between time steps. Previous approaches that use deep-learning rely on regularization to ensure that reconstructions are approximately continuous, which works well on short sequences. As sequence length grows, though, it becomes more difficult to regularize, and it becomes less feasible to learn only through regularization. We propose a new architecture for function reconstruction based on classical Bezier splines, which ensures $C^0$ and $C^1$-continuity, where $C^0$ continuity is that $\forall c:\lim\limits_{x\to c} f(x) = f(c)$, or more intuitively that there are no breaks at any point in the function. In order to demonstrate our architecture, we reconstruct dynamic scenes using Neural Radiance Fields, but hope it is clear that our approach is general and can be applied to a variety of problems. We recover a Bezier spline $B(\beta, t\in[0,1])$, parametrized by the control points $\beta$. Using Bezier splines ensures reconstructions have $C^0$ and $C^1$ continuity, allowing for guaranteed interpolation over time. We reconstruct $\beta$ with a multi-layer perceptron (MLP), blending machine learning with classical animation techniques. All code is available at https://github.com/JulianKnodt/nerf_atlas, and datasets are from prior work.