 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbig-DS: A Benchmark for Task-Framing Ambiguity in Data-Science Agents
May 10, 2026As data-science agents shift from co-pilots to auto-pilots, silent misframing becomes a critical failure mode. Agents quietly commit to plausible but unintended task framings, producing clean, executable artifacts that hide their incorrect assessment of the task. Existing benchmarks score whether the pipeline runs, ignoring whether the agent recognized the task was underspecified. We introduce Ambig-DS, two diagnostic suites: one for prediction-target ambiguity (Ambig-DS-Target, 51 tasks built on DSBench, a tabular modeling benchmark) and one for evaluation-objective ambiguity (Ambig-DS-Objective, 61 tasks built on MLE-bench, a Kaggle-style ML competition benchmark), constructed so that scoring uses each source benchmark's original evaluator. For every task we pair the original, fully specified version with an ambiguous variant produced by controlled edits; a human-and-LLM verification pipeline confirms each variant admits multiple plausible interpretations with decision-relevant consequences. The suites are analyzed independently and ambiguity lowers performance in both. Across five agents spanning efficient to frontier-class models, we find in our controlled diagnostic setting: (i) failures are silent commitments: wrong-target submissions on Target, wrong-metric or non-committal baseline submissions on Objective, rather than execution errors; (ii) allowing the agent to ask one clarifying question recovers much of the loss under idealized conditions, suggesting missing framing information drives a substantial part of the observed degradation; but (iii) agents cannot reliably tell when to use it: permissive prompts induce over-asking on clear tasks, while conservative prompts induce silent defaulting on ambiguous ones. Recognizing target and objective underspecification, not pipeline execution, is the bottleneck missing from standard DS-agent evaluations.
Letters From the Past: Modeling Historical Sound Change Through Diachronic Character Embeddings
May 17, 2022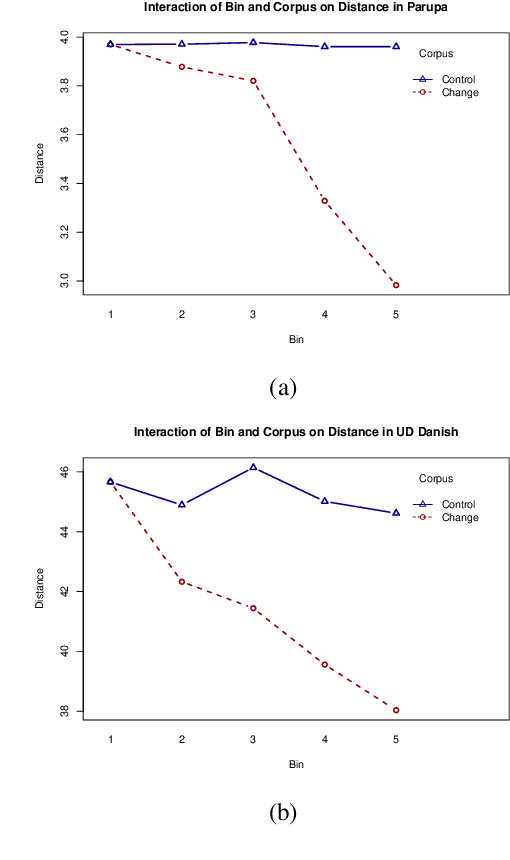
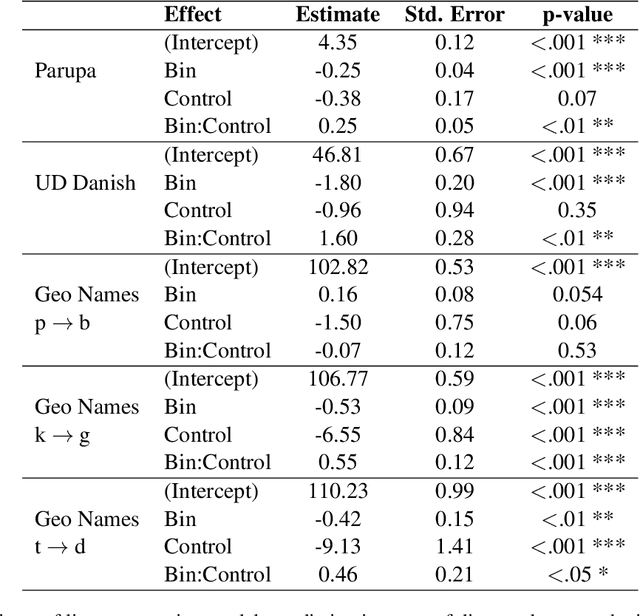
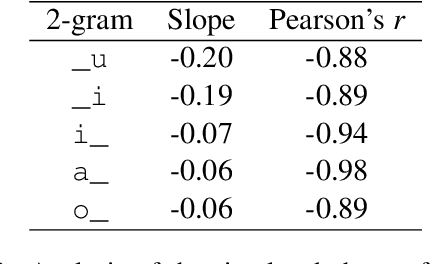
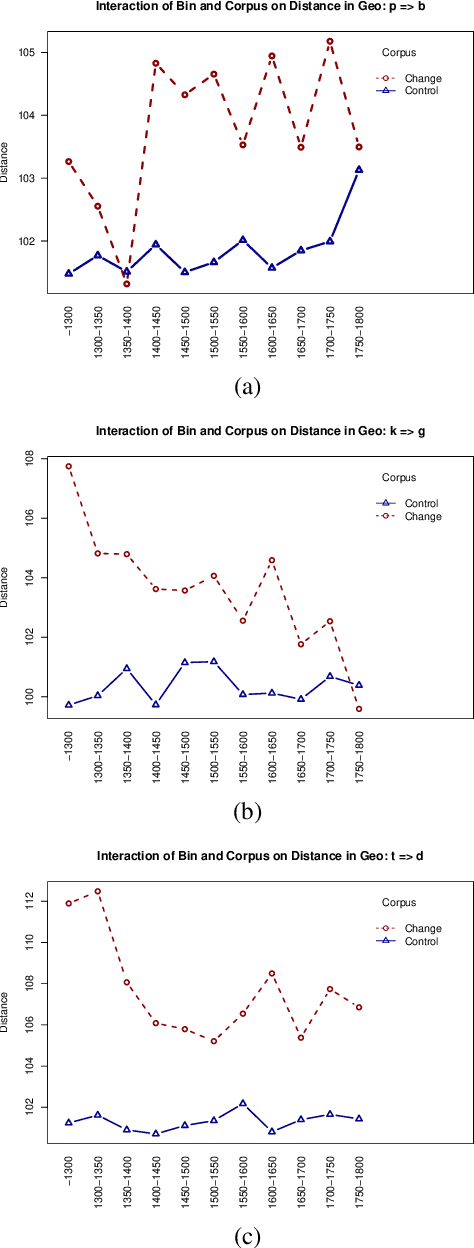
While a great deal of work has been done on NLP approaches to lexical semantic change detection, other aspects of language change have received less attention from the NLP community. In this paper, we address the detection of sound change through historical spelling. We propose that a sound change can be captured by comparing the relative distance through time between their distributions using PPMI character embeddings. We verify this hypothesis in synthetic data and then test the method's ability to trace the well-known historical change of lenition of plosives in Danish historical sources. We show that the models are able to identify several of the changes under consideration and to uncover meaningful contexts in which they appeared. The methodology has the potential to contribute to the study of open questions such as the relative chronology of sound shifts and their geographical distribution.