 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SDWPF: A Dataset for Spatial Dynamic Wind Power Forecasting Challenge at KDD Cup 2022
Aug 08, 2022


The variability of wind power supply can present substantial challenges to incorporating wind power into a grid system. Thus, Wind Power Forecasting (WPF) has been widely recognized as one of the most critical issues in wind power integration and operation. There has been an explosion of studies on wind power forecasting problems in the past decades. Nevertheless, how to well handle the WPF problem is still challenging, since high prediction accuracy is always demanded to ensure grid stability and security of supply. We present a unique Spatial Dynamic Wind Power Forecasting dataset: SDWPF, which includes the spatial distribution of wind turbines, as well as the dynamic context factors. Whereas, most of the existing datasets have only a small number of wind turbines without knowing the locations and context information of wind turbines at a fine-grained time scale. By contrast, SDWPF provides the wind power data of 134 wind turbines from a wind farm over half a year with their relative positions and internal statuses. We use this dataset to launch the Baidu KDD Cup 2022 to examine the limit of current WPF solutions. The dataset is released at https://aistudio.baidu.com/aistudio/competition/detail/152/0/datasets.
Improving Streaming End-to-End ASR on Transformer-based Causal Models with Encoder States Revision Strategies
Jul 06, 2022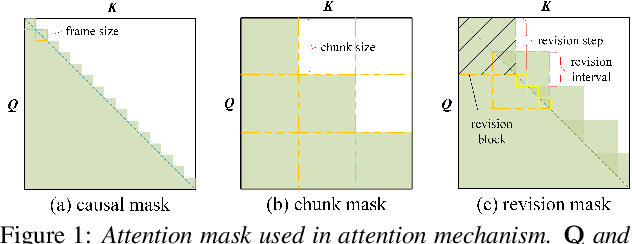
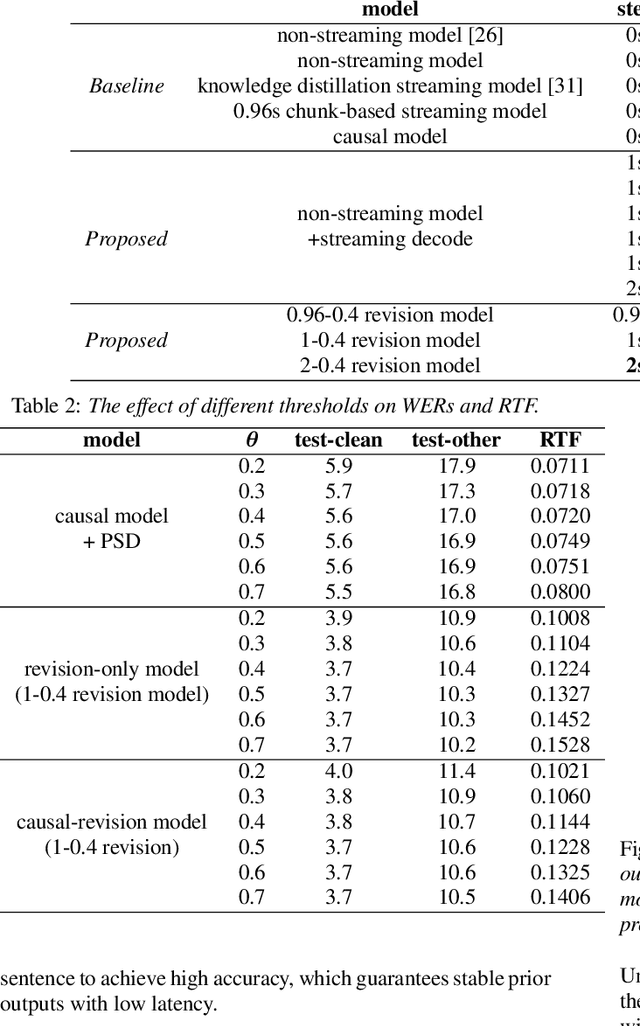
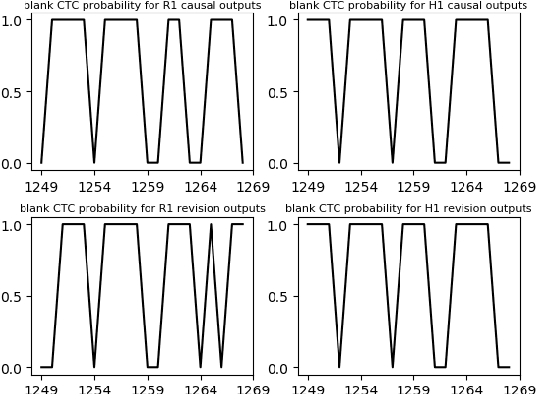
There is often a trade-off between performance and latency in streaming automatic speech recognition (ASR). Traditional methods such as look-ahead and chunk-based methods, usually require information from future frames to advance recognition accuracy, which incurs inevitable latency even if the computation is fast enough. A causal model that computes without any future frames can avoid this latency, but its performance is significantly worse than traditional methods. In this paper, we propose corresponding revision strategies to improve the causal model. Firstly, we introduce a real-time encoder states revision strategy to modify previous states. Encoder forward computation starts once the data is received and revises the previous encoder states after several frames, which is no need to wait for any right context. Furthermore, a CTC spike position alignment decoding algorithm is designed to reduce time costs brought by the revision strategy. Experiments are all conducted on Librispeech datasets. Fine-tuning on the CTC-based wav2vec2.0 model, our best method can achieve 3.7/9.2 WERs on test-clean/other sets, which is also competitive with the chunk-based methods and the knowledge distillation methods.
Time Series Clustering for Grouping Products Based on Price and Sales Patterns
Apr 18, 2022
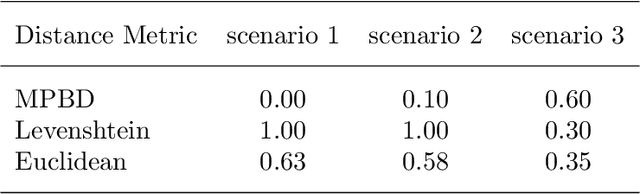
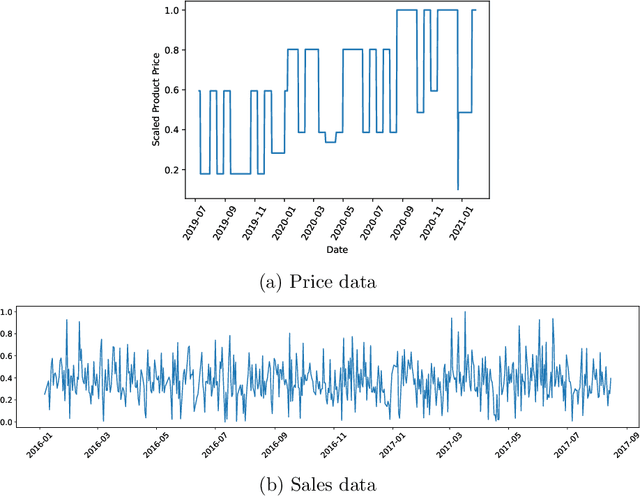
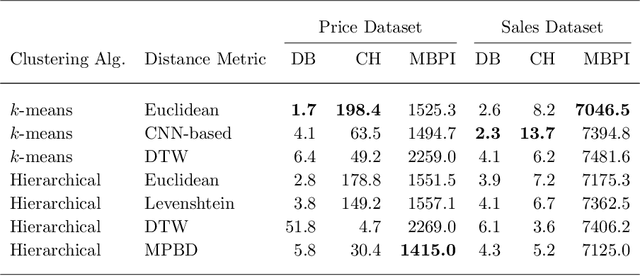
Developing technology and changing lifestyles have made online grocery delivery applications an indispensable part of urban life. Since the beginning of the COVID-19 pandemic, the demand for such applications has dramatically increased, creating new competitors that disrupt the market. An increasing level of competition might prompt companies to frequently restructure their marketing and product pricing strategies. Therefore, identifying the change patterns in product prices and sales volumes would provide a competitive advantage for the companies in the marketplace. In this paper, we investigate alternative clustering methodologies to group the products based on the price patterns and sales volumes. We propose a novel distance metric that takes into account how product prices and sales move together rather than calculating the distance using numerical values. We compare our approach with traditional clustering algorithms, which typically rely on generic distance metrics such as Euclidean distance, and image clustering approaches that aim to group data by capturing its visual patterns. We evaluate the performances of different clustering algorithms using our custom evaluation metric as well as Calinski Harabasz and Davies Bouldin indices, which are commonly used internal validity metrics. We conduct our numerical study using a propriety price dataset from an online food and grocery delivery company, and the publicly available Favorita sales dataset. We find that our proposed clustering approach and image clustering both perform well for finding the products with similar price and sales patterns within large datasets.
Shielding Federated Learning Systems against Inference Attacks with ARM TrustZone
Aug 11, 2022
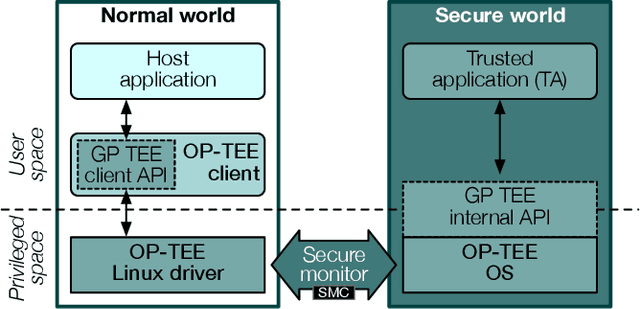
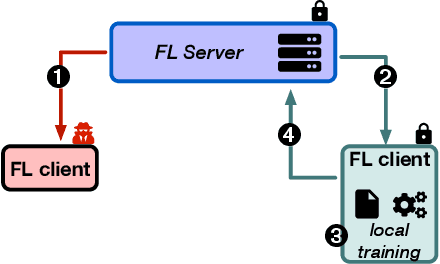
Federated Learning (FL) opens new perspectives for training machine learning models while keeping personal data on the users premises. Specifically, in FL, models are trained on the users devices and only model updates (i.e., gradients) are sent to a central server for aggregation purposes. However, the long list of inference attacks that leak private data from gradients, published in the recent years, have emphasized the need of devising effective protection mechanisms to incentivize the adoption of FL at scale. While there exist solutions to mitigate these attacks on the server side, little has been done to protect users from attacks performed on the client side. In this context, the use of Trusted Execution Environments (TEEs) on the client side are among the most proposing solutions. However, existing frameworks (e.g., DarkneTZ) require statically putting a large portion of the machine learning model into the TEE to effectively protect against complex attacks or a combination of attacks. We present GradSec, a solution that allows protecting in a TEE only sensitive layers of a machine learning model, either statically or dynamically, hence reducing both the TCB size and the overall training time by up to 30% and 56%, respectively compared to state-of-the-art competitors.
Fast 3D Sparse Topological Skeleton Graph Generation for Mobile Robot Global Planning
Aug 08, 2022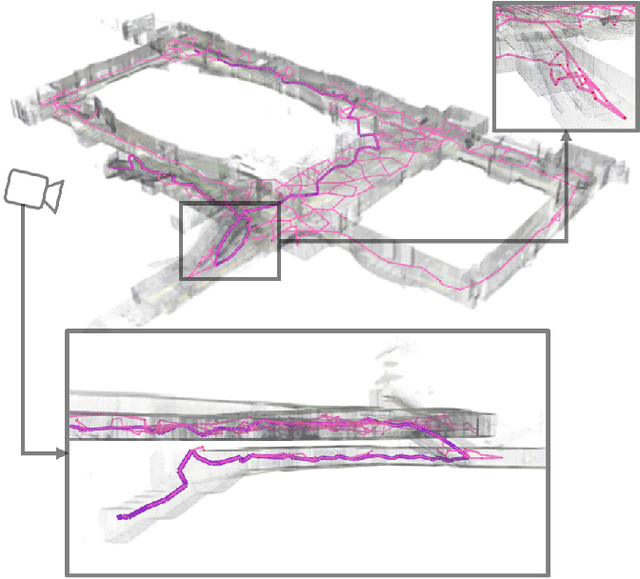
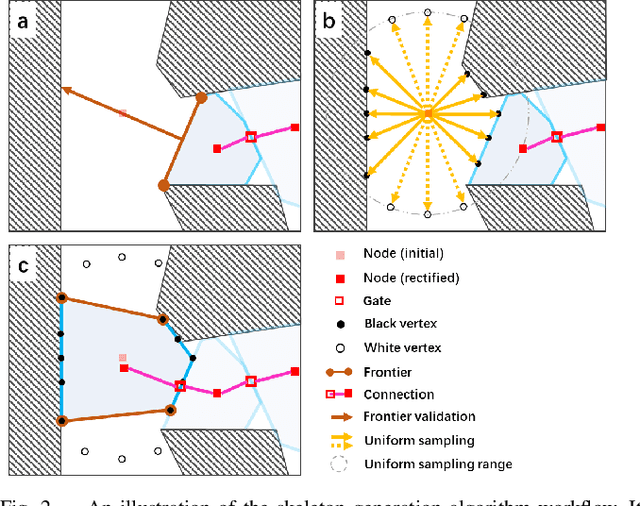
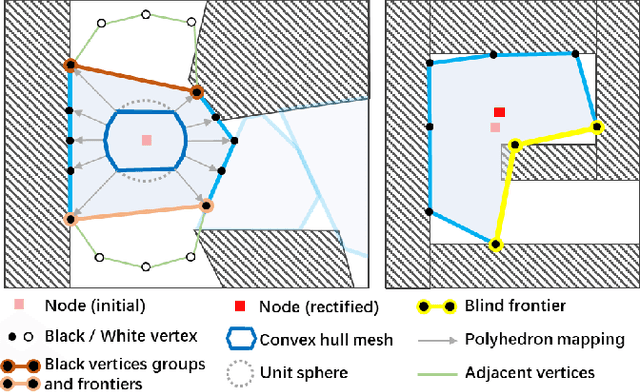
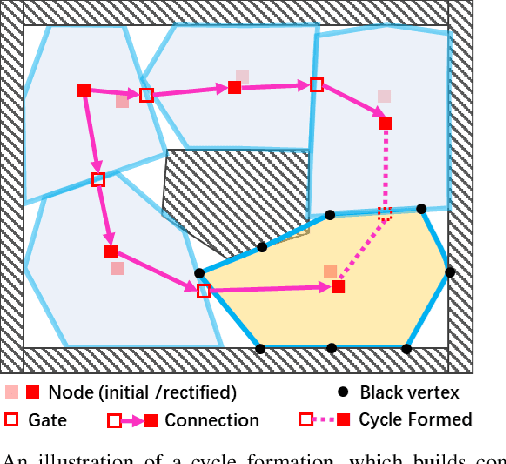
In recent years, mobile robots are becoming ambitious and deployed in large-scale scenarios. Serving as a high-level understanding of environments, a sparse skeleton graph is beneficial for more efficient global planning. Currently, existing solutions for skeleton graph generation suffer from several major limitations, including poor adaptiveness to different map representations, dependency on robot inspection trajectories and high computational overhead. In this paper, we propose an efficient and flexible algorithm generating a trajectory-independent 3D sparse topological skeleton graph capturing the spatial structure of the free space. In our method, an efficient ray sampling and validating mechanism are adopted to find distinctive free space regions, which contributes to skeleton graph vertices, with traversability between adjacent vertices as edges. A cycle formation scheme is also utilized to maintain skeleton graph compactness. Benchmark comparison with state-of-the-art works demonstrates that our approach generates sparse graphs in a substantially shorter time, giving high-quality global planning paths. Experiments conducted in real-world maps further validate the capability of our method in real-world scenarios. Our method will be made open source to benefit the community.
Planning and Scheduling in Digital Health with Answer Set Programming
Aug 05, 2022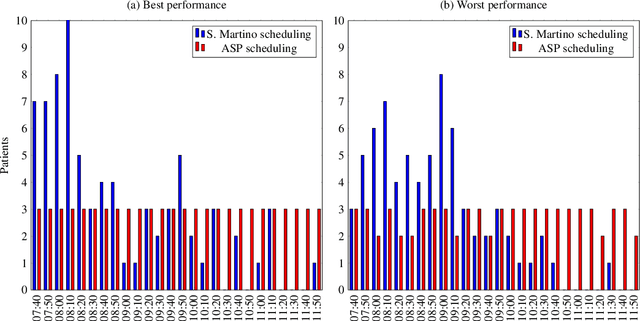
In the hospital world there are several complex combinatory problems, and solving these problems is important to increase the degree of patients' satisfaction and the quality of care offered. The problems in the healthcare are complex since to solve them several constraints and different type of resources should be taken into account. Moreover, the solutions must be evaluated in a small amount of time to ensure the usability in real scenarios. We plan to propose solutions to these kind of problems both expanding already tested solutions and by modelling solutions for new problems, taking into account the literature and by using real data when available. Solving these kind of problems is important but, since the European Commission established with the General Data Protection Regulation that each person has the right to ask for explanation of the decision taken by an AI, without developing Explainability methodologies the usage of AI based solvers e.g. those based on Answer Set programming will be limited. Thus, another part of the research will be devoted to study and propose new methodologies for explaining the solutions obtained.
* In Proceedings ICLP 2022, arXiv:2208.02685
SCouT: Synthetic Counterfactuals via Spatiotemporal Transformers for Actionable Healthcare
Jul 09, 2022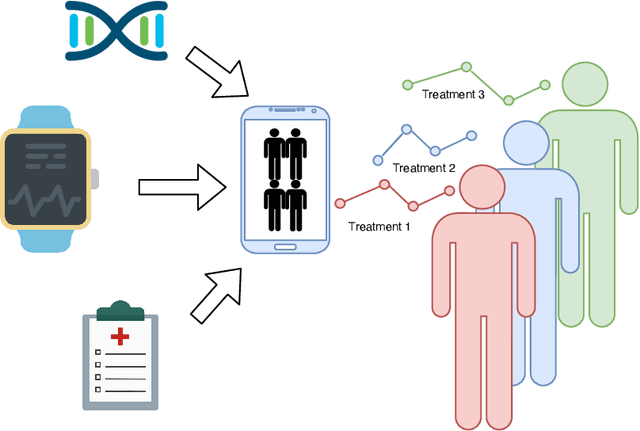
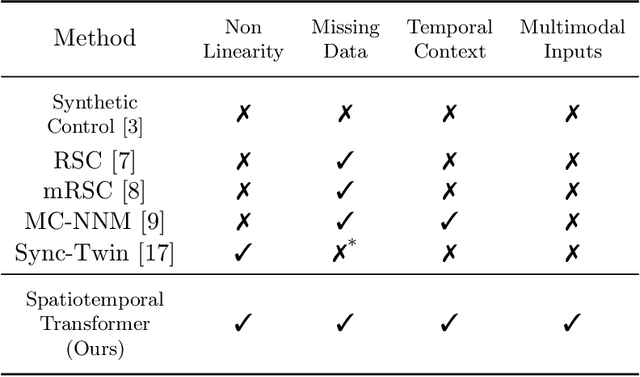
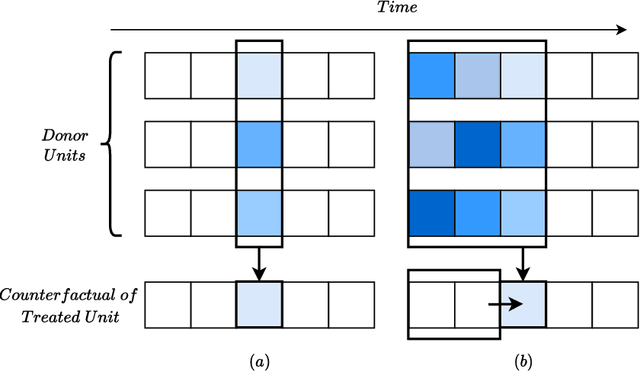

The Synthetic Control method has pioneered a class of powerful data-driven techniques to estimate the counterfactual reality of a unit from donor units. At its core, the technique involves a linear model fitted on the pre-intervention period that combines donor outcomes to yield the counterfactual. However, linearly combining spatial information at each time instance using time-agnostic weights fails to capture important inter-unit and intra-unit temporal contexts and complex nonlinear dynamics of real data. We instead propose an approach to use local spatiotemporal information before the onset of the intervention as a promising way to estimate the counterfactual sequence. To this end, we suggest a Transformer model that leverages particular positional embeddings, a modified decoder attention mask, and a novel pre-training task to perform spatiotemporal sequence-to-sequence modeling. Our experiments on synthetic data demonstrate the efficacy of our method in the typical small donor pool setting and its robustness against noise. We also generate actionable healthcare insights at the population and patient levels by simulating a state-wide public health policy to evaluate its effectiveness, an in silico trial for asthma medications to support randomized controlled trials, and a medical intervention for patients with Friedreich's ataxia to improve clinical decision-making and promote personalized therapy.
Time-Based Quantization for FRI and Bandlimited signals
Oct 05, 2021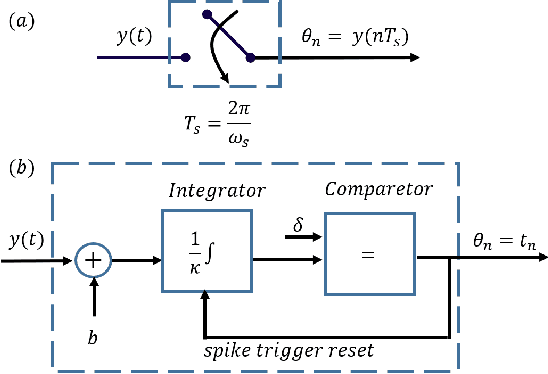
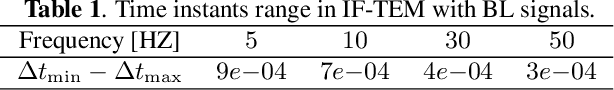
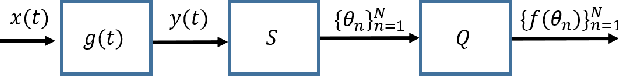
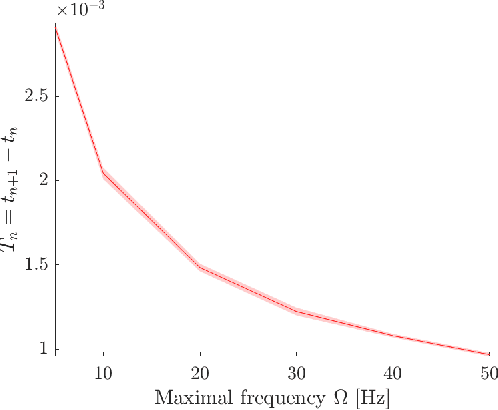
We consider the problem of quantizing samples of finite-rate-of-innovation (FRI) and bandlimited (BL) signals by using an integrate-and-fire time encoding machine (IF-TEM). We propose a uniform design of the quantization levels and show by numerical simulations that quantization using IF-TEM improves the recovery of FRI and BL signals in comparison with classical uniform sampling in the Fourier-domain and Nyquist methods, respectively. In terms of mean square error (MSE), the reduction reaches at least 5 dB for both classes of signals. Our numerical evaluations also demonstrate that the MSE further decreases when the number of pulses comprising the FRI signal increases. A similar observation is demonstrated for BL signals. In particular, we show that, in contrast to the classical method, increasing the frequency of the IF-TEM input decreases the quantization step size, which can reduce the MSE.
TsFeX: Contact Tracing Model using Time Series Feature Extraction and Gradient Boosting
Nov 29, 2021
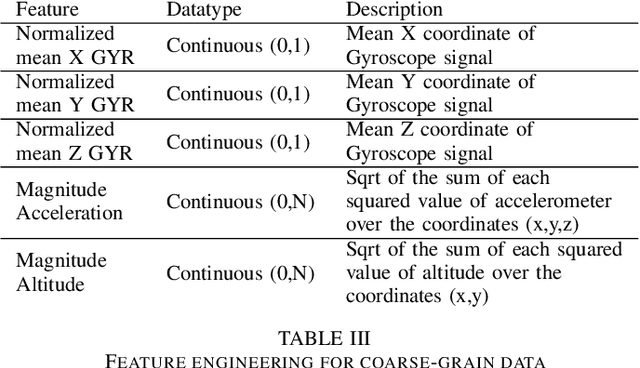
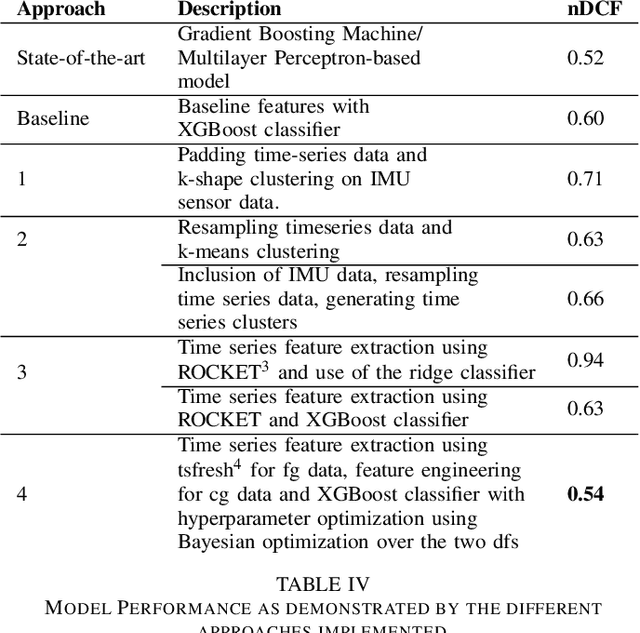
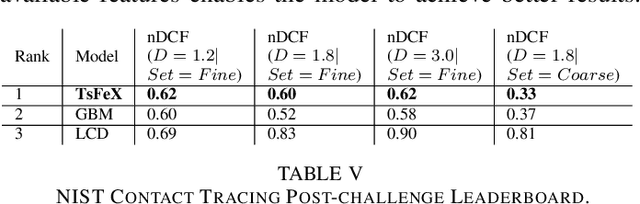
With the outbreak of COVID-19 pandemic, a dire need to effectively identify the individuals who may have come in close-contact to others who have been infected with COVID-19 has risen. This process of identifying individuals, also termed as 'Contact tracing', has significant implications for the containment and control of the spread of this virus. However, manual tracing has proven to be ineffective calling for automated contact tracing approaches. As such, this research presents an automated machine learning system for identifying individuals who may have come in contact with others infected with COVID-19 using sensor data transmitted through handheld devices. This paper describes the different approaches followed in arriving at an optimal solution model that effectually predicts whether a person has been in close proximity to an infected individual using a gradient boosting algorithm and time series feature extraction.
A Frequency-Velocity CNN for Developing Near-Surface 2D Vs Images from Linear-Array, Active-Source Wavefield Measurements
Jul 19, 2022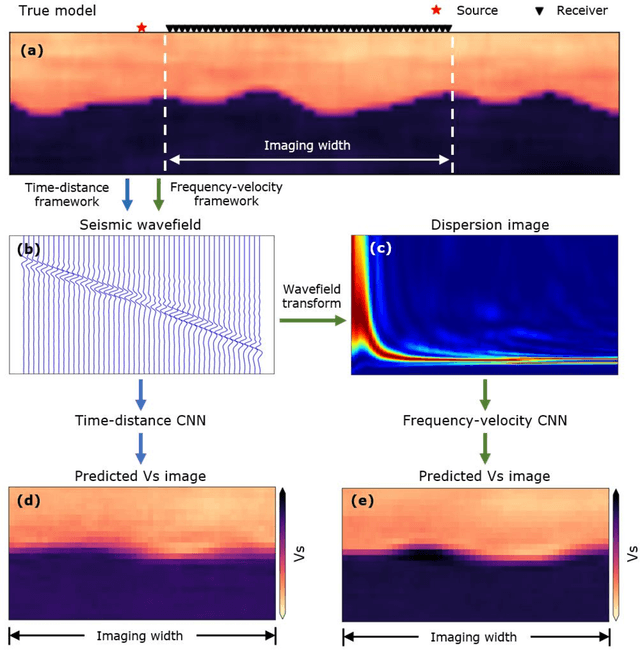
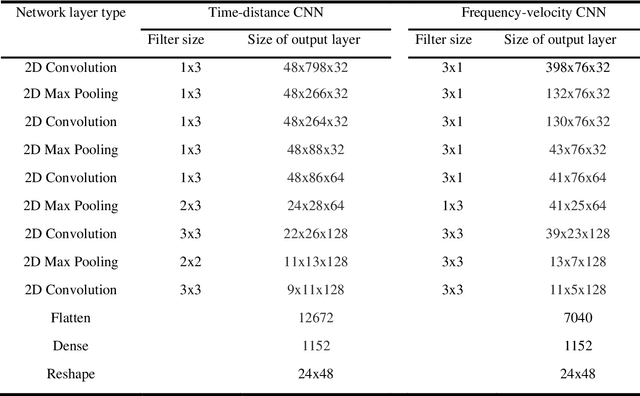
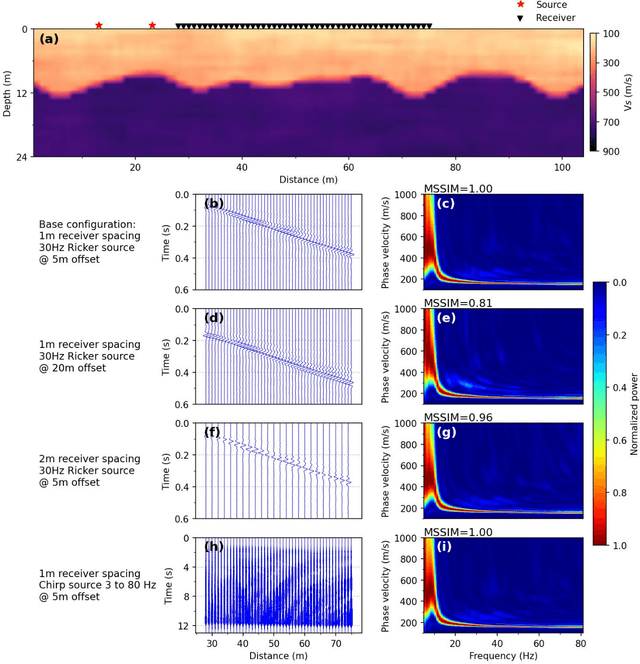
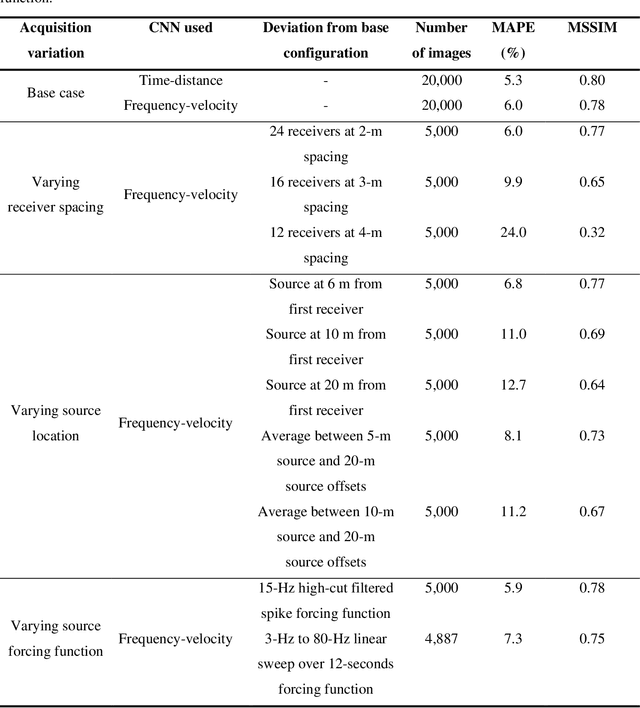
This paper presents a frequency-velocity convolutional neural network (CNN) for rapid, non-invasive 2D shear wave velocity (Vs) imaging of near-surface geo-materials. Operating in the frequency-velocity domain allows for significant flexibility in the linear-array, active-source experimental testing configurations used for generating the CNN input, which are normalized dispersion images. Unlike wavefield images, normalized dispersion images are relatively insensitive to the experimental testing configuration, accommodating various source types, source offsets, numbers of receivers, and receiver spacings. We demonstrate the effectiveness of the frequency-velocity CNN by applying it to a classic near-surface geophysics problem, namely, imaging a two-layer, undulating, soil-over-bedrock interface. This problem was recently investigated in our group by developing a time-distance CNN, which showed great promise but lacked flexibility in utilizing different field-testing configurations. Herein, the new frequency-velocity CNN is shown to have comparable accuracy to the time-distance CNN while providing greater flexibility to handle varied field applications. The frequency-velocity CNN was trained, validated, and tested using 100,000 synthetic near-surface models. The ability of the proposed frequency-velocity CNN to generalize across various acquisition configurations is first tested using synthetic near-surface models with different acquisition configurations from that of the training set, and then applied to experimental field data collected at the Hornsby Bend site in Austin, Texas, USA. When fully developed for a wider range of geological conditions, the proposed CNN may ultimately be used as a rapid, end-to-end alternative for current pseudo-2D surface wave imaging techniques or to develop starting models for full waveform inversion.