 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Deep Reinforcement Learning with Predictive Processing Proximal Policy Optimization
Nov 11, 2022
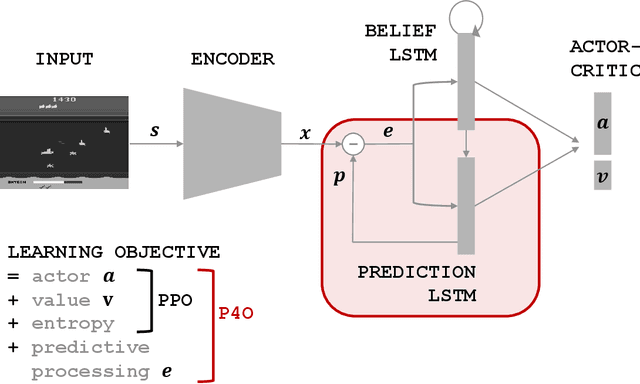

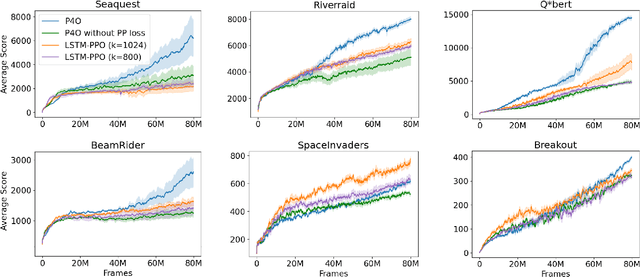
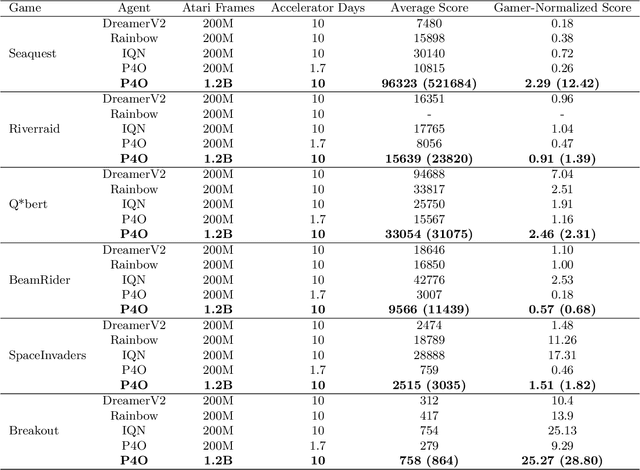
Advances in reinforcement learning (RL) often rely on massive compute resources and remain notoriously sample inefficient. In contrast, the human brain is able to efficiently learn effective control strategies using limited resources. This raises the question whether insights from neuroscience can be used to improve current RL methods. Predictive processing is a popular theoretical framework which maintains that the human brain is actively seeking to minimize surprise. We show that recurrent neural networks which predict their own sensory states can be leveraged to minimise surprise, yielding substantial gains in cumulative reward. Specifically, we present the Predictive Processing Proximal Policy Optimization (P4O) agent; an actor-critic reinforcement learning agent that applies predictive processing to a recurrent variant of the PPO algorithm by integrating a world model in its hidden state. P4O significantly outperforms a baseline recurrent variant of the PPO algorithm on multiple Atari games using a single GPU. It also outperforms other state-of-the-art agents given the same wall-clock time and exceeds human gamer performance on multiple games including Seaquest, which is a particularly challenging environment in the Atari domain. Altogether, our work underscores how insights from the field of neuroscience may support the development of more capable and efficient artificial agents.
Continent-wide Efficient and Fair Downlink Resource Allocation in LEO Satellite Constellations
Nov 11, 2022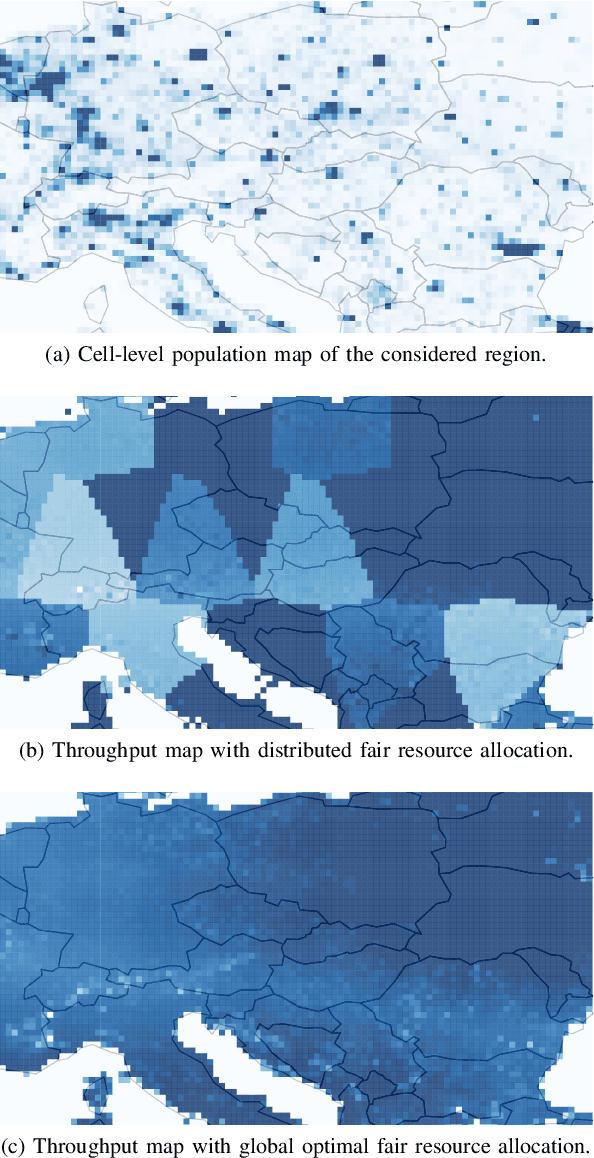
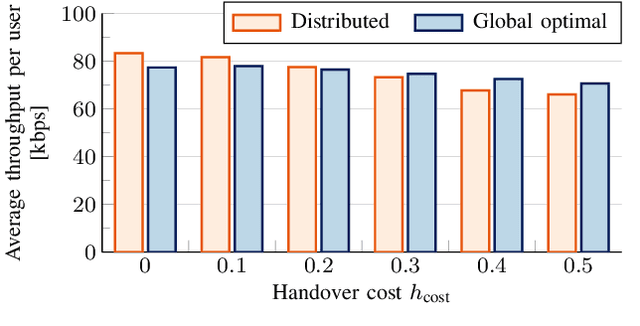
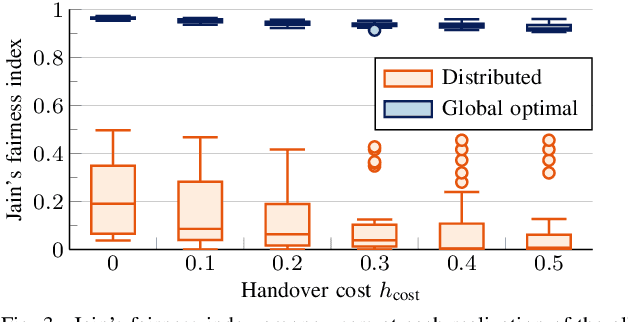
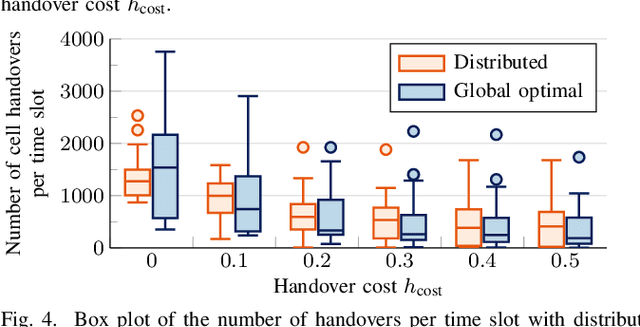
The integration of Low Earth Orbit (LEO) satellite constellations into 5G and Beyond is essential to achieve efficient global connectivity. As LEO satellites are a global infrastructure with predictable dynamics, a pre-planned fair and load-balanced allocation of the radio resources to provide efficient downlink connectivity over large areas is an achievable goal. In this paper, we propose a distributed and a global optimal algorithm for satellite-to-cell resource allocation with multiple beams. These algorithms aim to achieve a fair allocation of time-frequency resources and beams to the cells based on the number of users in connected mode (i.e., registered). Our analyses focus on evaluating the trade-offs between average per-user throughput, fairness, number of cell handovers, and computational complexity in a downlink scenario with fixed cells, where the number of users is extracted from a population map. Our results show that both algorithms achieve a similar average per-user throughput. However, the global optimal algorithm achieves a fairness index over 0.9 in all cases, which is more than twice that of the distributed algorithm. Furthermore, by correctly setting the handover cost parameter, the number of handovers can be effectively reduced by more than 70% with respect to the case where the handover cost is not considered.
A Generative Approach for Production-Aware Industrial Network Traffic Modeling
Nov 11, 2022
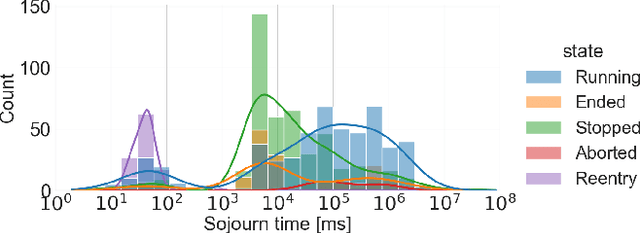
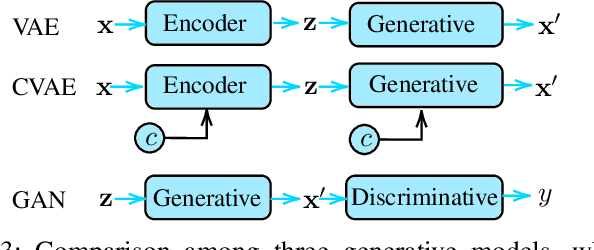
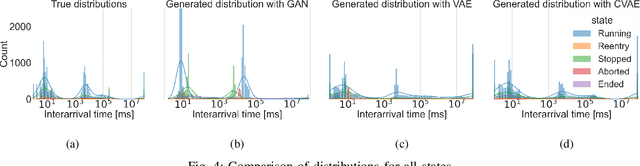
The new wave of digitization induced by Industry 4.0 calls for ubiquitous and reliable connectivity to perform and automate industrial operations. 5G networks can afford the extreme requirements of heterogeneous vertical applications, but the lack of real data and realistic traffic statistics poses many challenges for the optimization and configuration of the network for industrial environments. In this paper, we investigate the network traffic data generated from a laser cutting machine deployed in a Trumpf factory in Germany. We analyze the traffic statistics, capture the dependencies between the internal states of the machine, and model the network traffic as a production state dependent stochastic process. The two-step model is proposed as follows: first, we model the production process as a multi-state semi-Markov process, then we learn the conditional distributions of the production state dependent packet interarrival time and packet size with generative models. We compare the performance of various generative models including variational autoencoder (VAE), conditional variational autoencoder (CVAE), and generative adversarial network (GAN). The numerical results show a good approximation of the traffic arrival statistics depending on the production state. Among all generative models, CVAE provides in general the best performance in terms of the smallest Kullback-Leibler divergence.
Multitask Learning for Improved Late Mechanical Activation Detection of Heart from Cine DENSE MRI
Nov 11, 2022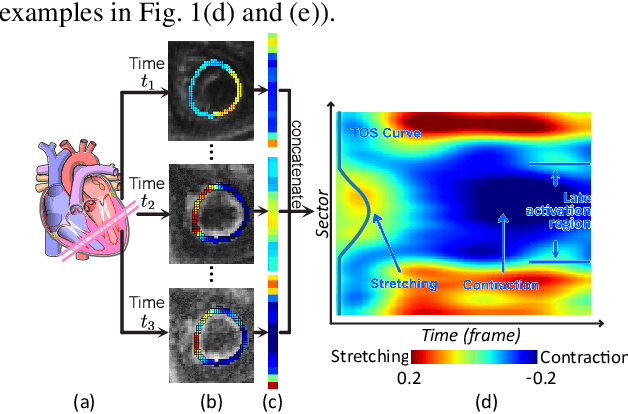
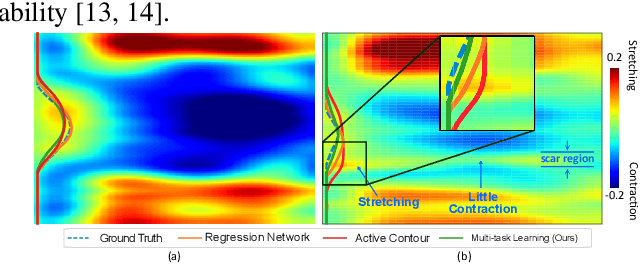
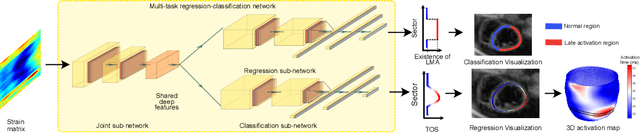
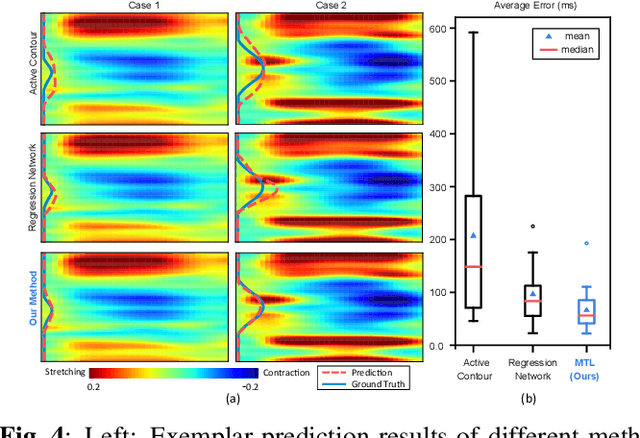
The selection of an optimal pacing site, which is ideally scar-free and late activated, is critical to the response of cardiac resynchronization therapy (CRT). Despite the success of current approaches formulating the detection of such late mechanical activation (LMA) regions as a problem of activation time regression, their accuracy remains unsatisfactory, particularly in cases where myocardial scar exists. To address this issue, this paper introduces a multi-task deep learning framework that simultaneously estimates LMA amount and classify the scar-free LMA regions based on cine displacement encoding with stimulated echoes (DENSE) magnetic resonance imaging (MRI). With a newly introduced auxiliary LMA region classification sub-network, our proposed model shows more robustness to the complex pattern cause by myocardial scar, significantly eliminates their negative effects in LMA detection, and in turn improves the performance of scar classification. To evaluate the effectiveness of our method, we tests our model on real cardiac MR images and compare the predicted LMA with the state-of-the-art approaches. It shows that our approach achieves substantially increased accuracy. In addition, we employ the gradient-weighted class activation mapping (Grad-CAM) to visualize the feature maps learned by all methods. Experimental results suggest that our proposed model better recognizes the LMA region pattern.
Runtime data center temperature prediction using Grammatical Evolution techniques
Nov 11, 2022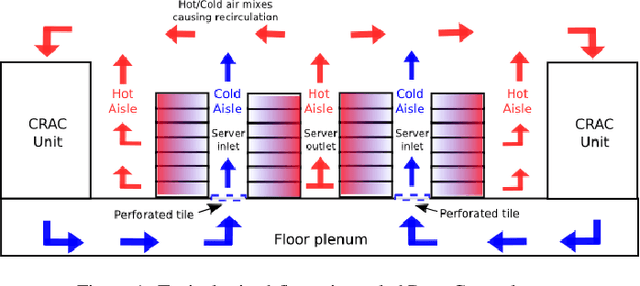

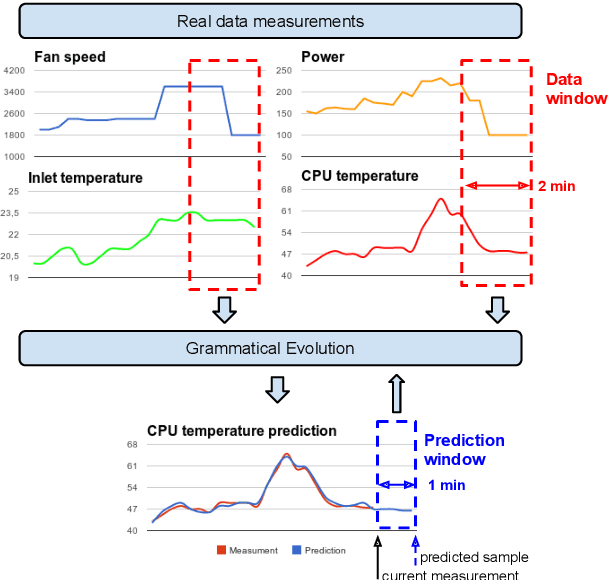
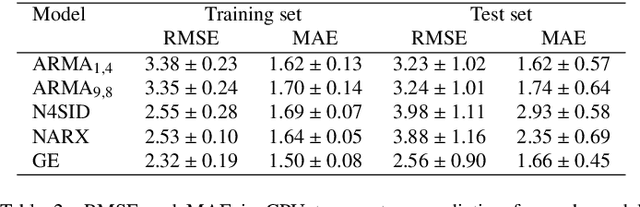
Data Centers are huge power consumers, both because of the energy required for computation and the cooling needed to keep servers below thermal redlining. The most common technique to minimize cooling costs is increasing data room temperature. However, to avoid reliability issues, and to enhance energy efficiency, there is a need to predict the temperature attained by servers under variable cooling setups. Due to the complex thermal dynamics of data rooms, accurate runtime data center temperature prediction has remained as an important challenge. By using Gramatical Evolution techniques, this paper presents a methodology for the generation of temperature models for data centers and the runtime prediction of CPU and inlet temperature under variable cooling setups. As opposed to time costly Computational Fluid Dynamics techniques, our models do not need specific knowledge about the problem, can be used in arbitrary data centers, re-trained if conditions change and have negligible overhead during runtime prediction. Our models have been trained and tested by using traces from real Data Center scenarios. Our results show how we can fully predict the temperature of the servers in a data rooms, with prediction errors below 2 C and 0.5 C in CPU and server inlet temperature respectively.
Optimal Stopping with Gaussian Processes
Sep 22, 2022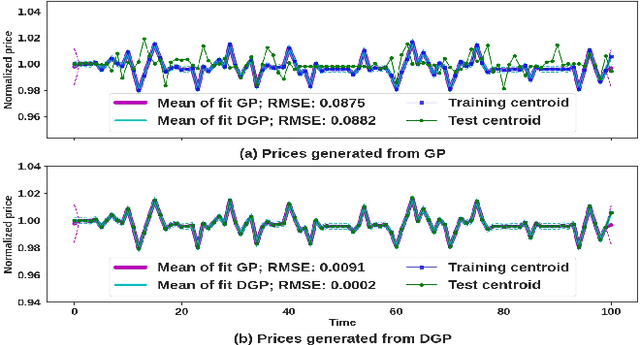

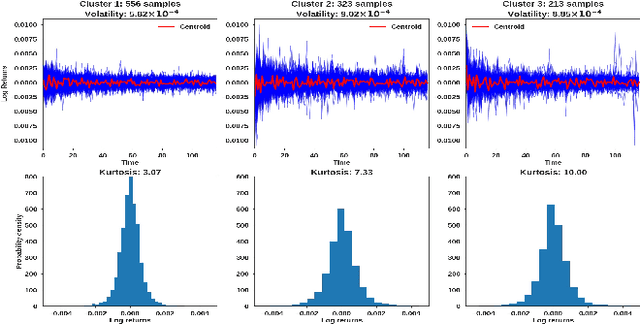
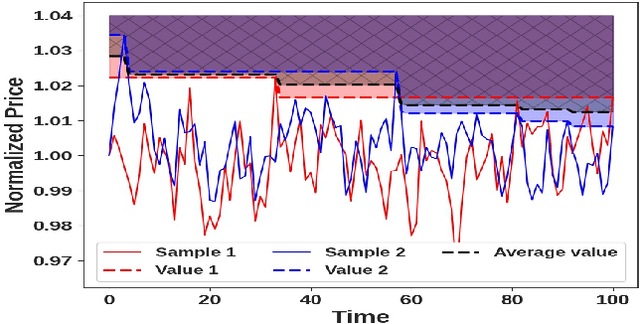
We propose a novel group of Gaussian Process based algorithms for fast approximate optimal stopping of time series with specific applications to financial markets. We show that structural properties commonly exhibited by financial time series (e.g., the tendency to mean-revert) allow the use of Gaussian and Deep Gaussian Process models that further enable us to analytically evaluate optimal stopping value functions and policies. We additionally quantify uncertainty in the value function by propagating the price model through the optimal stopping analysis. We compare and contrast our proposed methods against a sampling-based method, as well as a deep learning based benchmark that is currently considered the state-of-the-art in the literature. We show that our family of algorithms outperforms benchmarks on three historical time series datasets that include intra-day and end-of-day equity asset prices as well as the daily US treasury yield curve rates.
Time-Aware Neighbor Sampling for Temporal Graph Networks
Dec 18, 2021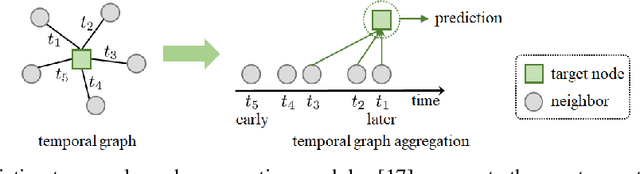


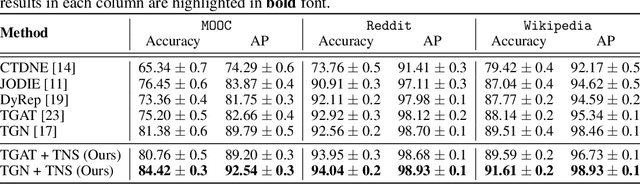
We present a new neighbor sampling method on temporal graphs. In a temporal graph, predicting different nodes' time-varying properties can require the receptive neighborhood of various temporal scales. In this work, we propose the TNS (Time-aware Neighbor Sampling) method: TNS learns from temporal information to provide an adaptive receptive neighborhood for every node at any time. Learning how to sample neighbors is non-trivial, since the neighbor indices in time order are discrete and not differentiable. To address this challenge, we transform neighbor indices from discrete values to continuous ones by interpolating the neighbors' messages. TNS can be flexibly incorporated into popular temporal graph networks to improve their effectiveness without increasing their time complexity. TNS can be trained in an end-to-end manner. It needs no extra supervision and is automatically and implicitly guided to sample the neighbors that are most beneficial for prediction. Empirical results on multiple standard datasets show that TNS yields significant gains on edge prediction and node classification.
Configuration Tracking Control of a Multi-Segment Soft Robotic Arm Using a Cosserat Rod Model
Oct 01, 2022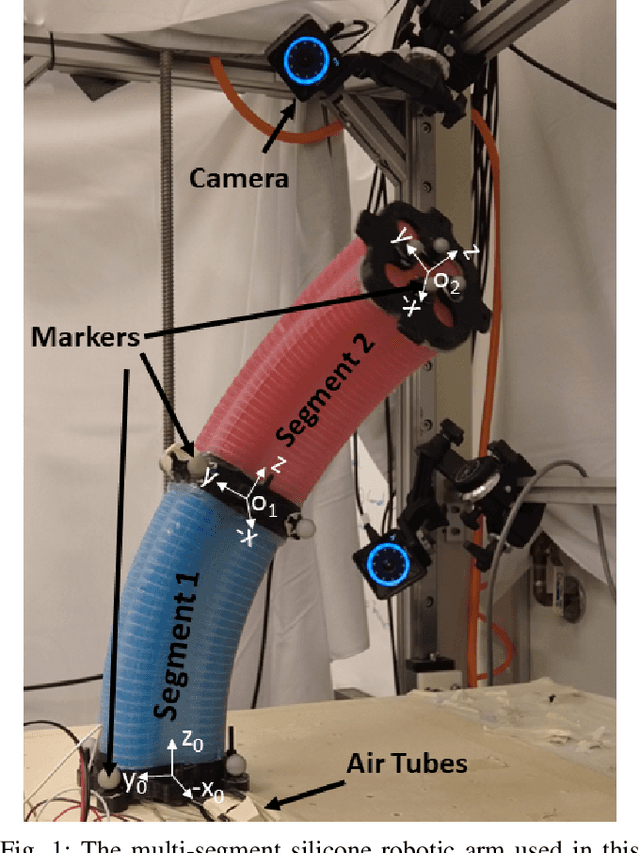
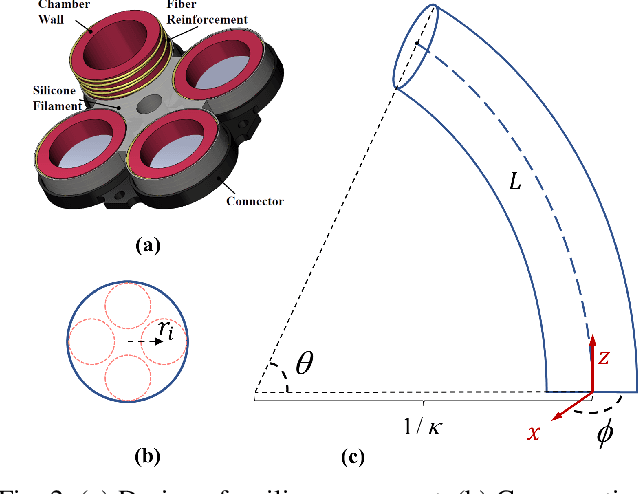
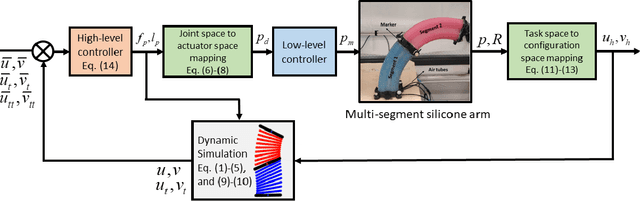
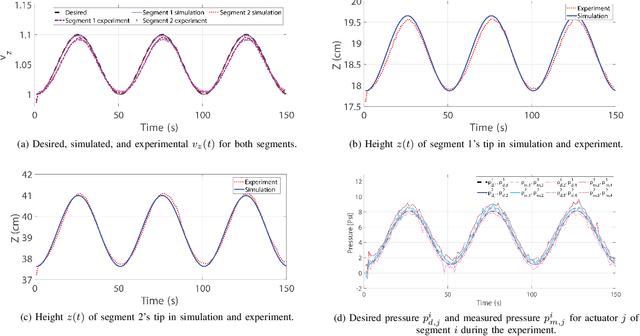
Controlling soft continuum robotic arms is challenging due to their hyper-redundancy and dexterity. In this paper we demonstrate, for the first time, closed-loop control of the configuration space variables of a soft robotic arm, composed of independently controllable segments, using a Cosserat rod model of the robot and the distributed sensing and actuation capabilities of the segments. Our controller solves the inverse dynamic problem by simulating the Cosserat rod model in MATLAB using a computationally efficient numerical solution scheme, and it applies the computed control output to the actual robot in real time. The position and orientation of the tip of each segment are measured in real time, while the remaining unknown variables that are needed to solve the inverse dynamics are estimated simultaneously in the simulation. We implement the controller on a multi-segment silicone robotic arm with pneumatic actuation, using a motion capture system to measure the segments' positions and orientations. The controller is used to reshape the arm into configurations that are achieved through different combinations of bending and extension deformations in 3D space. The resulting tracking performance indicates the effectiveness of the controller and the accuracy of the simulated Cosserat rod model that is used to estimate the unmeasured variables.
A Survey on the Integration of Machine Learning with Sampling-based Motion Planning
Nov 15, 2022
Sampling-based methods are widely adopted solutions for robot motion planning. The methods are straightforward to implement, effective in practice for many robotic systems. It is often possible to prove that they have desirable properties, such as probabilistic completeness and asymptotic optimality. Nevertheless, they still face challenges as the complexity of the underlying planning problem increases, especially under tight computation time constraints, which impact the quality of returned solutions or given inaccurate models. This has motivated machine learning to improve the computational efficiency and applicability of Sampling-Based Motion Planners (SBMPs). This survey reviews such integrative efforts and aims to provide a classification of the alternative directions that have been explored in the literature. It first discusses how learning has been used to enhance key components of SBMPs, such as node sampling, collision detection, distance or nearest neighbor computation, local planning, and termination conditions. Then, it highlights planners that use learning to adaptively select between different implementations of such primitives in response to the underlying problem's features. It also covers emerging methods, which build complete machine learning pipelines that reflect the traditional structure of SBMPs. It also discusses how machine learning has been used to provide data-driven models of robots, which can then be used by a SBMP. Finally, it provides a comparative discussion of the advantages and disadvantages of the approaches covered, and insights on possible future directions of research. An online version of this survey can be found at: https://prx-kinodynamic.github.io/
* First two authors contributed equally
ParticleGrid: Enabling Deep Learning using 3D Representation of Materials
Nov 15, 2022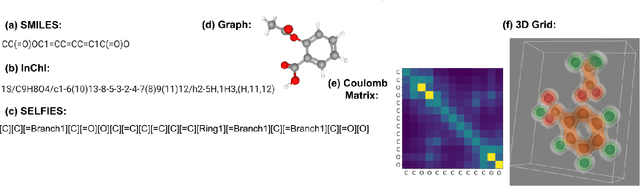
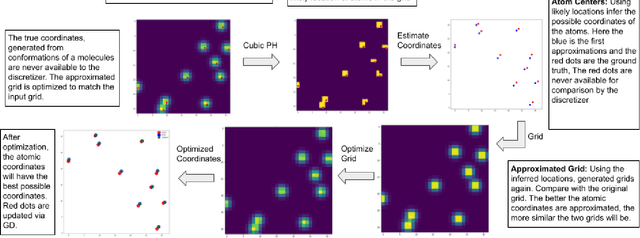
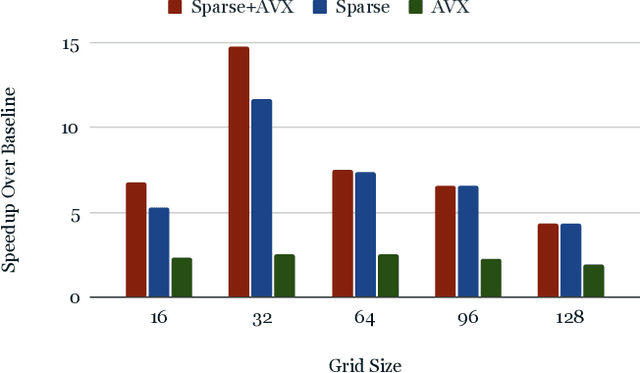
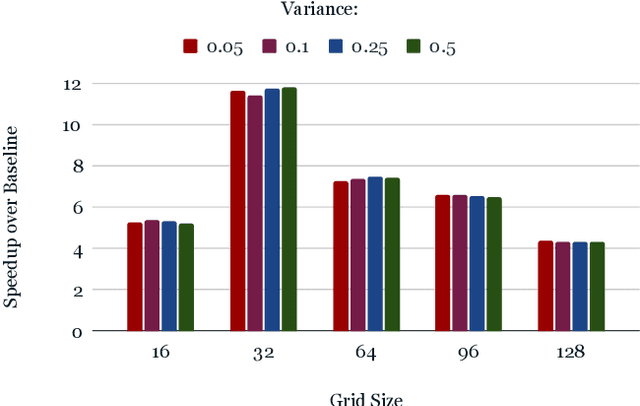
From AlexNet to Inception, autoencoders to diffusion models, the development of novel and powerful deep learning models and learning algorithms has proceeded at breakneck speeds. In part, we believe that rapid iteration of model architecture and learning techniques by a large community of researchers over a common representation of the underlying entities has resulted in transferable deep learning knowledge. As a result, model scale, accuracy, fidelity, and compute performance have dramatically increased in computer vision and natural language processing. On the other hand, the lack of a common representation for chemical structure has hampered similar progress. To enable transferable deep learning, we identify the need for a robust 3-dimensional representation of materials such as molecules and crystals. The goal is to enable both materials property prediction and materials generation with 3D structures. While computationally costly, such representations can model a large set of chemical structures. We propose $\textit{ParticleGrid}$, a SIMD-optimized library for 3D structures, that is designed for deep learning applications and to seamlessly integrate with deep learning frameworks. Our highly optimized grid generation allows for generating grids on the fly on the CPU, reducing storage and GPU compute and memory requirements. We show the efficacy of 3D grids generated via $\textit{ParticleGrid}$ and accurately predict molecular energy properties using a 3D convolutional neural network. Our model is able to get 0.006 mean square error and nearly match the values calculated using computationally costly density functional theory at a fraction of the time.