 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Scalable Data-Driven Technique for Joint Evacuation Routing and Scheduling Problems
Sep 12, 2022

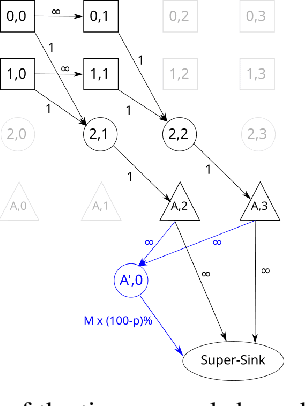
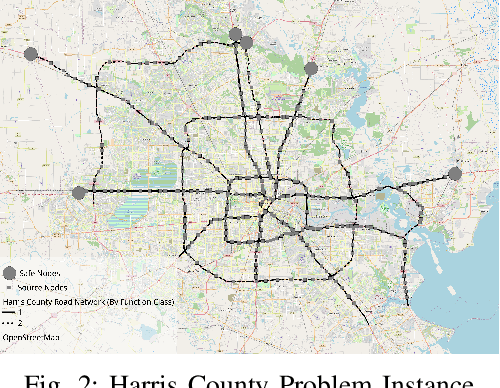
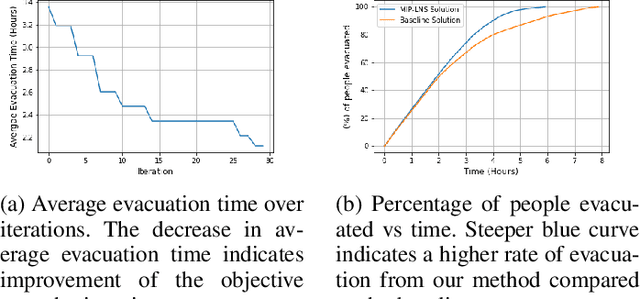
Evacuation planning is a crucial part of disaster management where the goal is to relocate people to safety and minimize casualties. Every evacuation plan has two essential components: routing and scheduling. However, joint optimization of these two components with objectives such as minimizing average evacuation time or evacuation completion time, is a computationally hard problem. To approach it, we present MIP-LNS, a scalable optimization method that combines heuristic search with mathematical optimization and can optimize a variety of objective functions. We use real-world road network and population data from Harris County in Houston, Texas, and apply MIP-LNS to find evacuation routes and schedule for the area. We show that, within a given time limit, our proposed method finds better solutions than existing methods in terms of average evacuation time, evacuation completion time and optimality guarantee of the solutions. We perform agent-based simulations of evacuation in our study area to demonstrate the efficacy and robustness of our solution. We show that our prescribed evacuation plan remains effective even if the evacuees deviate from the suggested schedule upto a certain extent. We also examine how evacuation plans are affected by road failures. Our results show that MIP-LNS can use information regarding estimated deadline of roads to come up with better evacuation plans in terms evacuating more people successfully and conveniently.
DAD: Data-free Adversarial Defense at Test Time
Apr 08, 2022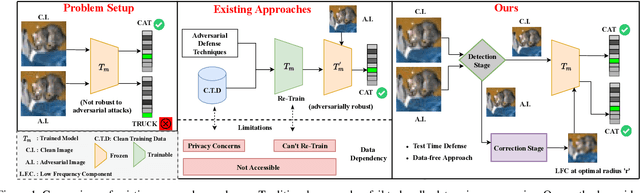



Deep models are highly susceptible to adversarial attacks. Such attacks are carefully crafted imperceptible noises that can fool the network and can cause severe consequences when deployed. To encounter them, the model requires training data for adversarial training or explicit regularization-based techniques. However, privacy has become an important concern, restricting access to only trained models but not the training data (e.g. biometric data). Also, data curation is expensive and companies may have proprietary rights over it. To handle such situations, we propose a completely novel problem of 'test-time adversarial defense in absence of training data and even their statistics'. We solve it in two stages: a) detection and b) correction of adversarial samples. Our adversarial sample detection framework is initially trained on arbitrary data and is subsequently adapted to the unlabelled test data through unsupervised domain adaptation. We further correct the predictions on detected adversarial samples by transforming them in Fourier domain and obtaining their low frequency component at our proposed suitable radius for model prediction. We demonstrate the efficacy of our proposed technique via extensive experiments against several adversarial attacks and for different model architectures and datasets. For a non-robust Resnet-18 model pre-trained on CIFAR-10, our detection method correctly identifies 91.42% adversaries. Also, we significantly improve the adversarial accuracy from 0% to 37.37% with a minimal drop of 0.02% in clean accuracy on state-of-the-art 'Auto Attack' without having to retrain the model.
Recurrent Auto-Encoder With Multi-Resolution Ensemble and Predictive Coding for Multivariate Time-Series Anomaly Detection
Feb 21, 2022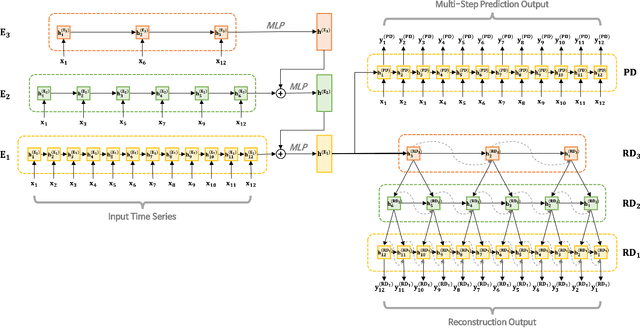

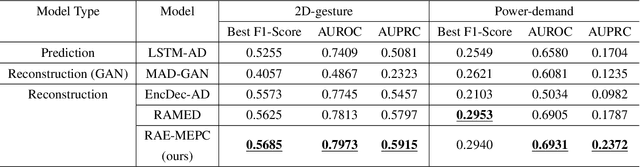
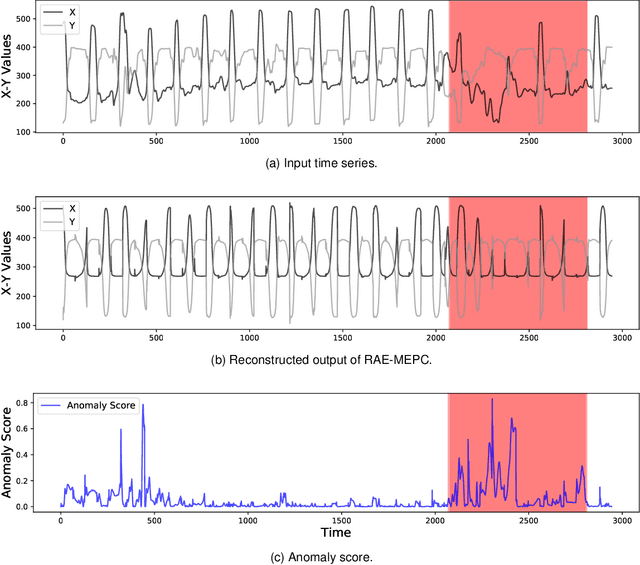
As large-scale time-series data can easily be found in real-world applications, multivariate time-series anomaly detection has played an essential role in diverse industries. It enables productivity improvement and maintenance cost reduction by preventing malfunctions and detecting anomalies based on time-series data. However, multivariate time-series anomaly detection is challenging because real-world time-series data exhibit complex temporal dependencies. For this task, it is crucial to learn a rich representation that effectively contains the nonlinear temporal dynamics of normal behavior. In this study, we propose an unsupervised multivariate time-series anomaly detection model named RAE-MEPC which learns informative normal representations based on multi-resolution ensemble and predictive coding. We introduce multi-resolution ensemble encoding to capture the multi-scale dependency from the input time series. The encoder hierarchically aggregates the temporal features extracted from the sub-encoders with different encoding lengths. From these encoded features, the reconstruction decoder reconstructs the input time series based on multi-resolution ensemble decoding where lower-resolution information helps to decode sub-decoders with higher-resolution outputs. Predictive coding is further introduced to encourage the model to learn the temporal dependencies of the time series. Experiments on real-world benchmark datasets show that the proposed model outperforms the benchmark models for multivariate time-series anomaly detection.
Unsafe's Betrayal: Abusing Unsafe Rust in Binary Reverse Engineering toward Finding Memory-safety Bugs via Machine Learning
Oct 31, 2022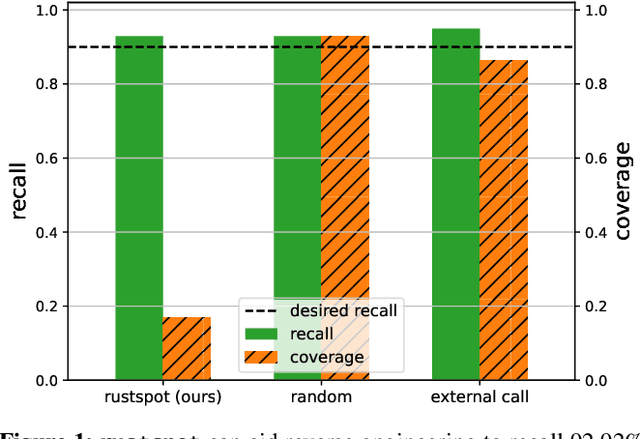
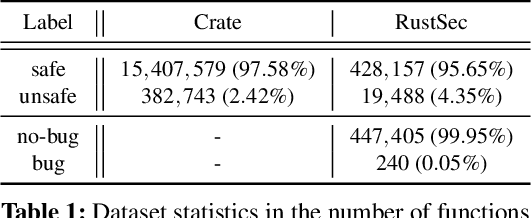
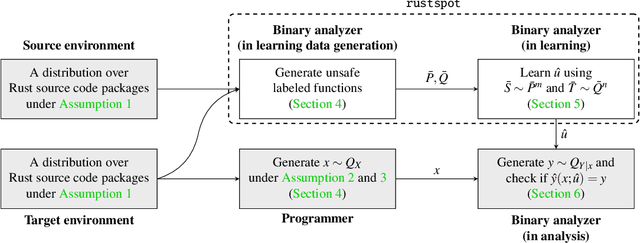
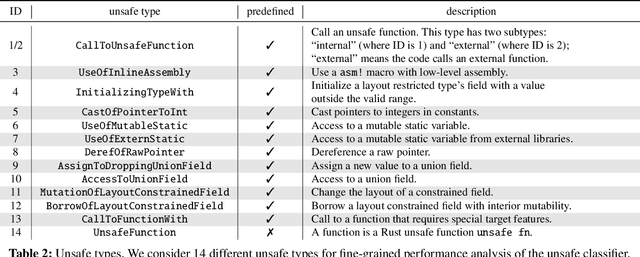
Memory-safety bugs introduce critical software-security issues. Rust provides memory-safe mechanisms to avoid memory-safety bugs in programming, while still allowing unsafe escape hatches via unsafe code. However, the unsafe code that enhances the usability of Rust provides clear spots for finding memory-safety bugs in Rust source code. In this paper, we claim that these unsafe spots can still be identifiable in Rust binary code via machine learning and be leveraged for finding memory-safety bugs. To support our claim, we propose the tool textttrustspot, that enables reverse engineering to learn an unsafe classifier that proposes a list of functions in Rust binaries for downstream analysis. We empirically show that the function proposals by textttrustspot can recall $92.92\%$ of memory-safety bugs, while it covers only $16.79\%$ of the entire binary code. As an application, we demonstrate that the function proposals are used in targeted fuzzing on Rust packages, which contribute to reducing the fuzzing time compared to non-targeted fuzzing.
Transformers For Recognition In Overhead Imagery: A Reality Check
Oct 31, 2022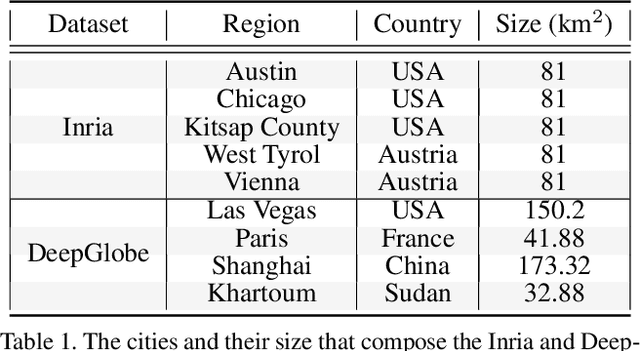
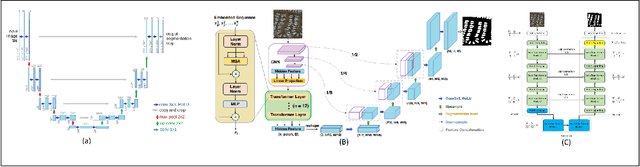

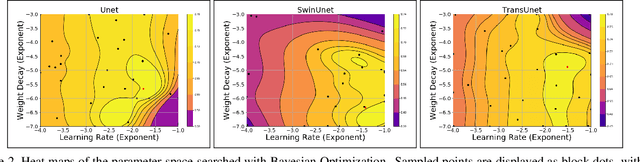
There is evidence that transformers offer state-of-the-art recognition performance on tasks involving overhead imagery (e.g., satellite imagery). However, it is difficult to make unbiased empirical comparisons between competing deep learning models, making it unclear whether, and to what extent, transformer-based models are beneficial. In this paper we systematically compare the impact of adding transformer structures into state-of-the-art segmentation models for overhead imagery. Each model is given a similar budget of free parameters, and their hyperparameters are optimized using Bayesian Optimization with a fixed quantity of data and computation time. We conduct our experiments with a large and diverse dataset comprising two large public benchmarks: Inria and DeepGlobe. We perform additional ablation studies to explore the impact of specific transformer-based modeling choices. Our results suggest that transformers provide consistent, but modest, performance improvements. We only observe this advantage however in hybrid models that combine convolutional and transformer-based structures, while fully transformer-based models achieve relatively poor performance.
Scoliosis Detection using Deep Neural Network
Oct 31, 2022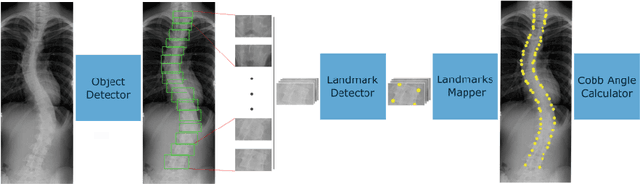
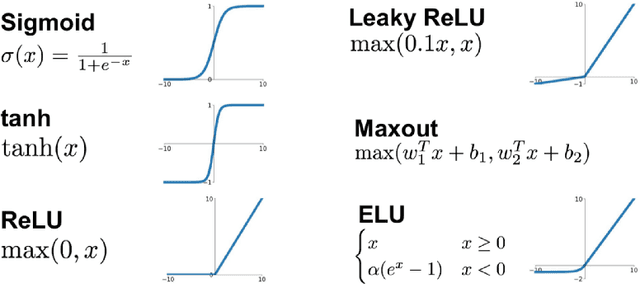
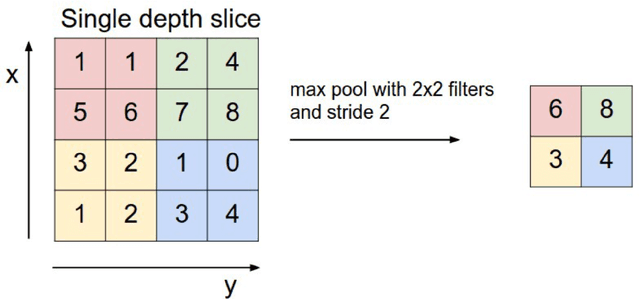
Scoliosis is a sideways curvature of the spine that most often is diagnosed among young teenagers. It dramatically affects the quality of life, which can cause complications from heart and lung injuries in severe cases. The current gold standard to detect and estimate scoliosis is to manually examine the spinal anterior-posterior X-ray images. This process is time-consuming, observer-dependent, and has high inter-rater variability. Consequently, there has been increasing interest in automatic scoliosis estimation from spinal X-ray images, and the development of deep learning has shown amazing achievements in automatic spinal curvature estimation. The main target of this thesis is to review the fundamental concepts of deep learning, analyze how deep learning is applied to detect spinal curvature, explore the practical deep learning-based models that have been employed. It aims to improve the accuracy of scoliosis detection and implement the most successful one for automated Cobb angle prediction. Keywords: Scoliosis Detection, Spinal Curvature Estimation, Deep Learning. i
Improving Temporal Generalization of Pre-trained Language Models with Lexical Semantic Change
Oct 31, 2022
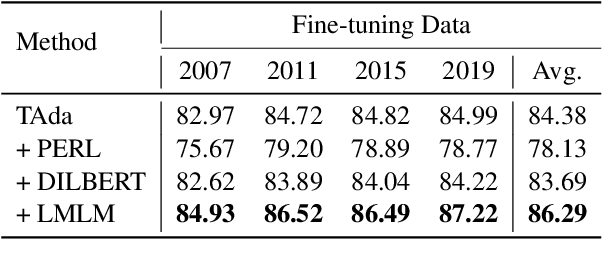
Recent research has revealed that neural language models at scale suffer from poor temporal generalization capability, i.e., the language model pre-trained on static data from past years performs worse over time on emerging data. Existing methods mainly perform continual training to mitigate such a misalignment. While effective to some extent but is far from being addressed on both the language modeling and downstream tasks. In this paper, we empirically observe that temporal generalization is closely affiliated with lexical semantic change, which is one of the essential phenomena of natural languages. Based on this observation, we propose a simple yet effective lexical-level masking strategy to post-train a converged language model. Experiments on two pre-trained language models, two different classification tasks, and four benchmark datasets demonstrate the effectiveness of our proposed method over existing temporal adaptation methods, i.e., continual training with new data. Our code is available at \url{https://github.com/zhaochen0110/LMLM}.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022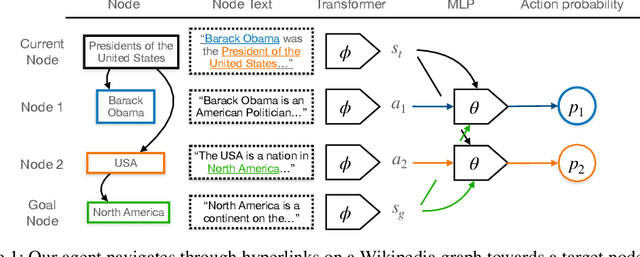

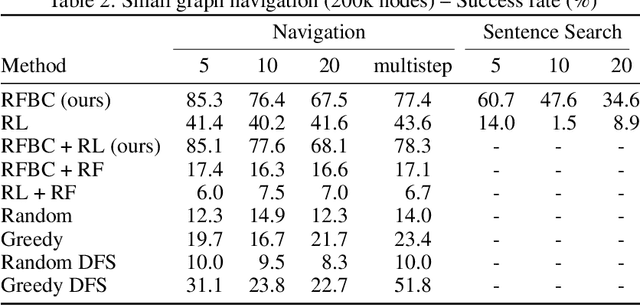
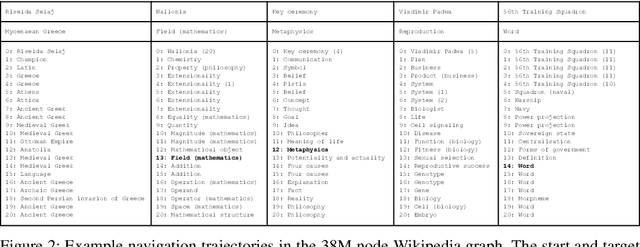
A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
Accelerating Carbon Capture and Storage Modeling using Fourier Neural Operators
Oct 31, 2022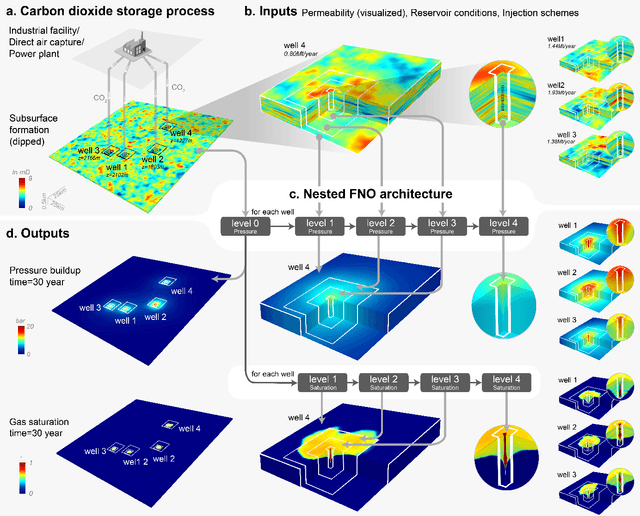
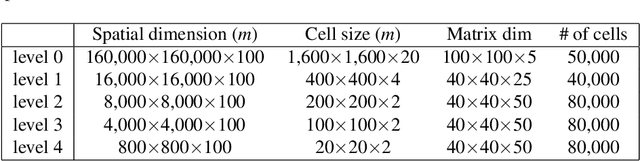
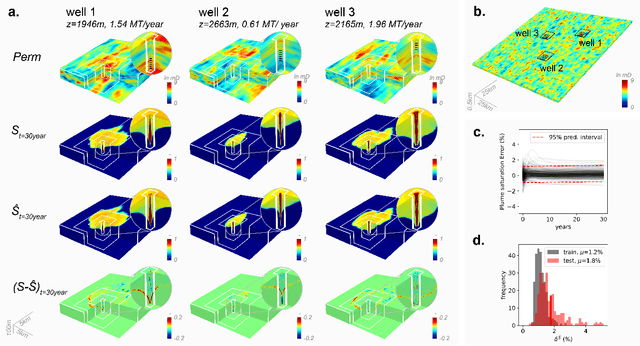
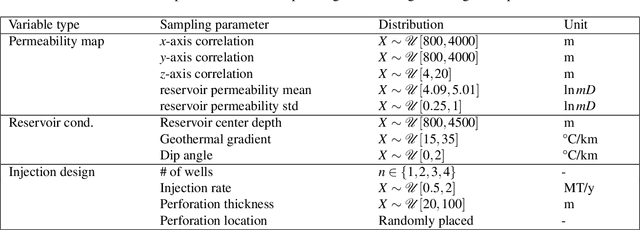
Carbon capture and storage (CCS) is an important strategy for reducing carbon dioxide emissions and mitigating climate change. We consider the storage aspect of CCS, which involves injecting carbon dioxide into underground reservoirs. This requires accurate and high-resolution predictions of carbon dioxide plume migration and reservoir pressure buildup. However, such modeling is challenging at scale due to the high computational costs of existing numerical methods. We introduce a novel machine learning approach for four-dimensional spatial-temporal modeling, which speeds up predictions nearly 700,000 times compared to existing methods. It provides highly accurate predictions under diverse reservoir conditions, geological heterogeneity, and injection schemes. Our framework, Nested Fourier Neural Operator (FNO), learns the solution operator for the family of partial differential equations governing the carbon dioxide-water multiphase flow. It uses a hierarchy of FNO models to produce outputs at different refinement levels. Thus, our approach enables unprecedented real-time high-resolution modeling for carbon dioxide storage.
Diffusion models for missing value imputation in tabular data
Oct 31, 2022
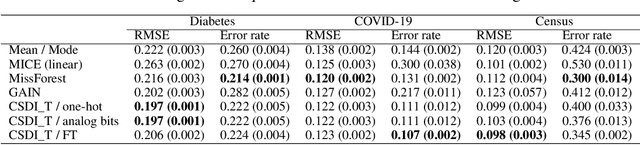
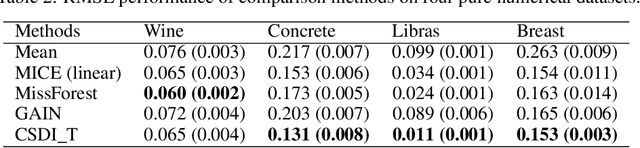
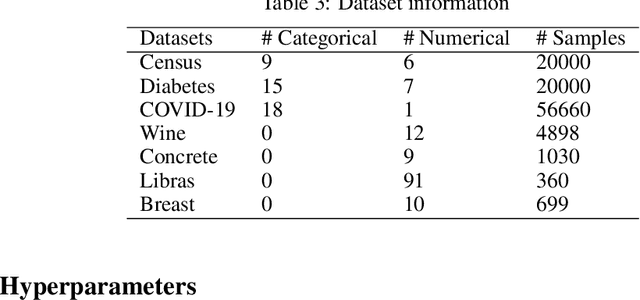
Missing value imputation in machine learning is the task of estimating the missing values in the dataset accurately using available information. In this task, several deep generative modeling methods have been proposed and demonstrated their usefulness, e.g., generative adversarial imputation networks. Recently, diffusion models have gained popularity because of their effectiveness in the generative modeling task in images, texts, audio, etc. To our knowledge, less attention has been paid to the investigation of the effectiveness of diffusion models for missing value imputation in tabular data. Based on recent development of diffusion models for time-series data imputation, we propose a diffusion model approach called "Conditional Score-based Diffusion Models for Tabular data" (CSDI_T). To effectively handle categorical variables and numerical variables simultaneously, we investigate three techniques: one-hot encoding, analog bits encoding, and feature tokenization. Experimental results on benchmark datasets demonstrated the effectiveness of CSDI_T compared with well-known existing methods, and also emphasized the importance of the categorical embedding techniques.