 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Denial-of-Service Attacks on Learned Image Compression
May 26, 2022

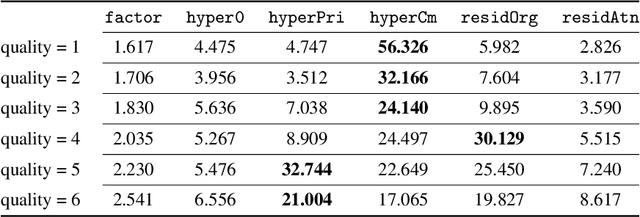
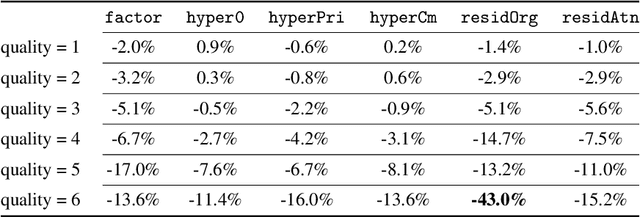

Deep learning techniques have shown promising results in image compression, with competitive bitrate and image reconstruction quality from compressed latent. However, while image compression has progressed towards higher peak signal-to-noise ratio (PSNR) and fewer bits per pixel (bpp), their robustness to corner-case images has never received deliberation. In this work, we, for the first time, investigate the robustness of image compression systems where imperceptible perturbation of input images can precipitate a significant increase in the bitrate of their compressed latent. To characterize the robustness of state-of-the-art learned image compression, we mount white and black-box attacks. Our results on several image compression models with various bitrate qualities show that they are surprisingly fragile, where the white-box attack achieves up to 56.326x and black-box 1.947x bpp change. To improve robustness, we propose a novel model which incorporates attention modules and a basic factorized entropy model, resulting in a promising trade-off between the PSNR/bpp ratio and robustness to adversarial attacks that surpasses existing learned image compressors.
Multi-Robot Active Mapping via Neural Bipartite Graph Matching
Apr 01, 2022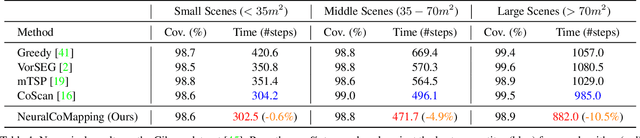
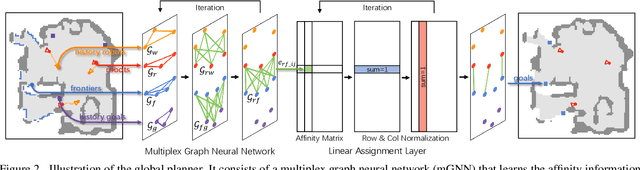
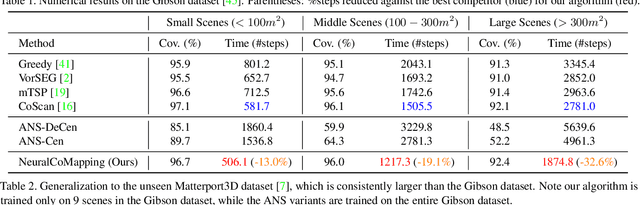
We study the problem of multi-robot active mapping, which aims for complete scene map construction in minimum time steps. The key to this problem lies in the goal position estimation to enable more efficient robot movements. Previous approaches either choose the frontier as the goal position via a myopic solution that hinders the time efficiency, or maximize the long-term value via reinforcement learning to directly regress the goal position, but does not guarantee the complete map construction. In this paper, we propose a novel algorithm, namely NeuralCoMapping, which takes advantage of both approaches. We reduce the problem to bipartite graph matching, which establishes the node correspondences between two graphs, denoting robots and frontiers. We introduce a multiplex graph neural network (mGNN) that learns the neural distance to fill the affinity matrix for more effective graph matching. We optimize the mGNN with a differentiable linear assignment layer by maximizing the long-term values that favor time efficiency and map completeness via reinforcement learning. We compare our algorithm with several state-of-the-art multi-robot active mapping approaches and adapted reinforcement-learning baselines. Experimental results demonstrate the superior performance and exceptional generalization ability of our algorithm on various indoor scenes and unseen number of robots, when only trained with 9 indoor scenes.
Placement and Resource Allocation of Wireless-Powered Multiantenna UAV for Energy-Efficient Multiuser NOMA
Apr 20, 2022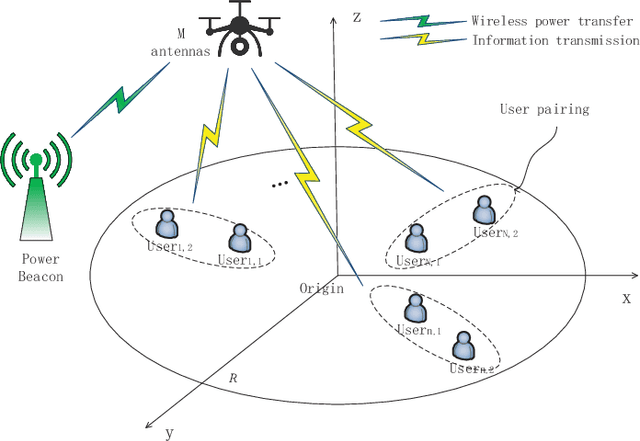
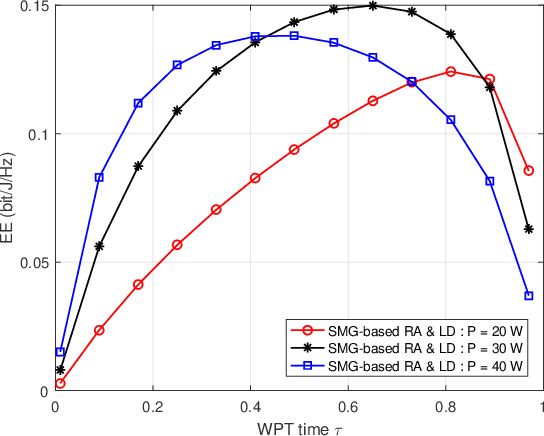
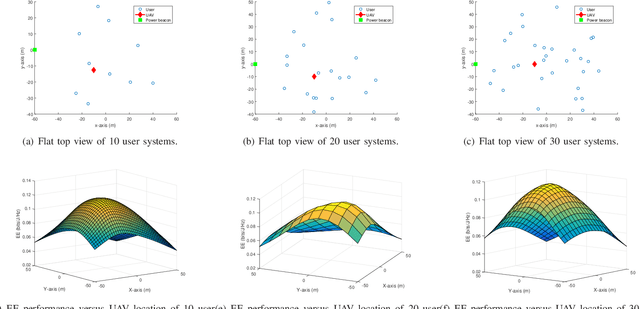
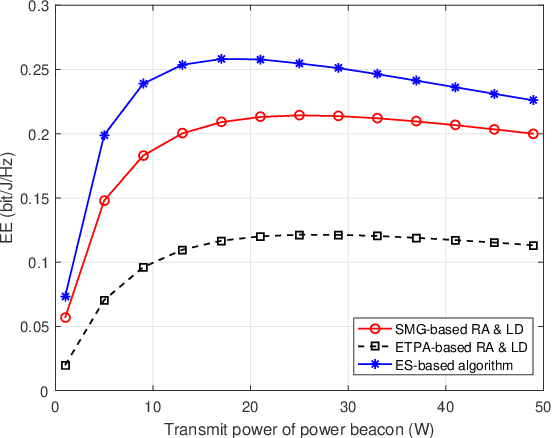
This paper investigates a new downlink nonorthogonal multiple access (NOMA) system, where a multiantenna unmanned aerial vehicle (UAV) is powered by wireless power transfer (WPT) and serves as the base station for multiple pairs of ground users (GUs) running NOMA in each pair. An energy efficiency (EE) maximization problem is formulated to jointly optimize the WPT time and the placement for the UAV, and the allocation of the UAV's transmit power between different NOMA user pairs and within each pair. To efficiently solve this nonconvex problem, we decompose the problem into three subproblems using block coordinate descent. For the subproblem of intra-pair power allocation within each NOMA user pair, we construct a supermodular game with confirmed convergence to a Nash equilibrium. Given the intra-pair power allocation, successive convex approximation is applied to convexify and solve the subproblem of WPT time allocation and inter-pair power allocation between the user pairs. Finally, we solve the subproblem of UAV placement by using the Lagrange multiplier method. Simulations show that our approach can substantially outperform its alternatives that do not use NOMA and WPT techniques or that do not optimize the UAV location.
Unified Recurrence Modeling for Video Action Anticipation
Jun 02, 2022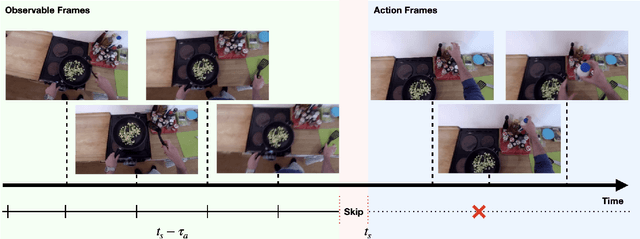
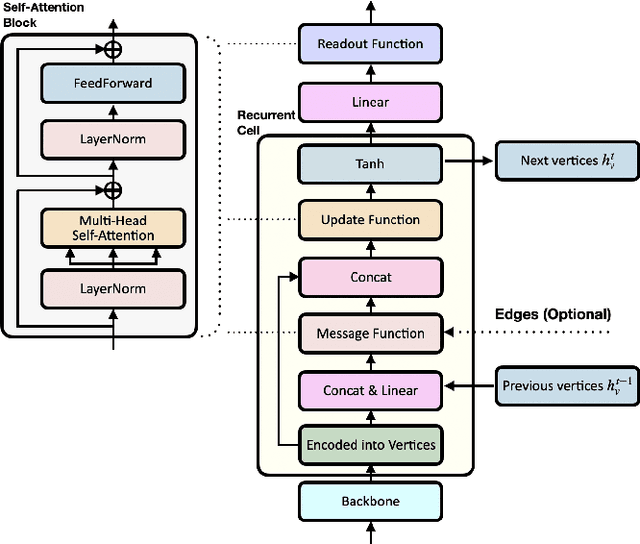
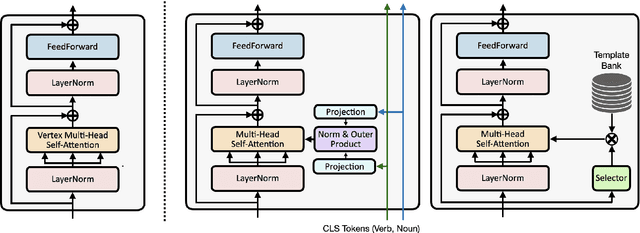
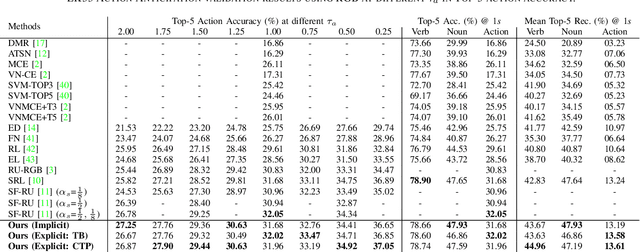
Forecasting future events based on evidence of current conditions is an innate skill of human beings, and key for predicting the outcome of any decision making. In artificial vision for example, we would like to predict the next human action before it happens, without observing the future video frames associated to it. Computer vision models for action anticipation are expected to collect the subtle evidence in the preamble of the target actions. In prior studies recurrence modeling often leads to better performance, the strong temporal inference is assumed to be a key element for reasonable prediction. To this end, we propose a unified recurrence modeling for video action anticipation via message passing framework. The information flow in space-time can be described by the interaction between vertices and edges, and the changes of vertices for each incoming frame reflects the underlying dynamics. Our model leverages self-attention as the building blocks for each of the message passing functions. In addition, we introduce different edge learning strategies that can be end-to-end optimized to gain better flexibility for the connectivity between vertices. Our experimental results demonstrate that our proposed method outperforms previous works on the large-scale EPIC-Kitchen dataset.
Transformer with Memory Replay
May 19, 2022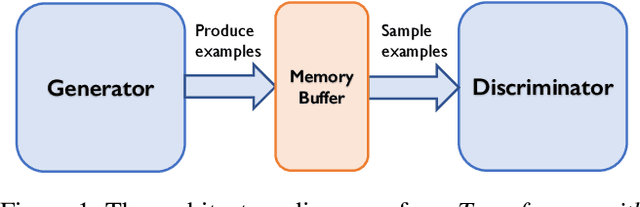

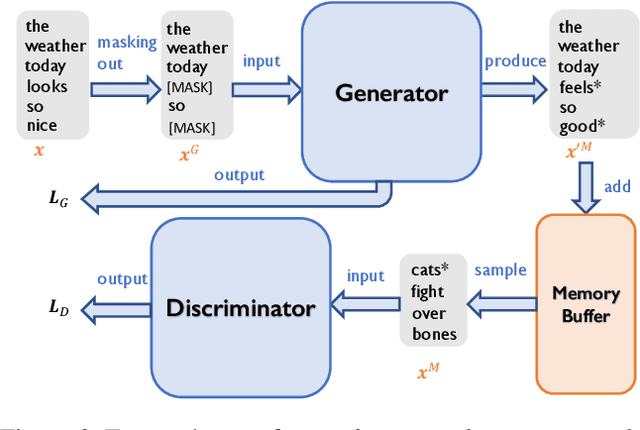
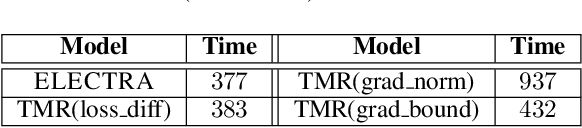
Transformers achieve state-of-the-art performance for natural language processing tasks by pre-training on large-scale text corpora. They are extremely compute-intensive and have very high sample complexity. Memory replay is a mechanism that remembers and reuses past examples by saving to and replaying from a memory buffer. It has been successfully used in reinforcement learning and GANs due to better sample efficiency. In this paper, we propose \emph{Transformer with Memory Replay} (TMR), which integrates memory replay with transformer, making transformer more sample-efficient. Experiments on GLUE and SQuAD benchmark datasets show that Transformer with Memory Replay achieves at least $1\%$ point increase compared to the baseline transformer model when pretrained with the same number of examples. Further, by adopting a careful design that reduces the wall-clock time overhead of memory replay, we also empirically achieve a better runtime efficiency.
Spikemax: Spike-based Loss Methods for Classification
May 19, 2022



Spiking Neural Networks~(SNNs) are a promising research paradigm for low power edge-based computing. Recent works in SNN backpropagation has enabled training of SNNs for practical tasks. However, since spikes are binary events in time, standard loss formulations are not directly compatible with spike output. As a result, current works are limited to using mean-squared loss of spike count. In this paper, we formulate the output probability interpretation from the spike count measure and introduce spike-based negative log-likelihood measure which are more suited for classification tasks especially in terms of the energy efficiency and inference latency. We compare our loss measures with other existing alternatives and evaluate using classification performances on three neuromorphic benchmark datasets: NMNIST, DVS Gesture and N-TIDIGITS18. In addition, we demonstrate state of the art performances on these datasets, achieving faster inference speed and less energy consumption.
An Improved Deep Convolutional Neural Network by Using Hybrid Optimization Algorithms to Detect and Classify Brain Tumor Using Augmented MRI Images
Jun 08, 2022Automated brain tumor detection is becoming a highly considerable medical diagnosis research. In recent medical diagnoses, detection and classification are highly considered to employ machine learning and deep learning techniques. Nevertheless, the accuracy and performance of current models need to be improved for suitable treatments. In this paper, an improvement in deep convolutional learning is ensured by adopting enhanced optimization algorithms, Thus, Deep Convolutional Neural Network (DCNN) based on improved Harris Hawks Optimization (HHO), called G-HHO has been considered. This hybridization features Grey Wolf Optimization (GWO) and HHO to give better results, limiting the convergence rate and enhancing performance. Moreover, Otsu thresholding is adopted to segment the tumor portion that emphasizes brain tumor detection. Experimental studies are conducted to validate the performance of the suggested method on a total number of 2073 augmented MRI images. The technique's performance was ensured by comparing it with the nine existing algorithms on huge augmented MRI images in terms of accuracy, precision, recall, f-measure, execution time, and memory usage. The performance comparison shows that the DCNN-G-HHO is much more successful than existing methods, especially on a scoring accuracy of 97%. Additionally, the statistical performance analysis indicates that the suggested approach is faster and utilizes less memory at identifying and categorizing brain tumor cancers on the MR images. The implementation of this validation is conducted on the Python platform. The relevant codes for the proposed approach are available at: https://github.com/bryarahassan/DCNN-G-HHO.
Continuously-Tempered PDMP Samplers
May 29, 2022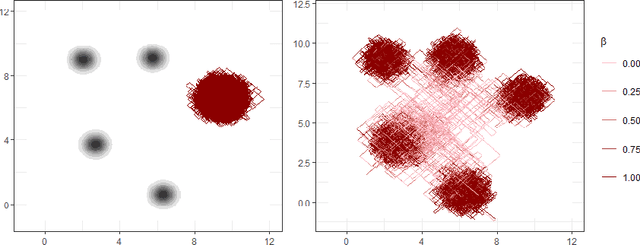
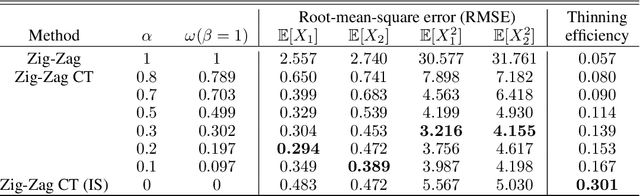
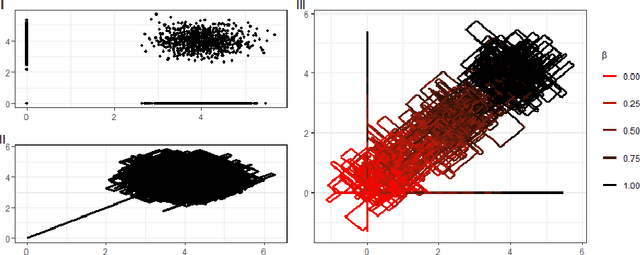
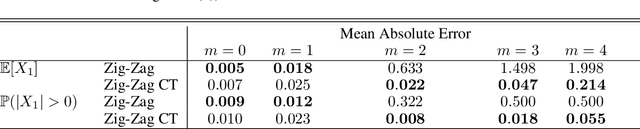
New sampling algorithms based on simulating continuous-time stochastic processes called piece-wise deterministic Markov processes (PDMPs) have shown considerable promise. However, these methods can struggle to sample from multi-modal or heavy-tailed distributions. We show how tempering ideas can improve the mixing of PDMPs in such cases. We introduce an extended distribution defined over the state of the posterior distribution and an inverse temperature, which interpolates between a tractable distribution when the inverse temperature is 0 and the posterior when the inverse temperature is 1. The marginal distribution of the inverse temperature is a mixture of a continuous distribution on [0,1) and a point mass at 1: which means that we obtain samples when the inverse temperature is 1, and these are draws from the posterior, but sampling algorithms will also explore distributions at lower temperatures which will improve mixing. We show how PDMPs, and particularly the Zig-Zag sampler, can be implemented to sample from such an extended distribution. The resulting algorithm is easy to implement and we show empirically that it can outperform existing PDMP-based samplers on challenging multimodal posteriors.
Letters From the Past: Modeling Historical Sound Change Through Diachronic Character Embeddings
May 17, 2022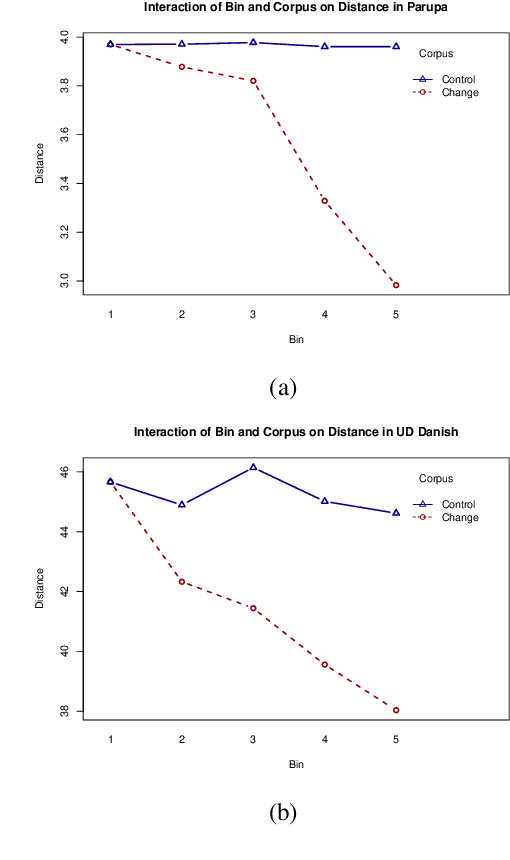
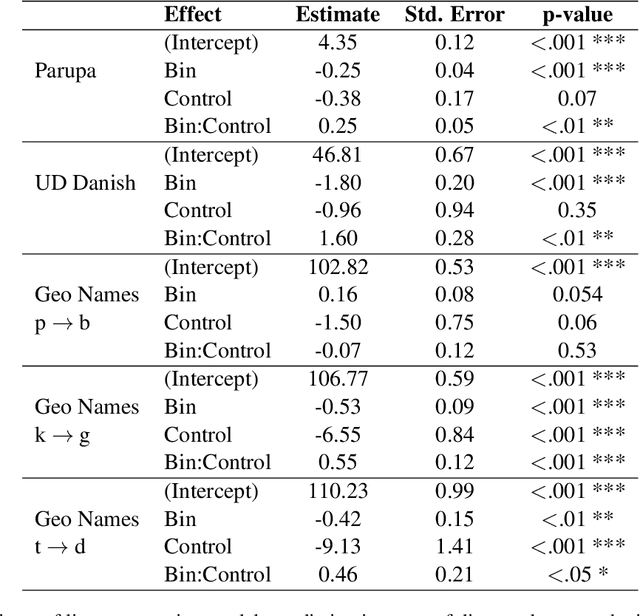
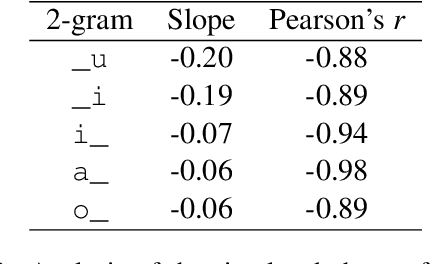
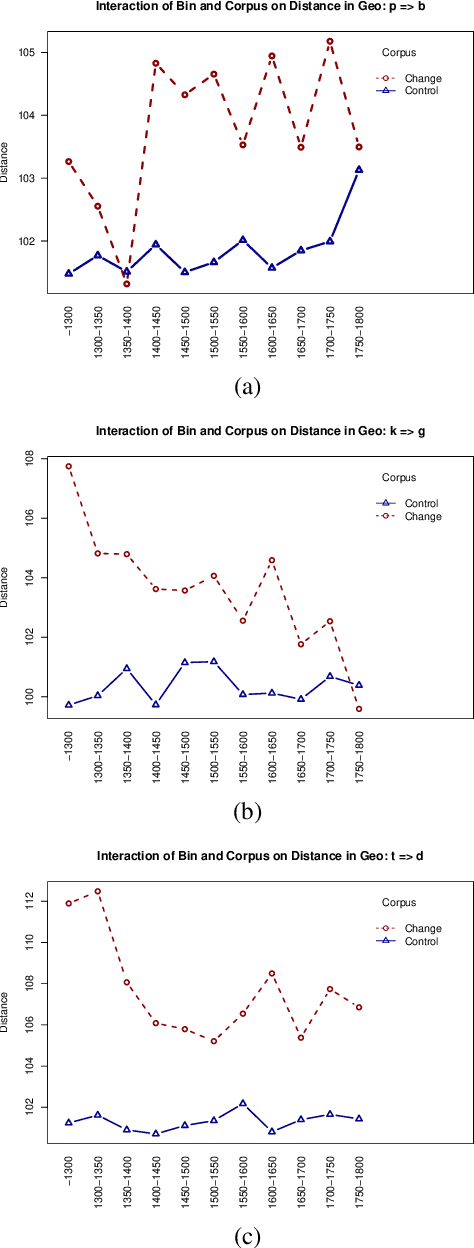
While a great deal of work has been done on NLP approaches to lexical semantic change detection, other aspects of language change have received less attention from the NLP community. In this paper, we address the detection of sound change through historical spelling. We propose that a sound change can be captured by comparing the relative distance through time between their distributions using PPMI character embeddings. We verify this hypothesis in synthetic data and then test the method's ability to trace the well-known historical change of lenition of plosives in Danish historical sources. We show that the models are able to identify several of the changes under consideration and to uncover meaningful contexts in which they appeared. The methodology has the potential to contribute to the study of open questions such as the relative chronology of sound shifts and their geographical distribution.
fairlib: A Unified Framework for Assessing and Improving Classification Fairness
May 04, 2022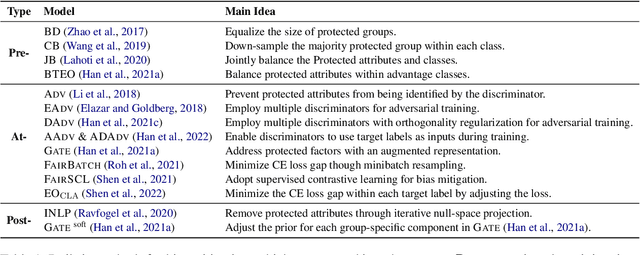
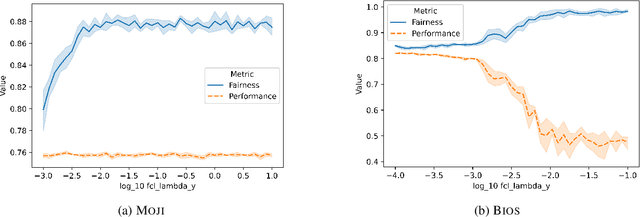
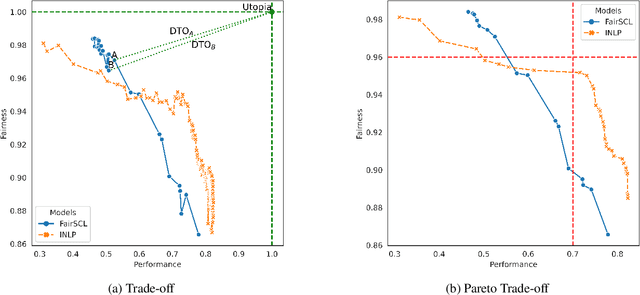
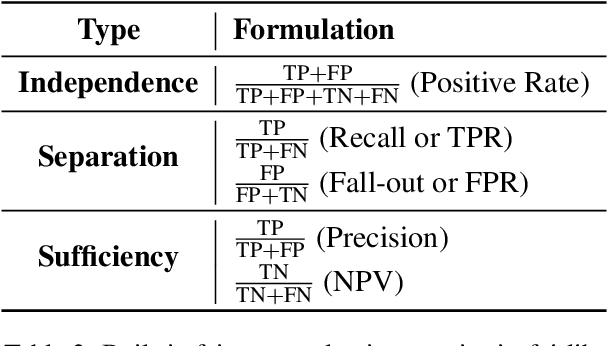
This paper presents fairlib, an open-source framework for assessing and improving classification fairness. It provides a systematic framework for quickly reproducing existing baseline models, developing new methods, evaluating models with different metrics, and visualizing their results. Its modularity and extensibility enable the framework to be used for diverse types of inputs, including natural language, images, and audio. In detail, we implement 14 debiasing methods, including pre-processing, at-training-time, and post-processing approaches. The built-in metrics cover the most commonly used fairness criterion and can be further generalized and customized for fairness evaluation.