 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LPCSE: Neural Speech Enhancement through Linear Predictive Coding
Jun 22, 2022
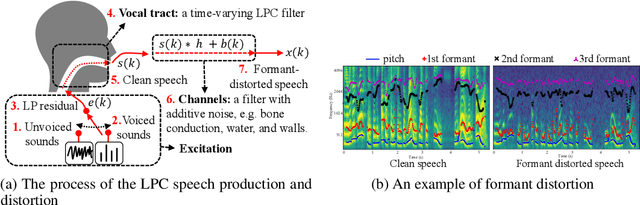
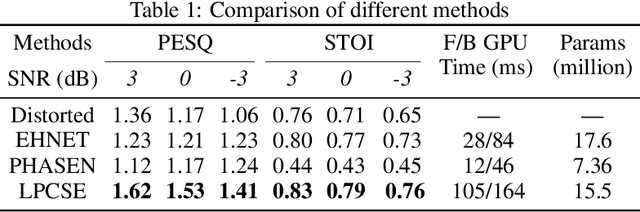
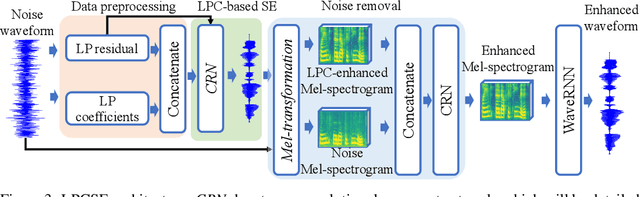
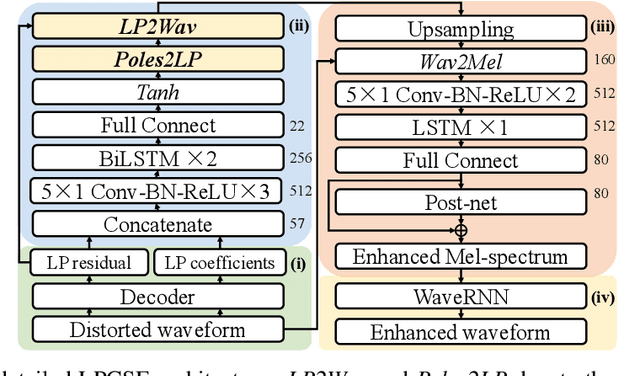
The increasingly stringent requirement on quality-of-experience in 5G/B5G communication systems has led to the emerging neural speech enhancement techniques, which however have been developed in isolation from the existing expert-rule based models of speech pronunciation and distortion, such as the classic Linear Predictive Coding (LPC) speech model because it is difficult to integrate the models with auto-differentiable machine learning frameworks. In this paper, to improve the efficiency of neural speech enhancement, we introduce an LPC-based speech enhancement (LPCSE) architecture, which leverages the strong inductive biases in the LPC speech model in conjunction with the expressive power of neural networks. Differentiable end-to-end learning is achieved in LPCSE via two novel blocks: a block that utilizes the expert rules to reduce the computational overhead when integrating the LPC speech model into neural networks, and a block that ensures the stability of the model and avoids exploding gradients in end-to-end training by mapping the Linear prediction coefficients to the filter poles. The experimental results show that LPCSE successfully restores the formants of the speeches distorted by transmission loss, and outperforms two existing neural speech enhancement methods of comparable neural network sizes in terms of the Perceptual evaluation of speech quality (PESQ) and Short-Time Objective Intelligibility (STOI) on the LJ Speech corpus.
Noisy $\ell^{0}$-Sparse Subspace Clustering on Dimensionality Reduced Data
Jun 22, 2022
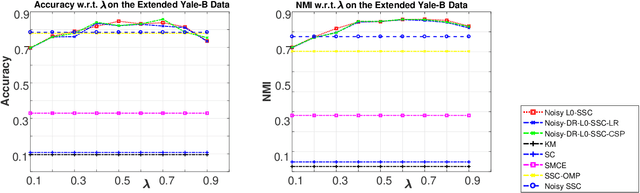
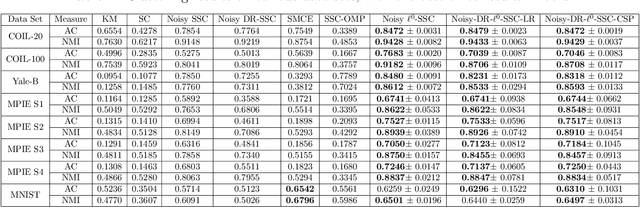
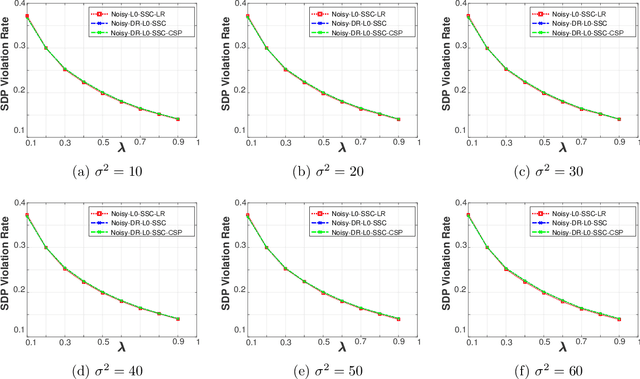
Sparse subspace clustering methods with sparsity induced by $\ell^{0}$-norm, such as $\ell^{0}$-Sparse Subspace Clustering ($\ell^{0}$-SSC)~\citep{YangFJYH16-L0SSC-ijcv}, are demonstrated to be more effective than its $\ell^{1}$ counterpart such as Sparse Subspace Clustering (SSC)~\citep{ElhamifarV13}. However, the theoretical analysis of $\ell^{0}$-SSC is restricted to clean data that lie exactly in subspaces. Real data often suffer from noise and they may lie close to subspaces. In this paper, we show that an optimal solution to the optimization problem of noisy $\ell^{0}$-SSC achieves subspace detection property (SDP), a key element with which data from different subspaces are separated, under deterministic and semi-random model. Our results provide theoretical guarantee on the correctness of noisy $\ell^{0}$-SSC in terms of SDP on noisy data for the first time, which reveals the advantage of noisy $\ell^{0}$-SSC in terms of much less restrictive condition on subspace affinity. In order to improve the efficiency of noisy $\ell^{0}$-SSC, we propose Noisy-DR-$\ell^{0}$-SSC which provably recovers the subspaces on dimensionality reduced data. Noisy-DR-$\ell^{0}$-SSC first projects the data onto a lower dimensional space by random projection, then performs noisy $\ell^{0}$-SSC on the projected data for improved efficiency. Experimental results demonstrate the effectiveness of Noisy-DR-$\ell^{0}$-SSC.
Effects of Reward Shaping on Curriculum Learning in Goal Conditioned Tasks
Jun 06, 2022
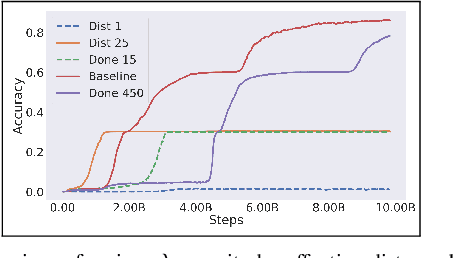
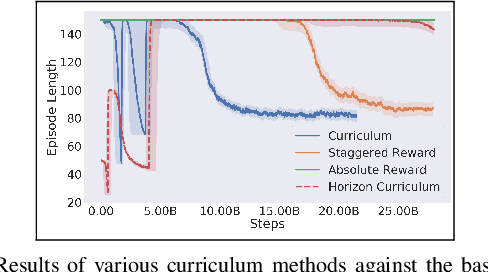
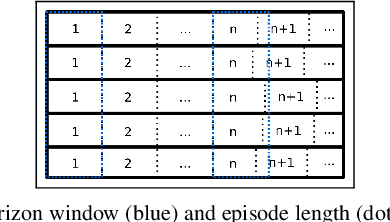
Real-time control for robotics is a popular research area in the reinforcement learning (RL) community. Through the use of techniques such as reward shaping, researchers have managed to train online agents across a multitude of domains. Despite these advances, solving goal-oriented tasks still require complex architectural changes or heavy constraints to be placed on the problem. To address this issue, recent works have explored how curriculum learning can be used to separate a complex task into sequential sub-goals, hence enabling the learning of a problem that may otherwise be too difficult to learn from scratch. In this article, we present how curriculum learning, reward shaping, and a high number of efficiently parallelized environments can be coupled together to solve the problem of multiple cube stacking. Finally, we extend the best configuration identified on a higher complexity environment with differently shaped objects.
Quantum Multi-Armed Bandits and Stochastic Linear Bandits Enjoy Logarithmic Regrets
May 30, 2022
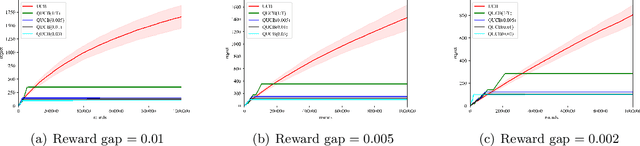
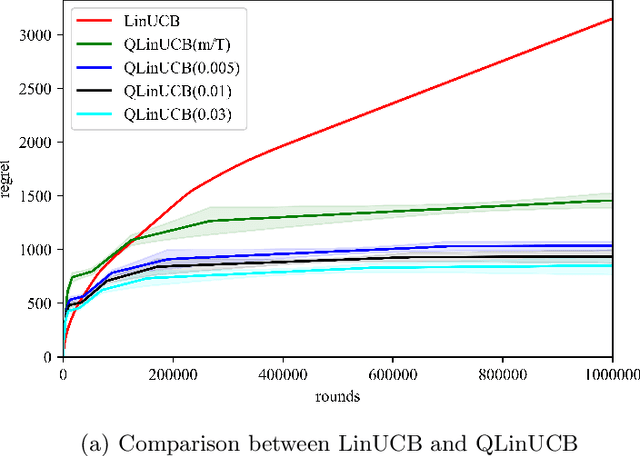
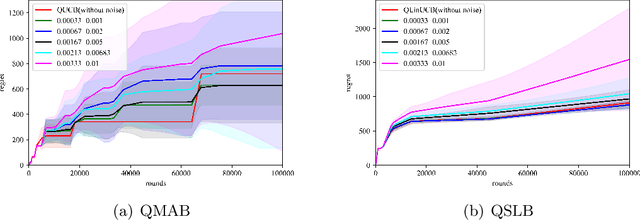
Multi-arm bandit (MAB) and stochastic linear bandit (SLB) are important models in reinforcement learning, and it is well-known that classical algorithms for bandits with time horizon $T$ suffer $\Omega(\sqrt{T})$ regret. In this paper, we study MAB and SLB with quantum reward oracles and propose quantum algorithms for both models with $O(\mbox{poly}(\log T))$ regrets, exponentially improving the dependence in terms of $T$. To the best of our knowledge, this is the first provable quantum speedup for regrets of bandit problems and in general exploitation in reinforcement learning. Compared to previous literature on quantum exploration algorithms for MAB and reinforcement learning, our quantum input model is simpler and only assumes quantum oracles for each individual arm.
Accelerating Inference and Language Model Fusion of Recurrent Neural Network Transducers via End-to-End 4-bit Quantization
Jun 16, 2022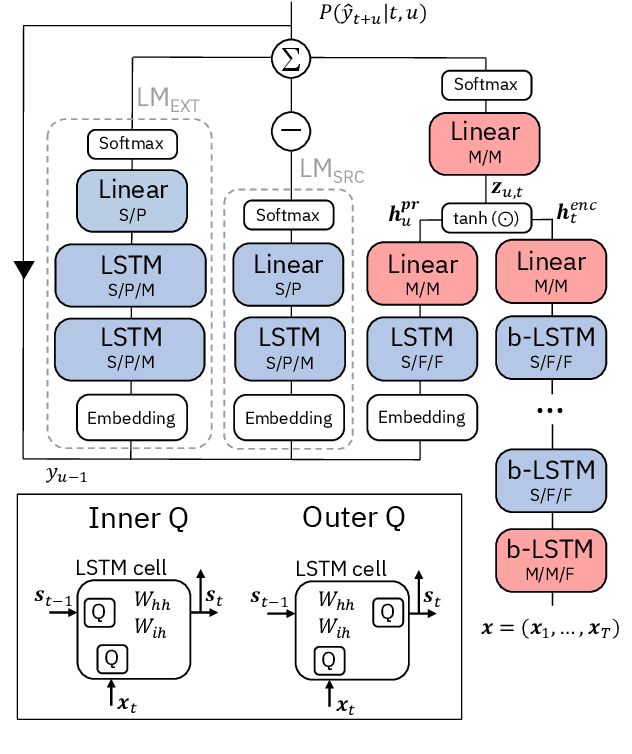
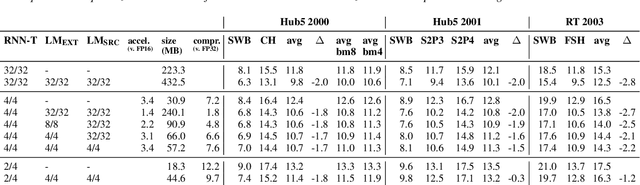
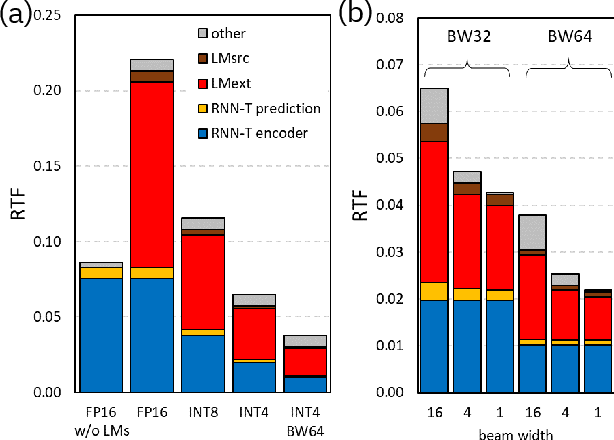
We report on aggressive quantization strategies that greatly accelerate inference of Recurrent Neural Network Transducers (RNN-T). We use a 4 bit integer representation for both weights and activations and apply Quantization Aware Training (QAT) to retrain the full model (acoustic encoder and language model) and achieve near-iso-accuracy. We show that customized quantization schemes that are tailored to the local properties of the network are essential to achieve good performance while limiting the computational overhead of QAT. Density ratio Language Model fusion has shown remarkable accuracy gains on RNN-T workloads but it severely increases the computational cost of inference. We show that our quantization strategies enable using large beam widths for hypothesis search while achieving streaming-compatible runtimes and a full model compression ratio of 7.6$\times$ compared to the full precision model. Via hardware simulations, we estimate a 3.4$\times$ acceleration from FP16 to INT4 for the end-to-end quantized RNN-T inclusive of LM fusion, resulting in a Real Time Factor (RTF) of 0.06. On the NIST Hub5 2000, Hub5 2001, and RT-03 test sets, we retain most of the gains associated with LM fusion, improving the average WER by $>$1.5%.
Wave-based extreme deep learning based on non-linear time-Floquet entanglement
Jul 19, 2021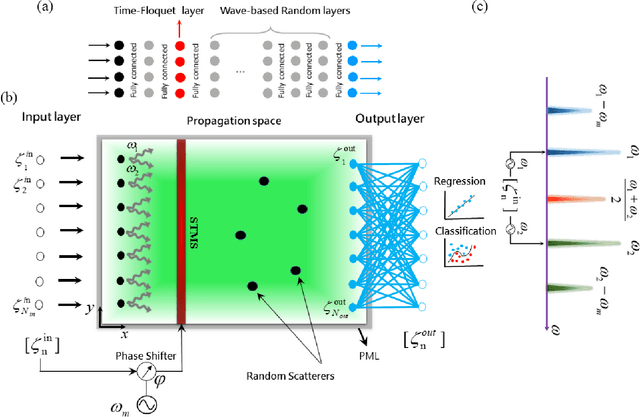
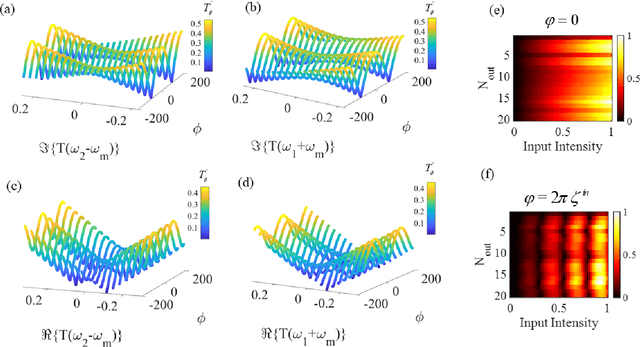
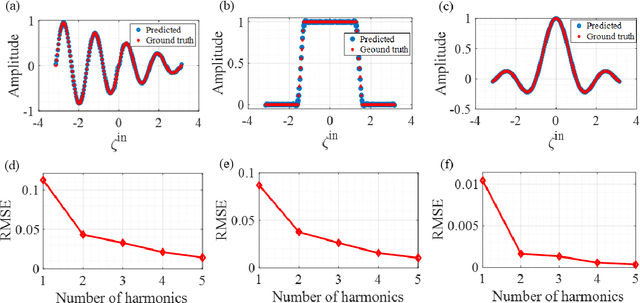
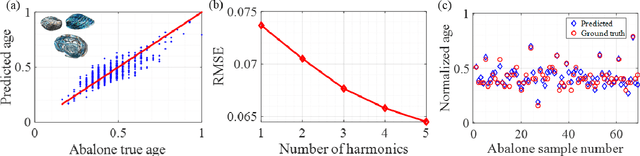
Wave-based analog signal processing holds the promise of extremely fast, on-the-fly, power-efficient data processing, occurring as a wave propagates through an artificially engineered medium. Yet, due to the fundamentally weak non-linearities of traditional wave materials, such analog processors have been so far largely confined to simple linear projections such as image edge detection or matrix multiplications. Complex neuromorphic computing tasks, which inherently require strong non-linearities, have so far remained out-of-reach of wave-based solutions, with a few attempts that implemented non-linearities on the digital front, or used weak and inflexible non-linear sensors, restraining the learning performance. Here, we tackle this issue by demonstrating the relevance of Time-Floquet physics to induce a strong non-linear entanglement between signal inputs at different frequencies, enabling a power-efficient and versatile wave platform for analog extreme deep learning involving a single, uniformly modulated dielectric layer and a scattering medium. We prove the efficiency of the method for extreme learning machines and reservoir computing to solve a range of challenging learning tasks, from forecasting chaotic time series to the simultaneous classification of distinct datasets. Our results open the way for wave-based machine learning with high energy efficiency, speed, and scalability.
A Deep Learning Approach to Dst Index Prediction
May 05, 2022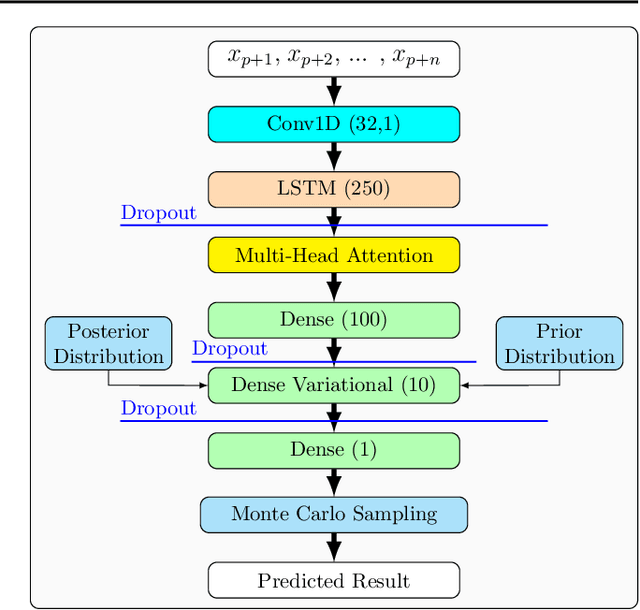
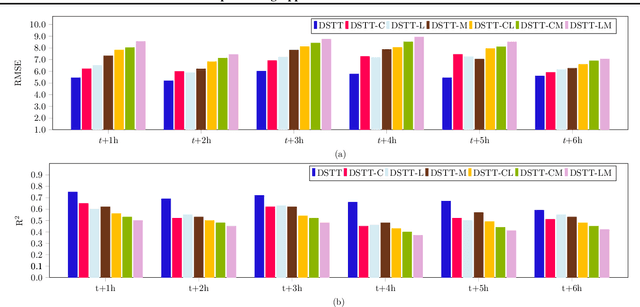
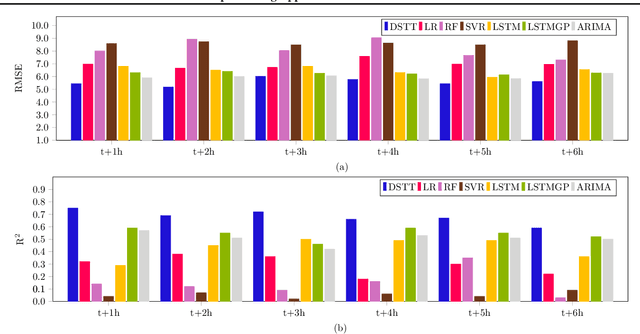
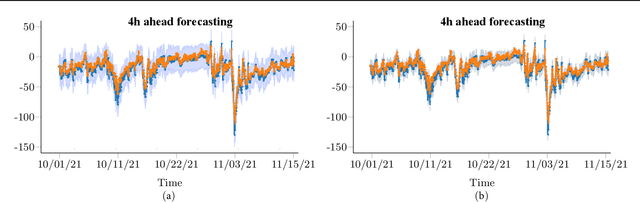
The disturbance storm time (Dst) index is an important and useful measurement in space weather research. It has been used to characterize the size and intensity of a geomagnetic storm. A negative Dst value means that the Earth's magnetic field is weakened, which happens during storms. In this paper, we present a novel deep learning method, called the Dst Transformer, to perform short-term, 1-6 hour ahead, forecasting of the Dst index based on the solar wind parameters provided by the NASA Space Science Data Coordinated Archive. The Dst Transformer combines a multi-head attention layer with Bayesian inference, which is capable of quantifying both aleatoric uncertainty and epistemic uncertainty when making Dst predictions. Experimental results show that the proposed Dst Transformer outperforms related machine learning methods in terms of the root mean square error and R-squared. Furthermore, the Dst Transformer can produce both data and model uncertainty quantification results, which can not be done by the existing methods. To our knowledge, this is the first time that Bayesian deep learning has been used for Dst index forecasting.
FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy
Jun 30, 2022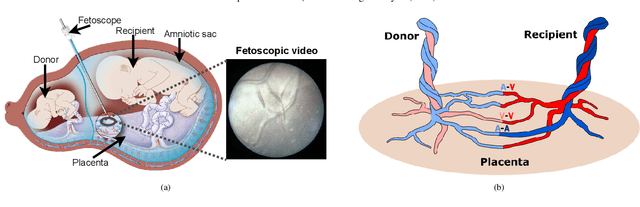
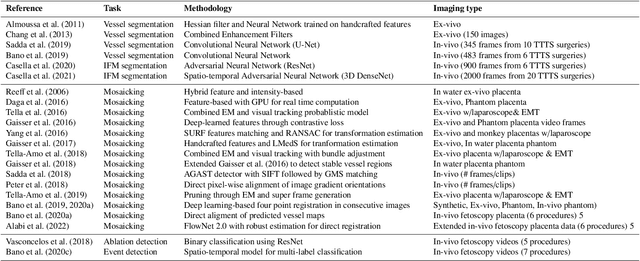
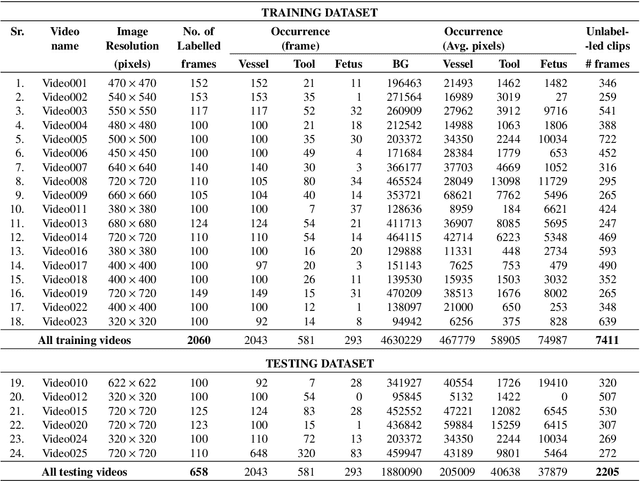
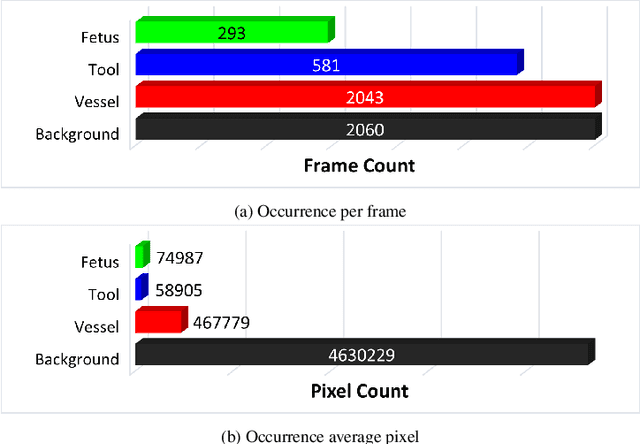
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to regulate blood exchange among twins. The procedure is particularly challenging due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation. Computer-assisted intervention (CAI) can provide surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision challenge, we released the first largescale multicentre TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. The challenge provided an opportunity for creating generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-centre fetoscopic data, we provide a benchmark for future research in this field.
Streamable Neural Audio Synthesis With Non-Causal Convolutions
Apr 14, 2022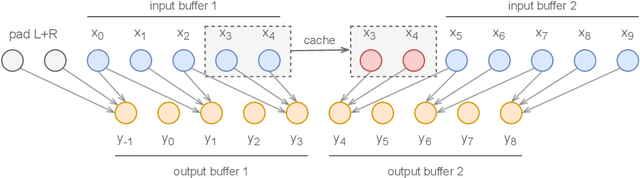
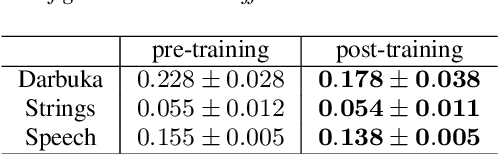
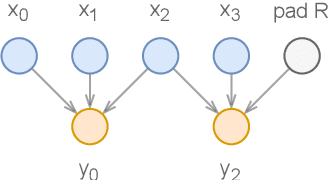
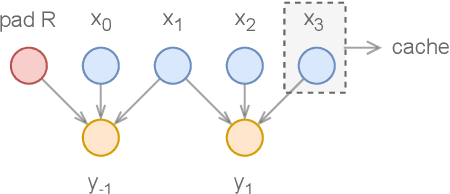
Deep learning models are mostly used in an offline inference fashion. However, this strongly limits the use of these models inside audio generation setups, as most creative workflows are based on real-time digital signal processing. Although approaches based on recurrent networks can be naturally adapted to this buffer-based computation, the use of convolutions still poses some serious challenges. To tackle this issue, the use of causal streaming convolutions have been proposed. However, this requires specific complexified training and can impact the resulting audio quality. In this paper, we introduce a new method allowing to produce non-causal streaming models. This allows to make any convolutional model compatible with real-time buffer-based processing. As our method is based on a post-training reconfiguration of the model, we show that it is able to transform models trained without causal constraints into a streaming model. We show how our method can be adapted to fit complex architectures with parallel branches. To evaluate our method, we apply it on the recent RAVE model, which provides high-quality real-time audio synthesis. We test our approach on multiple music and speech datasets and show that it is faster than overlap-add methods, while having no impact on the generation quality. Finally, we introduce two open-source implementation of our work as Max/MSP and PureData externals, and as a VST audio plugin. This allows to endow traditional digital audio workstation with real-time neural audio synthesis on a laptop CPU.
Prospective Preference Enhanced Mixed Attentive Model for Session-based Recommendation
Jun 04, 2022
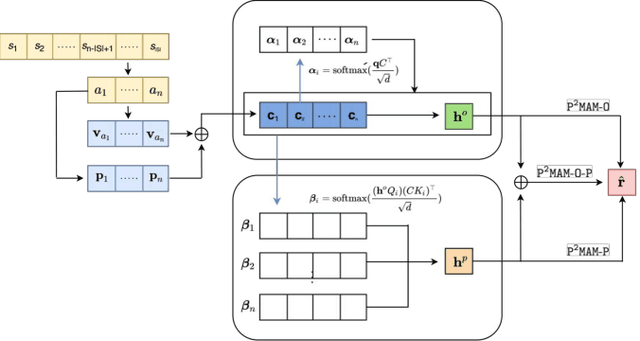
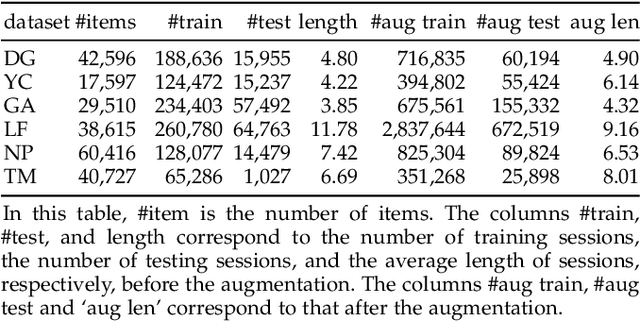
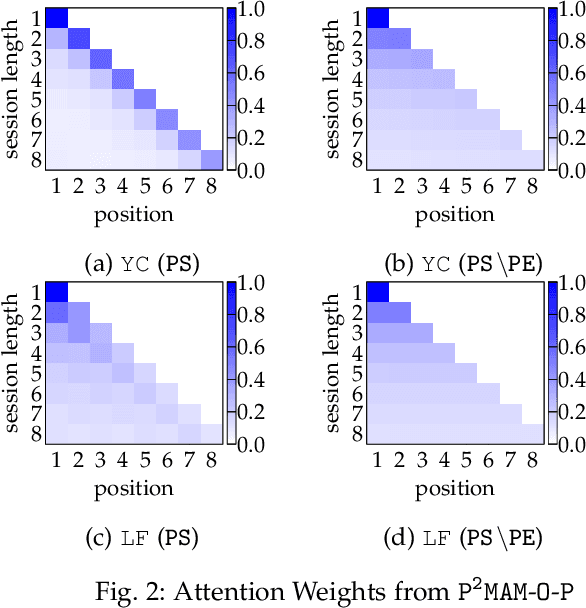
Session-based recommendation aims to generate recommendations for the next item of users' interest based on a given session. In this manuscript, we develop prospective preference enhanced mixed attentive model (P2MAM) to generate session-based recommendations using two important factors: temporal patterns and estimates of users' prospective preferences. Unlike existing methods, P2MAM models the temporal patterns using a light-weight while effective position-sensitive attention mechanism. In P2MAM, we also leverage the estimate of users' prospective preferences to signify important items, and generate better recommendations. Our experimental results demonstrate that P2MAM models significantly outperform the state-of-the-art methods in six benchmark datasets, with an improvement as much as 19.2%. In addition, our run-time performance comparison demonstrates that during testing, P2MAM models are much more efficient than the best baseline method, with a significant average speedup of 47.7 folds.