 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Enforcing Better Conditioned Meta-Learning for Rapid Few-Shot Adaptation
Jun 15, 2022
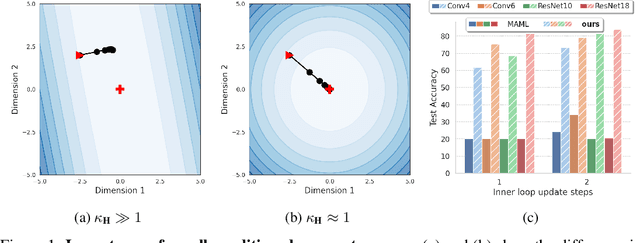

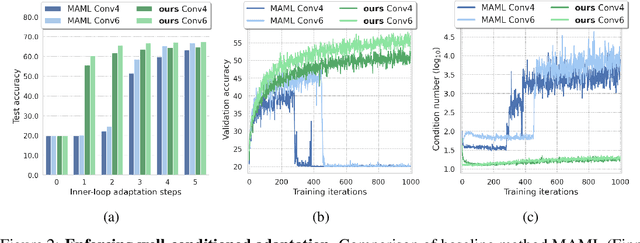
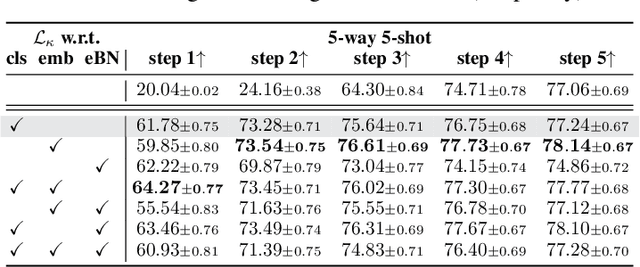
Inspired by the concept of preconditioning, we propose a novel method to increase adaptation speed for gradient-based meta-learning methods without incurring extra parameters. We demonstrate that recasting the optimization problem to a non-linear least-squares formulation provides a principled way to actively enforce a $\textit{well-conditioned}$ parameter space for meta-learning models based on the concepts of the condition number and local curvature. Our comprehensive evaluations show that the proposed method significantly outperforms its unconstrained counterpart especially during initial adaptation steps, while achieving comparable or better overall results on several few-shot classification tasks -- creating the possibility of dynamically choosing the number of adaptation steps at inference time.
AFAFed -- Protocol analysis
Jun 29, 2022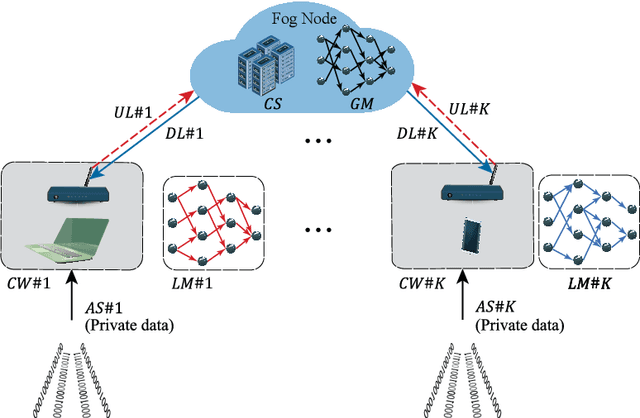
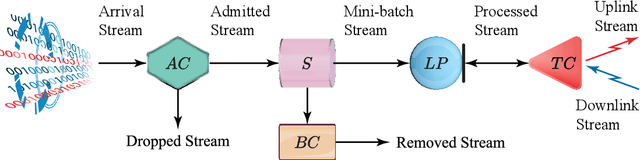
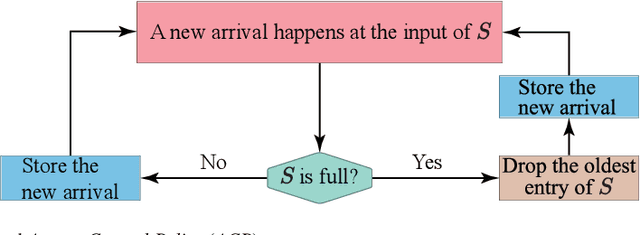
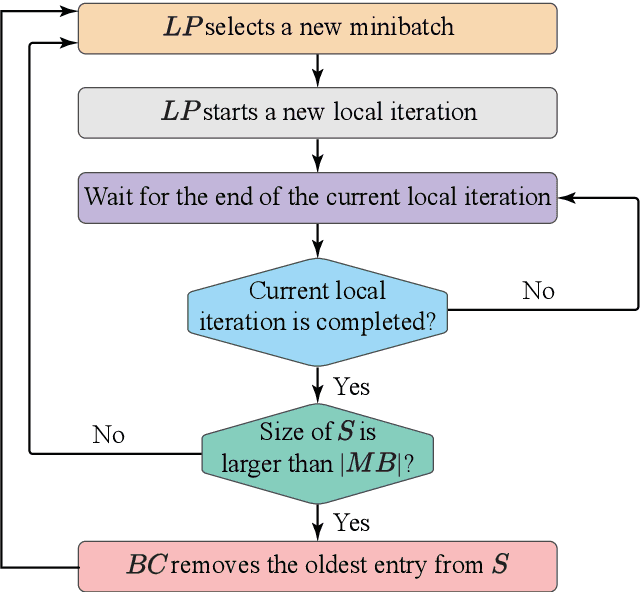
In this paper, we design, analyze the convergence properties and address the implementation aspects of AFAFed. This is a novel Asynchronous Fair Adaptive Federated learning framework for stream-oriented IoT application environments, which are featured by time-varying operating conditions, heterogeneous resource-limited devices (i.e., coworkers), non-i.i.d. local training data and unreliable communication links. The key new of AFAFed is the synergic co-design of: (i) two sets of adaptively tuned tolerance thresholds and fairness coefficients at the coworkers and central server, respectively; and, (ii) a distributed adaptive mechanism, which allows each coworker to adaptively tune own communication rate. The convergence properties of AFAFed under (possibly) non-convex loss functions is guaranteed by a set of new analytical bounds, which formally unveil the impact on the resulting AFAFed convergence rate of a number of Federated Learning (FL) parameters, like, first and second moments of the per-coworker number of consecutive model updates, data skewness, communication packet-loss probability, and maximum/minimum values of the (adaptively tuned) mixing coefficient used for model aggregation.
Towards the Use of Saliency Maps for Explaining Low-Quality Electrocardiograms to End Users
Jul 06, 2022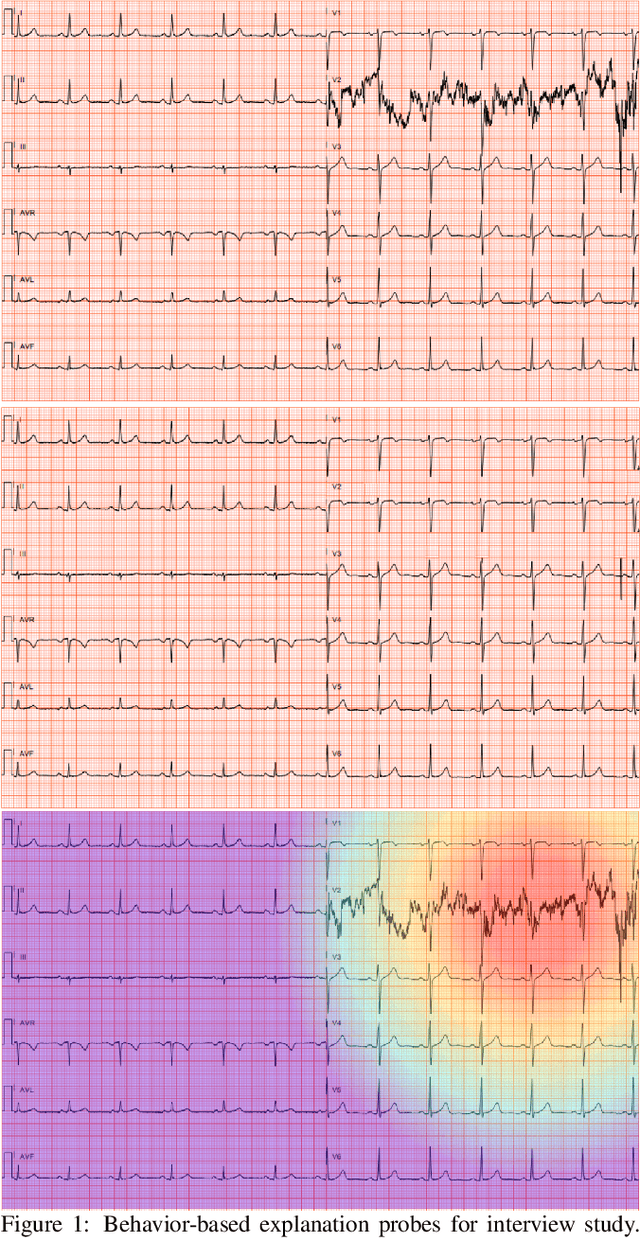

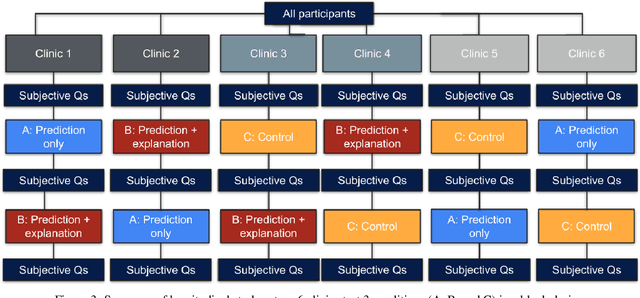
When using medical images for diagnosis, either by clinicians or artificial intelligence (AI) systems, it is important that the images are of high quality. When an image is of low quality, the medical exam that produced the image often needs to be redone. In telemedicine, a common problem is that the quality issue is only flagged once the patient has left the clinic, meaning they must return in order to have the exam redone. This can be especially difficult for people living in remote regions, who make up a substantial portion of the patients at Portal Telemedicina, a digital healthcare organization based in Brazil. In this paper, we report on ongoing work regarding (i) the development of an AI system for flagging and explaining low-quality medical images in real-time, (ii) an interview study to understand the explanation needs of stakeholders using the AI system at OurCompany, and, (iii) a longitudinal user study design to examine the effect of including explanations on the workflow of the technicians in our clinics. To the best of our knowledge, this would be the first longitudinal study on evaluating the effects of XAI methods on end-users -- stakeholders that use AI systems but do not have AI-specific expertise. We welcome feedback and suggestions on our experimental setup.
Traversing Supervisor Problem: An Approximately Optimal Approach to Multi-Robot Assistance
May 03, 2022
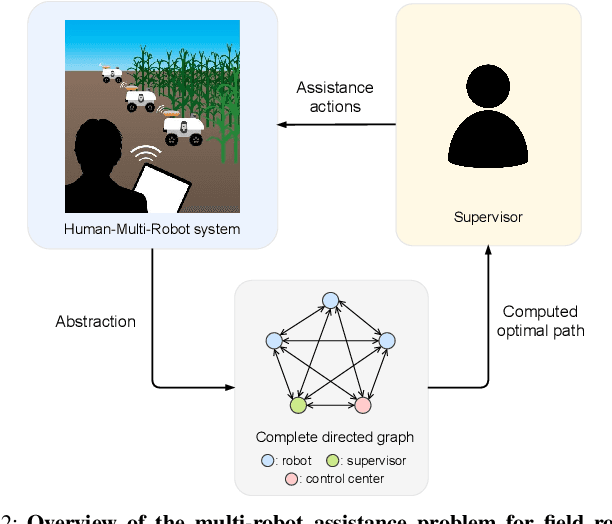
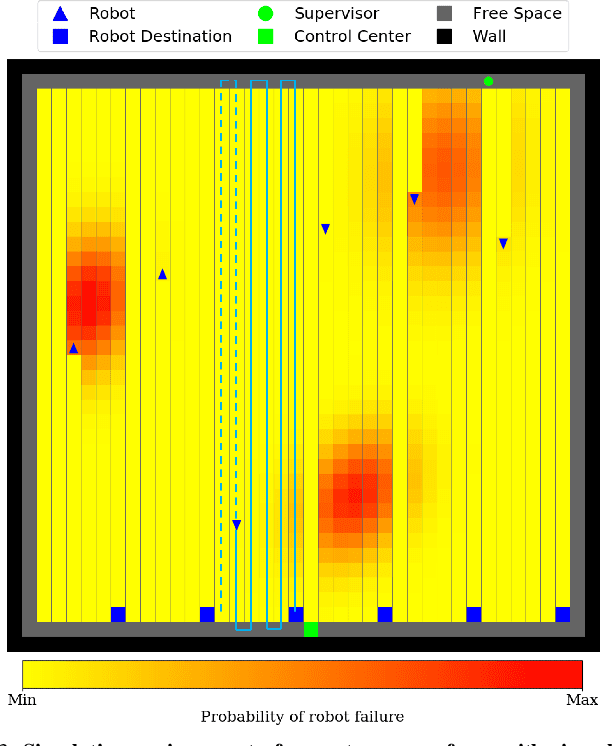
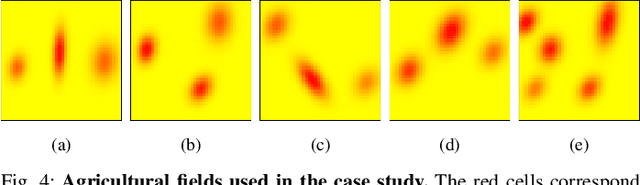
The number of multi-robot systems deployed in field applications has increased dramatically over the years. Despite the recent advancement of navigation algorithms, autonomous robots often encounter challenging situations where the control policy fails and the human assistance is required to resume robot tasks. Human-robot collaboration can help achieve high-levels of autonomy, but monitoring and managing multiple robots at once by a single human supervisor remains a challenging problem. Our goal is to help a supervisor decide which robots to assist in which order such that the team performance can be maximized. We formulate the one-to-many supervision problem in uncertain environments as a dynamic graph traversal problem. An approximation algorithm based on the profitable tour problem on a static graph is developed to solve the original problem, and the approximation error is bounded and analyzed. Our case study on a simulated autonomous farm demonstrates superior team performance than baseline methods in task completion time and human working time, and that our method can be deployed in real-time for robot fleets with moderate size.
Safety Certification for Stochastic Systems via Neural Barrier Functions
Jun 03, 2022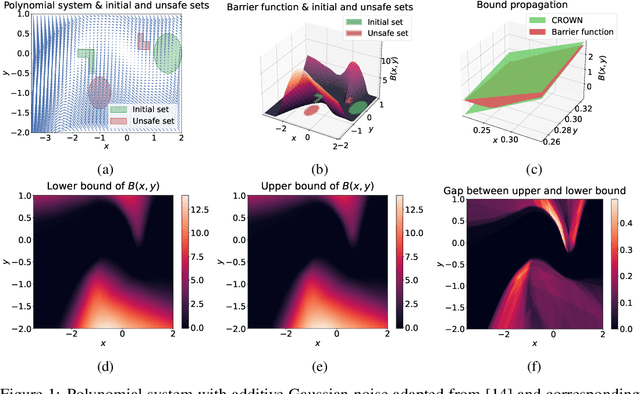
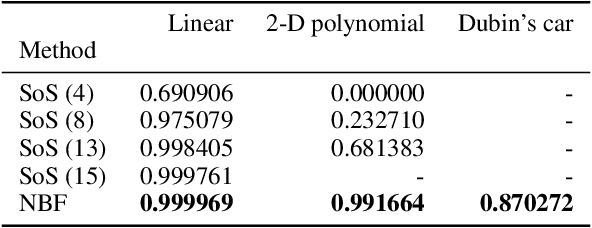
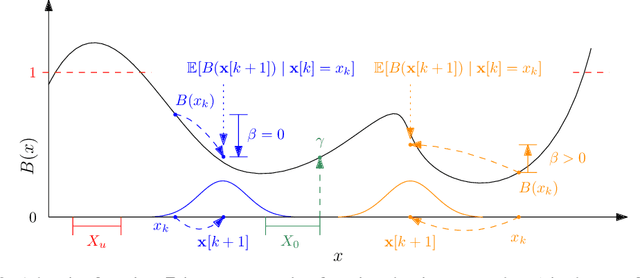
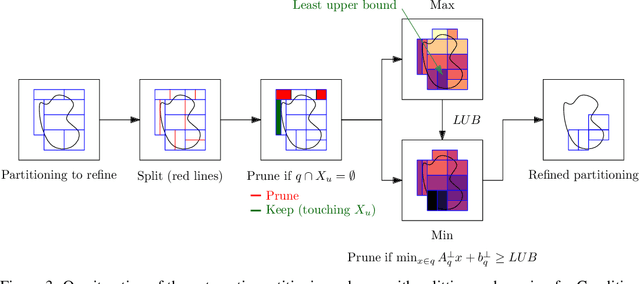
Providing non-trivial certificates of safety for non-linear stochastic systems is an important open problem that limits the wider adoption of autonomous systems in safety-critical applications. One promising solution to address this problem is barrier functions. The composition of a barrier function with a stochastic system forms a supermartingale, thus enabling the computation of the probability that the system stays in a safe set over a finite time horizon via martingale inequalities. However, existing approaches to find barrier functions for stochastic systems generally rely on convex optimization programs that restrict the search of a barrier to a small class of functions such as low degree SoS polynomials and can be computationally expensive. In this paper, we parameterize a barrier function as a neural network and show that techniques for robust training of neural networks can be successfully employed to find neural barrier functions. Specifically, we leverage bound propagation techniques to certify that a neural network satisfies the conditions to be a barrier function via linear programming and then employ the resulting bounds at training time to enforce the satisfaction of these conditions. We also present a branch-and-bound scheme that makes the certification framework scalable. We show that our approach outperforms existing methods in several case studies and often returns certificates of safety that are orders of magnitude larger.
Universality and approximation bounds for echo state networks with random weights
Jun 12, 2022We study the uniform approximation of echo state networks with randomly generated internal weights. These models, in which only the readout weights are optimized during training, have made empirical success in learning dynamical systems. We address the representational capacity of these models by showing that they are universal under weak conditions. Our main result gives a sufficient condition for the activation function and a sampling procedure for the internal weights so that echo state networks can approximate any continuous casual time-invariant operators with high probability. In particular, for ReLU activation, we quantify the approximation error of echo state networks for sufficiently regular operators.
Cascaded Deep Hybrid Models for Multistep Household Energy Consumption Forecasting
Jul 06, 2022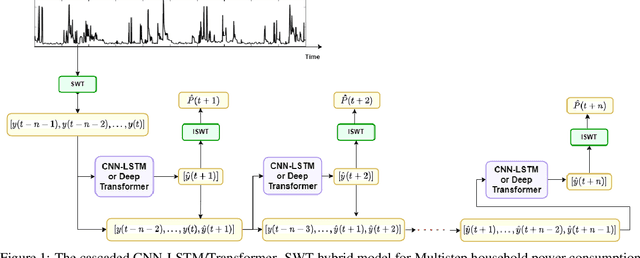
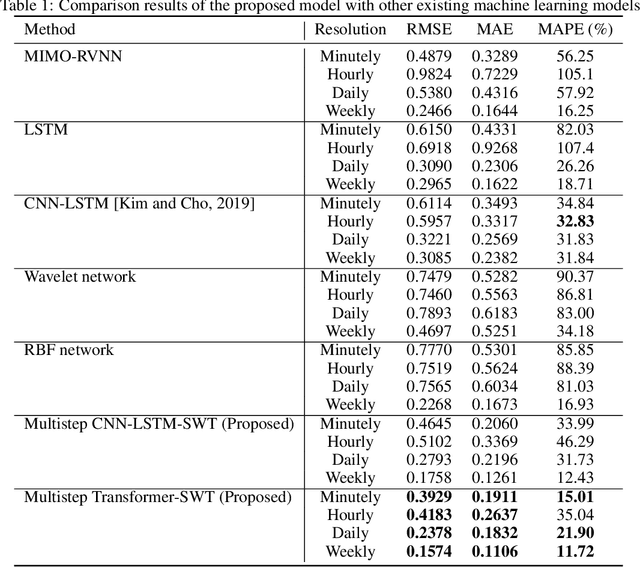
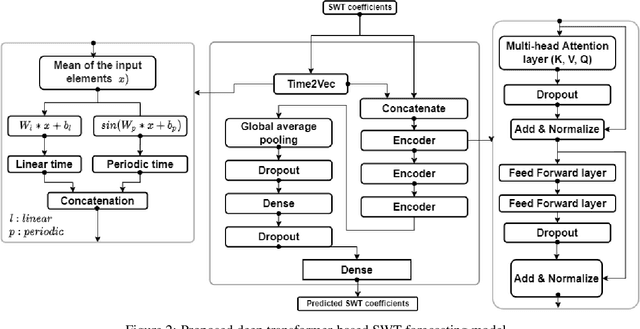
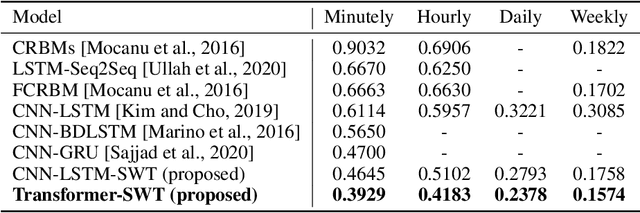
Sustainability requires increased energy efficiency with minimal waste. The future power systems should thus provide high levels of flexibility iin controling energy consumption. Precise projections of future energy demand/load at the aggregate and on the individual site levels are of great importance for decision makers and professionals in the energy industry. Forecasting energy loads has become more advantageous for energy providers and customers, allowing them to establish an efficient production strategy to satisfy demand. This study introduces two hybrid cascaded models for forecasting multistep household power consumption in different resolutions. The first model integrates Stationary Wavelet Transform (SWT), as an efficient signal preprocessing technique, with Convolutional Neural Networks and Long Short Term Memory (LSTM). The second hybrid model combines SWT with a self-attention based neural network architecture named transformer. The major constraint of using time-frequency analysis methods such as SWT in multistep energy forecasting problems is that they require sequential signals, making signal reconstruction problematic in multistep forecasting applications.The cascaded models can efficiently address this problem through using the recursive outputs. Experimental results show that the proposed hybrid models achieve superior prediction performance compared to the existing multistep power consumption prediction methods. The results will pave the way for more accurate and reliable forecasting of household power consumption.
CQC: A Crosstalk-Aware Quantum Program Compilation Framework
Jul 12, 2022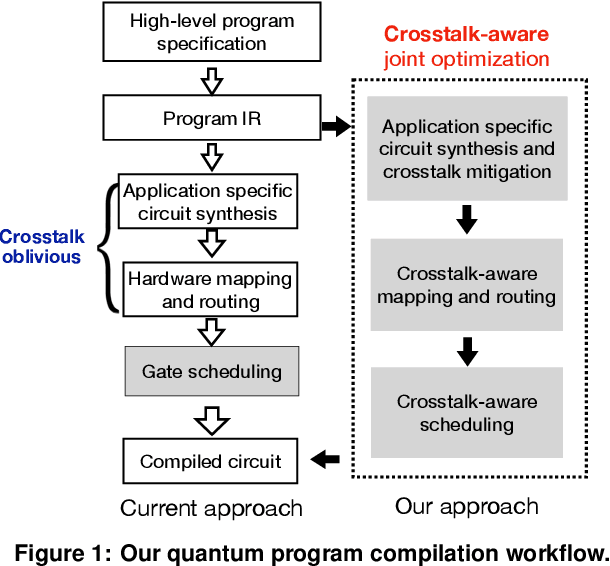
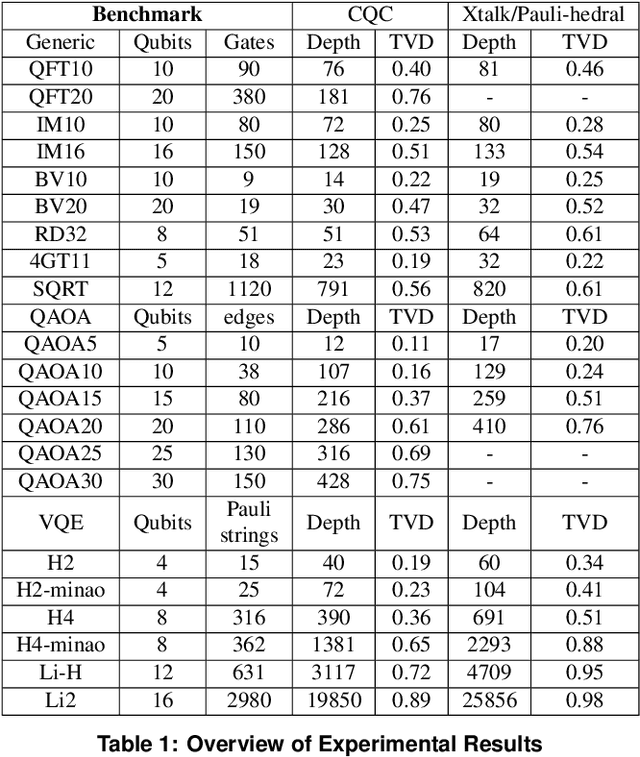
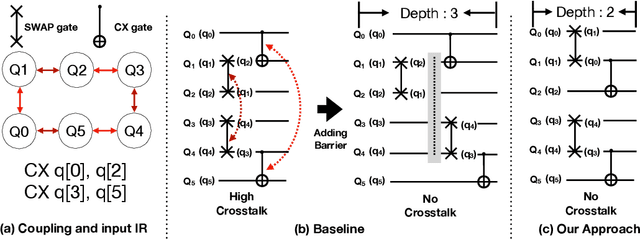
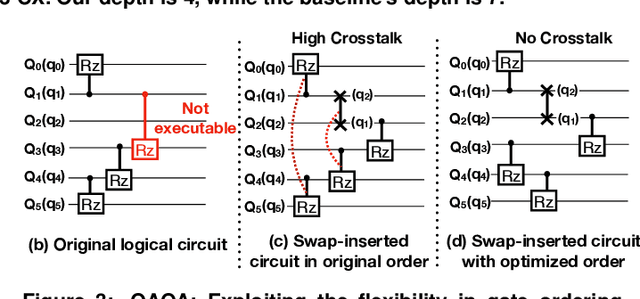
Near-term quantum systems are noisy. Crosstalk noise has been identified as one of the major sources of noises in superconducting Noisy Intermediate-Scale Quantum (NISQ) devices. Crosstalk arises from the concurrent execution of two-qubit gates, such as \texttt{CX}, on nearby qubits. It may significantly increase the error rate of gates compared to running them individually. Crosstalk can be mitigated through scheduling or hardware tuning. Prior studies, however, handle crosstalk at a very late stage in the compilation later, typically after hardware mapping is done. It might miss great opportunities of optimizing algorithm logic, routing, and crosstalk at the same time. In this paper, we push the envelope by considering all these factors simultaneously at the very early compilation stage. We propose a crosstalk-aware quantum program compilation framework called CQC that can enhance crosstalk-mitigation while achieving satisfactory circuit depth. Moreover, we identify opportunities for translation from intermediate representation to the circuit for application-specific crosstalk mitigation, for instance, the \texttt{CX} ladder construction in variational quantum eigensolvers (VQE). Evaluations through simulation and on real IBM-Q devices show that our framework can significantly reduce the error rate by up to 6$\times$, with only $\sim$60\% circuit depth compared to state-of-the-art gate scheduling approaches. In particular for VQE, we demonstrate 49\% circuit depth reduction with 9.6\% fidelity improvement over prior art on the H4 molecule using IBMQ Guadalupe. Our CQC framework will be released on GitHub.
Stream-based Active Learning with Verification Latency in Non-stationary Environments
Apr 14, 2022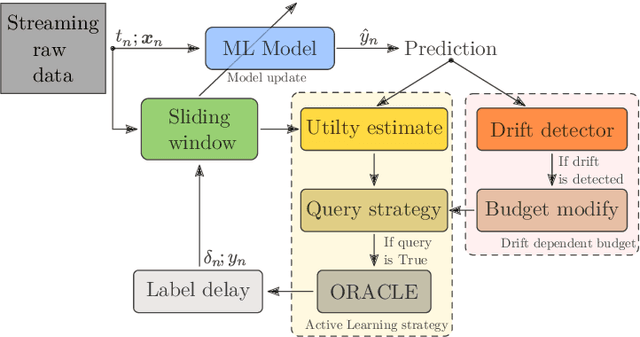
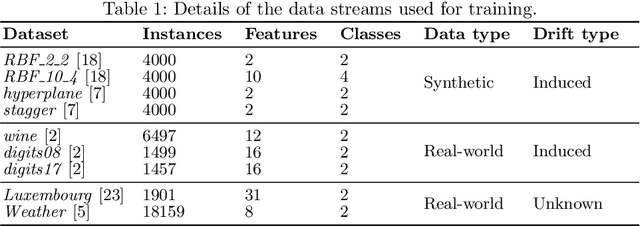
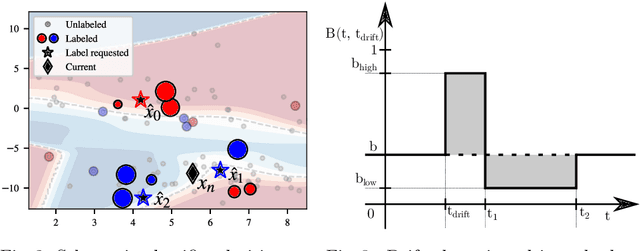
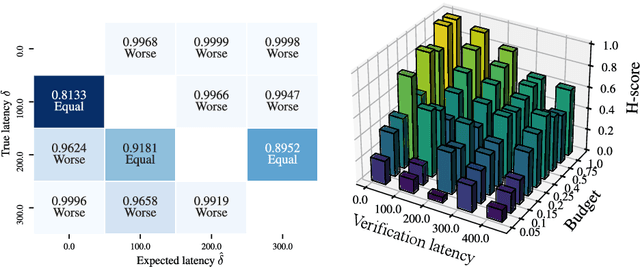
Data stream classification is an important problem in the field of machine learning. Due to the non-stationary nature of the data where the underlying distribution changes over time (concept drift), the model needs to continuously adapt to new data statistics. Stream-based Active Learning (AL) approaches address this problem by interactively querying a human expert to provide new data labels for the most recent samples, within a limited budget. Existing AL strategies assume that labels are immediately available, while in a real-world scenario the expert requires time to provide a queried label (verification latency), and by the time the requested labels arrive they may not be relevant anymore. In this article, we investigate the influence of finite, time-variable, and unknown verification delay, in the presence of concept drift on AL approaches. We propose PRopagate (PR), a latency independent utility estimator which also predicts the requested, but not yet known, labels. Furthermore, we propose a drift-dependent dynamic budget strategy, which uses a variable distribution of the labelling budget over time, after a detected drift. Thorough experimental evaluation, with both synthetic and real-world non-stationary datasets, and different settings of verification latency and budget are conducted and analyzed. We empirically show that the proposed method consistently outperforms the state-of-the-art. Additionally, we demonstrate that with variable budget allocation in time, it is possible to boost the performance of AL strategies, without increasing the overall labeling budget.
Faster Diffusion Cardiac MRI with Deep Learning-based breath hold reduction
Jun 21, 2022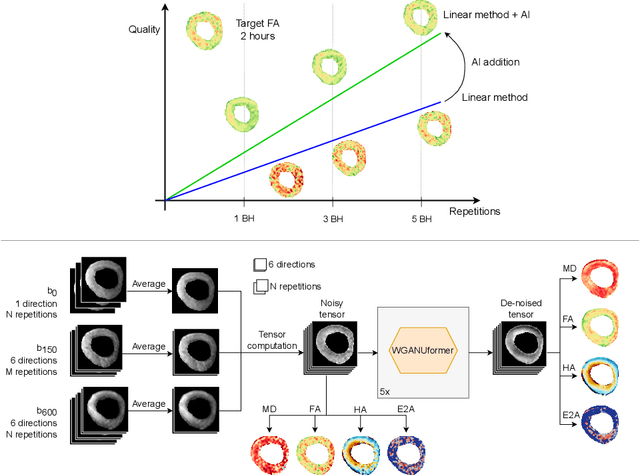
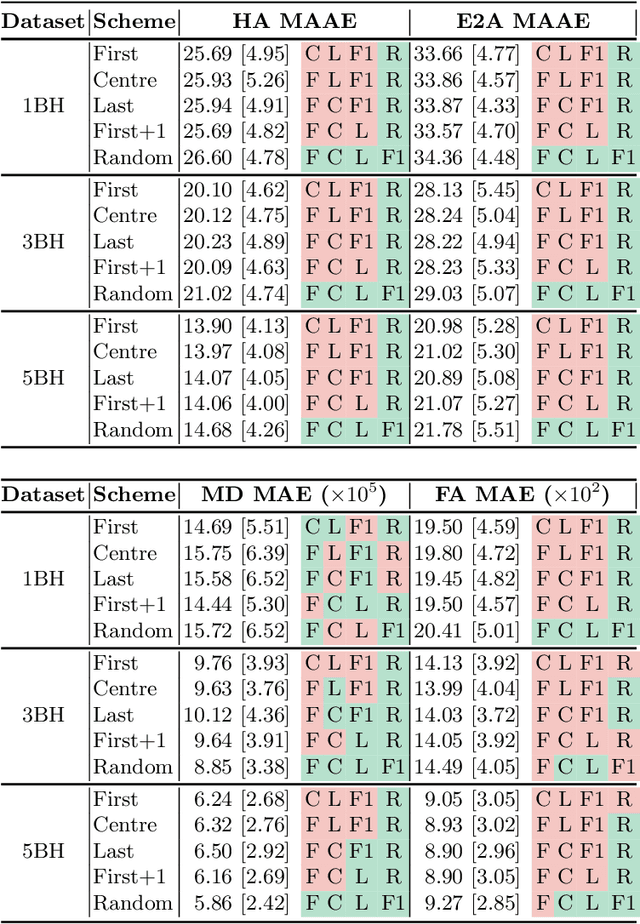
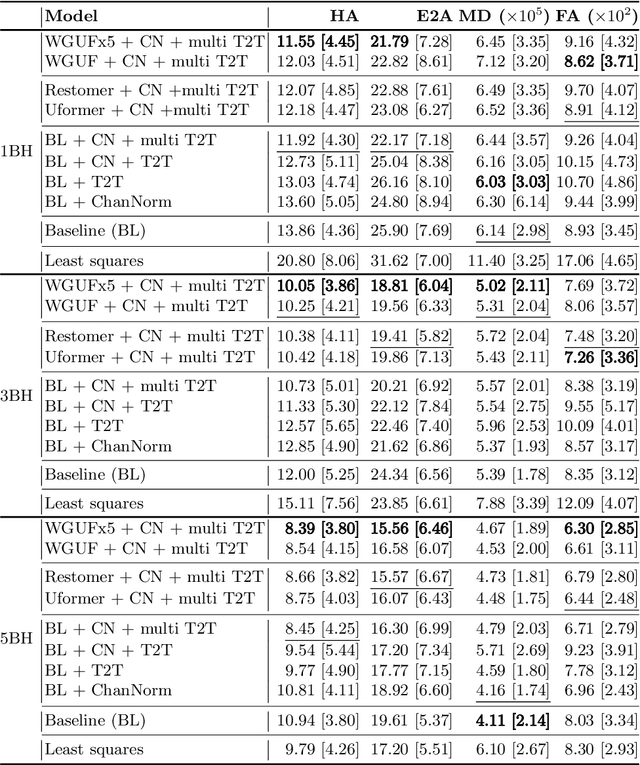
Diffusion Tensor Cardiac Magnetic Resonance (DT-CMR) enables us to probe the microstructural arrangement of cardiomyocytes within the myocardium in vivo and non-invasively, which no other imaging modality allows. This innovative technology could revolutionise the ability to perform cardiac clinical diagnosis, risk stratification, prognosis and therapy follow-up. However, DT-CMR is currently inefficient with over six minutes needed to acquire a single 2D static image. Therefore, DT-CMR is currently confined to research but not used clinically. We propose to reduce the number of repetitions needed to produce DT-CMR datasets and subsequently de-noise them, decreasing the acquisition time by a linear factor while maintaining acceptable image quality. Our proposed approach, based on Generative Adversarial Networks, Vision Transformers, and Ensemble Learning, performs significantly and considerably better than previous proposed approaches, bringing single breath-hold DT-CMR closer to reality.