 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Distributed and Uncoordinated Cognitive Radios Resource Allocation
May 27, 2022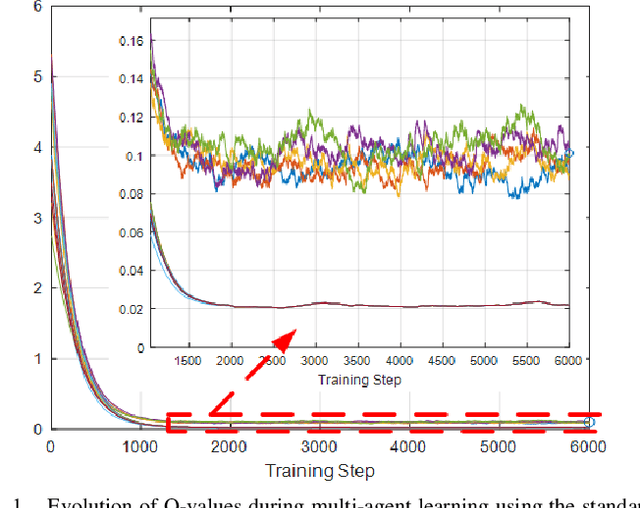
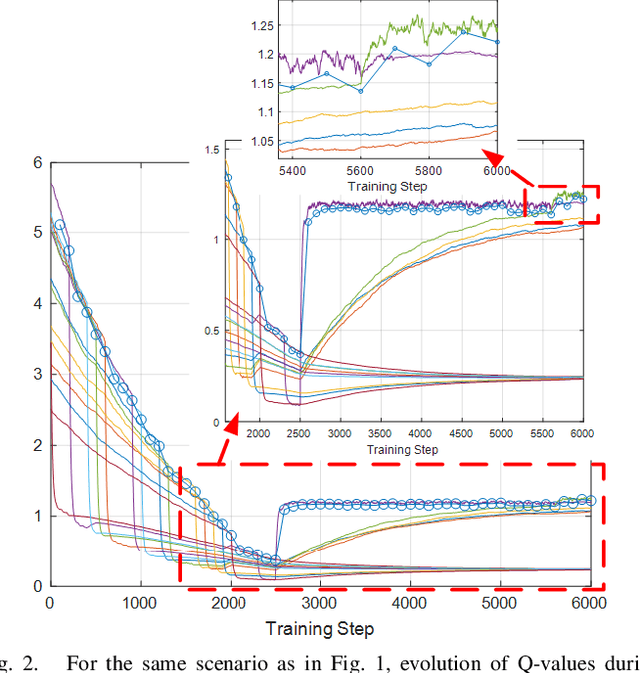
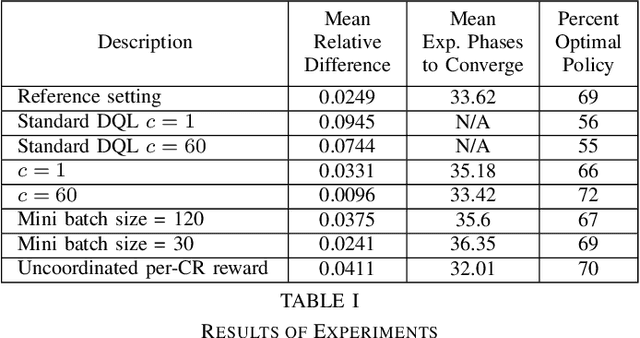
This paper presents a novel deep reinforcement learning-based resource allocation technique for the multi-agent environment presented by a cognitive radio network where the interactions of the agents during learning may lead to a non-stationary environment. The resource allocation technique presented in this work is distributed, not requiring coordination with other agents. It is shown by considering aspects specific to deep reinforcement learning that the presented algorithm converges in an arbitrarily long time to equilibrium policies in a non-stationary multi-agent environment that results from the uncoordinated dynamic interaction between radios through the shared wireless environment. Simulation results show that the presented technique achieves a faster learning performance compared to an equivalent table-based Q-learning algorithm and is able to find the optimal policy in 99% of cases for a sufficiently long learning time. In addition, simulations show that our DQL approach requires less than half the number of learning steps to achieve the same performance as an equivalent table-based implementation. Moreover, it is shown that the use of a standard single-agent deep reinforcement learning approach may not achieve convergence when used in an uncoordinated interacting multi-radio scenario
Deep Reinforcement Learning for Distributed Uncoordinated Cognitive Radios Resource Allocation
Oct 29, 2019This paper presents a novel deep reinforcement learning-based resource allocation technique for the multi-agent environment presented by a cognitive radio network that coexists through underlay dynamic spectrum access (DSA) with a primary network. The resource allocation technique presented in this work is distributed, not requiring coordination with other agents. By ensuring convergence to equilibrium policies almost surely, the presented novel technique succeeds in addressing the challenge of a non-stationary multi-agent environment that results from the dynamic interaction between radios through the shared wireless environment. Simulation results show that in a finite learning time the presented technique is able to find policies that yield performance within 3 % of an exhaustive search solution, finding the optimal policy in nearly 70 % of cases, and that standard single-agent deep reinforcement learning may not achieve convergence when used in a non-coordinated, coupled multi-radio scenario.
Neural Network Cognitive Engine for Autonomous and Distributed Underlay Dynamic Spectrum Access
Jul 05, 2018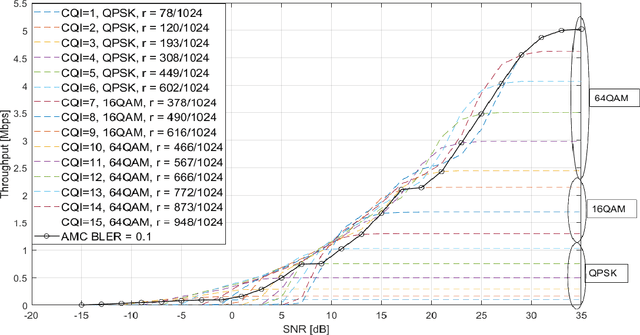
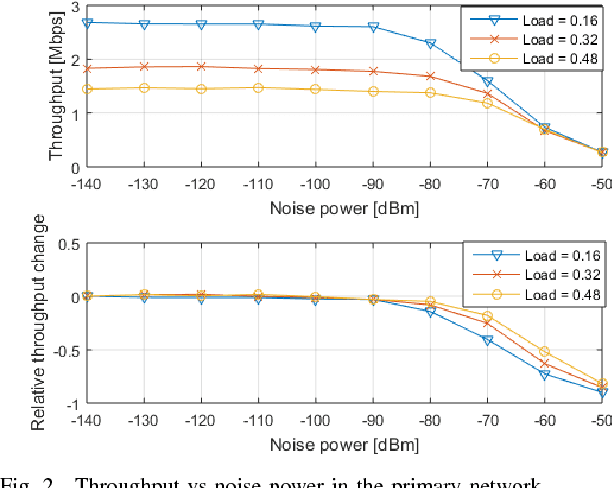
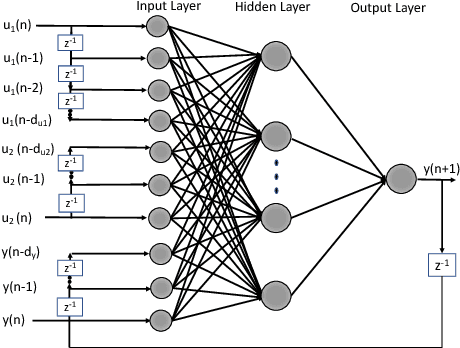

An important challenge in underlay dynamic spectrum access (DSA) is how to establish an interference limit for the primary network (PN) and how cognitive radios (CRs) in the secondary network (SN) become aware of their created interference on the PN, especially when there is no exchange of information between the primary and the secondary networks. This challenge is addressed in this paper by present- ing a fully autonomous and distributed underlay DSA scheme where each CR operates based on predicting its transmission effect on the PN. The scheme is based on a cognitive engine with an artificial neural network that predicts, without exchanging information between the networks, the adaptive modulation and coding configuration for the primary link nearest to a transmitting CR. By managing the tradeoff between the effect of the SN on the PN and the achievable throughput at the SN, the presented technique maintains the change in the PN relative average throughput within a prescribed maximum value, while also finding transmit settings for the CRs that result in throughput as large as allowed by the PN interference limit. Moreover, the proposed technique increases the CRs transmission opportunities compared to a scheme that can only estimate the modulation scheme.