 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
QHD: A brain-inspired hyperdimensional reinforcement learning algorithm
May 14, 2022
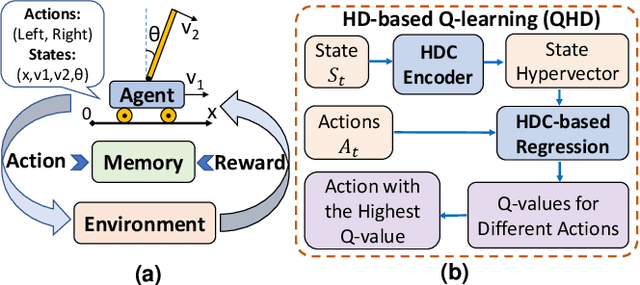
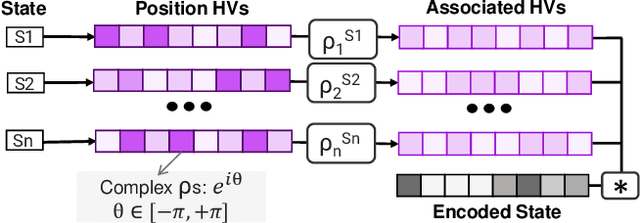
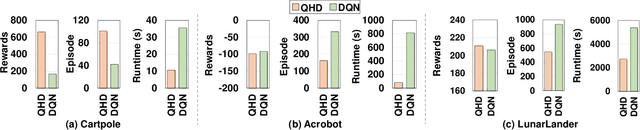
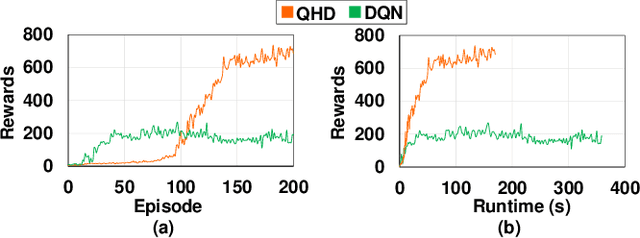
Reinforcement Learning (RL) has opened up new opportunities to solve a wide range of complex decision-making tasks. However, modern RL algorithms, e.g., Deep Q-Learning, are based on deep neural networks, putting high computational costs when running on edge devices. In this paper, we propose QHD, a Hyperdimensional Reinforcement Learning, that mimics brain properties toward robust and real-time learning. QHD relies on a lightweight brain-inspired model to learn an optimal policy in an unknown environment. We first develop a novel mathematical foundation and encoding module that maps state-action space into high-dimensional space. We accordingly develop a hyperdimensional regression model to approximate the Q-value function. The QHD-powered agent makes decisions by comparing Q-values of each possible action. We evaluate the effect of the different RL training batch sizes and local memory capacity on the QHD quality of learning. Our QHD is also capable of online learning with tiny local memory capacity, which can be as small as the training batch size. QHD provides real-time learning by further decreasing the memory capacity and the batch size. This makes QHD suitable for highly-efficient reinforcement learning in the edge environment, where it is crucial to support online and real-time learning. Our solution also supports a small experience replay batch size that provides 12.3 times speedup compared to DQN while ensuring minimal quality loss. Our evaluation shows QHD capability for real-time learning, providing 34.6 times speedup and significantly better quality of learning than state-of-the-art deep RL algorithms.
Detecting Damage Building Using Real-time Crowdsourced Images and Transfer Learning
Oct 12, 2021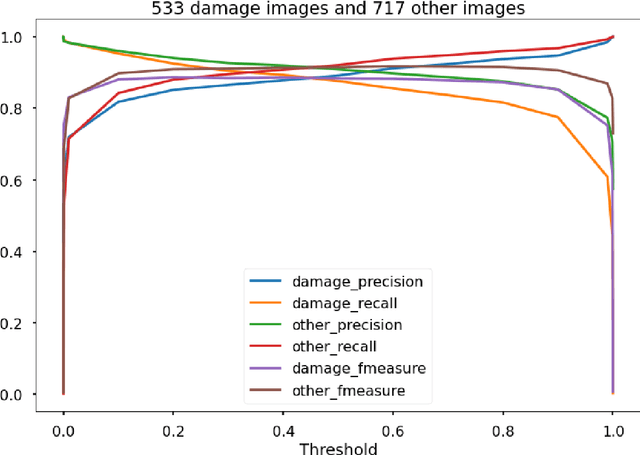


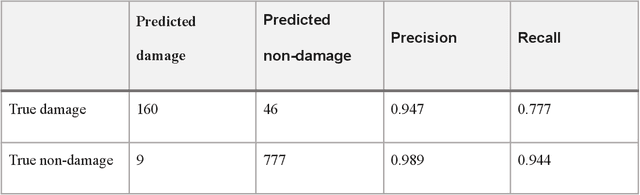
After significant earthquakes, we can see images posted on social media platforms by individuals and media agencies owing to the mass usage of smartphones these days. These images can be utilized to provide information about the shaking damage in the earthquake region both to the public and research community, and potentially to guide rescue work. This paper presents an automated way to extract the damaged building images after earthquakes from social media platforms such as Twitter and thus identify the particular user posts containing such images. Using transfer learning and ~6500 manually labelled images, we trained a deep learning model to recognize images with damaged buildings in the scene. The trained model achieved good performance when tested on newly acquired images of earthquakes at different locations and ran in near real-time on Twitter feed after the 2020 M7.0 earthquake in Turkey. Furthermore, to better understand how the model makes decisions, we also implemented the Grad-CAM method to visualize the important locations on the images that facilitate the decision.
A hybrid approach to seismic deblending: when physics meets self-supervision
May 30, 2022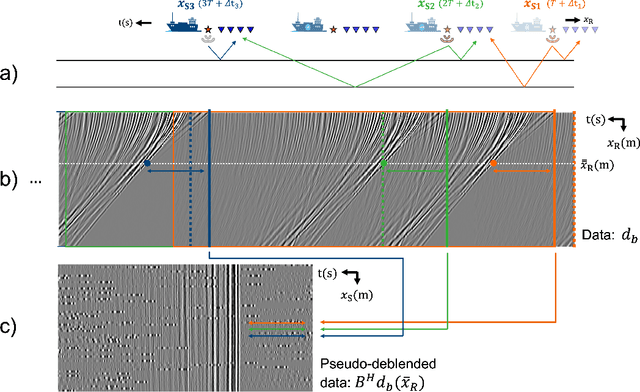
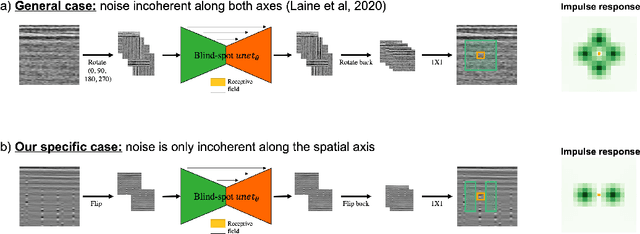
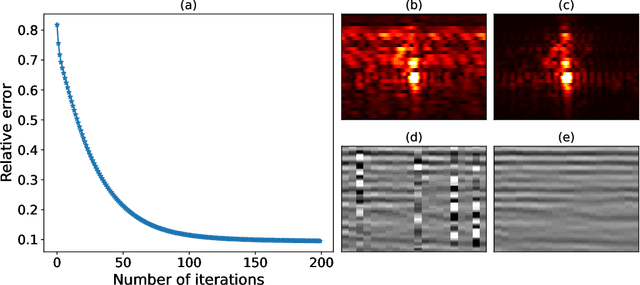
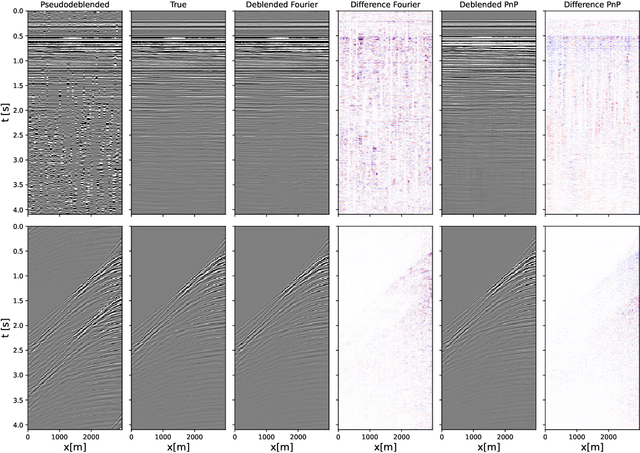
To limit the time, cost, and environmental impact associated with the acquisition of seismic data, in recent decades considerable effort has been put into so-called simultaneous shooting acquisitions, where seismic sources are fired at short time intervals between each other. As a consequence, waves originating from consecutive shots are entangled within the seismic recordings, yielding so-called blended data. For processing and imaging purposes, the data generated by each individual shot must be retrieved. This process, called deblending, is achieved by solving an inverse problem which is heavily underdetermined. Conventional approaches rely on transformations that render the blending noise into burst-like noise, whilst preserving the signal of interest. Compressed sensing type regularization is then applied, where sparsity in some domain is assumed for the signal of interest. The domain of choice depends on the geometry of the acquisition and the properties of seismic data within the chosen domain. In this work, we introduce a new concept that consists of embedding a self-supervised denoising network into the Plug-and-Play (PnP) framework. A novel network is introduced whose design extends the blind-spot network architecture of [28 ] for partially coherent noise (i.e., correlated in time). The network is then trained directly on the noisy input data at each step of the PnP algorithm. By leveraging both the underlying physics of the problem and the great denoising capabilities of our blind-spot network, the proposed algorithm is shown to outperform an industry-standard method whilst being comparable in terms of computational cost. Moreover, being independent on the acquisition geometry, our method can be easily applied to both marine and land data without any significant modification.
Neural Surface Reconstruction of Dynamic Scenes with Monocular RGB-D Camera
Jun 30, 2022
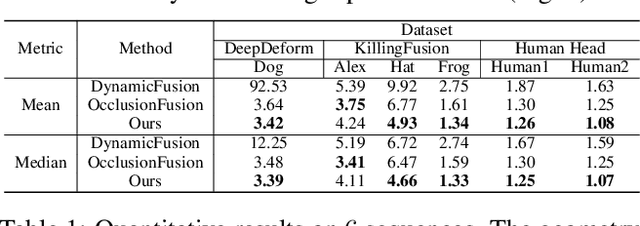
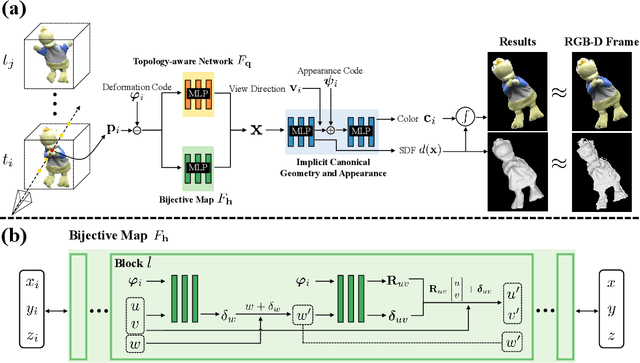

We propose Neural-DynamicReconstruction (NDR), a template-free method to recover high-fidelity geometry and motions of a dynamic scene from a monocular RGB-D camera. In NDR, we adopt the neural implicit function for surface representation and rendering such that the captured color and depth can be fully utilized to jointly optimize the surface and deformations. To represent and constrain the non-rigid deformations, we propose a novel neural invertible deforming network such that the cycle consistency between arbitrary two frames is automatically satisfied. Considering that the surface topology of dynamic scene might change over time, we employ a topology-aware strategy to construct the topology-variant correspondence for the fused frames. NDR also further refines the camera poses in a global optimization manner. Experiments on public datasets and our collected dataset demonstrate that NDR outperforms existing monocular dynamic reconstruction methods.
Mobile MIMO Channel Prediction with ODE-RNN: a Physics-Inspired Adaptive Approach
Jul 08, 2022
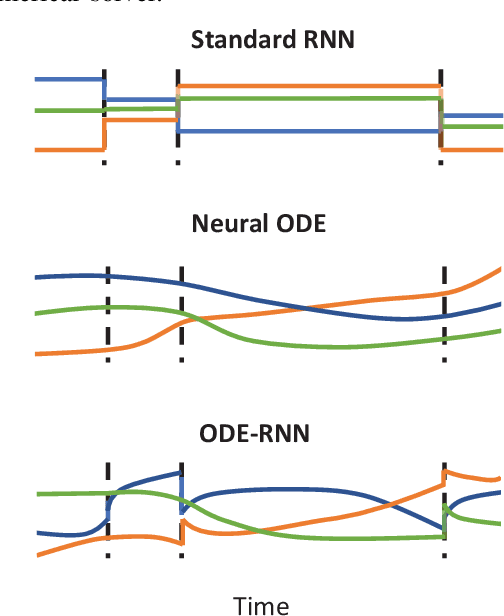
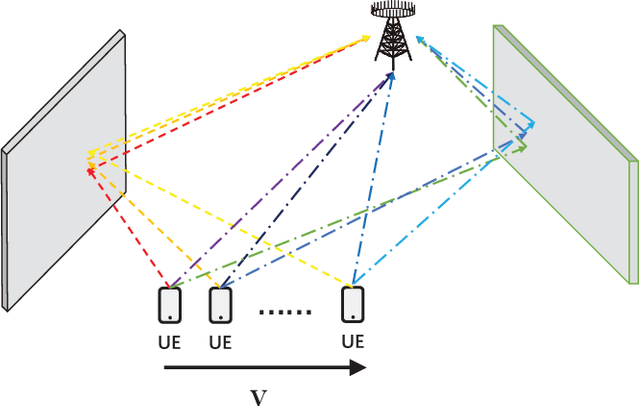
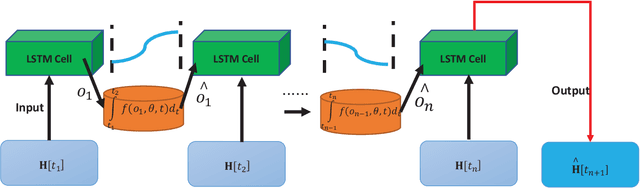
Obtaining accurate channel state information (CSI) is crucial and challenging for multiple-input multiple-output (MIMO) wireless communication systems. Conventional channel estimation method cannot guarantee the accuracy of mobile CSI while requires high signaling overhead. Through exploring the intrinsic correlation among a set of historical CSI instances randomly obtained in a certain communication environment, channel prediction can significantly increase CSI accuracy and save signaling overhead. In this paper, we propose a novel channel prediction method based on ordinary differential equation (ODE)-recurrent neural network (RNN) for accurate and flexible mobile MIMO channel prediction. Differing from existing works using sequential network structures for exploring the numerical correlation between observed data, our proposed method tries to represent the implicit physics process of path responses changing by specially designed continuous learning network with ODE structure. Due to the targeted design of learning network, our proposed method fits the mathematics feature of CSI data better and enjoy higher network interpretability. Experimental results show that the proposed learning approach outperforms existing methods, especially for long time interval of the CSI sequence and large channel measurement error.
MPC with Learned Residual Dynamics with Application on Omnidirectional MAVs
Jul 04, 2022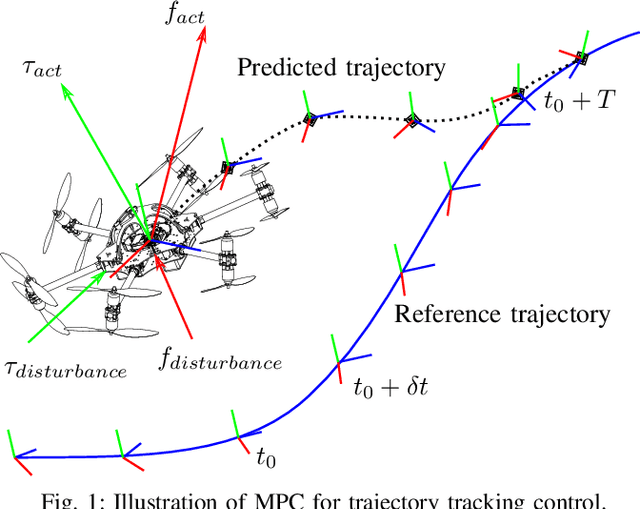
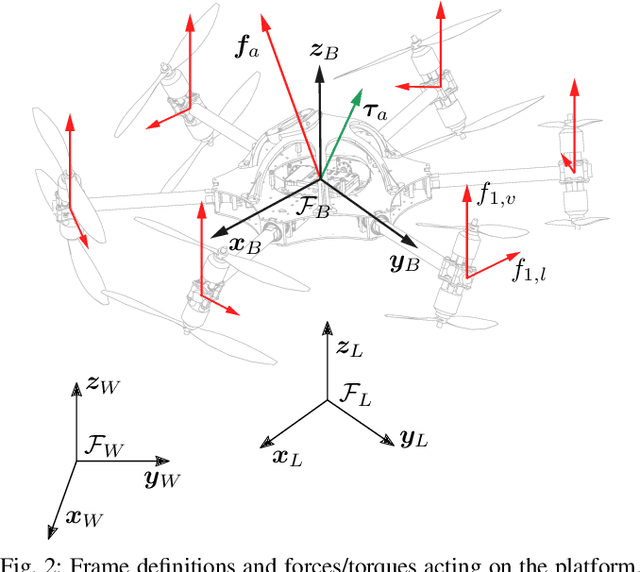
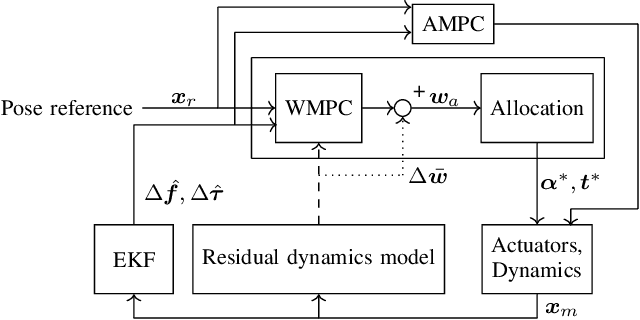
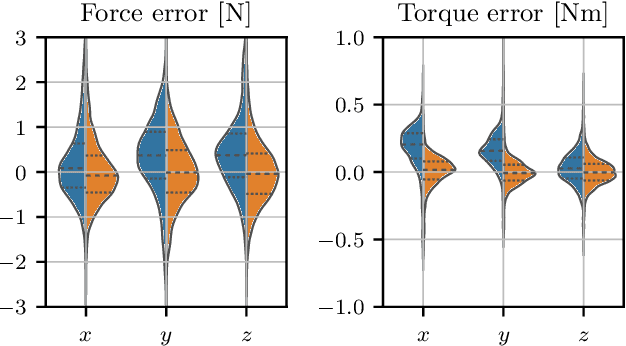
The growing field of aerial manipulation often relies on fully actuated or omnidirectional micro aerial vehicles (OMAVs) which can apply arbitrary forces and torques while in contact with the environment. Control methods are usually based on model-free approaches, separating a high-level wrench controller from an actuator allocation. If necessary, disturbances are rejected by online disturbance observers. However, while being general, this approach often produces sub-optimal control commands and cannot incorporate constraints given by the platform design. We present two model-based approaches to control OMAVs for the task of trajectory tracking while rejecting disturbances. The first one optimizes wrench commands and compensates model errors by a model learned from experimental data. The second one optimizes low-level actuator commands, allowing to exploit an allocation nullspace and to consider constraints given by the actuator hardware. The efficacy and real-time feasibility of both approaches is shown and evaluated in real-world experiments.
A Memory-Efficient Dynamic Image Reconstruction Method using Neural Fields
May 11, 2022
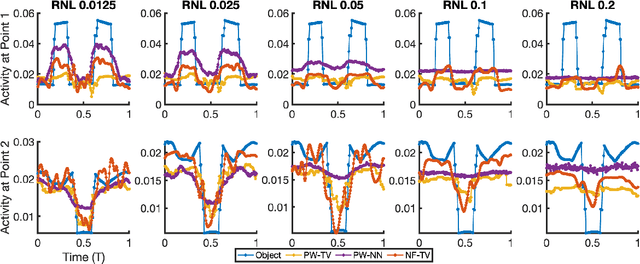
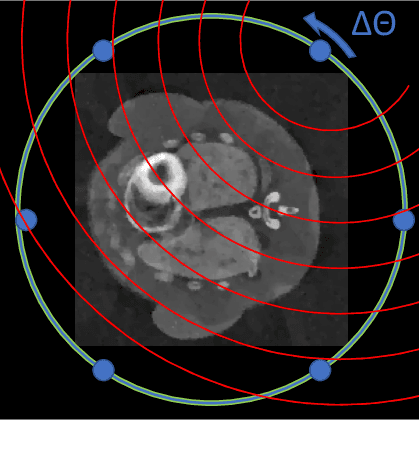
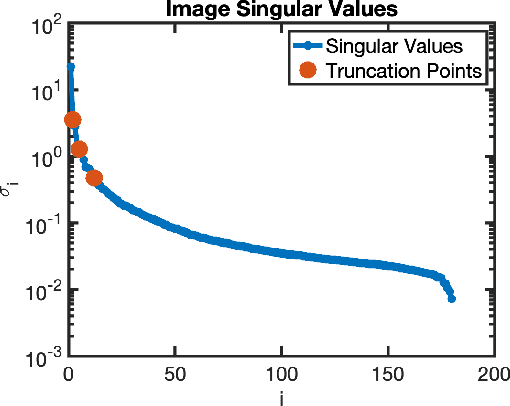
Dynamic imaging is essential for analyzing various biological systems and behaviors but faces two main challenges: data incompleteness and computational burden. For many imaging systems, high frame rates and short acquisition times require severe undersampling, which leads to data incompleteness. Multiple images may then be compatible with the data, thus requiring special techniques (regularization) to ensure the uniqueness of the reconstruction. Computational and memory requirements are particularly burdensome for three-dimensional dynamic imaging applications requiring high resolution in both space and time. Exploiting redundancies in the object's spatiotemporal features is key to addressing both challenges. This contribution investigates neural fields, or implicit neural representations, to model the sought-after dynamic object. Neural fields are a particular class of neural networks that represent the dynamic object as a continuous function of space and time, thus avoiding the burden of storing a full resolution image at each time frame. Neural field representation thus reduces the image reconstruction problem to estimating the network parameters via a nonlinear optimization problem (training). Once trained, the neural field can be evaluated at arbitrary locations in space and time, allowing for high-resolution rendering of the object. Key advantages of the proposed approach are that neural fields automatically learn and exploit redundancies in the sought-after object to both regularize the reconstruction and significantly reduce memory storage requirements. The feasibility of the proposed framework is illustrated with an application to dynamic image reconstruction from severely undersampled circular Radon transform data.
Explore Faster Localization Learning For Scene Text Detection
Jul 04, 2022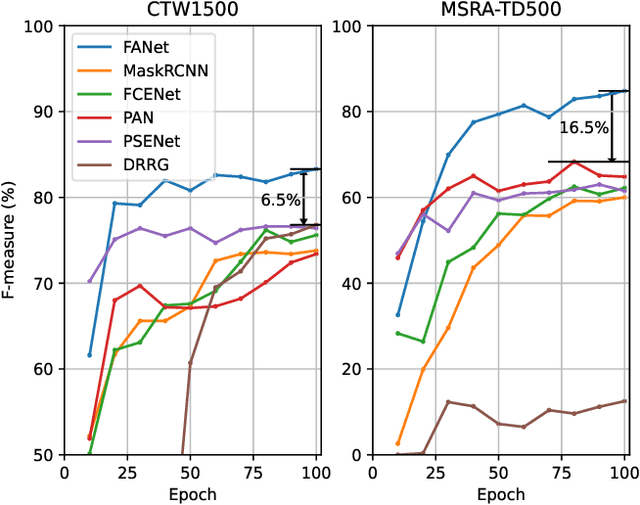
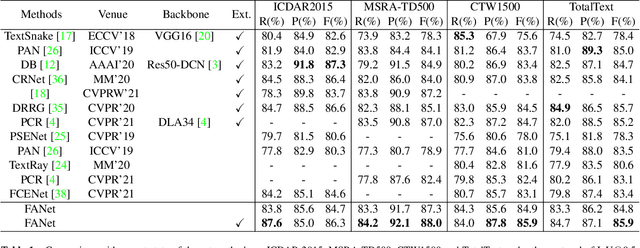
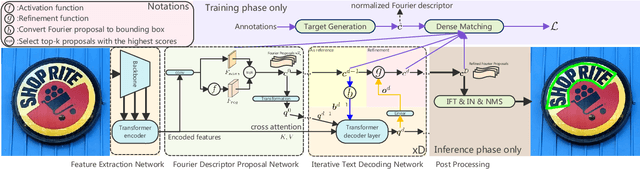

Generally pre-training and long-time training computation are necessary for obtaining a good-performance text detector based on deep networks. In this paper, we present a new scene text detection network (called FANet) with a Fast convergence speed and Accurate text localization. The proposed FANet is an end-to-end text detector based on transformer feature learning and normalized Fourier descriptor modeling, where the Fourier Descriptor Proposal Network and Iterative Text Decoding Network are designed to efficiently and accurately identify text proposals. Additionally, a Dense Matching Strategy and a well-designed loss function are also proposed for optimizing the network performance. Extensive experiments are carried out to demonstrate that the proposed FANet can achieve the SOTA performance with fewer training epochs and no pre-training. When we introduce additional data for pre-training, the proposed FANet can achieve SOTA performance on MSRATD500, CTW1500 and TotalText. The ablation experiments also verify the effectiveness of our contributions.
HTRON:Efficient Outdoor Navigation with Sparse Rewards via Heavy Tailed Adaptive Reinforce Algorithm
Jul 08, 2022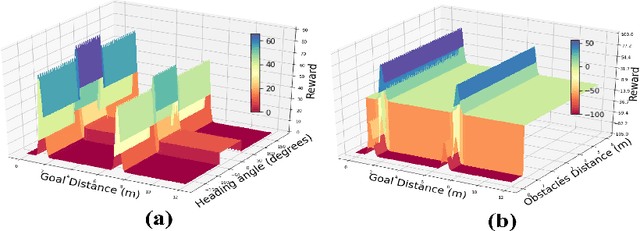
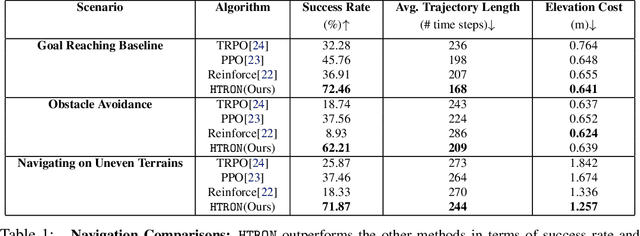
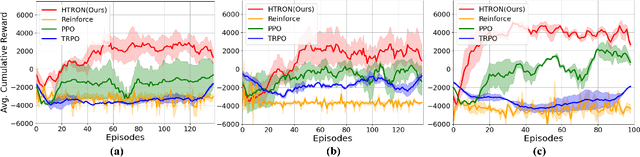
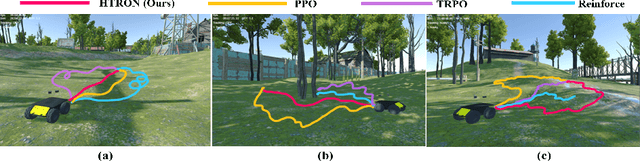
We present a novel approach to improve the performance of deep reinforcement learning (DRL) based outdoor robot navigation systems. Most, existing DRL methods are based on carefully designed dense reward functions that learn the efficient behavior in an environment. We circumvent this issue by working only with sparse rewards (which are easy to design), and propose a novel adaptive Heavy-Tailed Reinforce algorithm for Outdoor Navigation called HTRON. Our main idea is to utilize heavy-tailed policy parametrizations which implicitly induce exploration in sparse reward settings. We evaluate the performance of HTRON against Reinforce, PPO and TRPO algorithms in three different outdoor scenarios: goal-reaching, obstacle avoidance, and uneven terrain navigation. We observe in average an increase of 34.41% in terms of success rate, a 15.15% decrease in the average time steps taken to reach the goal, and a 24.9% decrease in the elevation cost compared to the navigation policies obtained by the other methods. Further, we demonstrate that our algorithm can be transferred directly into a Clearpath Husky robot to perform outdoor terrain navigation in real-world scenarios.
Fessonia: a Method for Real-Time Estimation of Human Operator Workload Using Behavioural Entropy
Oct 05, 2021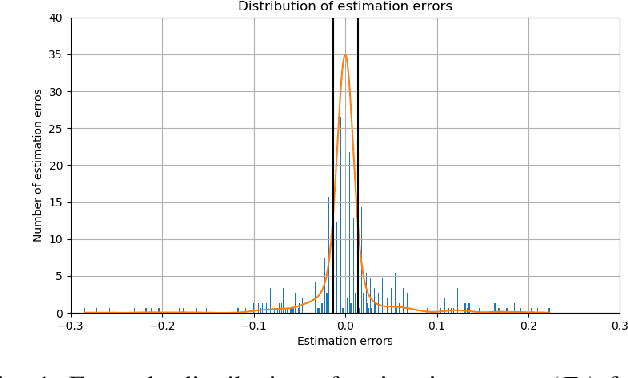
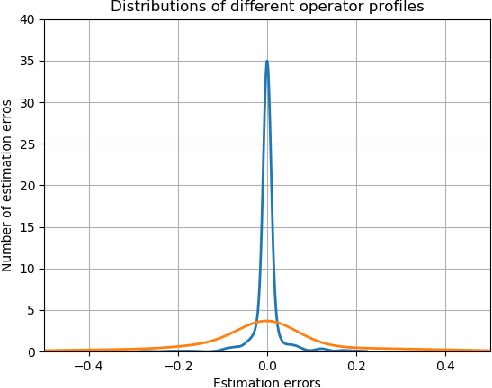
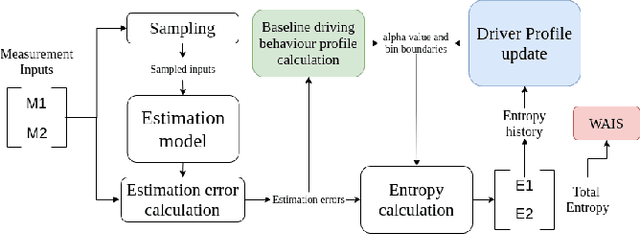
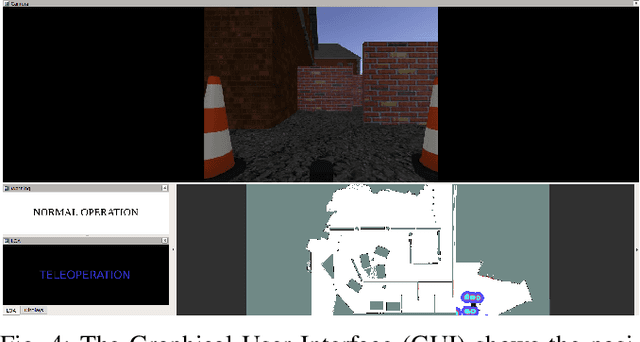
This paper addresses the problem of the human operator cognitive workload estimation while controlling a robot. Being capable of assessing, in real-time, the operator's workload could help prevent calamitous events from occurring. This workload estimation could enable an AI to make informed decisions to assist or advise the operator, in an advanced human-robot interaction framework. We propose a method, named Fessonia, for real-time cognitive workload estimation from multiple parameters of an operator's driving behaviour via the use of behavioural entropy. Fessonia is comprised of: a method to calculate the entropy (i.e. unpredictability) of the operator driving behaviour profile; the Driver Profile Update algorithm which adapts the entropy calculations to the evolving driving profile of individual operators; and a Warning And Indication System that uses workload estimations to issue advice to the operator. Fessonia is evaluated in a robot teleoperation scenario that incorporated cognitively demanding secondary tasks to induce varying degrees of workload. The results demonstrate the ability of Fessonia to estimate different levels of imposed workload. Additionally, it is demonstrated that our approach is able to detect and adapt to the evolving driving profile of the different operators. Lastly, based on data obtained, a decrease in entropy is observed when a warning indication is issued, suggesting a more attentive approach focused on the primary navigation task.