 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Two-Timescale Transmission Design for RIS-Aided Cell-Free Massive MIMO Systems
Oct 19, 2022
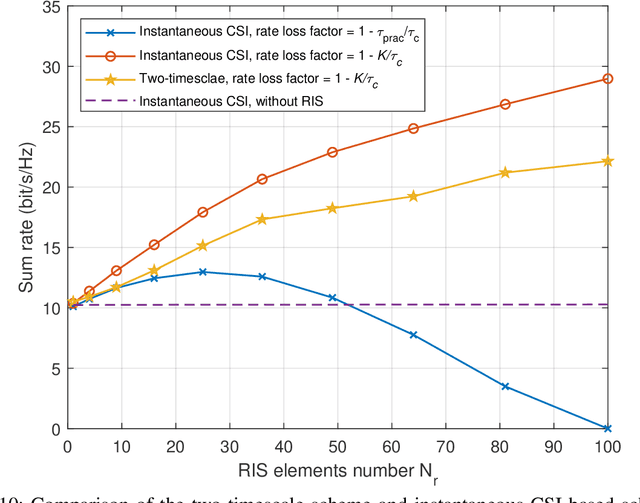
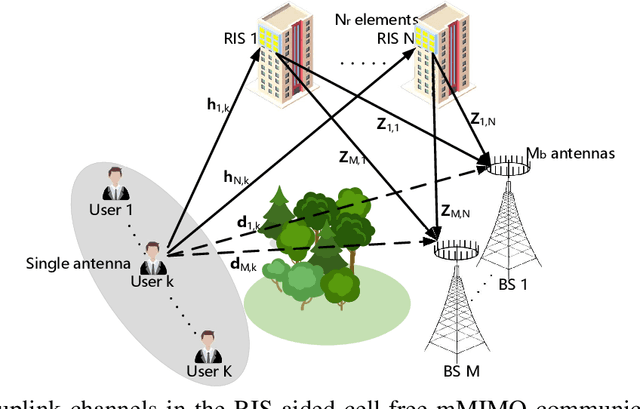
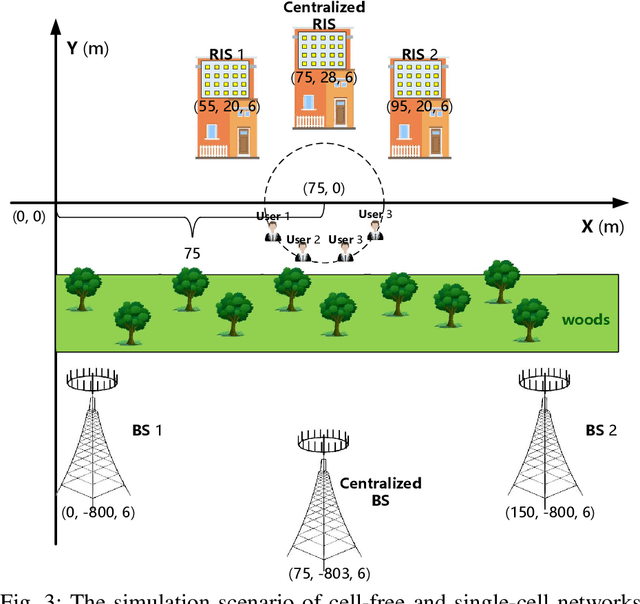
This paper investigates the performance of two-timescale transmission design for uplink reconfigurable intelligent surface (RIS)-aided cell-free massive multiple-input multiple-output (CF-mMIMO) systems. We consider the Rician channel model and design the passive beamforming of RISs based on the long-time statistical channel state information (CSI), while the maximum ratio combining (MRC) technique is utilized to design the active beamforming of base stations (BSs) based on the instantaneous overall channels, which are the superposition of the direct and RIS-reflected channels. Firstly, we derive the closed-form expressions of uplink achievable rate for arbitrary numbers of BS antennas and RIS reflecting elements. Relying on the derived expressions, we theoretically analyze the benefits of RIS-aided cell-free mMIMO systems and draw explicit insights. Then, based on closed-form expressions under statistical CSI, we maximize the sum user rate and the minimum user rate by optimizing the phase shifts of the RISs based on the genetic algorithm (GA). Finally, the numerical results demonstrate the feasibility and the benefits of deploying large-size RISs into conventional cell-free mMIMO systems. Besides, our results validate the effectiveness of the proposed two-timescale scheme in the RIS-aided cell-free mMIMO systems.
Characterization of causal ancestral graphs for time series with latent confounders
Dec 15, 2021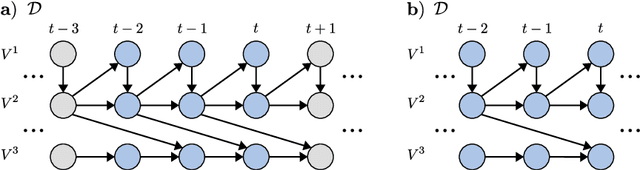
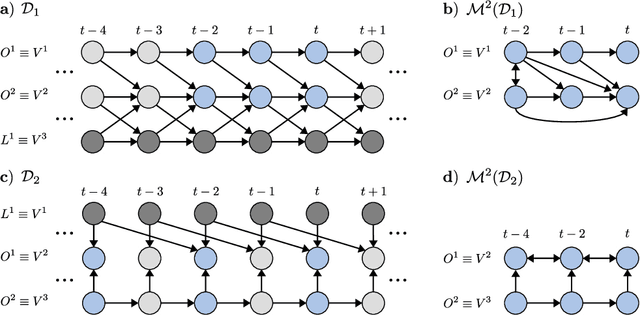


Generalizing directed maximal ancestral graphs, we introduce a class of graphical models for representing time lag specific causal relationships and independencies among finitely many regularly sampled and regularly subsampled time steps of multivariate time series with unobserved variables. We completely characterize these graphs and show that they entail constraints beyond those that have previously been considered in the literature. This allows for stronger causal inferences without having imposed additional assumptions. In generalization of directed partial ancestral graphs we further introduce a graphical representation of Markov equivalence classes of the novel type of graphs and show that these are more informative than what current state-of-the-art causal discovery algorithms learn. We also analyze the additional information gained by increasing the number of observed time steps.
Compact and Robust Deep Learning Architecture for Fluorescence Lifetime Imaging and FPGA Implementation
Sep 09, 2022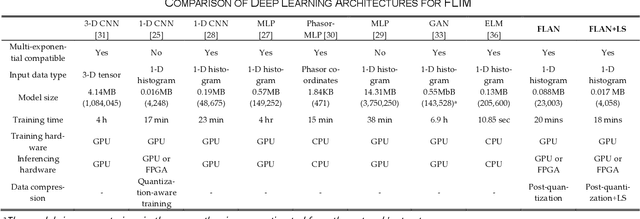
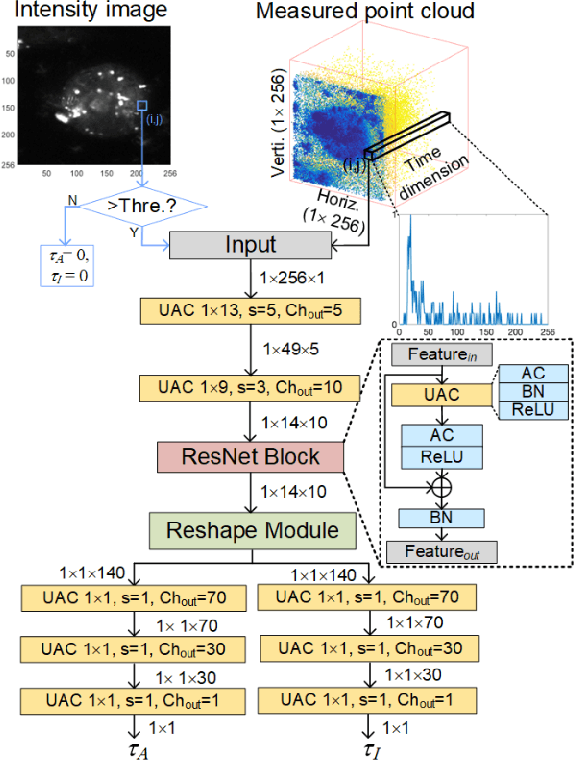
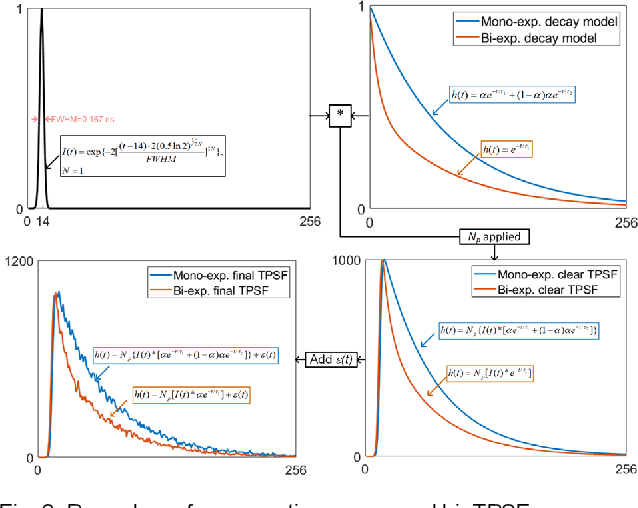
This paper reported a bespoke adder-based deep learning network for time-domain fluorescence lifetime imaging (FLIM). By leveraging the l1-norm extraction method, we propose a 1-D Fluorescence Lifetime AdderNet (FLAN) without multiplication-based convolutions to reduce the computational complexity. Further, we compressed fluorescence decays in temporal dimension using a log-scale merging technique to discard redundant temporal information derived as log-scaling FLAN (FLAN+LS). FLAN+LS achieves 0.11 and 0.23 compression ratios compared with FLAN and a conventional 1-D convolutional neural network (1-D CNN) while maintaining high accuracy in retrieving lifetimes. We extensively evaluated FLAN and FLAN+LS using synthetic and real data. A traditional fitting method and other non-fitting, high-accuracy algorithms were compared with our networks for synthetic data. Our networks attained a minor reconstruction error in different photon-count scenarios. For real data, we used fluorescent beads' data acquired by a confocal microscope to validate the effectiveness of real fluorophores, and our networks can differentiate beads with different lifetimes. Additionally, we implemented the network architecture on a field-programmable gate array (FPGA) with a post-quantization technique to shorten the bit-width, thereby improving computing efficiency. FLAN+LS on hardware achieves the highest computing efficiency compared to 1-D CNN and FLAN. We also discussed the applicability of our network and hardware architecture for other time-resolved biomedical applications using photon-efficient, time-resolved sensors.
Exploiting Expert Knowledge for Assigning Firms to Industries: A Novel Deep Learning Method
Sep 11, 2022
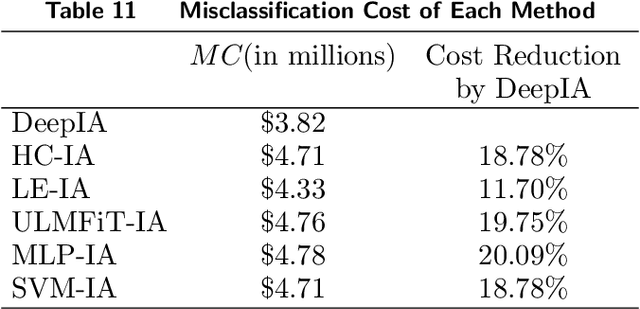
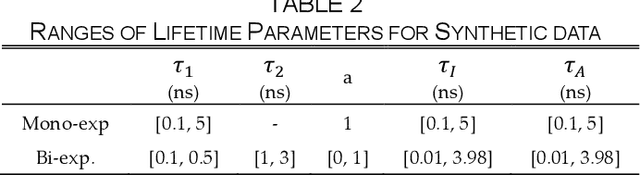
Industry assignment, which assigns firms to industries according to a predefined Industry Classification System (ICS), is fundamental to a large number of critical business practices, ranging from operations and strategic decision making by firms to economic analyses by government agencies. Three types of expert knowledge are essential to effective industry assignment: definition-based knowledge (i.e., expert definitions of each industry), structure-based knowledge (i.e., structural relationships among industries as specified in an ICS), and assignment-based knowledge (i.e., prior firm-industry assignments performed by domain experts). Existing industry assignment methods utilize only assignment-based knowledge to learn a model that classifies unassigned firms to industries, and overlook definition-based and structure-based knowledge. Moreover, these methods only consider which industry a firm has been assigned to, but ignore the time-specificity of assignment-based knowledge, i.e., when the assignment occurs. To address the limitations of existing methods, we propose a novel deep learning-based method that not only seamlessly integrates the three types of knowledge for industry assignment but also takes the time-specificity of assignment-based knowledge into account. Methodologically, our method features two innovations: dynamic industry representation and hierarchical assignment. The former represents an industry as a sequence of time-specific vectors by integrating the three types of knowledge through our proposed temporal and spatial aggregation mechanisms. The latter takes industry and firm representations as inputs, computes the probability of assigning a firm to different industries, and assigns the firm to the industry with the highest probability.
Bending the Future: Autoregressive Modeling of Temporal Knowledge Graphs in Curvature-Variable Hyperbolic Spaces
Sep 12, 2022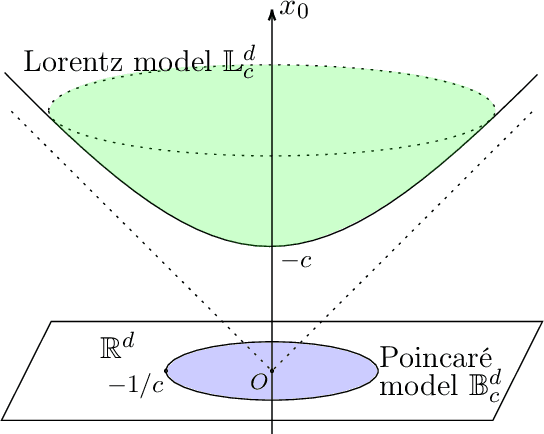
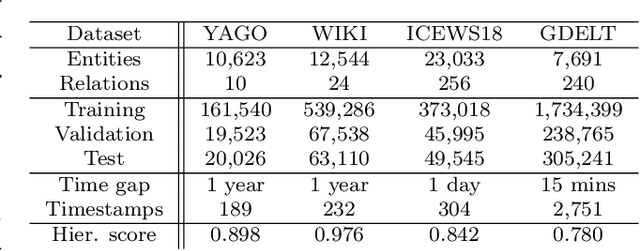
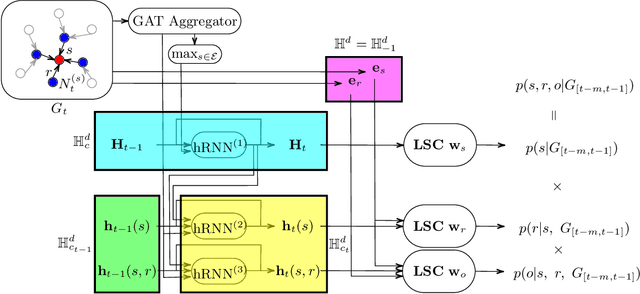
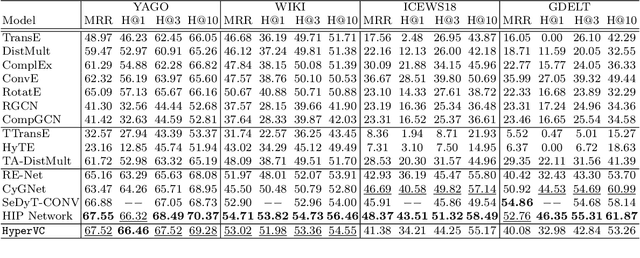
Recently there is an increasing scholarly interest in time-varying knowledge graphs, or temporal knowledge graphs (TKG). Previous research suggests diverse approaches to TKG reasoning that uses historical information. However, less attention has been given to the hierarchies within such information at different timestamps. Given that TKG is a sequence of knowledge graphs based on time, the chronology in the sequence derives hierarchies between the graphs. Furthermore, each knowledge graph has its hierarchical level which may differ from one another. To address these hierarchical characteristics in TKG, we propose HyperVC, which utilizes hyperbolic space that better encodes the hierarchies than Euclidean space. The chronological hierarchies between knowledge graphs at different timestamps are represented by embedding the knowledge graphs as vectors in a common hyperbolic space. Additionally, diverse hierarchical levels of knowledge graphs are represented by adjusting the curvatures of hyperbolic embeddings of their entities and relations. Experiments on four benchmark datasets show substantial improvements, especially on the datasets with higher hierarchical levels.
DEPTS: Deep Expansion Learning for Periodic Time Series Forecasting
Mar 15, 2022
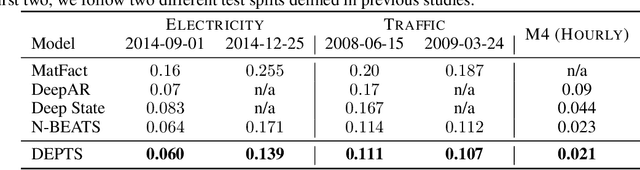
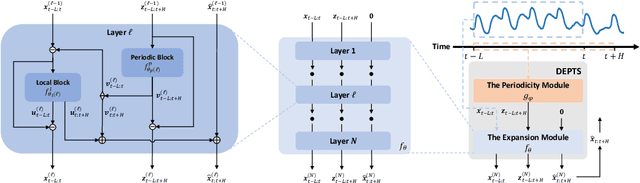
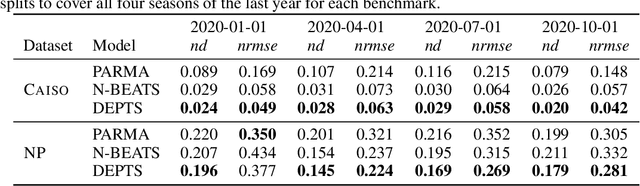
Periodic time series (PTS) forecasting plays a crucial role in a variety of industries to foster critical tasks, such as early warning, pre-planning, resource scheduling, etc. However, the complicated dependencies of the PTS signal on its inherent periodicity as well as the sophisticated composition of various periods hinder the performance of PTS forecasting. In this paper, we introduce a deep expansion learning framework, DEPTS, for PTS forecasting. DEPTS starts with a decoupled formulation by introducing the periodic state as a hidden variable, which stimulates us to make two dedicated modules to tackle the aforementioned two challenges. First, we develop an expansion module on top of residual learning to perform a layer-by-layer expansion of those complicated dependencies. Second, we introduce a periodicity module with a parameterized periodic function that holds sufficient capacity to capture diversified periods. Moreover, our two customized modules also have certain interpretable capabilities, such as attributing the forecasts to either local momenta or global periodicity and characterizing certain core periodic properties, e.g., amplitudes and frequencies. Extensive experiments on both synthetic data and real-world data demonstrate the effectiveness of DEPTS on handling PTS. In most cases, DEPTS achieves significant improvements over the best baseline. Specifically, the error reduction can even reach up to 20% for a few cases. Finally, all codes are publicly available.
Dynamic Control Barrier Function-based Model Predictive Control to Safety-Critical Obstacle-Avoidance of Mobile Robot
Sep 18, 2022
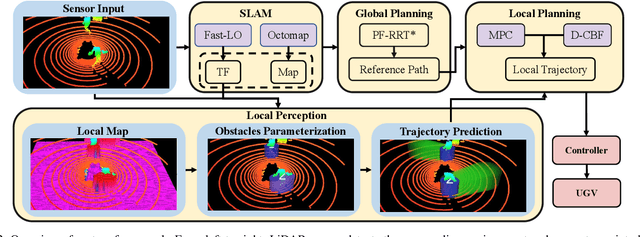
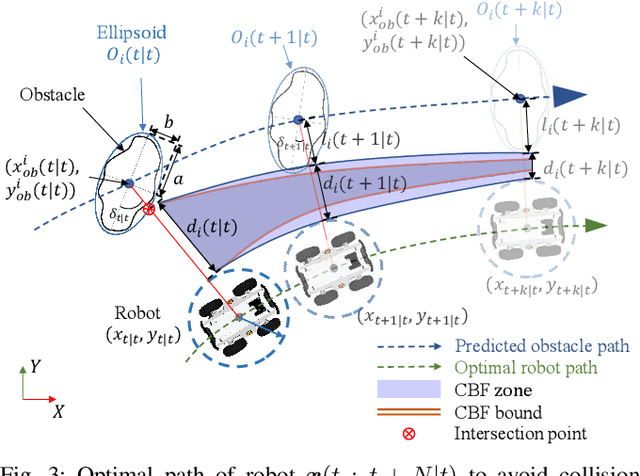
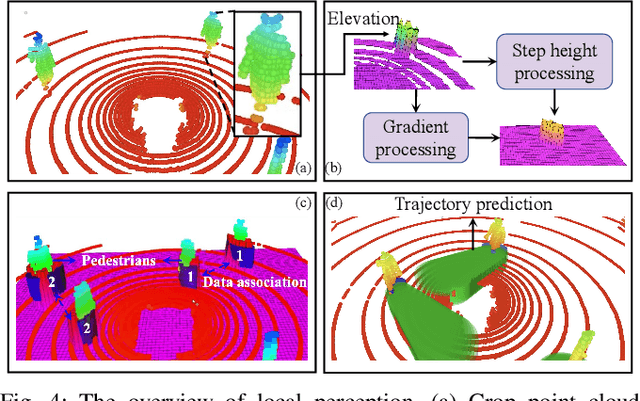
This paper presents an efficient and safe method to avoid static and dynamic obstacles based on LiDAR. First, point cloud is used to generate a real-time local grid map for obstacle detection. Then, obstacles are clustered by DBSCAN algorithm and enclosed with minimum bounding ellipses (MBEs). In addition, data association is conducted to match each MBE with the obstacle in the current frame. Considering MBE as an observation, Kalman filter (KF) is used to estimate and predict the motion state of the obstacle. In this way, the trajectory of each obstacle in the forward time domain can be parameterized as a set of ellipses. Due to the uncertainty of the MBE, the semi-major and semi-minor axes of the parameterized ellipse are extended to ensure safety. We extend the traditional Control Barrier Function (CBF) and propose Dynamic Control Barrier Function (D-CBF). We combine D-CBF with Model Predictive Control (MPC) to implement safety-critical dynamic obstacle avoidance. Experiments in simulated and real scenarios are conducted to verify the effectiveness of our algorithm. The source code is released for the reference of the community.
CaSS: A Channel-aware Self-supervised Representation Learning Framework for Multivariate Time Series Classification
Mar 08, 2022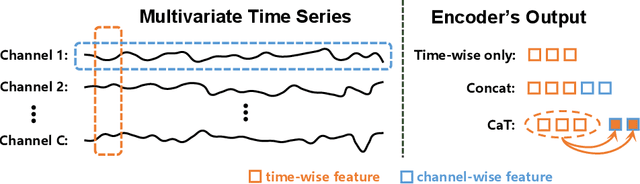
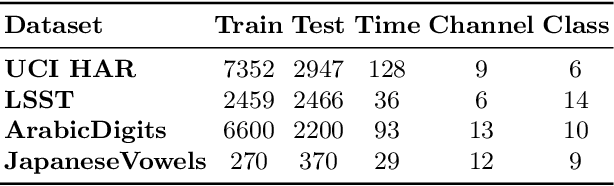
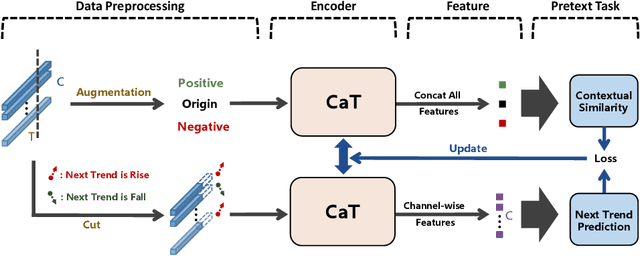
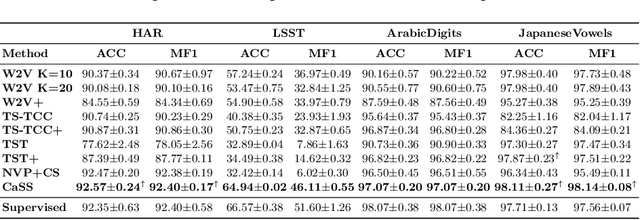
Self-supervised representation learning of Multivariate Time Series (MTS) is a challenging task and attracts increasing research interests in recent years. Many previous works focus on the pretext task of self-supervised learning and usually neglect the complex problem of MTS encoding, leading to unpromising results. In this paper, we tackle this challenge from two aspects: encoder and pretext task, and propose a unified channel-aware self-supervised learning framework CaSS. Specifically, we first design a new Transformer-based encoder Channel-aware Transformer (CaT) to capture the complex relationships between different time channels of MTS. Second, we combine two novel pretext tasks Next Trend Prediction (NTP) and Contextual Similarity (CS) for the self-supervised representation learning with our proposed encoder. Extensive experiments are conducted on several commonly used benchmark datasets. The experimental results show that our framework achieves new state-of-the-art comparing with previous self-supervised MTS representation learning methods (up to +7.70\% improvement on LSST dataset) and can be well applied to the downstream MTS classification.
RISO: Combining Rigid Grippers with Soft Switchable Adhesives
Oct 27, 2022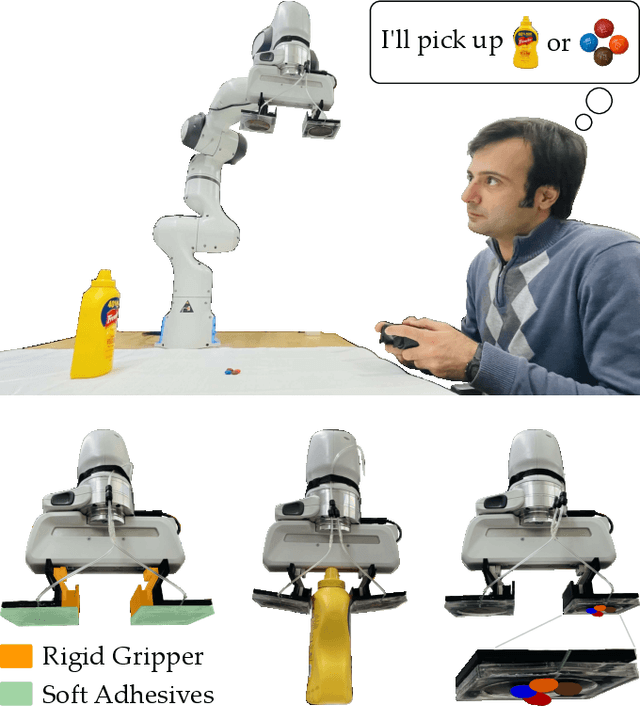
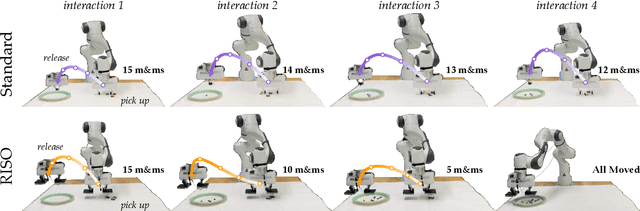
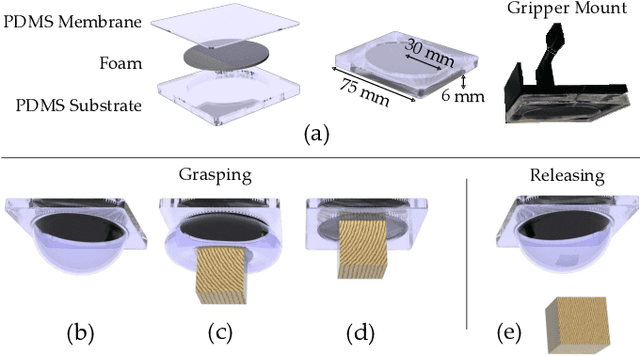
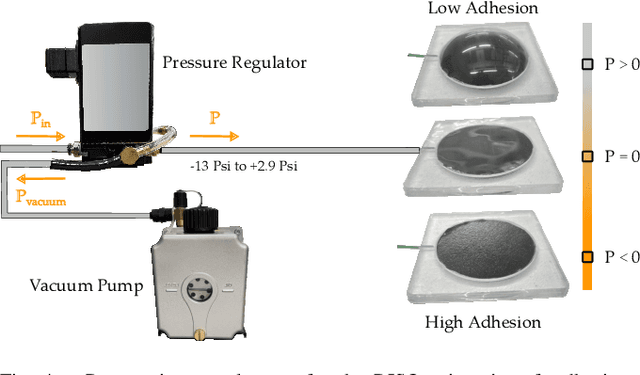
Robot arms that assist humans should be able to pick up, move, and release everyday objects. Today's assistive robot arms use rigid grippers to pinch items between fingers; while these rigid grippers are well suited for large and heavy objects, they often struggle to grasp small, numerous, or delicate items (such as foods). Soft grippers cover the opposite end of the spectrum; these grippers use adhesives or change shape to wrap around small and irregular items, but cannot exert the large forces needed to manipulate heavy objects. In this paper we introduce RIgid-SOft (RISO) grippers that combine switchable soft adhesives with standard rigid mechanisms to enable a diverse range of robotic grasping. We develop RISO grippers by leveraging a novel class of soft materials that change adhesion force in real-time through pneumatically controlled shape and rigidity tuning. By mounting these soft adhesives on the bottom of rigid fingers, we create a gripper that can interact with objects using either purely rigid grasps (pinching the object) or purely soft grasps (adhering to the object). This increased capability requires additional decision making, and we therefore formulate a shared control approach that partially automates the motion of the robot arm. In practice, this controller aligns the RISO gripper while inferring which object the human wants to grasp and how the human wants to grasp that item. Our user study demonstrates that RISO grippers can pick up, move, and release household items from existing datasets, and that the system performs grasps more successfully and efficiently when sharing control between the human and robot. See videos here: https://youtu.be/5uLUkBYcnwg
HYDRA-HGR: A Hybrid Transformer-based Architecture for Fusion of Macroscopic and Microscopic Neural Drive Information
Oct 27, 2022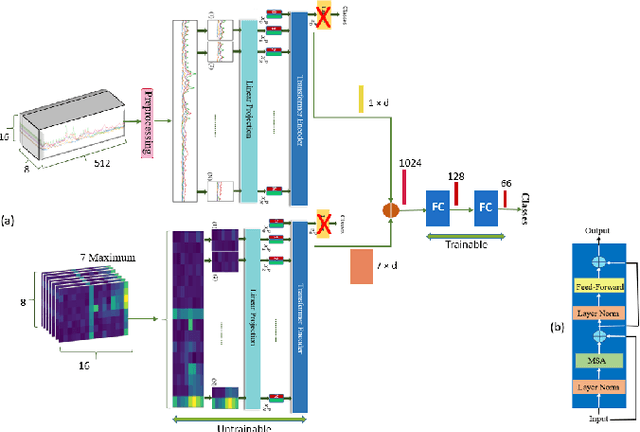
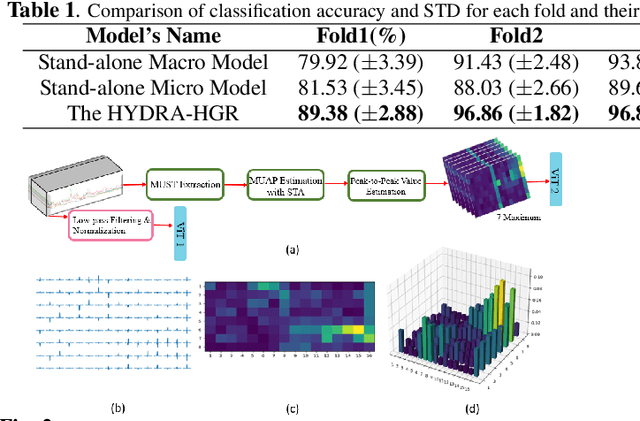
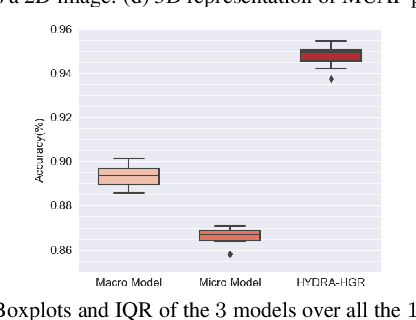
Development of advance surface Electromyogram (sEMG)-based Human-Machine Interface (HMI) systems is of paramount importance to pave the way towards emergence of futuristic Cyber-Physical-Human (CPH) worlds. In this context, the main focus of recent literature was on development of different Deep Neural Network (DNN)-based architectures that perform Hand Gesture Recognition (HGR) at a macroscopic level (i.e., directly from sEMG signals). At the same time, advancements in acquisition of High-Density sEMG signals (HD-sEMG) have resulted in a surge of significant interest on sEMG decomposition techniques to extract microscopic neural drive information. However, due to complexities of sEMG decomposition and added computational overhead, HGR at microscopic level is less explored than its aforementioned DNN-based counterparts. In this regard, we propose the HYDRA-HGR framework, which is a hybrid model that simultaneously extracts a set of temporal and spatial features through its two independent Vision Transformer (ViT)-based parallel architectures (the so called Macro and Micro paths). The Macro Path is trained directly on the pre-processed HD-sEMG signals, while the Micro path is fed with the p-to-p values of the extracted Motor Unit Action Potentials (MUAPs) of each source. Extracted features at macroscopic and microscopic levels are then coupled via a Fully Connected (FC) fusion layer. We evaluate the proposed hybrid HYDRA-HGR framework through a recently released HD-sEMG dataset, and show that it significantly outperforms its stand-alone counterparts. The proposed HYDRA-HGR framework achieves average accuracy of 94.86% for the 250 ms window size, which is 5.52% and 8.22% higher than that of the Macro and Micro paths, respectively.