 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning ultrasound plane pose regression: assessing generalized pose coordinates in the fetal brain
Jan 19, 2023



In obstetric ultrasound (US) scanning, the learner's ability to mentally build a three-dimensional (3D) map of the fetus from a two-dimensional (2D) US image represents a significant challenge in skill acquisition. We aim to build a US plane localization system for 3D visualization, training, and guidance without integrating additional sensors. This work builds on top of our previous work, which predicts the six-dimensional (6D) pose of arbitrarily-oriented US planes slicing the fetal brain with respect to a normalized reference frame using a convolutional neural network (CNN) regression network. Here, we analyze in detail the assumptions of the normalized fetal brain reference frame and quantify its accuracy with respect to the acquisition of transventricular (TV) standard plane (SP) for fetal biometry. We investigate the impact of registration quality in the training and testing data and its subsequent effect on trained models. Finally, we introduce data augmentations and larger training sets that improve the results of our previous work, achieving median errors of 3.53 mm and 6.42 degrees for translation and rotation, respectively.
FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy
Jun 30, 2022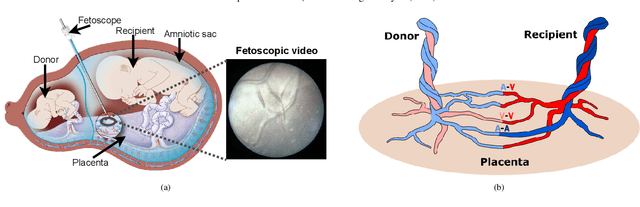
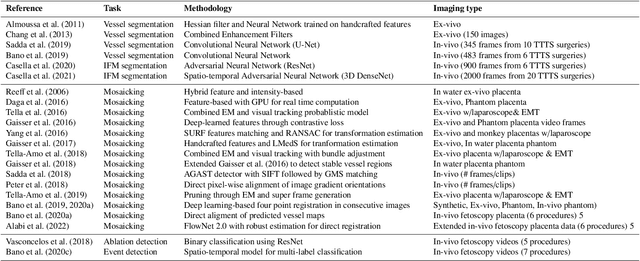
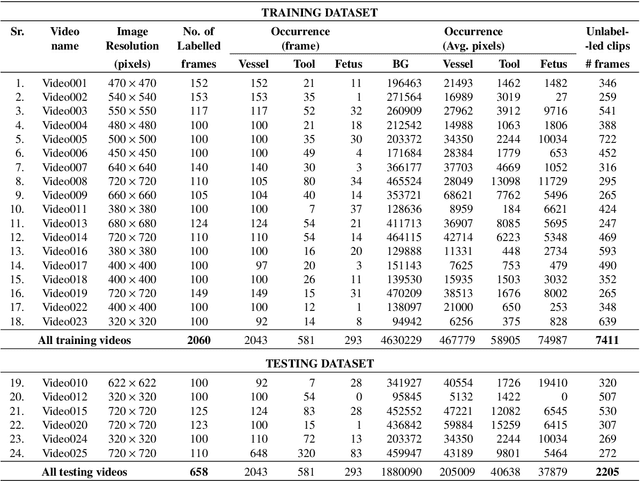
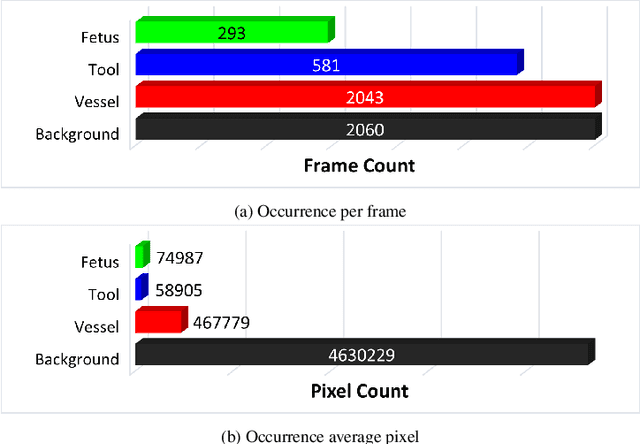
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to regulate blood exchange among twins. The procedure is particularly challenging due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation. Computer-assisted intervention (CAI) can provide surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision challenge, we released the first largescale multicentre TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. The challenge provided an opportunity for creating generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-centre fetoscopic data, we provide a benchmark for future research in this field.