 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Fine-Tuning of BERT Models on the Edge
May 03, 2022
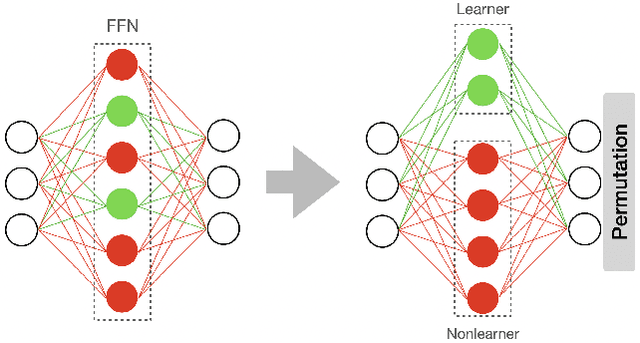
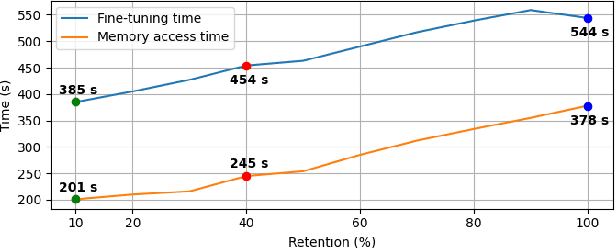
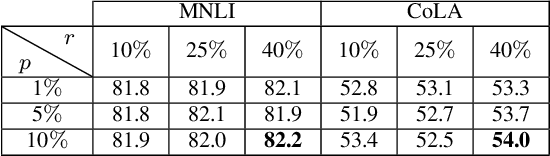
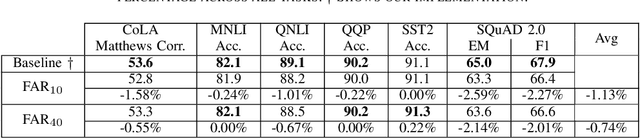
Resource-constrained devices are increasingly the deployment targets of machine learning applications. Static models, however, do not always suffice for dynamic environments. On-device training of models allows for quick adaptability to new scenarios. With the increasing size of deep neural networks, as noted with the likes of BERT and other natural language processing models, comes increased resource requirements, namely memory, computation, energy, and time. Furthermore, training is far more resource intensive than inference. Resource-constrained on-device learning is thus doubly difficult, especially with large BERT-like models. By reducing the memory usage of fine-tuning, pre-trained BERT models can become efficient enough to fine-tune on resource-constrained devices. We propose Freeze And Reconfigure (FAR), a memory-efficient training regime for BERT-like models that reduces the memory usage of activation maps during fine-tuning by avoiding unnecessary parameter updates. FAR reduces fine-tuning time on the DistilBERT model and CoLA dataset by 30%, and time spent on memory operations by 47%. More broadly, reductions in metric performance on the GLUE and SQuAD datasets are around 1% on average.
Faster Diffusion Cardiac MRI with Deep Learning-based breath hold reduction
Jun 21, 2022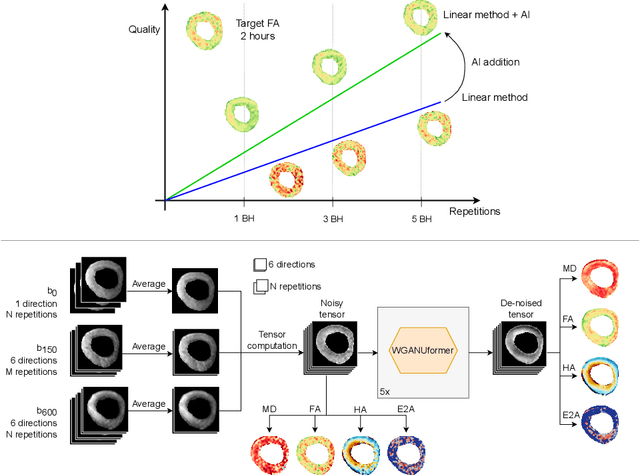
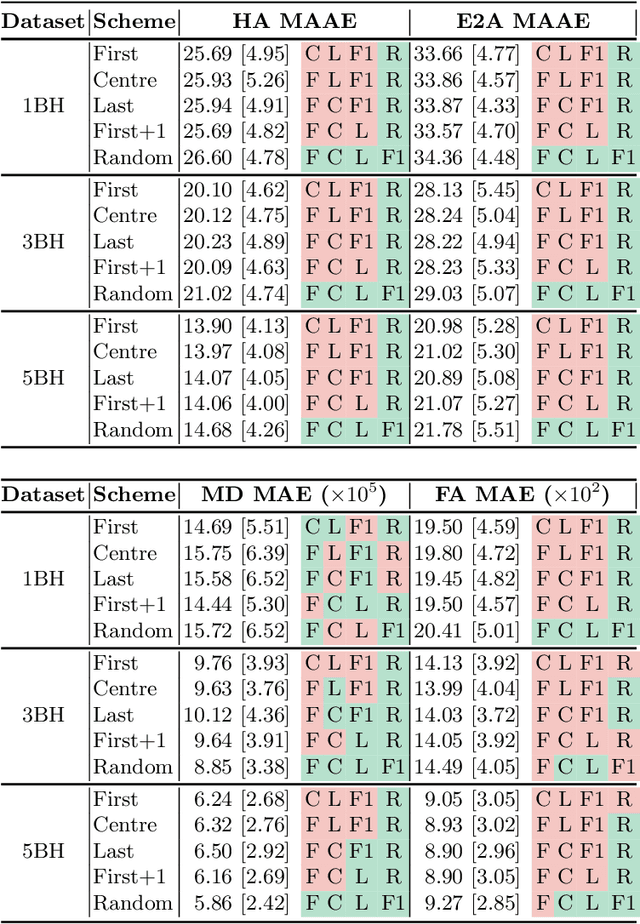
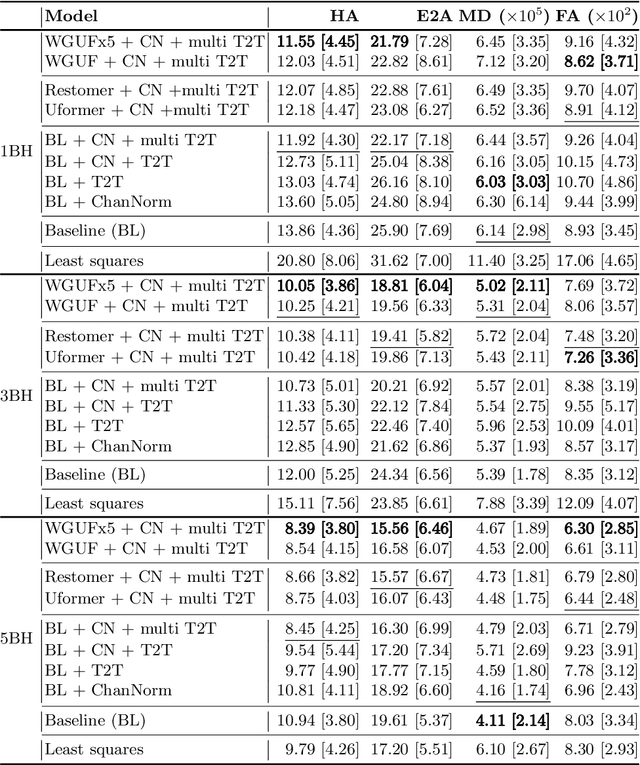
Diffusion Tensor Cardiac Magnetic Resonance (DT-CMR) enables us to probe the microstructural arrangement of cardiomyocytes within the myocardium in vivo and non-invasively, which no other imaging modality allows. This innovative technology could revolutionise the ability to perform cardiac clinical diagnosis, risk stratification, prognosis and therapy follow-up. However, DT-CMR is currently inefficient with over six minutes needed to acquire a single 2D static image. Therefore, DT-CMR is currently confined to research but not used clinically. We propose to reduce the number of repetitions needed to produce DT-CMR datasets and subsequently de-noise them, decreasing the acquisition time by a linear factor while maintaining acceptable image quality. Our proposed approach, based on Generative Adversarial Networks, Vision Transformers, and Ensemble Learning, performs significantly and considerably better than previous proposed approaches, bringing single breath-hold DT-CMR closer to reality.
Trial2Vec: Zero-Shot Clinical Trial Document Similarity Search using Self-Supervision
Jun 29, 2022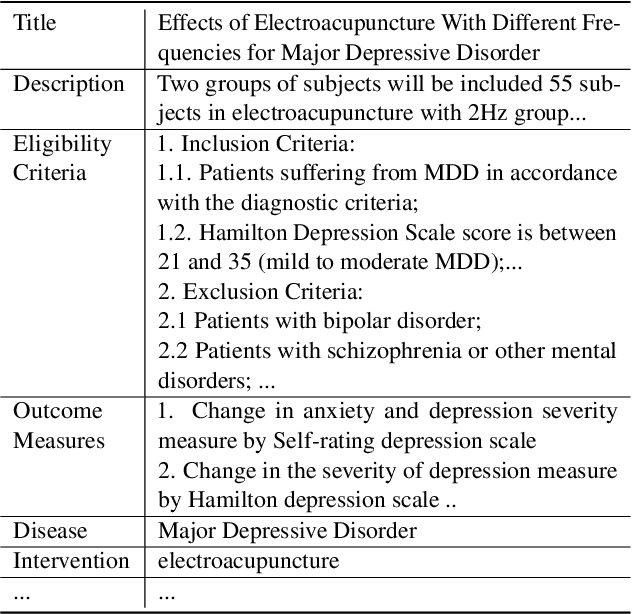
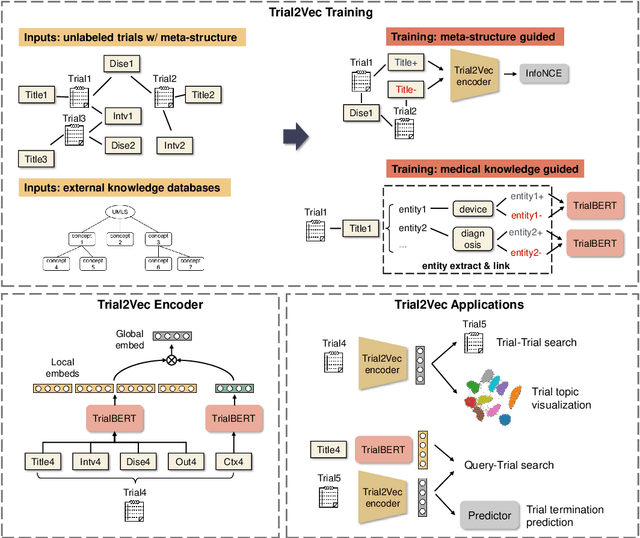
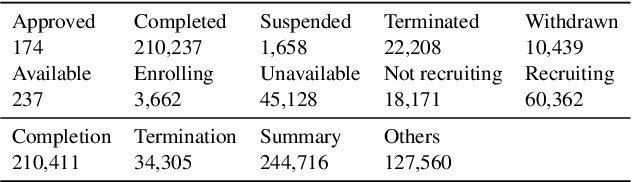
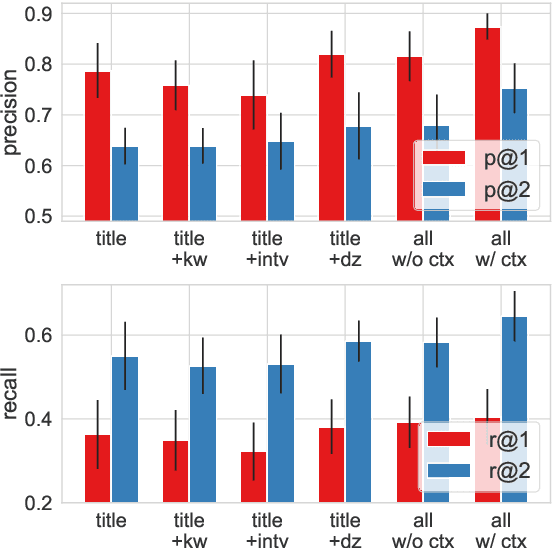
Clinical trials are essential for drug development but are extremely expensive and time-consuming to conduct. It is beneficial to study similar historical trials when designing a clinical trial. However, lengthy trial documents and lack of labeled data make trial similarity search difficult. We propose a zero-shot clinical trial retrieval method, Trial2Vec, which learns through self-supervision without annotating similar clinical trials. Specifically, the meta-structure of trial documents (e.g., title, eligibility criteria, target disease) along with clinical knowledge (e.g., UMLS knowledge base https://www.nlm.nih.gov/research/umls/index.html) are leveraged to automatically generate contrastive samples. Besides, Trial2Vec encodes trial documents considering meta-structure thus producing compact embeddings aggregating multi-aspect information from the whole document. We show that our method yields medically interpretable embeddings by visualization and it gets a 15% average improvement over the best baselines on precision/recall for trial retrieval, which is evaluated on our labeled 1600 trial pairs. In addition, we prove the pre-trained embeddings benefit the downstream trial outcome prediction task over 240k trials.
Deep Reinforcement Learning for Distributed and Uncoordinated Cognitive Radios Resource Allocation
May 27, 2022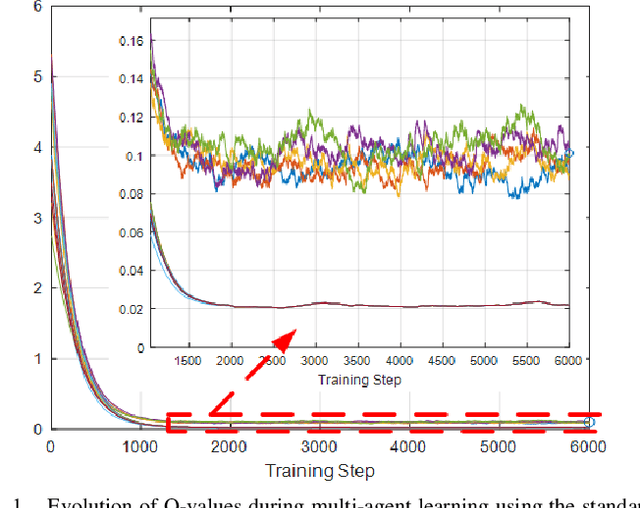
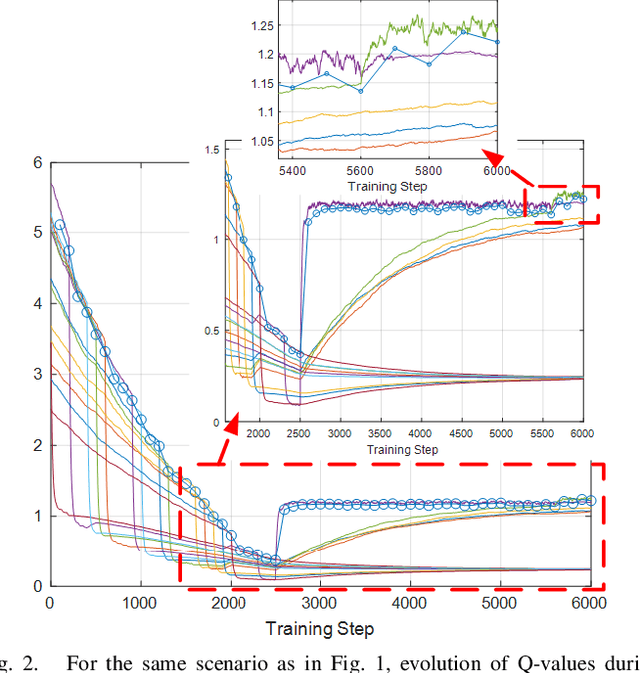
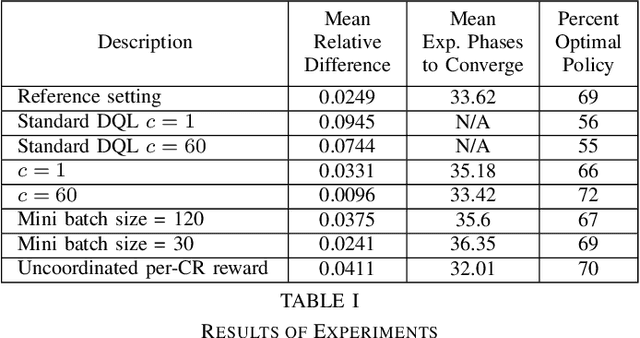
This paper presents a novel deep reinforcement learning-based resource allocation technique for the multi-agent environment presented by a cognitive radio network where the interactions of the agents during learning may lead to a non-stationary environment. The resource allocation technique presented in this work is distributed, not requiring coordination with other agents. It is shown by considering aspects specific to deep reinforcement learning that the presented algorithm converges in an arbitrarily long time to equilibrium policies in a non-stationary multi-agent environment that results from the uncoordinated dynamic interaction between radios through the shared wireless environment. Simulation results show that the presented technique achieves a faster learning performance compared to an equivalent table-based Q-learning algorithm and is able to find the optimal policy in 99% of cases for a sufficiently long learning time. In addition, simulations show that our DQL approach requires less than half the number of learning steps to achieve the same performance as an equivalent table-based implementation. Moreover, it is shown that the use of a standard single-agent deep reinforcement learning approach may not achieve convergence when used in an uncoordinated interacting multi-radio scenario
Multi-Octave Interference Detectors with Sub-Microsecond Response
Jul 03, 2022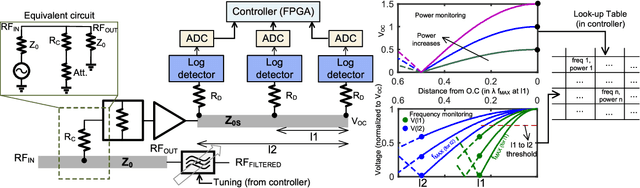
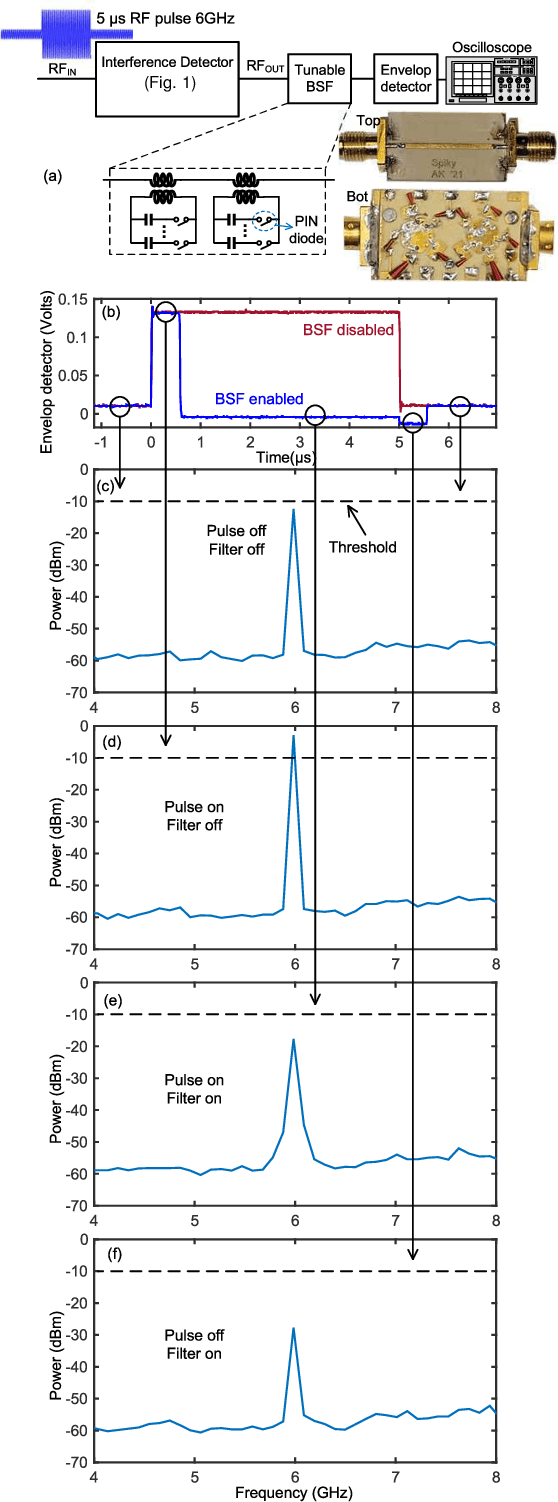
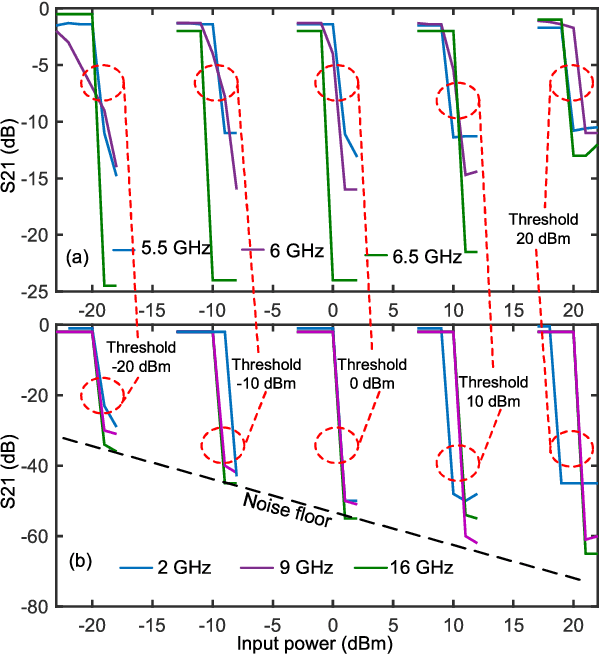
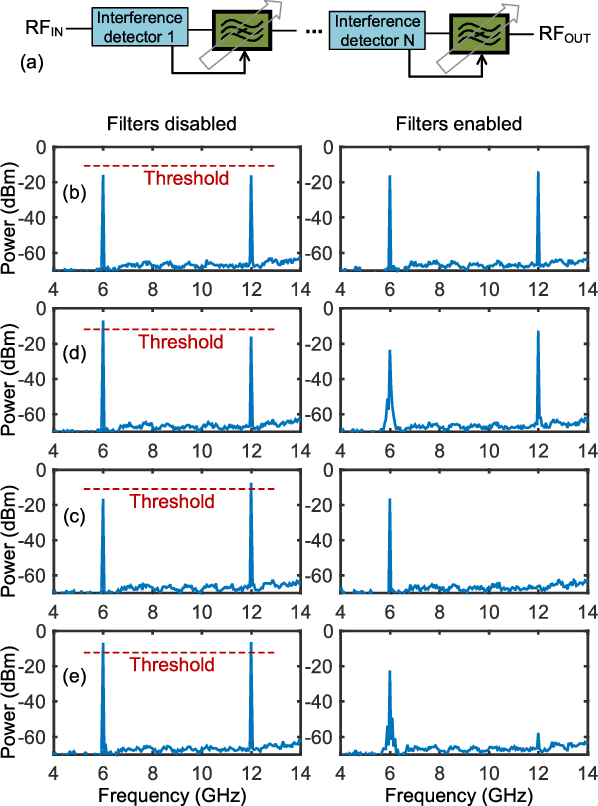
High-power interferers are one of the main hurdles in wideband communication channels. To that end, this paper presents a wideband interferer detection method. The presented technique operates by sampling the incoming signal as an input, and produces the frequency and the power readings of the detected interferer. The detection method relies on driving an open circuit stub, where the voltage is proportional to the power of the interferer, and the standing wave pattern is an indicator of its frequency. This approach is feasible over multi-octave bandwidth with a wide power dynamic range. The concept is analyzed for design and optimization, and a prototype is built for a proof-of-concept. The measured results demonstrate the ability to detect an interferer within the 1--16 GHz frequency range, with a power dynamic range between -20 to 20 dBm. The detection concept is also fitted with different types of tunable bandstop filters (BSFs) for automatic detection and suppression of the interferer if its power exceeds a programmable threshold. With a measured response time of 500 ns, the presented method is a technology enabler for wideband receivers.
Online vs. Offline Adaptive Domain Randomization Benchmark
Jun 29, 2022

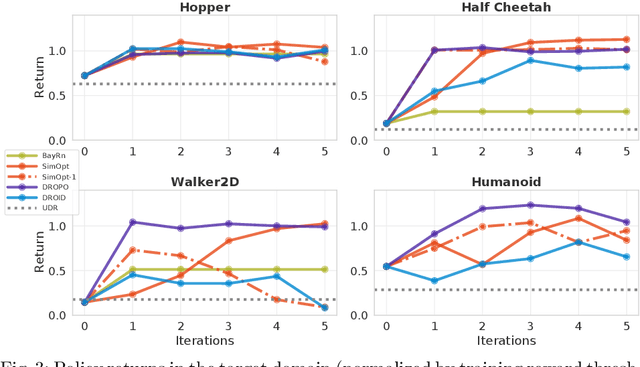
Physics simulators have shown great promise for conveniently learning reinforcement learning policies in safe, unconstrained environments. However, transferring the acquired knowledge to the real world can be challenging due to the reality gap. To this end, several methods have been recently proposed to automatically tune simulator parameters with posterior distributions given real data, for use with domain randomization at training time. These approaches have been shown to work for various robotic tasks under different settings and assumptions. Nevertheless, existing literature lacks a thorough comparison of existing adaptive domain randomization methods with respect to transfer performance and real-data efficiency. In this work, we present an open benchmark for both offline and online methods (SimOpt, BayRn, DROID, DROPO), to shed light on which are most suitable for each setting and task at hand. We found that online methods are limited by the quality of the currently learned policy for the next iteration, while offline methods may sometimes fail when replaying trajectories in simulation with open-loop commands. The code used will be released at https://github.com/gabrieletiboni/adr-benchmark.
VRKitchen2.0-IndoorKit: A Tutorial for Augmented Indoor Scene Building in Omniverse
Jun 23, 2022

With the recent progress of simulations by 3D modeling software and game engines, many researchers have focused on Embodied AI tasks in the virtual environment. However, the research community lacks a platform that can easily serve both indoor scene synthesis and model benchmarking with various algorithms. Meanwhile, computer graphics-related tasks need a toolkit for implementing advanced synthesizing techniques. To facilitate the study of indoor scene building methods and their potential robotics applications, we introduce INDOORKIT: a built-in toolkit for NVIDIA OMNIVERSE that provides flexible pipelines for indoor scene building, scene randomizing, and animation controls. Besides, combining Python coding in the animation software INDOORKIT assists researchers in creating real-time training and controlling avatars and robotics. The source code for this toolkit is available at https://github.com/realvcla/VRKitchen2.0-Tutorial, and the tutorial along with the toolkit is available at https://vrkitchen20-tutorial.readthedocs.io/en/
Rethinking Audio-visual Synchronization for Active Speaker Detection
Jun 21, 2022
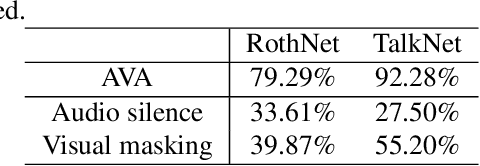

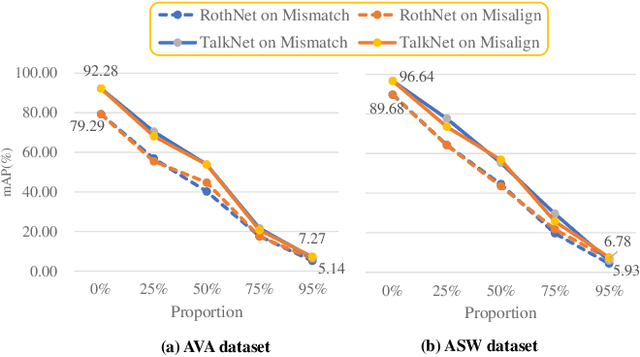
Active speaker detection (ASD) systems are important modules for analyzing multi-talker conversations. They aim to detect which speakers or none are talking in a visual scene at any given time. Existing research on ASD does not agree on the definition of active speakers. We clarify the definition in this work and require synchronization between the audio and visual speaking activities. This clarification of definition is motivated by our extensive experiments, through which we discover that existing ASD methods fail in modeling the audio-visual synchronization and often classify unsynchronized videos as active speaking. To address this problem, we propose a cross-modal contrastive learning strategy and apply positional encoding in attention modules for supervised ASD models to leverage the synchronization cue. Experimental results suggest that our model can successfully detect unsynchronized speaking as not speaking, addressing the limitation of current models.
2nd Place Solution for Waymo Open Dataset Challenge -- Real-time 2D Object Detection
Jun 16, 2021
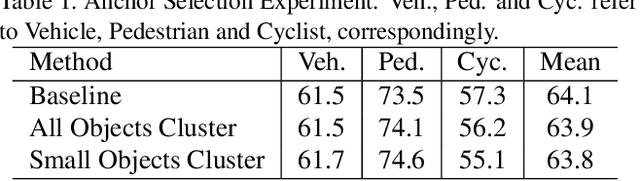
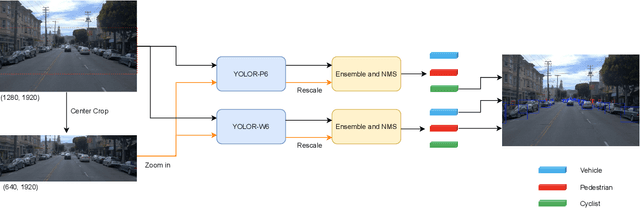
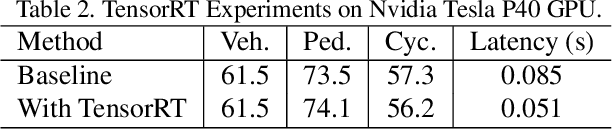
In an autonomous driving system, it is essential to recognize vehicles, pedestrians and cyclists from images. Besides the high accuracy of the prediction, the requirement of real-time running brings new challenges for convolutional network models. In this report, we introduce a real-time method to detect the 2D objects from images. We aggregate several popular one-stage object detectors and train the models of variety input strategies independently, to yield better performance for accurate multi-scale detection of each category, especially for small objects. For model acceleration, we leverage TensorRT to optimize the inference time of our detection pipeline. As shown in the leaderboard, our proposed detection framework ranks the 2nd place with 75.00% L1 mAP and 69.72% L2 mAP in the real-time 2D detection track of the Waymo Open Dataset Challenges, while our framework achieves the latency of 45.8ms/frame on an Nvidia Tesla V100 GPU.
YOLOSA: Object detection based on 2D local feature superimposed self-attention
Jun 23, 2022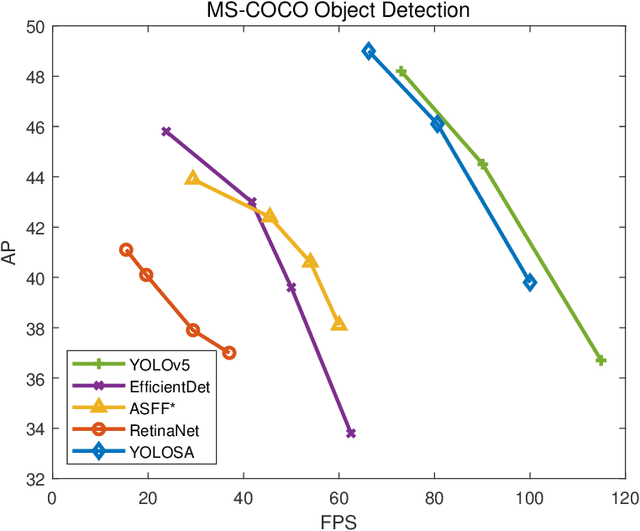
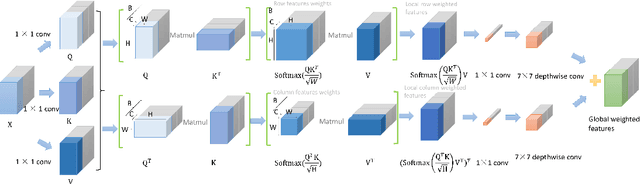

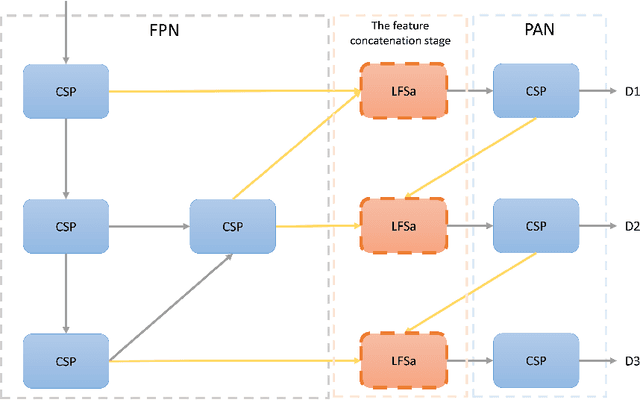
We analyzed the network structure of real-time object detection models and found that the features in the feature concatenation stage are very rich. Applying an attention module here can effectively improve the detection accuracy of the model. However, the commonly used attention module or self-attention module shows poor performance in detection accuracy and inference efficiency. Therefore, we propose a novel self-attention module, called 2D local feature superimposed self-attention, for the feature concatenation stage of the neck network. This self-attention module reflects global features through local features and local receptive fields. We also propose and optimize an efficient decoupled head and AB-OTA, and achieve SOTA results. Average precisions of 49.0\% (66.2 FPS), 46.1\% (80.6 FPS), and 39.1\% (100 FPS) were obtained for large, medium, and small-scale models built using our proposed improvements. Our models exceeded YOLOv5 by 0.8\% -- 3.1\% in average precision.