 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
Feb 07, 2024
Recent language model (LM) advancements have showcased impressive zero-shot voice conversion (VC) performance. However, existing LM-based VC models usually apply offline conversion from source semantics to acoustic features, demanding the complete source speech, and limiting their deployment to real-time applications. In this paper, we introduce StreamVoice, a novel streaming LM-based model for zero-shot VC, facilitating real-time conversion given arbitrary speaker prompts and source speech. Specifically, to enable streaming capability, StreamVoice employs a fully causal context-aware LM with a temporal-independent acoustic predictor, while alternately processing semantic and acoustic features at each time step of autoregression which eliminates the dependence on complete source speech. To address the potential performance degradation from the incomplete context in streaming processing, we enhance the context-awareness of the LM through two strategies: 1) teacher-guided context foresight, using a teacher model to summarize the present and future semantic context during training to guide the model's forecasting for missing context; 2) semantic masking strategy, promoting acoustic prediction from preceding corrupted semantic and acoustic input, enhancing context-learning ability. Notably, StreamVoice is the first LM-based streaming zero-shot VC model without any future look-ahead. Experimental results demonstrate StreamVoice's streaming conversion capability while maintaining zero-shot performance comparable to non-streaming VC systems.
An Empirical Study of Challenges in Machine Learning Asset Management
Feb 28, 2024In machine learning (ML), efficient asset management, including ML models, datasets, algorithms, and tools, is vital for resource optimization, consistent performance, and a streamlined development lifecycle. This enables quicker iterations, adaptability, reduced development-to-deployment time, and reliable outputs. Despite existing research, a significant knowledge gap remains in operational challenges like model versioning, data traceability, and collaboration, which are crucial for the success of ML projects. Our study aims to address this gap by analyzing 15,065 posts from developer forums and platforms, employing a mixed-method approach to classify inquiries, extract challenges using BERTopic, and identify solutions through open card sorting and BERTopic clustering. We uncover 133 topics related to asset management challenges, grouped into 16 macro-topics, with software dependency, model deployment, and model training being the most discussed. We also find 79 solution topics, categorized under 18 macro-topics, highlighting software dependency, feature development, and file management as key solutions. This research underscores the need for further exploration of identified pain points and the importance of collaborative efforts across academia, industry, and the research community.
DAGnosis: Localized Identification of Data Inconsistencies using Structures
Feb 28, 2024Identification and appropriate handling of inconsistencies in data at deployment time is crucial to reliably use machine learning models. While recent data-centric methods are able to identify such inconsistencies with respect to the training set, they suffer from two key limitations: (1) suboptimality in settings where features exhibit statistical independencies, due to their usage of compressive representations and (2) lack of localization to pin-point why a sample might be flagged as inconsistent, which is important to guide future data collection. We solve these two fundamental limitations using directed acyclic graphs (DAGs) to encode the training set's features probability distribution and independencies as a structure. Our method, called DAGnosis, leverages these structural interactions to bring valuable and insightful data-centric conclusions. DAGnosis unlocks the localization of the causes of inconsistencies on a DAG, an aspect overlooked by previous approaches. Moreover, we show empirically that leveraging these interactions (1) leads to more accurate conclusions in detecting inconsistencies, as well as (2) provides more detailed insights into why some samples are flagged.
LeMo-NADe: Multi-Parameter Neural Architecture Discovery with LLMs
Feb 28, 2024Building efficient neural network architectures can be a time-consuming task requiring extensive expert knowledge. This task becomes particularly challenging for edge devices because one has to consider parameters such as power consumption during inferencing, model size, inferencing speed, and CO2 emissions. In this article, we introduce a novel framework designed to automatically discover new neural network architectures based on user-defined parameters, an expert system, and an LLM trained on a large amount of open-domain knowledge. The introduced framework (LeMo-NADe) is tailored to be used by non-AI experts, does not require a predetermined neural architecture search space, and considers a large set of edge device-specific parameters. We implement and validate this proposed neural architecture discovery framework using CIFAR-10, CIFAR-100, and ImageNet16-120 datasets while using GPT-4 Turbo and Gemini as the LLM component. We observe that the proposed framework can rapidly (within hours) discover intricate neural network models that perform extremely well across a diverse set of application settings defined by the user.
Multistatic-Radar RCS-Signature Recognition of Aerial Vehicles: A Bayesian Fusion Approach
Feb 28, 2024Radar Automated Target Recognition (RATR) for Unmanned Aerial Vehicles (UAVs) involves transmitting Electromagnetic Waves (EMWs) and performing target type recognition on the received radar echo, crucial for defense and aerospace applications. Previous studies highlighted the advantages of multistatic radar configurations over monostatic ones in RATR. However, fusion methods in multistatic radar configurations often suboptimally combine classification vectors from individual radars probabilistically. To address this, we propose a fully Bayesian RATR framework employing Optimal Bayesian Fusion (OBF) to aggregate classification probability vectors from multiple radars. OBF, based on expected 0-1 loss, updates a Recursive Bayesian Classification (RBC) posterior distribution for target UAV type, conditioned on historical observations across multiple time steps. We evaluate the approach using simulated random walk trajectories for seven drones, correlating target aspect angles to Radar Cross Section (RCS) measurements in an anechoic chamber. Comparing against single radar Automated Target Recognition (ATR) systems and suboptimal fusion methods, our empirical results demonstrate that the OBF method integrated with RBC significantly enhances classification accuracy compared to other fusion methods and single radar configurations.
Leveraging Compliant Tactile Perception for Haptic Blind Surface Reconstruction
Feb 28, 2024Non-flat surfaces pose difficulties for robots operating in unstructured environments. Reconstructions of uneven surfaces may only be partially possible due to non-compliant end-effectors and limitations on vision systems such as transparency, reflections, and occlusions. This study achieves blind surface reconstruction by harnessing the robotic manipulator's kinematic data and a compliant tactile sensing module, which incorporates inertial, magnetic, and pressure sensors. The module's flexibility enables us to estimate contact positions and surface normals by analyzing its deformation during interactions with unknown objects. While previous works collect only positional information, we include the local normals in a geometrical approach to estimate curvatures between adjacent contact points. These parameters then guide a spline-based patch generation, which allows us to recreate larger surfaces without an increase in complexity while reducing the time-consuming step of probing the surface. Experimental validation demonstrates that this approach outperforms an off-the-shelf vision system in estimation accuracy. Moreover, this compliant haptic method works effectively even when the manipulator's approach angle is not aligned with the surface normals, which is ideal for unknown non-flat surfaces.
Redefining Aerial Innovation: Autonomous Tethered Drones as a Solution to Battery Life and Data Latency Challenges
Feb 28, 2024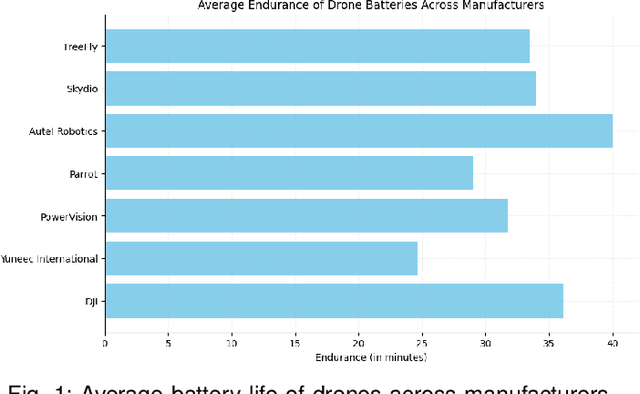
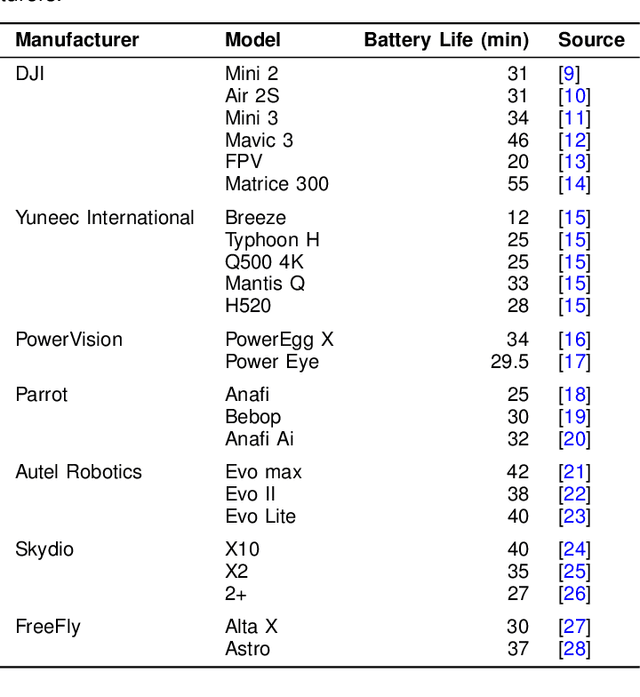
The emergence of tethered drones represents a major advancement in unmanned aerial vehicles (UAVs) offering solutions to key limitations faced by traditional drones. This article explores the potential of tethered drones with a particular focus on their ability to tackle issues related to battery life constraints and data latency commonly experienced by battery operated drones. Through their connection to a ground station via a tether, autonomous tethered drones provide continuous power supply and a secure direct data transmission link facilitating prolonged operational durations and real time data transfer. These attributes significantly enhance the effectiveness and dependability of drone missions in scenarios requiring extended surveillance, continuous monitoring and immediate data processing needs. Examining the advancements, operational benefits and potential future progressions associated with tethered drones, this article shows their increasing significance across various sectors and their pivotal role in pushing the boundaries of current UAV capabilities. The emergence of tethered drone technology not only addresses existing obstacles but also paves the way for new innovations within the UAV industry.
A Quick Framework for Evaluating Worst Robustness of Complex Networks
Feb 28, 2024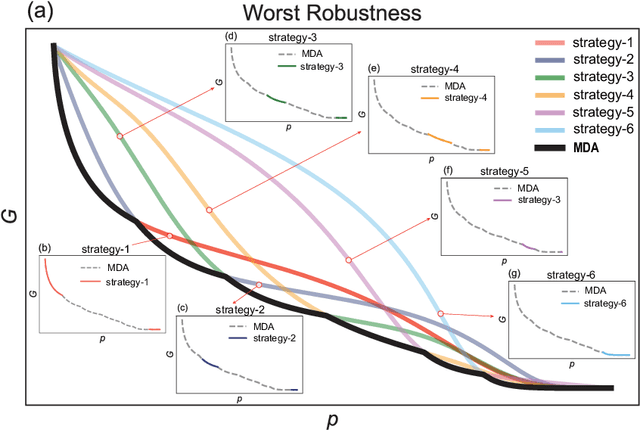
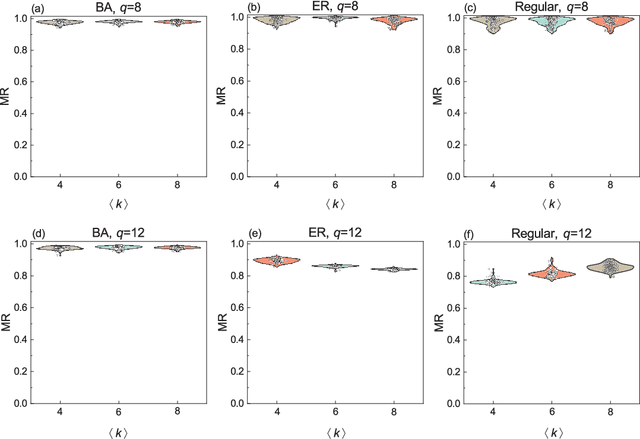
Robustness is pivotal for comprehending, designing, optimizing, and rehabilitating networks, with simulation attacks being the prevailing evaluation method. Simulation attacks are often time-consuming or even impractical, however, a more crucial yet persistently overlooked drawback is that any attack strategy merely provides a potential paradigm of disintegration. The key concern is: in the worst-case scenario or facing the most severe attacks, what is the limit of robustness, referred to as ``Worst Robustness'', for a given system? Understanding a system's worst robustness is imperative for grasping its reliability limits, accurately evaluating protective capabilities, and determining associated design and security maintenance costs. To address these challenges, we introduce the concept of Most Destruction Attack (MDA) based on the idea of knowledge stacking. MDA is employed to assess the worst robustness of networks, followed by the application of an adapted CNN algorithm for rapid worst robustness prediction. We establish the logical validity of MDA and highlight the exceptional performance of the adapted CNN algorithm in predicting the worst robustness across diverse network topologies, encompassing both model and empirical networks.
From Text Segmentation to Smart Chaptering: A Novel Benchmark for Structuring Video Transcriptions
Feb 27, 2024Text segmentation is a fundamental task in natural language processing, where documents are split into contiguous sections. However, prior research in this area has been constrained by limited datasets, which are either small in scale, synthesized, or only contain well-structured documents. In this paper, we address these limitations by introducing a novel benchmark YTSeg focusing on spoken content that is inherently more unstructured and both topically and structurally diverse. As part of this work, we introduce an efficient hierarchical segmentation model MiniSeg, that outperforms state-of-the-art baselines. Lastly, we expand the notion of text segmentation to a more practical "smart chaptering" task that involves the segmentation of unstructured content, the generation of meaningful segment titles, and a potential real-time application of the models.
A Literature Review of Literature Reviews in Pattern Analysis and Machine Intelligence
Feb 29, 2024By consolidating scattered knowledge, the literature review provides a comprehensive understanding of the investigated topic. However, excessive reviews, especially in the booming field of pattern analysis and machine intelligence (PAMI), raise concerns for both researchers and reviewers. In response to these concerns, this Analysis aims to provide a thorough review of reviews in the PAMI field from diverse perspectives. First, large language model-empowered bibliometric indicators are proposed to evaluate literature reviews automatically. To facilitate this, a meta-data database dubbed RiPAMI, and a topic dataset are constructed, which are utilized to obtain statistical characteristics of PAMI reviews. Unlike traditional bibliometric measurements, the proposed article-level indicators provide real-time and field-normalized quantified assessments of reviews without relying on user-defined keywords. Second, based on these indicators, the study presents comparative analyses of different reviews, unveiling the characteristics of publications across various fields, periods, and journals. The newly emerging AI-generated literature reviews are also appraised, and the observed differences suggest that most AI-generated reviews still lag behind human-authored reviews in several aspects. Third, we briefly provide a subjective evaluation of representative PAMI reviews and introduce a paper structure-based typology of literature reviews. This typology may improve the clarity and effectiveness for scholars in reading and writing reviews, while also serving as a guide for AI systems in generating well-organized reviews. Finally, this Analysis offers insights into the current challenges of literature reviews and envisions future directions for their development.