 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Interpretable Sleep Stage Classification Using Cross-Modal Transformers
Aug 15, 2022
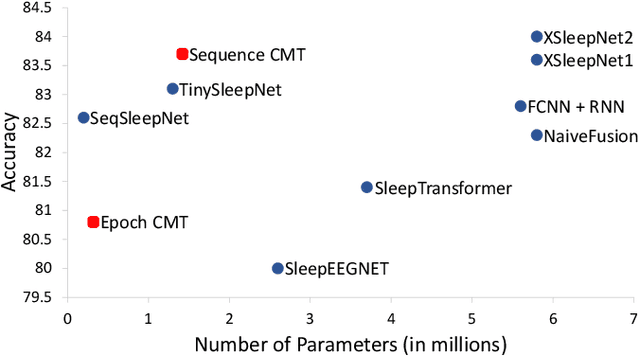
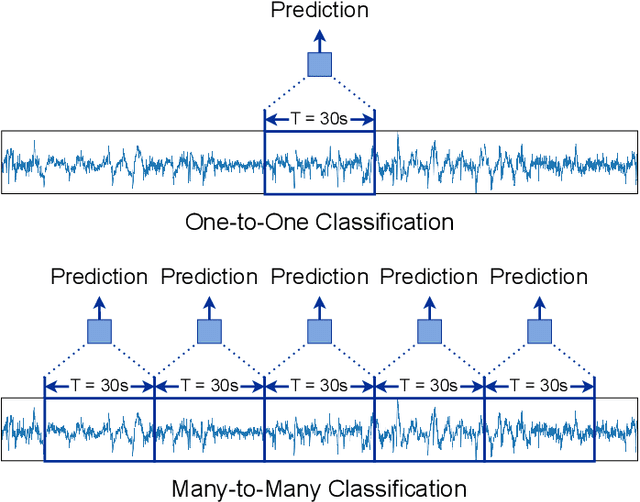
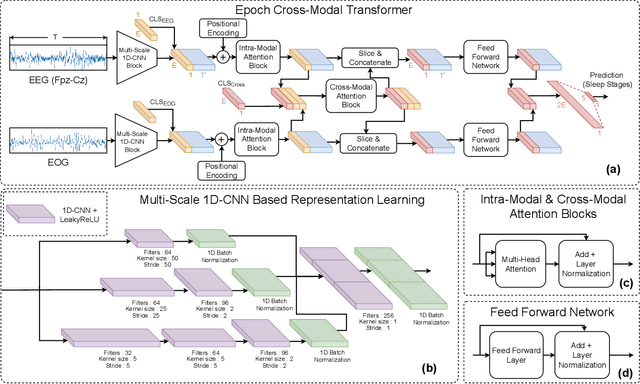
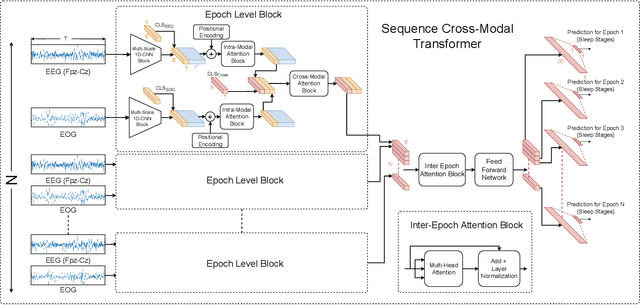
Accurate sleep stage classification is significant for sleep health assessment. In recent years, several deep learning and machine learning based sleep staging algorithms have been developed and they have achieved performance on par with human annotation. Despite improved performance, a limitation of most deep-learning based algorithms is their Black-box behavior, which which have limited their use in clinical settings. Here, we propose Cross-Modal Transformers, which is a transformer-based method for sleep stage classification. Our models achieve both competitive performance with the state-of-the-art approaches and eliminates the Black-box behavior of deep-learning models by utilizing the interpretability aspect of the attention modules. The proposed cross-modal transformers consist of a novel cross-modal transformer encoder architecture along with a multi-scale 1-dimensional convolutional neural network for automatic representation learning. Our sleep stage classifier based on this design was able to achieve sleep stage classification performance on par with or better than the state-of-the-art approaches, along with interpretability, a fourfold reduction in the number of parameters and a reduced training time compared to the current state-of-the-art. Our code is available at https://github.com/Jathurshan0330/Cross-Modal-Transformer.
Visual Cross-View Metric Localization with Dense Uncertainty Estimates
Aug 17, 2022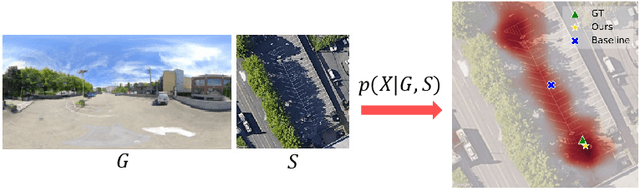

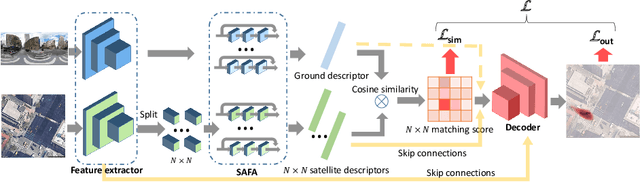
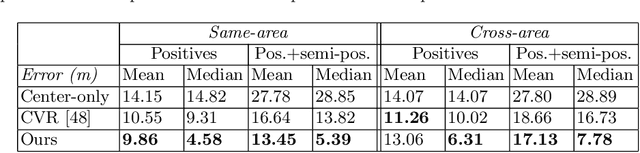
This work addresses visual cross-view metric localization for outdoor robotics. Given a ground-level color image and a satellite patch that contains the local surroundings, the task is to identify the location of the ground camera within the satellite patch. Related work addressed this task for range-sensors (LiDAR, Radar), but for vision, only as a secondary regression step after an initial cross-view image retrieval step. Since the local satellite patch could also be retrieved through any rough localization prior (e.g. from GPS/GNSS, temporal filtering), we drop the image retrieval objective and focus on the metric localization only. We devise a novel network architecture with denser satellite descriptors, similarity matching at the bottleneck (rather than at the output as in image retrieval), and a dense spatial distribution as output to capture multi-modal localization ambiguities. We compare against a state-of-the-art regression baseline that uses global image descriptors. Quantitative and qualitative experimental results on the recently proposed VIGOR and the Oxford RobotCar datasets validate our design. The produced probabilities are correlated with localization accuracy, and can even be used to roughly estimate the ground camera's heading when its orientation is unknown. Overall, our method reduces the median metric localization error by 51%, 37%, and 28% compared to the state-of-the-art when generalizing respectively in the same area, across areas, and across time.
Analyzing Robustness of End-to-End Neural Models for Automatic Speech Recognition
Aug 17, 2022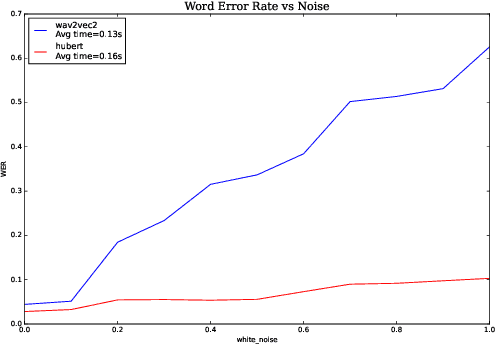
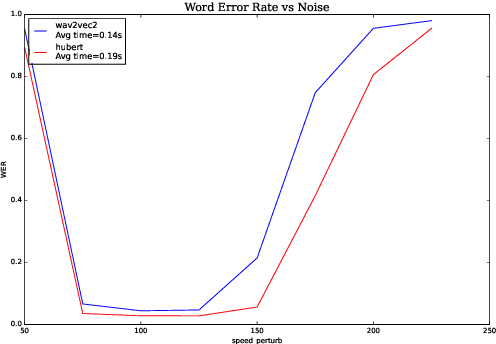
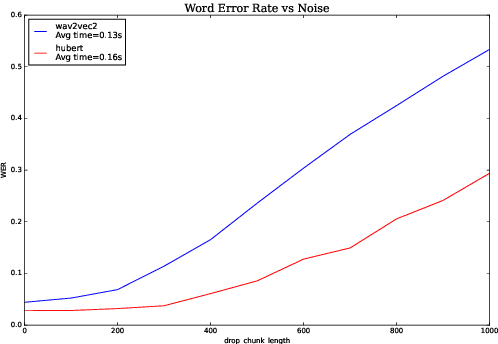
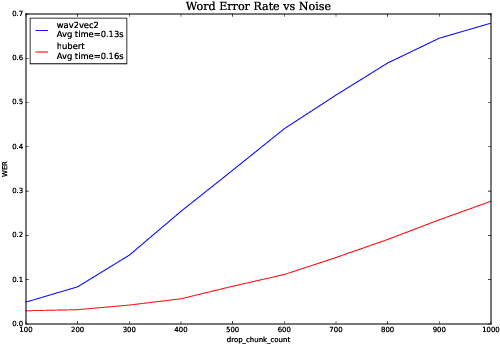
We investigate robustness properties of pre-trained neural models for automatic speech recognition. Real life data in machine learning is usually very noisy and almost never clean, which can be attributed to various factors depending on the domain, e.g. outliers, random noise and adversarial noise. Therefore, the models we develop for various tasks should be robust to such kinds of noisy data, which led to the thriving field of robust machine learning. We consider this important issue in the setting of automatic speech recognition. With the increasing popularity of pre-trained models, it's an important question to analyze and understand the robustness of such models to noise. In this work, we perform a robustness analysis of the pre-trained neural models wav2vec2, HuBERT and DistilHuBERT on the LibriSpeech and TIMIT datasets. We use different kinds of noising mechanisms and measure the model performances as quantified by the inference time and the standard Word Error Rate metric. We also do an in-depth layer-wise analysis of the wav2vec2 model when injecting noise in between layers, enabling us to predict at a high level what each layer learns. Finally for this model, we visualize the propagation of errors across the layers and compare how it behaves on clean versus noisy data. Our experiments conform the predictions of Pasad et al. [2021] and also raise interesting directions for future work.
BCRLSP: An Offline Reinforcement Learning Framework for Sequential Targeted Promotion
Jul 16, 2022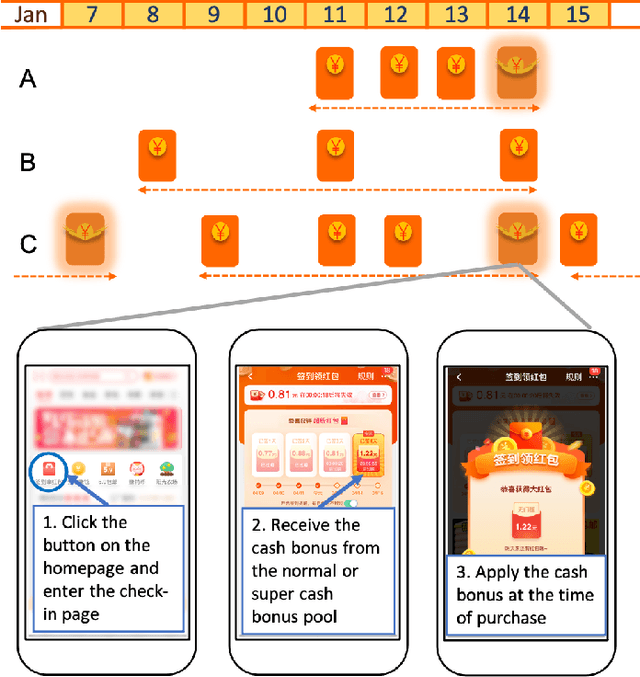
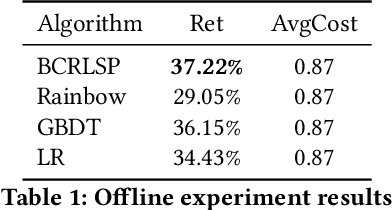
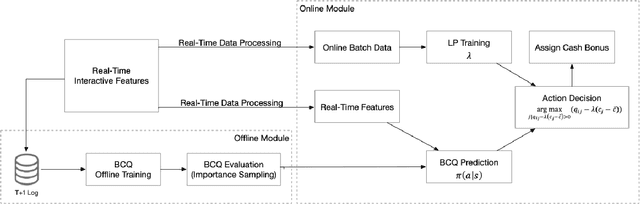
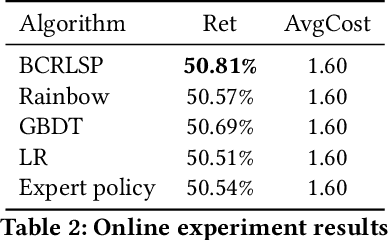
We utilize an offline reinforcement learning (RL) model for sequential targeted promotion in the presence of budget constraints in a real-world business environment. In our application, the mobile app aims to boost customer retention by sending cash bonuses to customers and control the costs of such cash bonuses during each time period. To achieve the multi-task goal, we propose the Budget Constrained Reinforcement Learning for Sequential Promotion (BCRLSP) framework to determine the value of cash bonuses to be sent to users. We first find out the target policy and the associated Q-values that maximizes the user retention rate using an RL model. A linear programming (LP) model is then added to satisfy the constraints of promotion costs. We solve the LP problem by maximizing the Q-values of actions learned from the RL model given the budget constraints. During deployment, we combine the offline RL model with the LP model to generate a robust policy under the budget constraints. Using both online and offline experiments, we demonstrate the efficacy of our approach by showing that BCRLSP achieves a higher long-term customer retention rate and a lower cost than various baselines. Taking advantage of the near real-time cost control method, the proposed framework can easily adapt to data with a noisy behavioral policy and/or meet flexible budget constraints.
FADNet++: Real-Time and Accurate Disparity Estimation with Configurable Networks
Oct 06, 2021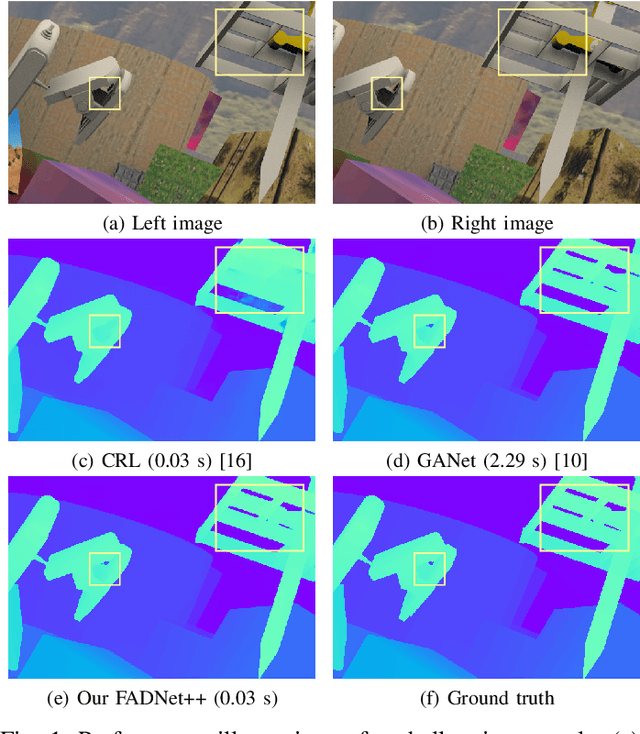
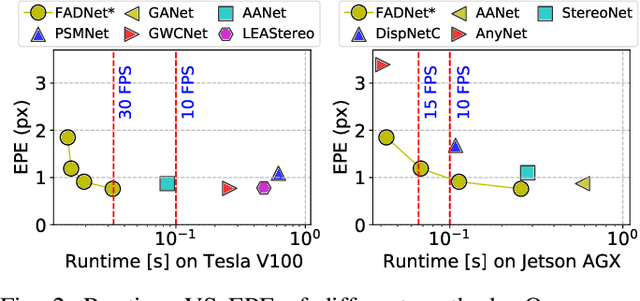
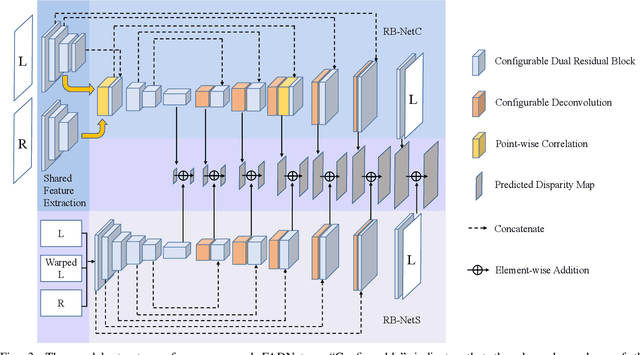
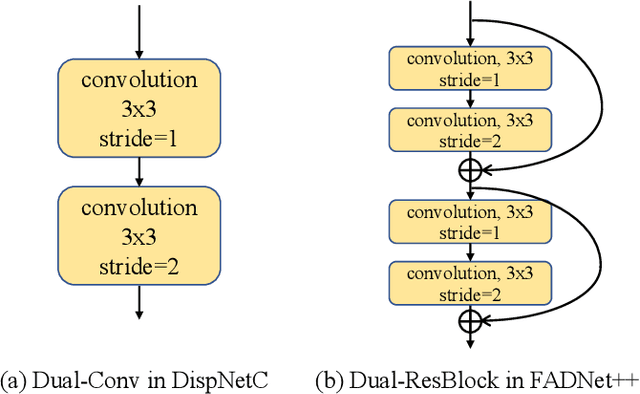
Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy than traditional hand-crafted feature-based methods. However, the existing DNNs hardly serve both efficient computation and rich expression capability, which makes them difficult for deployment in real-time and high-quality applications, especially on mobile devices. To this end, we propose an efficient, accurate, and configurable deep network for disparity estimation named FADNet++. Leveraging several liberal network design and training techniques, FADNet++ can boost its accuracy with a fast model inference speed for real-time applications. Besides, it enables users to easily configure different sizes of models for balancing accuracy and inference efficiency. We conduct extensive experiments to demonstrate the effectiveness of FADNet++ on both synthetic and realistic datasets among six GPU devices varying from server to mobile platforms. Experimental results show that FADNet++ and its variants achieve state-of-the-art prediction accuracy, and run at a significant order of magnitude faster speed than existing 3D models. With the constraint of running at above 15 frames per second (FPS) on a mobile GPU, FADNet++ achieves a new state-of-the-art result for the SceneFlow dataset.
Group GAN
May 27, 2022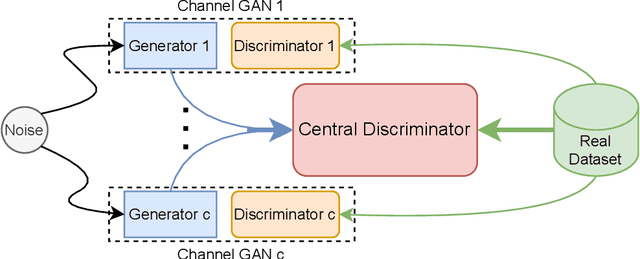
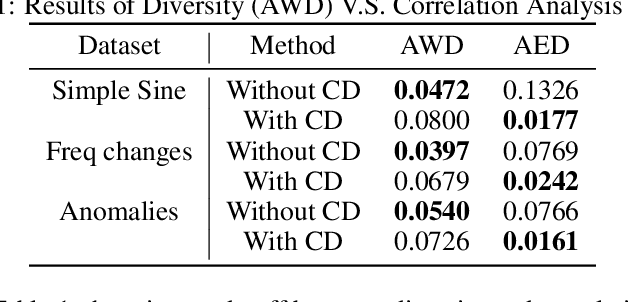
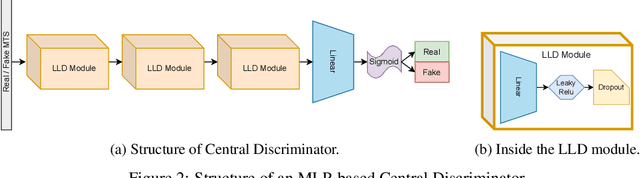
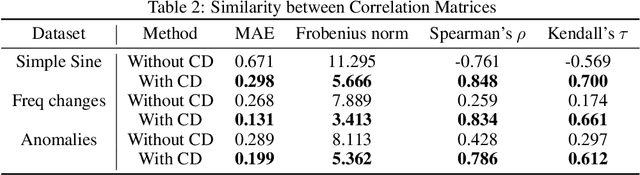
Generating multivariate time series is a promising approach for sharing sensitive data in many medical, financial, and IoT applications. A common type of multivariate time series originates from a single source such as the biometric measurements from a medical patient. This leads to complex dynamical patterns between individual time series that are hard to learn by typical generation models such as GANs. There is valuable information in those patterns that machine learning models can use to better classify, predict or perform other downstream tasks. We propose a novel framework that takes time series' common origin into account and favors inter-channel relationship preservation. The two key points of our method are: 1) the individual time series are generated from a common point in latent space and 2) a central discriminator favors the preservation of inter-channel dynamics. We demonstrate empirically that our method helps preserve channel correlations and that our synthetic data performs very well downstream tasks with medical and financial data.
Intelligent Reflecting Surface Enabled Multi-Target Sensing
Jul 04, 2022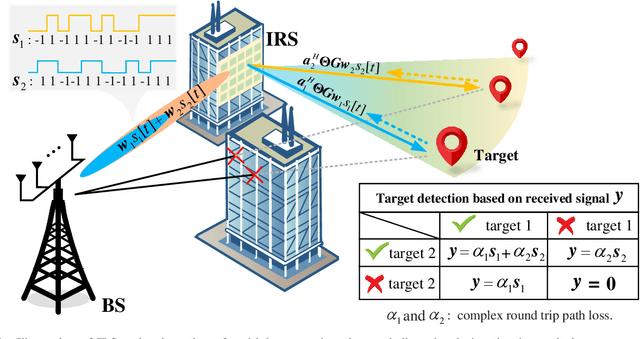
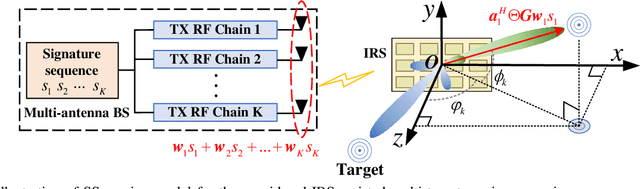
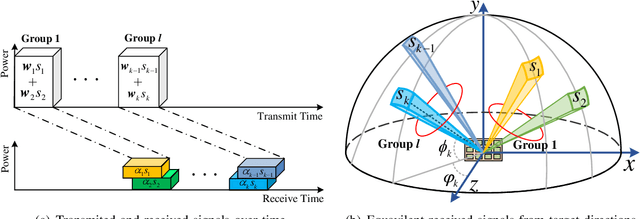
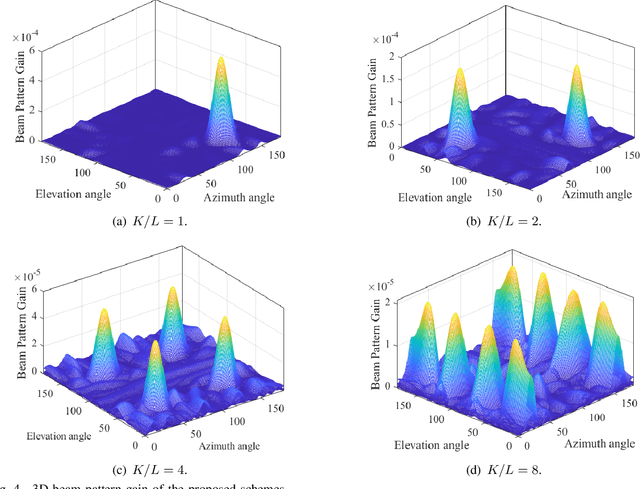
Besides improving communication performance, intelligent reflecting surfaces (IRSs) are also promising enablers for achieving larger sensing coverage and enhanced sensing quality. Nevertheless, in the absence of a direct path between the base station (BS) and the targets, multi-target sensing is generally very difficult, since IRSs are incapable of proactively transmitting sensing beams or analyzing target information. Moreover, the echoes of different targets reflected via the IRS-established virtual links share the same directionality at the BS. In this paper, we study a wireless system comprising a multi-antenna BS and an IRS for multi-target sensing, where the beamforming vector and the IRS phase shifts are jointly optimized to improve the sensing performance. To meet the different sensing requirements, such as a minimum received power and a minimum sensing frequency, we propose three novel IRS-assisted sensing schemes: Time division (TD) sensing, signature sequence (SS) sensing, and hybrid TD-SS sensing. First, for TD sensing, the sensing tasks are performed in sequence over time. Subsequently, a novel signature sequence (SS) sensing scheme is proposed to improve sensing efficiency by establishing a relationship between directions and SSs. To strike a flexible balance between the beam pattern gain and sensing efficiency, we also propose a general hybrid TD-SS sensing scheme with target grouping, where targets belonging to the same group are sensed simultaneously via SS sensing, while the targets in different groups are assigned to orthogonal time slots. By controlling the number of groups, the hybrid TD-SS sensing scheme can provide a more flexible balance between beam pattern gain and sensing frequency. Moreover, ...
Multi-Objective Autonomous Exploration on Real-Time Continuous Occupancy Maps
Oct 29, 2021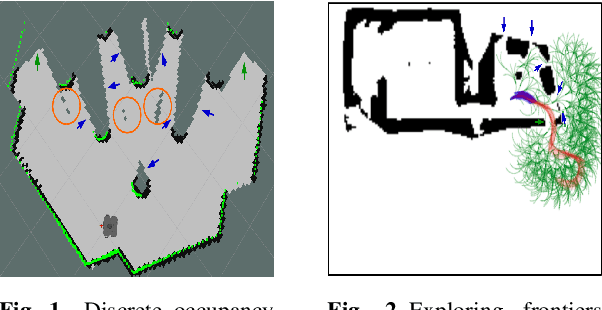
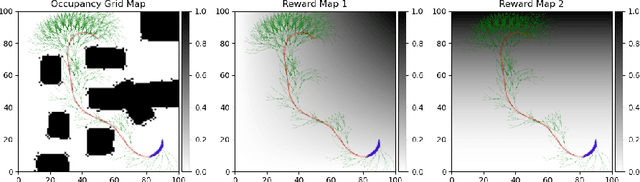


Autonomous exploration in unknown environments using mobile robots is the pillar of many robotic applications. Existing exploration frameworks either select the nearest geometric frontier or the nearest information-theoretic frontier. However, just because a frontier itself is informative does not necessarily mean that the robot will be in an informative area after reaching that frontier. To fill this gap, we propose to use a multi-objective variant of Monte-Carlo tree search that provides a non-myopic Pareto optimal action sequence leading the robot to a frontier with the greatest extent of unknown area uncovering. We also adopted Bayesian Hilbert Map (BHM) for continuous occupancy mapping and made it more applicable to real-time tasks.
A Model-Oriented Approach for Lifting Symmetries in Answer Set Programming
Aug 05, 2022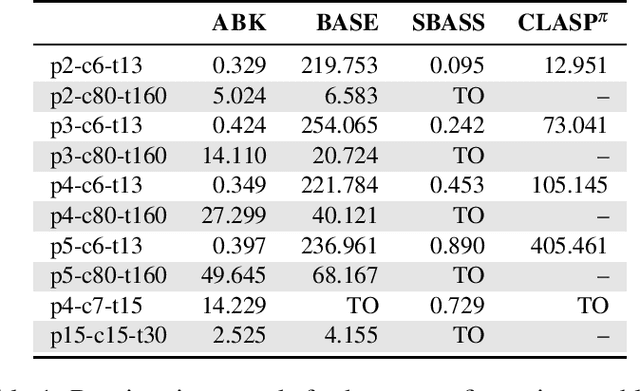
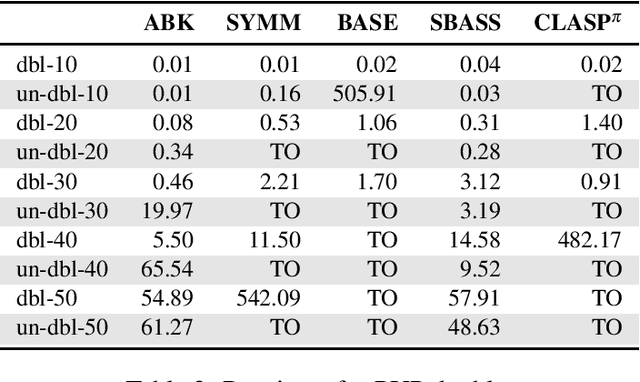
When solving combinatorial problems, pruning symmetric solution candidates from the search space is essential. Most of the existing approaches are instance-specific and focus on the automatic computation of Symmetry Breaking Constraints (SBCs) for each given problem instance. However, the application of such approaches to large-scale instances or advanced problem encodings might be problematic since the computed SBCs are propositional and, therefore, can neither be meaningfully interpreted nor transferred to other instances. As a result, a time-consuming recomputation of SBCs must be done before every invocation of a solver. To overcome these limitations, we introduce a new model-oriented approach for Answer Set Programming that lifts the SBCs of small problem instances into a set of interpretable first-order constraints using a form of machine learning called Inductive Logic Programming. After targeting simple combinatorial problems, we aim to extend our method to be applied also for advanced decision and optimization problems.
* In Proceedings ICLP 2022, arXiv:2208.02685. arXiv admin note: text overlap with arXiv:2112.11806
Space-time Mixing Attention for Video Transformer
Jun 11, 2021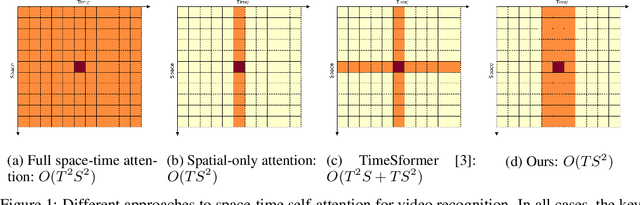
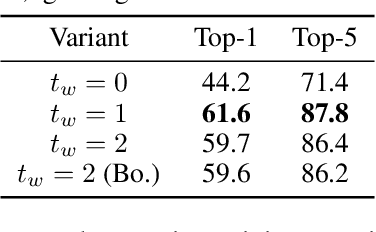
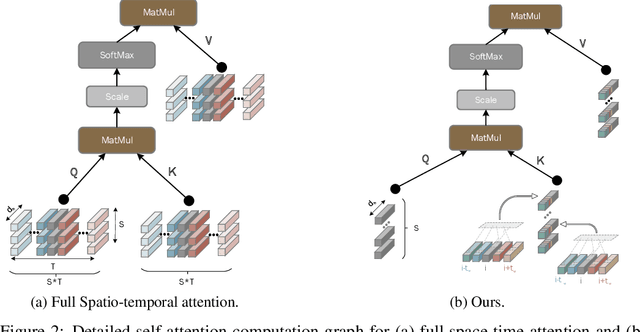
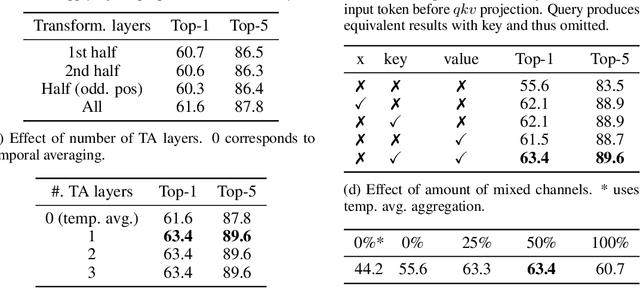
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.