 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAQNN: Spectral Adaptive Quantum Neural Network as a Universal Approximator
Feb 10, 2026Quantum machine learning (QML), as an interdisciplinary field bridging quantum computing and machine learning, has garnered significant attention in recent years. Currently, the field as a whole faces challenges due to incomplete theoretical foundations for the expressivity of quantum neural networks (QNNs). In this paper we propose a constructive QNN model and demonstrate that it possesses the universal approximation property (UAP), which means it can approximate any square-integrable function up to arbitrary accuracy. Furthermore, it supports switching function bases, thus adaptable to various scenarios in numerical approximation and machine learning. Our model has asymptotic advantages over the best classical feed-forward neural networks in terms of circuit size and achieves optimal parameter complexity when approximating Sobolev functions under $L_2$ norm.
Efficient Quantum Circuits for Machine Learning Activation Functions including Constant T-depth ReLU
Apr 09, 2024



In recent years, Quantum Machine Learning (QML) has increasingly captured the interest of researchers. Among the components in this domain, activation functions hold a fundamental and indispensable role. Our research focuses on the development of activation functions quantum circuits for integration into fault-tolerant quantum computing architectures, with an emphasis on minimizing $T$-depth. Specifically, we present novel implementations of ReLU and leaky ReLU activation functions, achieving constant $T$-depths of 4 and 8, respectively. Leveraging quantum lookup tables, we extend our exploration to other activation functions such as the sigmoid. This approach enables us to customize precision and $T$-depth by adjusting the number of qubits, making our results more adaptable to various application scenarios. This study represents a significant advancement towards enhancing the practicality and application of quantum machine learning.
Boosting Gradient Ascent for Continuous DR-submodular Maximization
Jan 16, 2024Projected Gradient Ascent (PGA) is the most commonly used optimization scheme in machine learning and operations research areas. Nevertheless, numerous studies and examples have shown that the PGA methods may fail to achieve the tight approximation ratio for continuous DR-submodular maximization problems. To address this challenge, we present a boosting technique in this paper, which can efficiently improve the approximation guarantee of the standard PGA to \emph{optimal} with only small modifications on the objective function. The fundamental idea of our boosting technique is to exploit non-oblivious search to derive a novel auxiliary function $F$, whose stationary points are excellent approximations to the global maximum of the original DR-submodular objective $f$. Specifically, when $f$ is monotone and $\gamma$-weakly DR-submodular, we propose an auxiliary function $F$ whose stationary points can provide a better $(1-e^{-\gamma})$-approximation than the $(\gamma^2/(1+\gamma^2))$-approximation guaranteed by the stationary points of $f$ itself. Similarly, for the non-monotone case, we devise another auxiliary function $F$ whose stationary points can achieve an optimal $\frac{1-\min_{\boldsymbol{x}\in\mathcal{C}}\|\boldsymbol{x}\|_{\infty}}{4}$-approximation guarantee where $\mathcal{C}$ is a convex constraint set. In contrast, the stationary points of the original non-monotone DR-submodular function can be arbitrarily bad~\citep{chen2023continuous}. Furthermore, we demonstrate the scalability of our boosting technique on four problems. In all of these four problems, our resulting variants of boosting PGA algorithm beat the previous standard PGA in several aspects such as approximation ratio and efficiency. Finally, we corroborate our theoretical findings with numerical experiments, which demonstrate the effectiveness of our boosting PGA methods.
Bandit Multi-linear DR-Submodular Maximization and Its Applications on Adversarial Submodular Bandits
May 21, 2023
We investigate the online bandit learning of the monotone multi-linear DR-submodular functions, designing the algorithm $\mathtt{BanditMLSM}$ that attains $O(T^{2/3}\log T)$ of $(1-1/e)$-regret. Then we reduce submodular bandit with partition matroid constraint and bandit sequential monotone maximization to the online bandit learning of the monotone multi-linear DR-submodular functions, attaining $O(T^{2/3}\log T)$ of $(1-1/e)$-regret in both problems, which improve the existing results. To the best of our knowledge, we are the first to give a sublinear regret algorithm for the submodular bandit with partition matroid constraint. A special case of this problem is studied by Streeter et al.(2009). They prove a $O(T^{4/5})$ $(1-1/e)$-regret upper bound. For the bandit sequential submodular maximization, the existing work proves an $O(T^{2/3})$ regret with a suboptimal $1/2$ approximation ratio (Niazadeh et al. 2021).
Near-Term Quantum Computing Techniques: Variational Quantum Algorithms, Error Mitigation, Circuit Compilation, Benchmarking and Classical Simulation
Nov 17, 2022Quantum computing is a game-changing technology for global academia, research centers and industries including computational science, mathematics, finance, pharmaceutical, materials science, chemistry and cryptography. Although it has seen a major boost in the last decade, we are still a long way from reaching the maturity of a full-fledged quantum computer. That said, we will be in the Noisy-Intermediate Scale Quantum (NISQ) era for a long time, working on dozens or even thousands of qubits quantum computing systems. An outstanding challenge, then, is to come up with an application that can reliably carry out a nontrivial task of interest on the near-term quantum devices with non-negligible quantum noise. To address this challenge, several near-term quantum computing techniques, including variational quantum algorithms, error mitigation, quantum circuit compilation and benchmarking protocols, have been proposed to characterize and mitigate errors, and to implement algorithms with a certain resistance to noise, so as to enhance the capabilities of near-term quantum devices and explore the boundaries of their ability to realize useful applications. Besides, the development of near-term quantum devices is inseparable from the efficient classical simulation, which plays a vital role in quantum algorithm design and verification, error-tolerant verification and other applications. This review will provide a thorough introduction of these near-term quantum computing techniques, report on their progress, and finally discuss the future prospect of these techniques, which we hope will motivate researchers to undertake additional studies in this field.
Quantum Multi-Armed Bandits and Stochastic Linear Bandits Enjoy Logarithmic Regrets
May 30, 2022
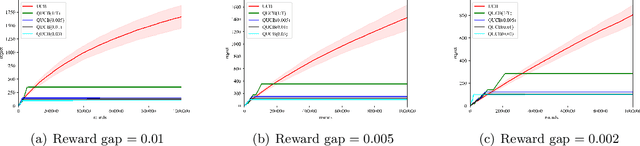
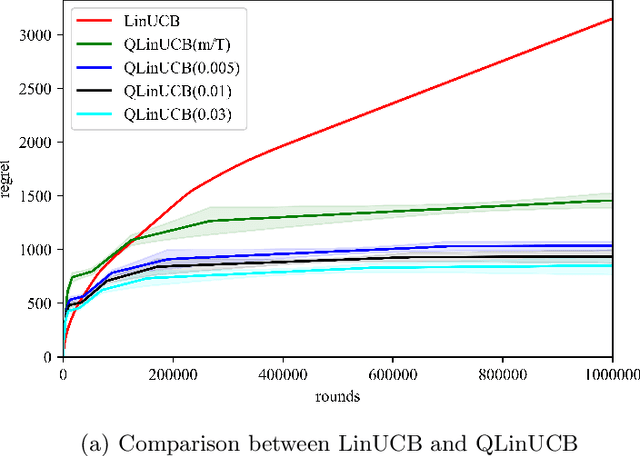
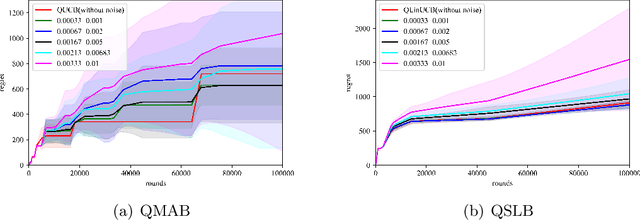
Multi-arm bandit (MAB) and stochastic linear bandit (SLB) are important models in reinforcement learning, and it is well-known that classical algorithms for bandits with time horizon $T$ suffer $\Omega(\sqrt{T})$ regret. In this paper, we study MAB and SLB with quantum reward oracles and propose quantum algorithms for both models with $O(\mbox{poly}(\log T))$ regrets, exponentially improving the dependence in terms of $T$. To the best of our knowledge, this is the first provable quantum speedup for regrets of bandit problems and in general exploitation in reinforcement learning. Compared to previous literature on quantum exploration algorithms for MAB and reinforcement learning, our quantum input model is simpler and only assumes quantum oracles for each individual arm.
Bounded Memory Adversarial Bandits with Composite Anonymous Delayed Feedback
Apr 28, 2022We study the adversarial bandit problem with composite anonymous delayed feedback. In this setting, losses of an action are split into $d$ components, spreading over consecutive rounds after the action is chosen. And in each round, the algorithm observes the aggregation of losses that come from the latest $d$ rounds. Previous works focus on oblivious adversarial setting, while we investigate the harder non-oblivious setting. We show non-oblivious setting incurs $\Omega(T)$ pseudo regret even when the loss sequence is bounded memory. However, we propose a wrapper algorithm which enjoys $o(T)$ policy regret on many adversarial bandit problems with the assumption that the loss sequence is bounded memory. Especially, for $K$-armed bandit and bandit convex optimization, we have $\mathcal{O}(T^{2/3})$ policy regret bound. We also prove a matching lower bound for $K$-armed bandit. Our lower bound works even when the loss sequence is oblivious but the delay is non-oblivious. It answers the open problem proposed in \cite{wang2021adaptive}, showing that non-oblivious delay is enough to incur $\tilde{\Omega}(T^{2/3})$ regret.
New Distinguishers for Negation-Limited Weak Pseudorandom Functions
Mar 23, 2022We show how to distinguish circuits with $\log k$ negations (a.k.a $k$-monotone functions) from uniformly random functions in $\exp\left(\tilde{O}\left(n^{1/3}k^{2/3}\right)\right)$ time using random samples. The previous best distinguisher, due to the learning algorithm by Blais, Cannone, Oliveira, Servedio, and Tan (RANDOM'15), requires $\exp\big(\tilde{O}(n^{1/2} k)\big)$ time. Our distinguishers are based on Fourier analysis on \emph{slices of the Boolean cube}. We show that some "middle" slices of negation-limited circuits have strong low-degree Fourier concentration and then we apply a variation of the classic Linial, Mansour, and Nisan "Low-Degree algorithm" (JACM'93) on slices. Our techniques also lead to a slightly improved weak learner for negation limited circuits under the uniform distribution.
Online Influence Maximization with Node-level Feedback Using Standard Offline Oracles
Sep 13, 2021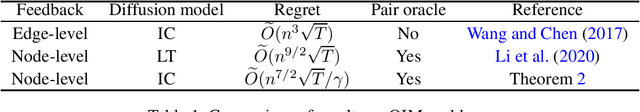
We study the online influence maximization (OIM) problem in social networks, where in multiple rounds the learner repeatedly chooses seed nodes to generate cascades, observes the cascade feedback, and gradually learns the best seeds that generate the largest cascade. We focus on two major challenges in this paper. First, we work with node-level feedback instead of edge-level feedback. The edge-level feedback reveals all edges that pass through information in a cascade, where the node-level feedback only reveals the activated nodes with timestamps. The node-level feedback is arguably more realistic since in practice it is relatively easy to observe who is influenced but very difficult to observe from which relationship (edge) the influence comes from. Second, we use standard offline oracle instead of offline pair-oracle. To compute a good seed set for the next round, an offline pair-oracle finds the best seed set and the best parameters within the confidence region simultaneously, and such an oracle is difficult to compute due to the combinatorial core of OIM problem. So we focus on how to use the standard offline influence maximization oracle which finds the best seed set given the edge parameters as input. In this paper, we resolve these challenges for the two most popular diffusion models, the independent cascade (IC) and the linear threshold (LT) model. For the IC model, the past research only achieves edge-level feedback, while we present the first $\widetilde{O}(\sqrt{T})$-regret algorithm for the node-level feedback. Besides, the algorithm only invokes standard offline oracles. For the LT model, a recent study only provides an OIM solution that meets the first challenge but still requires a pair-oracle. In this paper, we apply a similar technique as in the IC model to replace the pair-oracle with a standard oracle while maintaining $\widetilde{O}(\sqrt{T})$-regret.
Network Inference and Influence Maximization from Samples
Jun 07, 2021Influence maximization is the task of selecting a small number of seed nodes in a social network to maximize the spread of the influence from these seeds, and it has been widely investigated in the past two decades. In the canonical setting, the whole social network as well as its diffusion parameters is given as input. In this paper, we consider the more realistic sampling setting where the network is unknown and we only have a set of passively observed cascades that record the set of activated nodes at each diffusion step. We study the task of influence maximization from these cascade samples (IMS), and present constant approximation algorithms for this task under mild conditions on the seed set distribution. To achieve the optimization goal, we also provide a novel solution to the network inference problem, that is, learning diffusion parameters and the network structure from the cascade data. Comparing with prior solutions, our network inference algorithm requires weaker assumptions and does not rely on maximum-likelihood estimation and convex programming. Our IMS algorithms enhance the learning-and-then-optimization approach by allowing a constant approximation ratio even when the diffusion parameters are hard to learn, and we do not need any assumption related to the network structure or diffusion parameters.