 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLetters From the Past: Modeling Historical Sound Change Through Diachronic Character Embeddings
May 17, 2022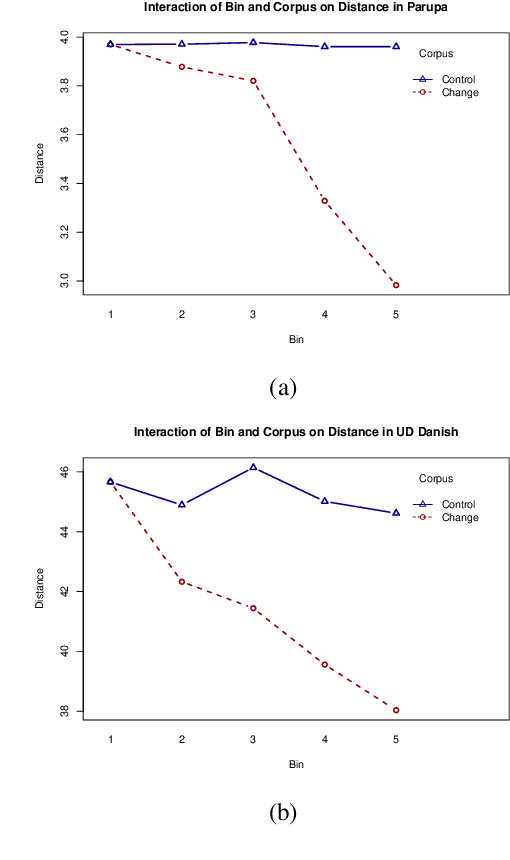
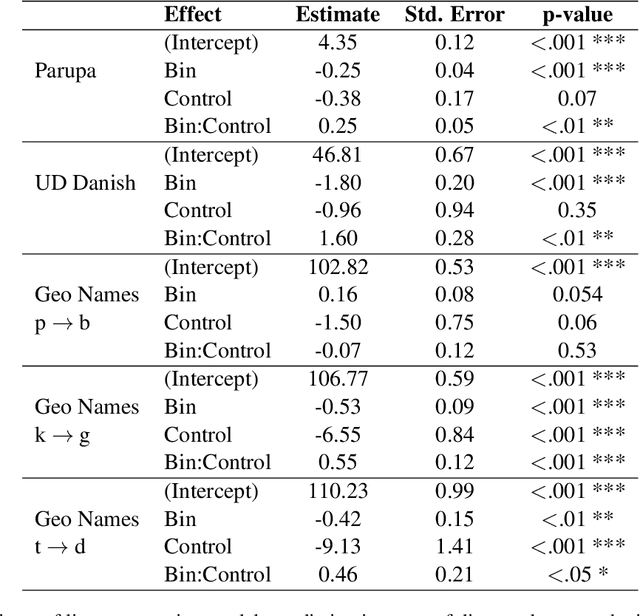
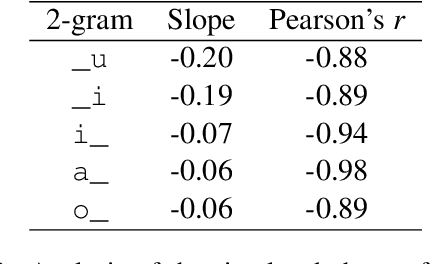
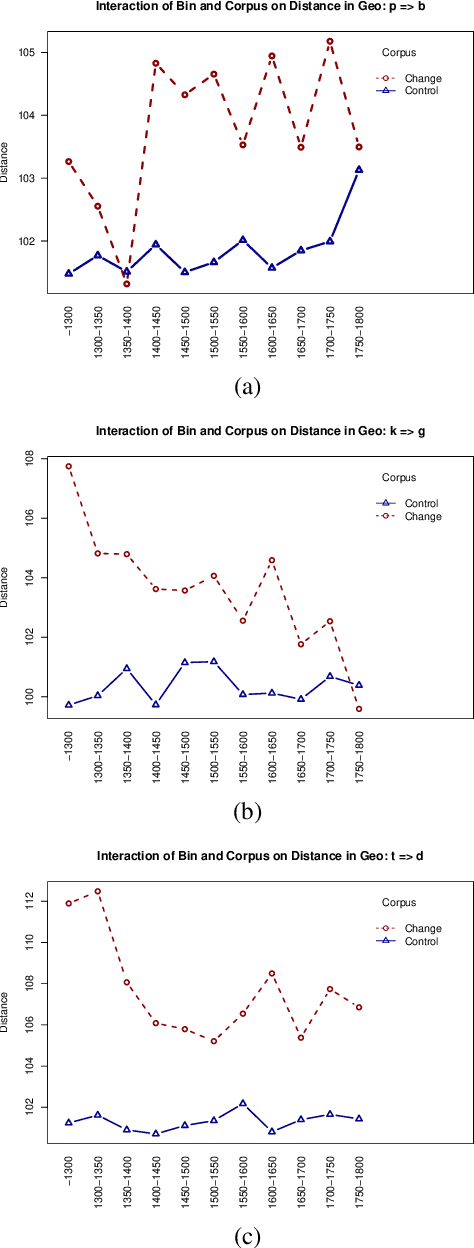
While a great deal of work has been done on NLP approaches to lexical semantic change detection, other aspects of language change have received less attention from the NLP community. In this paper, we address the detection of sound change through historical spelling. We propose that a sound change can be captured by comparing the relative distance through time between their distributions using PPMI character embeddings. We verify this hypothesis in synthetic data and then test the method's ability to trace the well-known historical change of lenition of plosives in Danish historical sources. We show that the models are able to identify several of the changes under consideration and to uncover meaningful contexts in which they appeared. The methodology has the potential to contribute to the study of open questions such as the relative chronology of sound shifts and their geographical distribution.
Face2Text: Collecting an Annotated Image Description Corpus for the Generation of Rich Face Descriptions
Mar 10, 2018
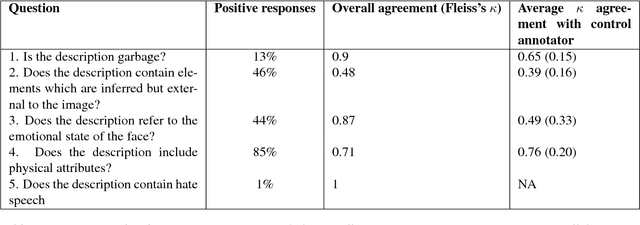
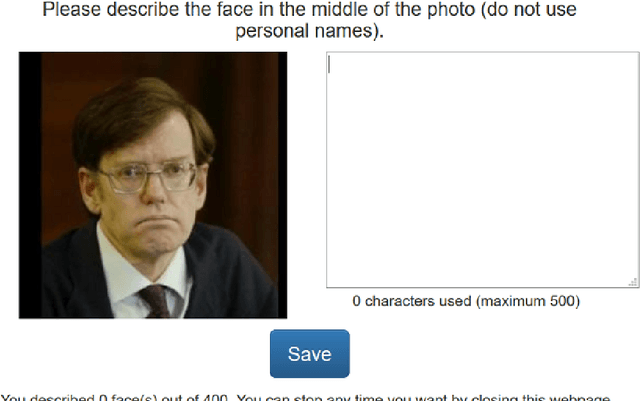
The past few years have witnessed renewed interest in NLP tasks at the interface between vision and language. One intensively-studied problem is that of automatically generating text from images. In this paper, we extend this problem to the more specific domain of face description. Unlike scene descriptions, face descriptions are more fine-grained and rely on attributes extracted from the image, rather than objects and relations. Given that no data exists for this task, we present an ongoing crowdsourcing study to collect a corpus of descriptions of face images taken `in the wild'. To gain a better understanding of the variation we find in face description and the possible issues that this may raise, we also conducted an annotation study on a subset of the corpus. Primarily, we found descriptions to refer to a mixture of attributes, not only physical, but also emotional and inferential, which is bound to create further challenges for current image-to-text methods.