 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Dynamic Rebalancing in Dockless Bike-Sharing Systems via Deep Reinforcement Learning
May 14, 2026This paper proposes a fully dynamic Deep Reinforcement Learning (DRL) method for rebalancing dockless bike-sharing systems, overcoming the limitations of periodic, system-wide interventions. We model the service through a graph-based simulator and cast rebalancing as a Markov decision process. A DRL agent routes a single truck in real time, executing localized pick-up, drop-off, and charging actions guided by spatiotemporal criticality scores. Experiments on real-world data show significant reductions in availability failures with a minimal fleet size, while limiting spatial inequality and mobility deserts. Our approach demonstrates the value of learning-based rebalancing for efficient and reliable shared micromobility.
GO-GenZip: Goal-Oriented Generative Sampling and Hybrid Compression
Mar 20, 2026Current network data telemetry pipelines consist of massive streams of fine-grained Key Performance Indicators (KPIs) from multiple distributed sources towards central aggregators, making data storage, transmission, and real-time analysis increasingly unsustainable. This work presents a generative AI (GenAI)-driven sampling and hybrid compression framework that redesigns network telemetry from a goal-oriented perspective. Unlike conventional approaches that passively compress fully observed data, our approach jointly optimizes what to observe and how to encode it, guided by the relevance of information to downstream tasks. The framework integrates adaptive sampling policies, using adaptive masking techniques, with generative modeling to identify patterns and preserve critical features across temporal and spatial dimensions. The selectively acquired data are further processed through a hybrid compression scheme that combines traditional lossless coding with GenAI-driven, lossy compression. Experimental results on real network datasets demonstrate over 50$\%$ reductions in sampling and data transfer costs, while maintaining comparable reconstruction accuracy and goal-oriented analytical fidelity in downstream tasks.
Goal-Oriented Access Optimization for ISAC-Enabled Digital Twins
Mar 02, 2026The digital twins (DTs) of physical systems and environments enable real-time remote tracking, control, and learning, but require low-latency transmission of updates and sensory data to maintain alignment with their physical counterparts. In this context, augmenting sensory data with the network's own integrated sensing and communication (ISAC)capabilities can expand the DT's awareness of the environment by allowing it to precisely non-radar locate measurements from mobile nodes. However, this integration increases the complexity of the communication system, and can only be supported through intelligent resource allocation and access optimization. In this work, we propose a two-step goal-oriented approach to solve this problem: we design a push-based random access in which sensors with a high Value of Information (VoI) inform the network of their access requirements, followed by a pull-based scheduled transmission of the actual sensory data. This design allows to combine the ISAC and reliable transmission requirements and maximize the VoI of the information delivered to the DT, significantly outperforming existing schemes.
Robust Reinforcement Learning over Wireless Networks with Homomorphic State Representations
Aug 11, 2025In this work, we address the problem of training Reinforcement Learning (RL) agents over communication networks. The RL paradigm requires the agent to instantaneously perceive the state evolution to infer the effects of its actions on the environment. This is impossible if the agent receives state updates over lossy or delayed wireless systems and thus operates with partial and intermittent information. In recent years, numerous frameworks have been proposed to manage RL with imperfect feedback; however, they often offer specific solutions with a substantial computational burden. To address these limits, we propose a novel architecture, named Homomorphic Robust Remote Reinforcement Learning (HR3L), that enables the training of remote RL agents exchanging observations across a non-ideal wireless channel. HR3L considers two units: the transmitter, which encodes meaningful representations of the environment, and the receiver, which decodes these messages and performs actions to maximize a reward signal. Importantly, HR3L does not require the exchange of gradient information across the wireless channel, allowing for quicker training and a lower communication overhead than state-of-the-art solutions. Experimental results demonstrate that HR3L significantly outperforms baseline methods in terms of sample efficiency and adapts to different communication scenarios, including packet losses, delayed transmissions, and capacity limitations.
To Train or Not to Train: Balancing Efficiency and Training Cost in Deep Reinforcement Learning for Mobile Edge Computing
Nov 11, 2024



Artificial Intelligence (AI) is a key component of 6G networks, as it enables communication and computing services to adapt to end users' requirements and demand patterns. The management of Mobile Edge Computing (MEC) is a meaningful example of AI application: computational resources available at the network edge need to be carefully allocated to users, whose jobs may have different priorities and latency requirements. The research community has developed several AI algorithms to perform this resource allocation, but it has neglected a key aspect: learning is itself a computationally demanding task, and considering free training results in idealized conditions and performance in simulations. In this work, we consider a more realistic case in which the cost of learning is specifically accounted for, presenting a new algorithm to dynamically select when to train a Deep Reinforcement Learning (DRL) agent that allocates resources. Our method is highly general, as it can be directly applied to any scenario involving a training overhead, and it can approach the same performance as an ideal learning agent even under realistic training conditions.
Content-based Wake-up for Energy-efficient and Timely Top-k IoT Sensing Data Retrieval
Oct 08, 2024



Energy efficiency and information freshness are key requirements for sensor nodes serving Industrial Internet of Things (IIoT) applications, where a sink node collects informative and fresh data before a deadline, e.g., to control an external actuator. Content-based wake-up (CoWu) activates a subset of nodes that hold data relevant for the sink's goal, thereby offering an energy-efficient way to attain objectives related to information freshness. This paper focuses on a scenario where the sink collects fresh information on top-k values, defined as data from the nodes observing the k highest readings at the deadline. We introduce a new metric called top-k Query Age of Information (k-QAoI), which allows us to characterize the performance of CoWu by considering the characteristics of the physical process. Further, we show how to select the CoWu parameters, such as its timing and threshold, to attain both information freshness and energy efficiency. The numerical results reveal the effectiveness of the CoWu approach, which is able to collect top-k data with higher energy efficiency while reducing k-QAoI when compared to round-robin scheduling, especially when the number of nodes is large and the required size of k is small.
A Fairness-Oriented Reinforcement Learning Approach for the Operation and Control of Shared Micromobility Services
Mar 23, 2024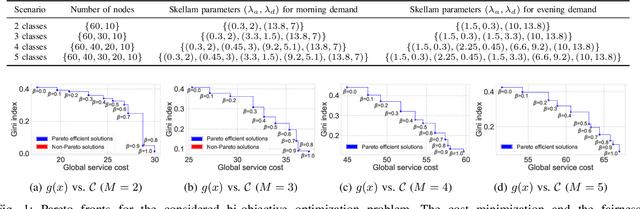


As Machine Learning systems become increasingly popular across diverse application domains, including those with direct human implications, the imperative of equity and algorithmic fairness has risen to prominence in the Artificial Intelligence community. On the other hand, in the context of Shared Micromobility Systems, the exploration of fairness-oriented approaches remains limited. Addressing this gap, we introduce a pioneering investigation into the balance between performance optimization and algorithmic fairness in the operation and control of Shared Micromobility Services. Our study leverages the Q-Learning algorithm in Reinforcement Learning, benefiting from its convergence guarantees to ensure the robustness of our proposed approach. Notably, our methodology stands out for its ability to achieve equitable outcomes, as measured by the Gini index, across different station categories--central, peripheral, and remote. Through strategic rebalancing of vehicle distribution, our approach aims to maximize operator performance while simultaneously upholding fairness principles for users. In addition to theoretical insights, we substantiate our findings with a case study or simulation based on synthetic data, validating the efficacy of our approach. This paper underscores the critical importance of fairness considerations in shaping control strategies for Shared Micromobility Services, offering a pragmatic framework for enhancing equity in urban transportation systems.
Effective Communication with Dynamic Feature Compression
Jan 29, 2024



The remote wireless control of industrial systems is one of the major use cases for 5G and beyond systems: in these cases, the massive amounts of sensory information that need to be shared over the wireless medium may overload even high-capacity connections. Consequently, solving the effective communication problem by optimizing the transmission strategy to discard irrelevant information can provide a significant advantage, but is often a very complex task. In this work, we consider a prototypal system in which an observer must communicate its sensory data to a robot controlling a task (e.g., a mobile robot in a factory). We then model it as a remote Partially Observable Markov Decision Process (POMDP), considering the effect of adopting semantic and effective communication-oriented solutions on the overall system performance. We split the communication problem by considering an ensemble Vector Quantized Variational Autoencoder (VQ-VAE) encoding, and train a Deep Reinforcement Learning (DRL) agent to dynamically adapt the quantization level, considering both the current state of the environment and the memory of past messages. We tested the proposed approach on the well-known CartPole reference control problem, obtaining a significant performance increase over traditional approaches.
Push- and Pull-based Effective Communication in Cyber-Physical Systems
Jan 15, 2024In Cyber Physical Systems (CPSs), two groups of actors interact toward the maximization of system performance: the sensors, observing and disseminating the system state, and the actuators, performing physical decisions based on the received information. While it is generally assumed that sensors periodically transmit updates, returning the feedback signal only when necessary, and consequently adapting the physical decisions to the communication policy, can significantly improve the efficiency of the system. In particular, the choice between push-based communication, in which updates are initiated autonomously by the sensors, and pull-based communication, in which they are requested by the actuators, is a key design step. In this work, we propose an analytical model for optimizing push- and pull-based communication in CPSs, observing that the policy optimality coincides with Value of Information (VoI) maximization. Our results also highlight that, despite providing a better optimal solution, implementable push-based communication strategies may underperform even in relatively simple scenarios.
Timely and Massive Communication in 6G: Pragmatics, Learning, and Inference
Jun 30, 2023



5G has expanded the traditional focus of wireless systems to embrace two new connectivity types: ultra-reliable low latency and massive communication. The technology context at the dawn of 6G is different from the past one for 5G, primarily due to the growing intelligence at the communicating nodes. This has driven the set of relevant communication problems beyond reliable transmission towards semantic and pragmatic communication. This paper puts the evolution of low-latency and massive communication towards 6G in the perspective of these new developments. At first, semantic/pragmatic communication problems are presented by drawing parallels to linguistics. We elaborate upon the relation of semantic communication to the information-theoretic problems of source/channel coding, while generalized real-time communication is put in the context of cyber-physical systems and real-time inference. The evolution of massive access towards massive closed-loop communication is elaborated upon, enabling interactive communication, learning, and cooperation among wireless sensors and actuators.