 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Evaluation Engineering: An Empirical Study of ML Evaluation Harnesses in the Wild
May 22, 2026Evaluation harnesses are software systems that orchestrate model evaluation by managing model invocation, data loading, metric computation, and result reporting. Despite their critical role in machine learning infrastructure, their operational challenges and engineering concerns have received limited attention so far. We present an empirical study of 57 evaluation harnesses, deriving a five-stage harness model and classifying 16,560 issues by workflow stage and root cause. Most harness operational challenges concentrate in the Specification stage (41.4% of issues), where harnesses integrate external models, datasets, and scoring judges. The three most frequent root causes of operational challenges are unimplemented features (24.3%), documentation gaps (20.3%), and missing input validation (17.2%), which together account for 61.7% of classified issues, spanning both defects in existing functionality and capability gaps that block intended workflows. Root causes also vary by workflow stage: environment incompatibility and external dependency breakage account for 36.2% of provisioning issues, whereas algorithmic error (25.9%) and validation gap (22.5%) dominate assessment issues. Together, these contributions establish an empirical foundation for treating evaluation engineering as a distinct software engineering concern.
From Leaderboard to Deployment: Code Quality Challenges in AV Perception Repositories
Mar 02, 2026Autonomous vehicle (AV) perception models are typically evaluated solely on benchmark performance metrics, with limited attention to code quality, production readiness and long-term maintainability. This creates a significant gap between research excellence and real-world deployment in safety-critical systems subject to international safety standards. To address this gap, we present the first large-scale empirical study of software quality in AV perception repositories, systematically analyzing 178 unique models from the KITTI and NuScenes 3D Object Detection leaderboards. Using static analysis tools (Pylint, Bandit, and Radon), we evaluated code errors, security vulnerabilities, maintainability, and development practices. Our findings revealed that only 7.3% of the studied repositories meet basic production-readiness criteria, defined as having zero critical errors and no high-severity security vulnerabilities. Security issues are highly concentrated, with the top five issues responsible for almost 80% of occurrences, which prompted us to develop a set of actionable guidelines to prevent them. Additionally, the adoption of Continuous Integration/Continuous Deployment pipelines was correlated with better code maintainability. Our findings highlight that leaderboard performance does not reflect production readiness and that targeted interventions could substantially improve the quality and safety of AV perception code.
Permissive-Washing in the Open AI Supply Chain: A Large-Scale Audit of License Integrity
Feb 09, 2026Permissive licenses like MIT, Apache-2.0, and BSD-3-Clause dominate open-source AI, signaling that artifacts like models, datasets, and code can be freely used, modified, and redistributed. However, these licenses carry mandatory requirements: include the full license text, provide a copyright notice, and preserve upstream attribution, that remain unverified at scale. Failure to meet these conditions can place reuse outside the scope of the license, effectively leaving AI artifacts under default copyright for those uses and exposing downstream users to litigation. We call this phenomenon ``permissive washing'': labeling AI artifacts as free to use, while omitting the legal documentation required to make that label actionable. To assess how widespread permissive washing is in the AI supply chain, we empirically audit 124,278 dataset $\rightarrow$ model $\rightarrow$ application supply chains, spanning 3,338 datasets, 6,664 models, and 28,516 applications across Hugging Face and GitHub. We find that an astonishing 96.5\% of datasets and 95.8\% of models lack the required license text, only 2.3\% of datasets and 3.2\% of models satisfy both license text and copyright requirements, and even when upstream artifacts provide complete licensing evidence, attribution rarely propagates downstream: only 27.59\% of models preserve compliant dataset notices and only 5.75\% of applications preserve compliant model notices (with just 6.38\% preserving any linked upstream notice). Practitioners cannot assume permissive labels confer the rights they claim: license files and notices, not metadata, are the source of legal truth. To support future research, we release our full audit dataset and reproducible pipeline.
Understanding Prompt Management in GitHub Repositories: A Call for Best Practices
Sep 15, 2025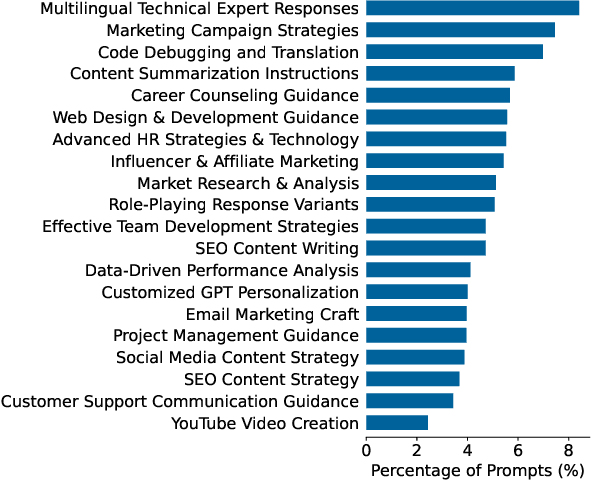
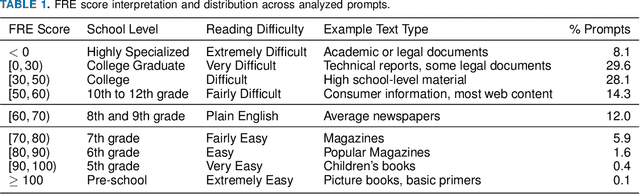
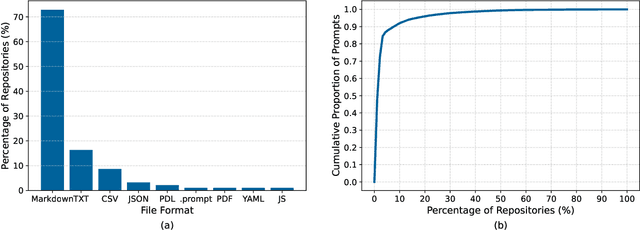

The rapid adoption of foundation models (e.g., large language models) has given rise to promptware, i.e., software built using natural language prompts. Effective management of prompts, such as organization and quality assurance, is essential yet challenging. In this study, we perform an empirical analysis of 24,800 open-source prompts from 92 GitHub repositories to investigate prompt management practices and quality attributes. Our findings reveal critical challenges such as considerable inconsistencies in prompt formatting, substantial internal and external prompt duplication, and frequent readability and spelling issues. Based on these findings, we provide actionable recommendations for developers to enhance the usability and maintainability of open-source prompts within the rapidly evolving promptware ecosystem.
OmniLLP: Enhancing LLM-based Log Level Prediction with Context-Aware Retrieval
Aug 12, 2025



Developers insert logging statements in source code to capture relevant runtime information essential for maintenance and debugging activities. Log level choice is an integral, yet tricky part of the logging activity as it controls log verbosity and therefore influences systems' observability and performance. Recent advances in ML-based log level prediction have leveraged large language models (LLMs) to propose log level predictors (LLPs) that demonstrated promising performance improvements (AUC between 0.64 and 0.8). Nevertheless, current LLM-based LLPs rely on randomly selected in-context examples, overlooking the structure and the diverse logging practices within modern software projects. In this paper, we propose OmniLLP, a novel LLP enhancement framework that clusters source files based on (1) semantic similarity reflecting the code's functional purpose, and (2) developer ownership cohesion. By retrieving in-context learning examples exclusively from these semantic and ownership aware clusters, we aim to provide more coherent prompts to LLPs leveraging LLMs, thereby improving their predictive accuracy. Our results show that both semantic and ownership-aware clusterings statistically significantly improve the accuracy (by up to 8\% AUC) of the evaluated LLM-based LLPs compared to random predictors (i.e., leveraging randomly selected in-context examples from the whole project). Additionally, our approach that combines the semantic and ownership signal for in-context prediction achieves an impressive 0.88 to 0.96 AUC across our evaluated projects. Our findings highlight the value of integrating software engineering-specific context, such as code semantic and developer ownership signals into LLM-LLPs, offering developers a more accurate, contextually-aware approach to logging and therefore, enhancing system maintainability and observability.
InterTrans: Leveraging Transitive Intermediate Translations to Enhance LLM-based Code Translation
Nov 05, 2024



Code translation aims to convert a program from one programming language (PL) to another. This long-standing software engineering task is crucial for modernizing legacy systems, ensuring cross-platform compatibility, enhancing performance, and more. However, automating this process remains challenging due to many syntactic and semantic differences between PLs. Recent studies show that even advanced techniques such as large language models (LLMs), especially open-source LLMs, still struggle with the task. Currently, code LLMs are trained with source code from multiple programming languages, thus presenting multilingual capabilities. In this paper, we investigate whether such multilingual capabilities can be harnessed to enhance code translation. To achieve this goal, we introduce InterTrans, an LLM-based automated code translation approach that, in contrast to existing approaches, leverages intermediate translations across PLs to bridge the syntactic and semantic gaps between source and target PLs. InterTrans contains two stages. It first utilizes a novel Tree of Code Translation (ToCT) algorithm to plan transitive intermediate translation sequences between a given source and target PL, then validates them in a specific order. We evaluate InterTrans with three open LLMs on three benchmarks (i.e., CodeNet, HumanEval-X, and TransCoder) involving six PLs. Results show an absolute improvement between 18.3% to 43.3% in Computation Accuracy (CA) for InterTrans over Direct Translation with 10 attempts. The best-performing variant of InterTrans (with Magicoder LLM) achieved an average CA of 87.3%-95.4% on three benchmarks.
On the Impact of White-box Deployment Strategies for Edge AI on Latency and Model Performance
Nov 01, 2024



To help MLOps engineers decide which operator to use in which deployment scenario, this study aims to empirically assess the accuracy vs latency trade-off of white-box (training-based) and black-box operators (non-training-based) and their combinations in an Edge AI setup. We perform inference experiments including 3 white-box (i.e., QAT, Pruning, Knowledge Distillation), 2 black-box (i.e., Partition, SPTQ), and their combined operators (i.e., Distilled SPTQ, SPTQ Partition) across 3 tiers (i.e., Mobile, Edge, Cloud) on 4 commonly-used Computer Vision and Natural Language Processing models to identify the effective strategies, considering the perspective of MLOps Engineers. Our Results indicate that the combination of Distillation and SPTQ operators (i.e., DSPTQ) should be preferred over non-hybrid operators when lower latency is required in the edge at small to medium accuracy drop. Among the non-hybrid operators, the Distilled operator is a better alternative in both mobile and edge tiers for lower latency performance at the cost of small to medium accuracy loss. Moreover, the operators involving distillation show lower latency in resource-constrained tiers (Mobile, Edge) compared to the operators involving Partitioning across Mobile and Edge tiers. For textual subject models, which have low input data size requirements, the Cloud tier is a better alternative for the deployment of operators than the Mobile, Edge, or Mobile-Edge tier (the latter being used for operators involving partitioning). In contrast, for image-based subject models, which have high input data size requirements, the Edge tier is a better alternative for operators than Mobile, Edge, or their combination.
Data Quality Antipatterns for Software Analytics
Aug 22, 2024



Background: Data quality is vital in software analytics, particularly for machine learning (ML) applications like software defect prediction (SDP). Despite the widespread use of ML in software engineering, the effect of data quality antipatterns on these models remains underexplored. Objective: This study develops a taxonomy of ML-specific data quality antipatterns and assesses their impact on software analytics models' performance and interpretation. Methods: We identified eight types and 14 sub-types of ML-specific data quality antipatterns through a literature review. We conducted experiments to determine the prevalence of these antipatterns in SDP data (RQ1), assess how cleaning order affects model performance (RQ2), evaluate the impact of antipattern removal on performance (RQ3), and examine the consistency of interpretation from models built with different antipatterns (RQ4). Results: In our SDP case study, we identified nine antipatterns. Over 90% of these overlapped at both row and column levels, complicating cleaning prioritization and risking excessive data removal. The order of cleaning significantly impacts ML model performance, with neural networks being more resilient to cleaning order changes than simpler models like logistic regression. Antipatterns such as Tailed Distributions and Class Overlap show a statistically significant correlation with performance metrics when other antipatterns are cleaned. Models built with different antipatterns showed moderate consistency in interpretation results. Conclusion: The cleaning order of different antipatterns impacts ML model performance. Five antipatterns have a statistically significant correlation with model performance when others are cleaned. Additionally, model interpretation is moderately affected by different data quality antipatterns.
On the Workflows and Smells of Leaderboard Operations (LBOps): An Exploratory Study of Foundation Model Leaderboards
Jul 04, 2024



Foundation models (FM), such as large language models (LLMs), which are large-scale machine learning (ML) models, have demonstrated remarkable adaptability in various downstream software engineering (SE) tasks, such as code completion, code understanding, and software development. As a result, FM leaderboards, especially those hosted on cloud platforms, have become essential tools for SE teams to compare and select the best third-party FMs for their specific products and purposes. However, the lack of standardized guidelines for FM evaluation and comparison threatens the transparency of FM leaderboards and limits stakeholders' ability to perform effective FM selection. As a first step towards addressing this challenge, our research focuses on understanding how these FM leaderboards operate in real-world scenarios ("leaderboard operations") and identifying potential leaderboard pitfalls and areas for improvement ("leaderboard smells"). In this regard, we perform a multivocal literature review to collect up to 721 FM leaderboards, after which we examine their documentation and engage in direct communication with leaderboard operators to understand their workflow patterns. Using card sorting and negotiated agreement, we identify 5 unique workflow patterns and develop a domain model that outlines the essential components and their interaction within FM leaderboards. We then identify 8 unique types of leaderboard smells in LBOps. By mitigating these smells, SE teams can improve transparency, accountability, and collaboration in current LBOps practices, fostering a more robust and responsible ecosystem for FM comparison and selection.
A State-of-the-practice Release-readiness Checklist for Generative AI-based Software Products
Mar 27, 2024This paper investigates the complexities of integrating Large Language Models (LLMs) into software products, with a focus on the challenges encountered for determining their readiness for release. Our systematic review of grey literature identifies common challenges in deploying LLMs, ranging from pre-training and fine-tuning to user experience considerations. The study introduces a comprehensive checklist designed to guide practitioners in evaluating key release readiness aspects such as performance, monitoring, and deployment strategies, aiming to enhance the reliability and effectiveness of LLM-based applications in real-world settings.