 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning for Scientific Computing in the Wild
Jan 31, 2023



Deep learning (DL) is revolutionizing the scientific computing community. To reduce the data gap caused by usually expensive simulations or experimentation, active learning has been identified as a promising solution for the scientific computing community. However, the deep active learning (DAL) literature is currently dominated by image classification problems and pool-based methods, which are not directly transferrable to scientific computing problems, dominated by regression problems with no pre-defined 'pool' of unlabeled data. Here for the first time, we investigate the robustness of DAL methods for scientific computing problems using ten state-of-the-art DAL methods and eight benchmark problems. We show that, to our surprise, the majority of the DAL methods are not robust even compared to random sampling when the ideal pool size is unknown. We further analyze the effectiveness and robustness of DAL methods and suggest that diversity is necessary for a robust DAL for scientific computing problems.
Transformers For Recognition In Overhead Imagery: A Reality Check
Oct 31, 2022



There is evidence that transformers offer state-of-the-art recognition performance on tasks involving overhead imagery (e.g., satellite imagery). However, it is difficult to make unbiased empirical comparisons between competing deep learning models, making it unclear whether, and to what extent, transformer-based models are beneficial. In this paper we systematically compare the impact of adding transformer structures into state-of-the-art segmentation models for overhead imagery. Each model is given a similar budget of free parameters, and their hyperparameters are optimized using Bayesian Optimization with a fixed quantity of data and computation time. We conduct our experiments with a large and diverse dataset comprising two large public benchmarks: Inria and DeepGlobe. We perform additional ablation studies to explore the impact of specific transformer-based modeling choices. Our results suggest that transformers provide consistent, but modest, performance improvements. We only observe this advantage however in hybrid models that combine convolutional and transformer-based structures, while fully transformer-based models achieve relatively poor performance.
Viewpoint Adaptation for Rigid Object Detection
Feb 24, 2017
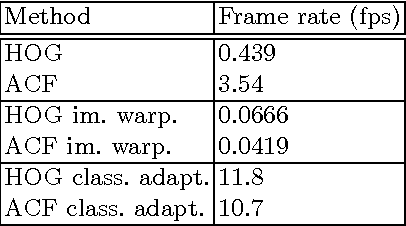
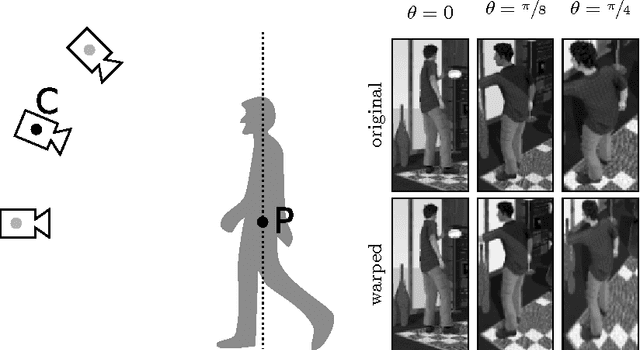
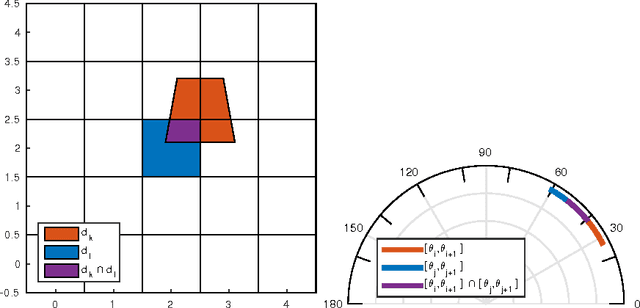
An object detector performs suboptimally when applied to image data taken from a viewpoint different from the one with which it was trained. In this paper, we present a viewpoint adaptation algorithm that allows a trained single-view object detector to be adapted to a new, distinct viewpoint. We first illustrate how a feature space transformation can be inferred from a known homography between the source and target viewpoints. Second, we show that a variety of trained classifiers can be modified to behave as if that transformation were applied to each testing instance. The proposed algorithm is evaluated on a person detection task using images from the PETS 2007 and CAVIAR datasets, as well as from a new synthetic multi-view person detection dataset. It yields substantial performance improvements when adapting single-view person detectors to new viewpoints, and simultaneously reduces computational complexity. This work has the potential to improve detection performance for cameras viewing objects from arbitrary viewpoints, while simplifying data collection and feature extraction.
An Open Source Pattern Recognition Toolbox for MATLAB
Jun 21, 2014
Pattern recognition and machine learning are becoming integral parts of algorithms in a wide range of applications. Different algorithms and approaches for machine learning include different tradeoffs between performance and computation, so during algorithm development it is often necessary to explore a variety of different approaches to a given task. A toolbox with a unified framework across multiple pattern recognition techniques enables algorithm developers the ability to rapidly evaluate different choices prior to deployment. MATLAB is a widely used environment for algorithm development and prototyping, and although several MATLAB toolboxes for pattern recognition are currently available these are either incomplete, expensive, or restrictively licensed. In this work we describe a MATLAB toolbox for pattern recognition and machine learning known as the PRT (Pattern Recognition Toolbox), licensed under the permissive MIT license. The PRT includes many popular techniques for data preprocessing, supervised learning, clustering, regression and feature selection, as well as a methodology for combining these components using a simple, uniform syntax. The resulting algorithms can be evaluated using cross-validation and a variety of scoring metrics to ensure robust performance when the algorithm is deployed. This paper presents an overview of the PRT as well as an example of usage on Fisher's Iris dataset.