 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Changepoint Detection for Real-Time Spectrum Sharing Radar
Jun 30, 2022
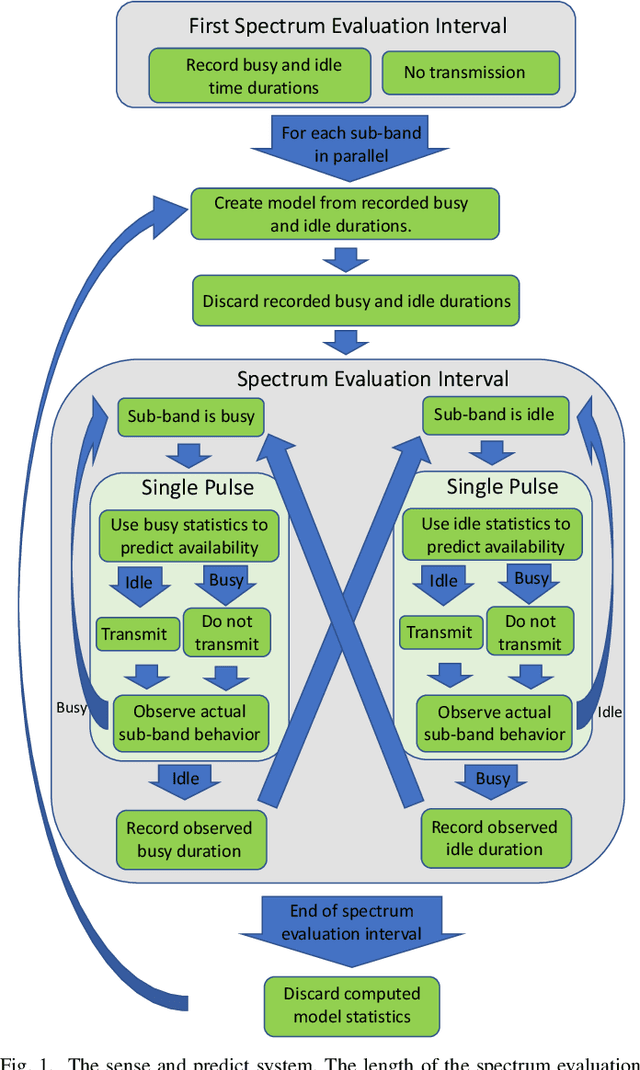
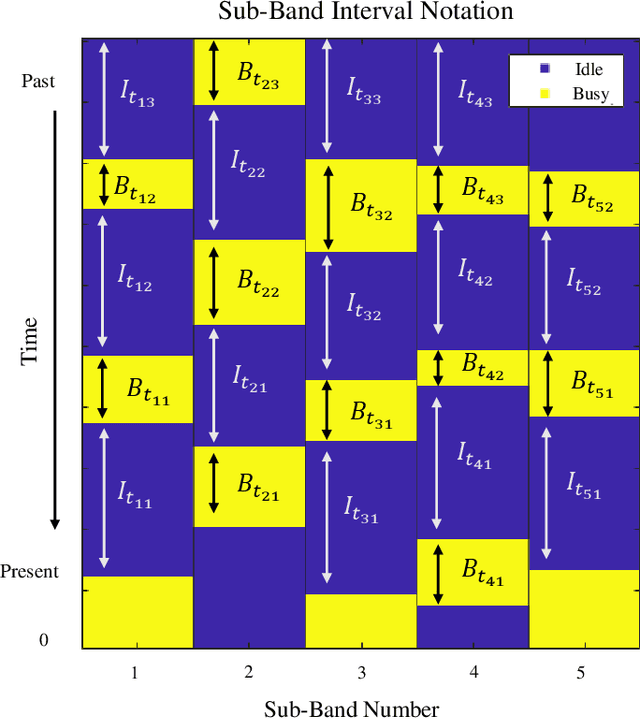
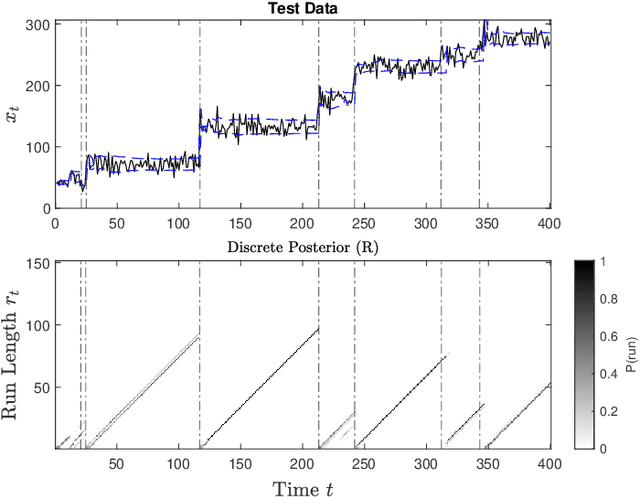
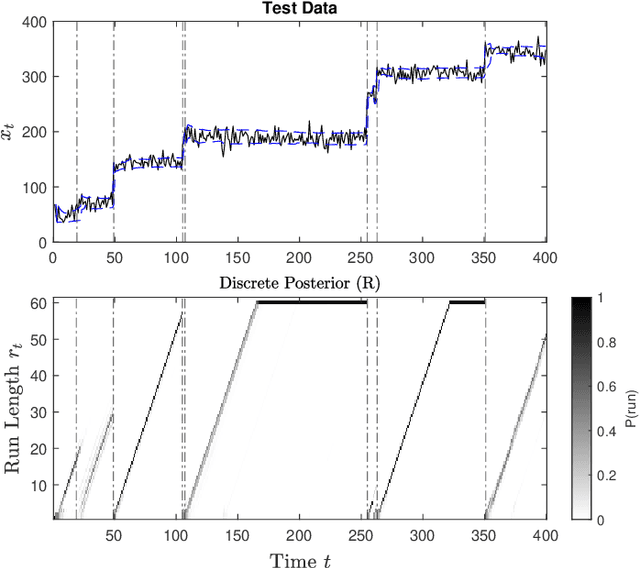
Radar must adapt to changing environments, and we propose changepoint detection as a method to do so. In the world of increasingly congested radio frequencies, radars must adapt to avoid interference. Many radar systems employ the prediction action cycle to proactively determine transmission mode while spectrum sharing. This method constructs and implements a model of the environment to predict unused frequencies, and then transmits in this predicted availability. For these selection strategies, performance is directly reliant on the quality of the underlying environmental models. In order to keep up with a changing environment, these models can employ changepoint detection. Changepoint detection is the identification of sudden changes, or changepoints, in the distribution from which data is drawn. This information allows the models to discard "garbage" data from a previous distribution, which has no relation to the current state of the environment. In this work, bayesian online changepoint detection (BOCD) is applied to the sense and predict algorithm to increase the accuracy of its models and improve its performance. In the context of spectrum sharing, these changepoints represent interferers leaving and entering the spectral environment. The addition of changepoint detection allows for dynamic and robust spectrum sharing even as interference patterns change dramatically. BOCD is especially advantageous because it enables online changepoint detection, allowing models to be updated continuously as data are collected. This strategy can also be applied to many other predictive algorithms that create models in a changing environment.
NoiSER: Noise is All You Need for Enhancing Low-Light Images Without Task-Related Data
Nov 09, 2022
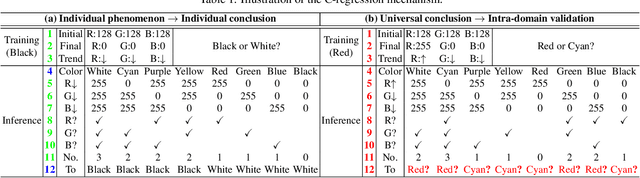

This paper is about an extraordinary phenomenon. Suppose we don't use any low-light images as training data, can we enhance a low-light image by deep learning? Obviously, current methods cannot do this, since deep neural networks require to train their scads of parameters using copious amounts of training data, especially task-related data. In this paper, we show that in the context of fundamental deep learning, it is possible to enhance a low-light image without any task-related training data. Technically, we propose a new, magical, effective and efficient method, termed \underline{Noi}se \underline{SE}lf-\underline{R}egression (NoiSER), which learns a gray-world mapping from Gaussian distribution for low-light image enhancement (LLIE). Specifically, a self-regression model is built as a carrier to learn a gray-world mapping during training, which is performed by simply iteratively feeding random noise. During inference, a low-light image is directly fed into the learned mapping to yield a normal-light one. Extensive experiments show that our NoiSER is highly competitive to current task-related data based LLIE models in terms of quantitative and visual results, while outperforming them in terms of the number of parameters, training time and inference speed. With only about 1K parameters, NoiSER realizes about 1 minute for training and 1.2 ms for inference with 600$\times$400 resolution on RTX 2080 Ti. Besides, NoiSER has an inborn automated exposure suppression capability and can automatically adjust too bright or too dark, without additional manipulations.
A Signal Temporal Logic Motion Planner for Bird Diverter Installation Tasks with Multi-Robot Aerial Systems
Oct 18, 2022
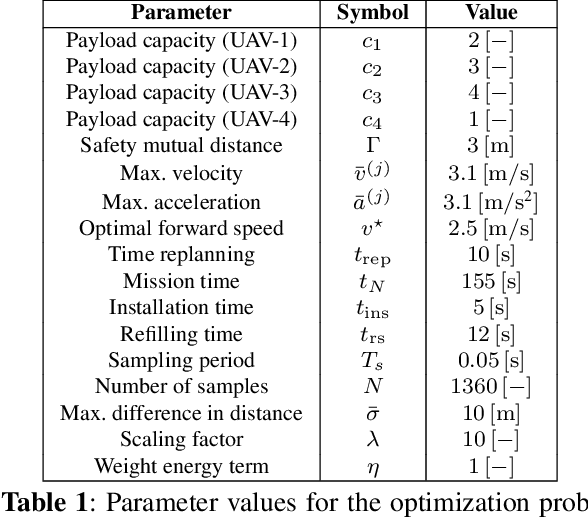
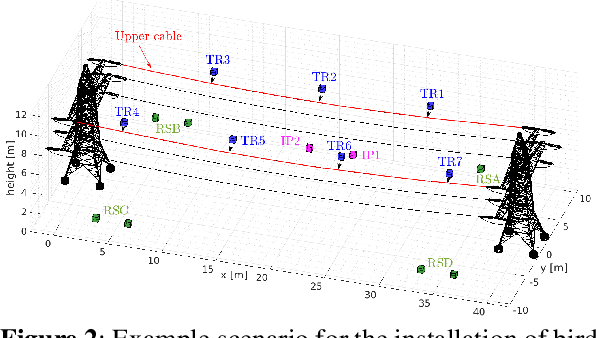
This paper investigates the problem of task assignment and trajectory generation for the installation of bird diverters with a fleet of multirotors leveraging on Signal Temporal Logic (STL) specifications. We extend our previous motion planner to compute feasible and constrained trajectories, taking into account payload capacity limitations and recharging constraints. The proposed planner ensures the continuity of the operation, while guaranteeing compliance with safety requirements and mission fulfillment. Additionally, an event-based replanning strategy is proposed to react to unforeseen failures. An energy minimization term is also considered to implicitly save multirotor flight time during installation operations. Numerical simulations in MATLAB, Gazebo, and field experiments demonstrate the performance of the approach and its validity in mock-up scenarios.
System theoretic approach of information processing in nested cellular automata
Oct 12, 2022
The subject of this paper is the evolution of the concept of information processing in regular structures based on multi-level processing in nested cellular automata. The essence of the proposed model is a discrete space-time containing nested orthogonal space-times at its points. The factorization of the function describing the global behavior of a system is the key element of the mathematical description. Factorization describes the relations of physical connections, signal propagation times and signal processing to global behavior. In the model appear expressions similar to expressions used in the Special Relativity Theory.
HERMES: Hybrid Error-corrector Model with inclusion of External Signals for nonstationary fashion time series
Feb 15, 2022Developing models and algorithms to draw causal inference for time series is a long standing statistical problem. It is crucial for many applications, in particular for fashion or retail industries, to make optimal inventory decisions and avoid massive wastes. By tracking thousands of fashion trends on social media with state-of-the-art computer vision approaches, we propose a new model for fashion time series forecasting. Our contribution is twofold. We first provide publicly the first fashion dataset gathering 10000 weekly fashion time series. As influence dynamics are the key of emerging trend detection, we associate with each time series an external weak signal representing behaviors of influencers. Secondly, to leverage such a complex and rich dataset, we propose a new hybrid forecasting model. Our approach combines per-time-series parametric models with seasonal components and a global recurrent neural network to include sporadic external signals. This hybrid model provides state-of-the-art results on the proposed fashion dataset, on the weekly time series of the M4 competition, and illustrates the benefit of the contribution of external weak signals.
Efficient Graph Neural Network Inference at Large Scale
Nov 05, 2022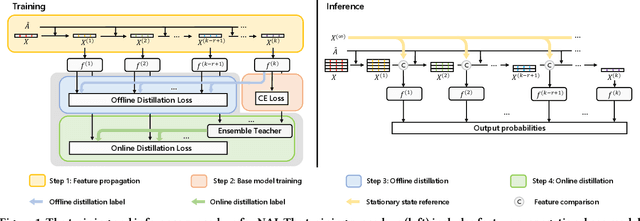
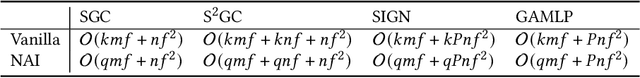
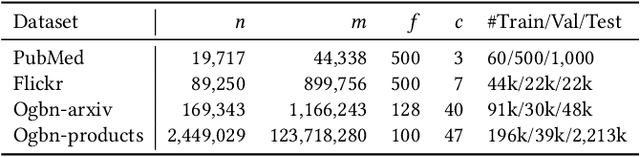
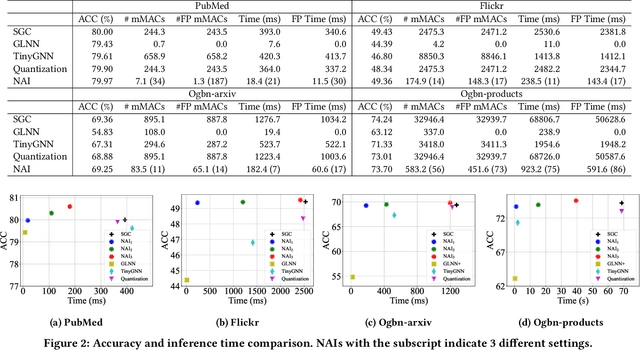
Graph neural networks (GNNs) have demonstrated excellent performance in a wide range of applications. However, the enormous size of large-scale graphs hinders their applications under real-time inference scenarios. Although existing scalable GNNs leverage linear propagation to preprocess the features and accelerate the training and inference procedure, these methods still suffer from scalability issues when making inferences on unseen nodes, as the feature preprocessing requires the graph is known and fixed. To speed up the inference in the inductive setting, we propose a novel adaptive propagation order approach that generates the personalized propagation order for each node based on its topological information. This could successfully avoid the redundant computation of feature propagation. Moreover, the trade-off between accuracy and inference latency can be flexibly controlled by simple hyper-parameters to match different latency constraints of application scenarios. To compensate for the potential inference accuracy loss, we further propose Inception Distillation to exploit the multi scale reception information and improve the inference performance. Extensive experiments are conducted on four public datasets with different scales and characteristics, and the experimental results show that our proposed inference acceleration framework outperforms the SOTA graph inference acceleration baselines in terms of both accuracy and efficiency. In particular, the advantage of our proposed method is more significant on larger-scale datasets, and our framework achieves $75\times$ inference speedup on the largest Ogbn-products dataset.
Leveraging the Hints: Adaptive Bidding in Repeated First-Price Auctions
Nov 05, 2022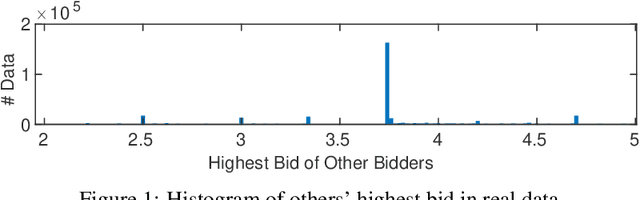
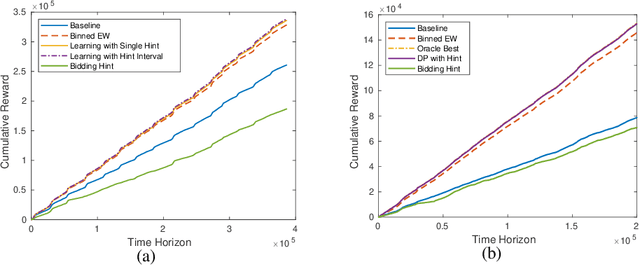
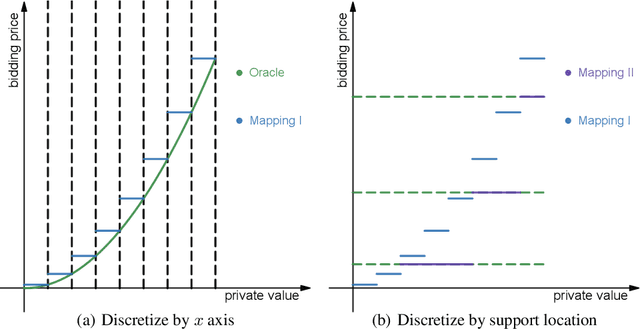
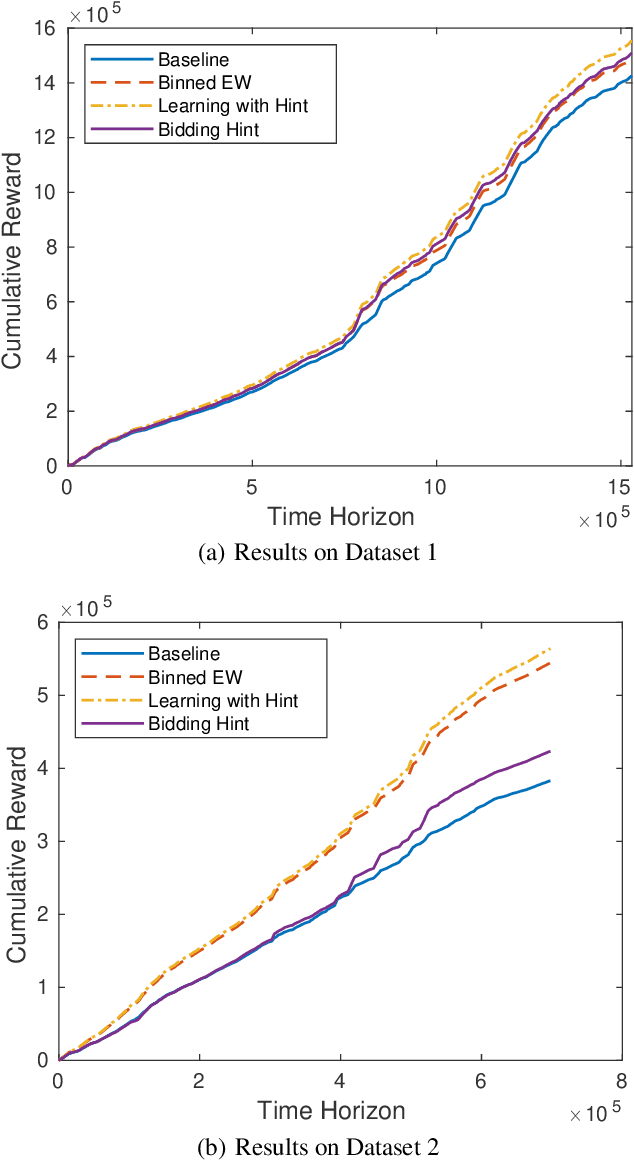
With the advent and increasing consolidation of e-commerce, digital advertising has very recently replaced traditional advertising as the main marketing force in the economy. In the past four years, a particularly important development in the digital advertising industry is the shift from second-price auctions to first-price auctions for online display ads. This shift immediately motivated the intellectually challenging question of how to bid in first-price auctions, because unlike in second-price auctions, bidding one's private value truthfully is no longer optimal. Following a series of recent works in this area, we consider a differentiated setup: we do not make any assumption about other bidders' maximum bid (i.e. it can be adversarial over time), and instead assume that we have access to a hint that serves as a prediction of other bidders' maximum bid, where the prediction is learned through some blackbox machine learning model. We consider two types of hints: one where a single point-prediction is available, and the other where a hint interval (representing a type of confidence region into which others' maximum bid falls) is available. We establish minimax optimal regret bounds for both cases and highlight the quantitatively different behavior between the two settings. We also provide improved regret bounds when the others' maximum bid exhibits the further structure of sparsity. Finally, we complement the theoretical results with demonstrations using real bidding data.
A Filtering-based General Approach to Learning Rational Constraints of Epistemic Graphs
Nov 05, 2022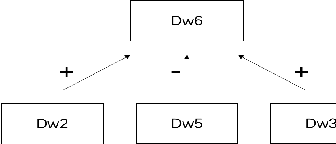
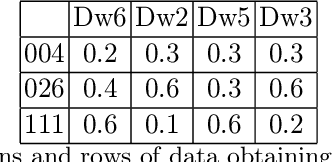
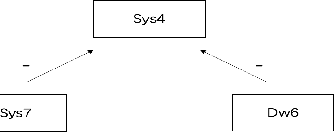
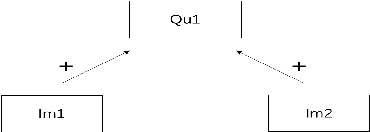
Epistemic graphs generalize the epistemic approach to probabilistic argumentation and tackle the uncertainties in and between arguments. A framework was proposed to generate epistemic constraints from data using a two-way generalization method in the perspective of only considering the beliefs of participants without considering the nature of relations represented in an epistemic graph. The deficiency of original framework is that it is unable to learn rules using tighter constraints, and the learnt rules might be counterintuitive. Meanwhile, when dealing with more restricted values, the filtering computational complexity will increase sharply, and the time performance would become unreasonable. This paper introduces a filtering-based approach using a multiple-way generalization step to generate a set of rational rules based on both the beliefs of each agent on different arguments and the epistemic graph corresponding to the epistemic constraints. This approach is able to generated rational rules with multiple restricted values in higher efficiency. Meanwhile, we have proposed a standard to analyze the rationality of a dataset based on the postulates of deciding rational rules. We evaluate the filtering-based approach on two suitable data bases. The empirical results show that the filtering-based approach performs well with a better efficiency comparing to the original framework, and rules generated from the improved approach are ensured to be rational.
HREyes: Design, Development, and Evaluation of a Novel Method for AUVs to Communicate Information and Gaze Direction
Nov 05, 2022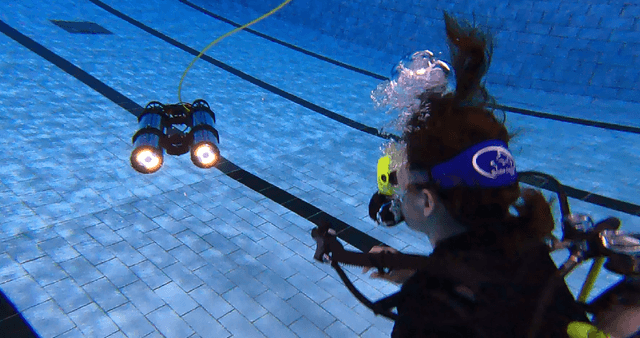

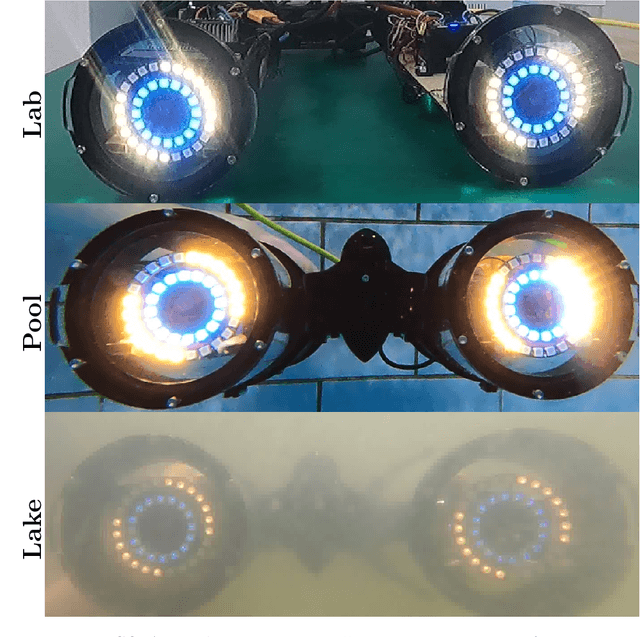

We present the design, development, and evaluation of HREyes: biomimetic communication devices which use light to communicate information and, for the first time, gaze direction from AUVs to humans. First, we introduce two types of information displays using the HREye devices: active lucemes and ocular lucemes. Active lucemes communicate information explicitly through animations, while ocular lucemes communicate gaze direction implicitly by mimicking human eyes. We present a human study in which our system is compared to the use of an embedded digital display that explicitly communicates information to a diver by displaying text. Our results demonstrate accurate recognition of active lucemes for trained interactants, limited intuitive understanding of these lucemes for untrained interactants, and relatively accurate perception of gaze direction for all interactants. The results on active luceme recognition demonstrate more accurate recognition than previous light-based communication systems for AUVs (albeit with different phrase sets). Additionally, the ocular lucemes we introduce in this work represent the first method for communicating gaze direction from an AUV, a critical aspect of nonverbal communication used in collaborative work. With readily available hardware as well as open-source and easily re-configurable programming, HREyes can be easily integrated into any AUV with the physical space for the devices and used to communicate effectively with divers in any underwater environment with appropriate visibility.
A Multi-task Model for Sentiment Aided Stance Detection of Climate Change Tweets
Nov 07, 2022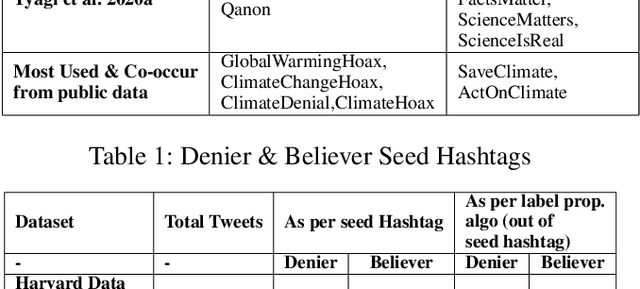
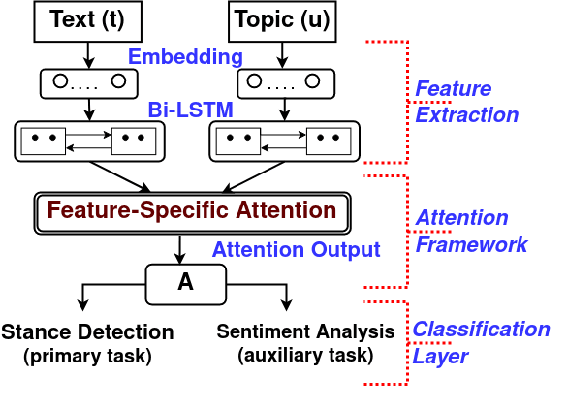
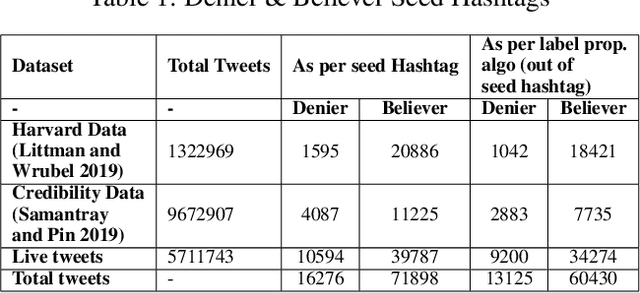
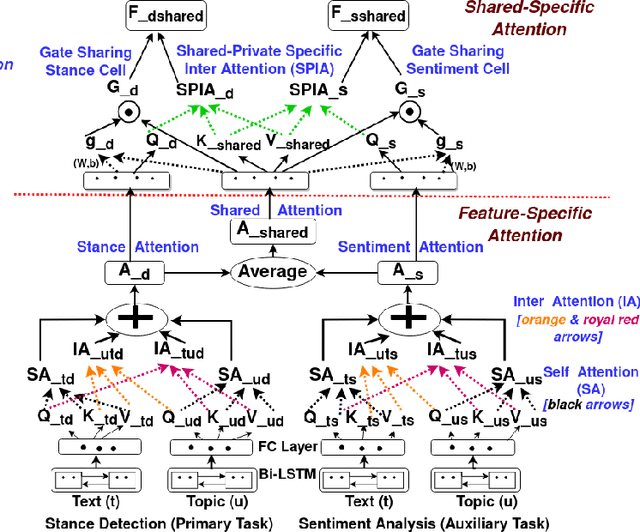
Climate change has become one of the biggest challenges of our time. Social media platforms such as Twitter play an important role in raising public awareness and spreading knowledge about the dangers of the current climate crisis. With the increasing number of campaigns and communication about climate change through social media, the information could create more awareness and reach the general public and policy makers. However, these Twitter communications lead to polarization of beliefs, opinion-dominated ideologies, and often a split into two communities of climate change deniers and believers. In this paper, we propose a framework that helps identify denier statements on Twitter and thus classifies the stance of the tweet into one of the two attitudes towards climate change (denier/believer). The sentimental aspects of Twitter data on climate change are deeply rooted in general public attitudes toward climate change. Therefore, our work focuses on learning two closely related tasks: Stance Detection and Sentiment Analysis of climate change tweets. We propose a multi-task framework that performs stance detection (primary task) and sentiment analysis (auxiliary task) simultaneously. The proposed model incorporates the feature-specific and shared-specific attention frameworks to fuse multiple features and learn the generalized features for both tasks. The experimental results show that the proposed framework increases the performance of the primary task, i.e., stance detection by benefiting from the auxiliary task, i.e., sentiment analysis compared to its uni-modal and single-task variants.