 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLRan: A Behavioural Dataset for Ransomware Analysis and Detection
May 24, 2025



Ransomware remains a critical threat to cybersecurity, yet publicly available datasets for training machine learning-based ransomware detection models are scarce and often have limited sample size, diversity, and reproducibility. In this paper, we introduce MLRan, a behavioural ransomware dataset, comprising over 4,800 samples across 64 ransomware families and a balanced set of goodware samples. The samples span from 2006 to 2024 and encompass the four major types of ransomware: locker, crypto, ransomware-as-a-service, and modern variants. We also propose guidelines (GUIDE-MLRan), inspired by previous work, for constructing high-quality behavioural ransomware datasets, which informed the curation of our dataset. We evaluated the ransomware detection performance of several machine learning (ML) models using MLRan. For this purpose, we performed feature selection by conducting mutual information filtering to reduce the initial 6.4 million features to 24,162, followed by recursive feature elimination, yielding 483 highly informative features. The ML models achieved an accuracy, precision and recall of up to 98.7%, 98.9%, 98.5%, respectively. Using SHAP and LIME, we identified critical indicators of malicious behaviour, including registry tampering, strings, and API misuse. The dataset and source code for feature extraction, selection, ML training, and evaluation are available publicly to support replicability and encourage future research, which can be found at https://github.com/faithfulco/mlran.
Measuring Fairness in Financial Transaction Machine Learning Models
Jan 18, 2025



Mastercard, a global leader in financial services, develops and deploys machine learning models aimed at optimizing card usage and preventing attrition through advanced predictive models. These models use aggregated and anonymized card usage patterns, including cross-border transactions and industry-specific spending, to tailor bank offerings and maximize revenue opportunities. Mastercard has established an AI Governance program, based on its Data and Tech Responsibility Principles, to evaluate any built and bought AI for efficacy, fairness, and transparency. As part of this effort, Mastercard has sought expertise from the Turing Institute through a Data Study Group to better assess fairness in more complex AI/ML models. The Data Study Group challenge lies in defining, measuring, and mitigating fairness in these predictions, which can be complex due to the various interpretations of fairness, gaps in the research literature, and ML-operations challenges.
TsFeX: Contact Tracing Model using Time Series Feature Extraction and Gradient Boosting
Dec 04, 2021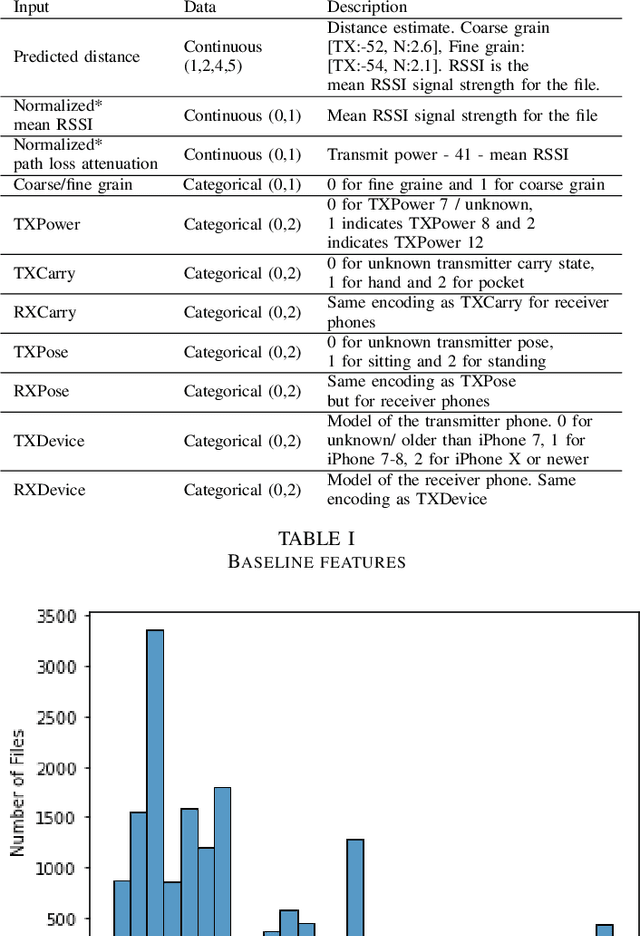
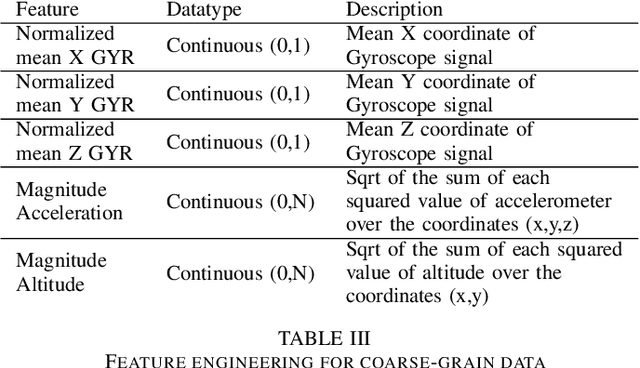
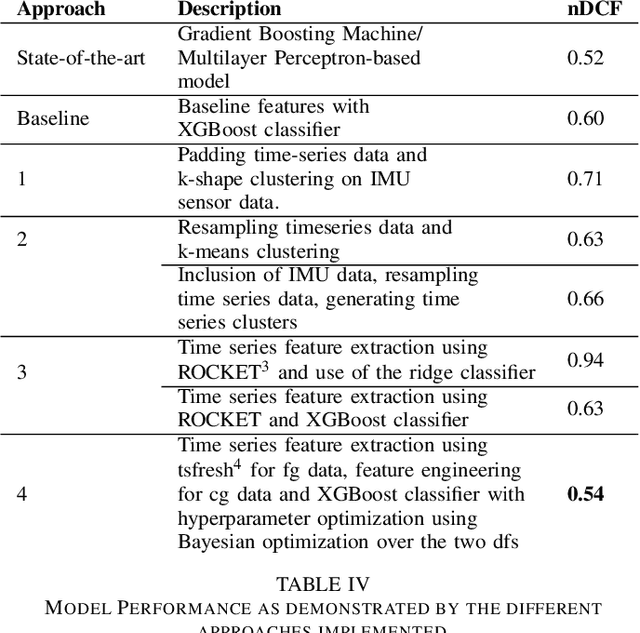
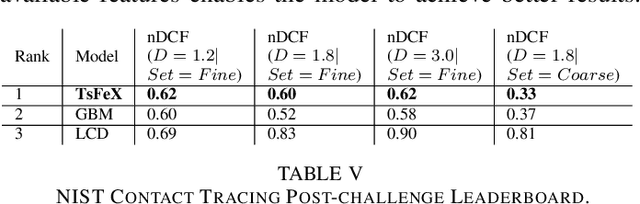
With the outbreak of COVID-19 pandemic, a dire need to effectively identify the individuals who may have come in close-contact to others who have been infected with COVID-19 has risen. This process of identifying individuals, also termed as 'Contact tracing', has significant implications for the containment and control of the spread of this virus. However, manual tracing has proven to be ineffective calling for automated contact tracing approaches. As such, this research presents an automated machine learning system for identifying individuals who may have come in contact with others infected with COVID-19 using sensor data transmitted through handheld devices. This paper describes the different approaches followed in arriving at an optimal solution model that effectually predicts whether a person has been in close proximity to an infected individual using a gradient boosting algorithm and time series feature extraction.