 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning-Assisted Algorithm Unrolling for Online Optimization with Budget Constraints
Dec 03, 2022
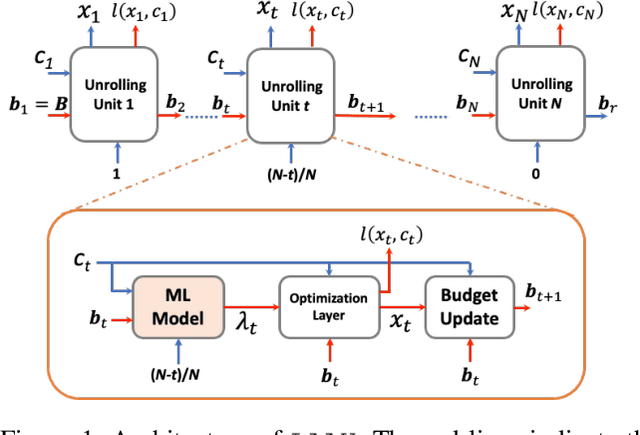
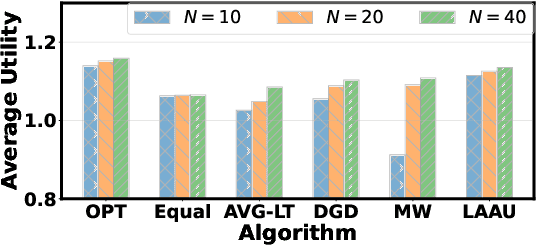
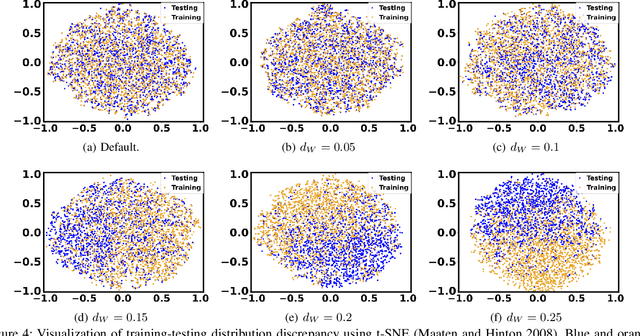
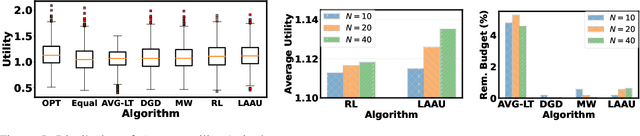
Online optimization with multiple budget constraints is challenging since the online decisions over a short time horizon are coupled together by strict inventory constraints. The existing manually-designed algorithms cannot achieve satisfactory average performance for this setting because they often need a large number of time steps for convergence and/or may violate the inventory constraints. In this paper, we propose a new machine learning (ML) assisted unrolling approach, called LAAU (Learning-Assisted Algorithm Unrolling), which unrolls the online decision pipeline and leverages an ML model for updating the Lagrangian multiplier online. For efficient training via backpropagation, we derive gradients of the decision pipeline over time. We also provide the average cost bounds for two cases when training data is available offline and collected online, respectively. Finally, we present numerical results to highlight that LAAU can outperform the existing baselines.
StreamYOLO: Real-time Object Detection for Streaming Perception
Jul 21, 2022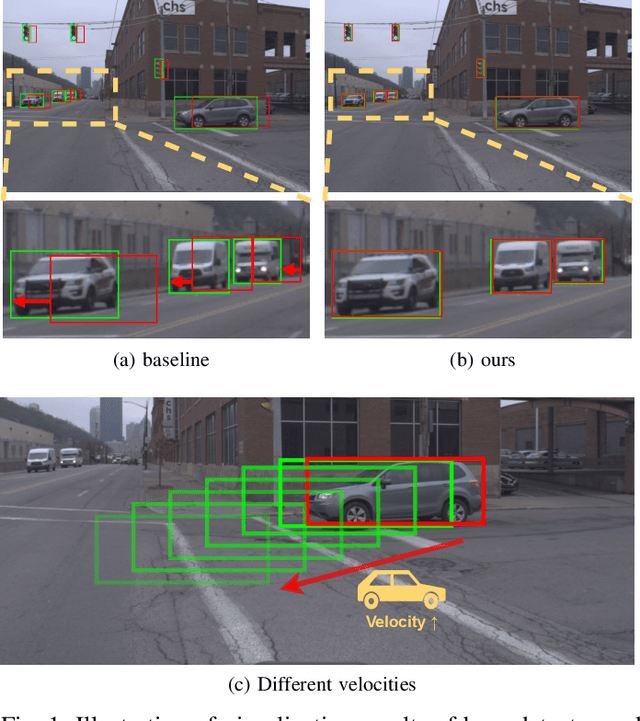
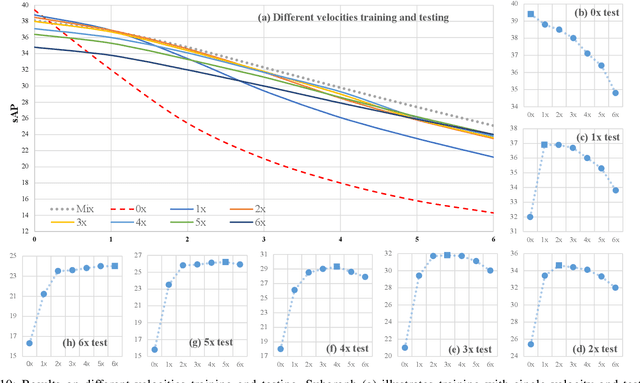
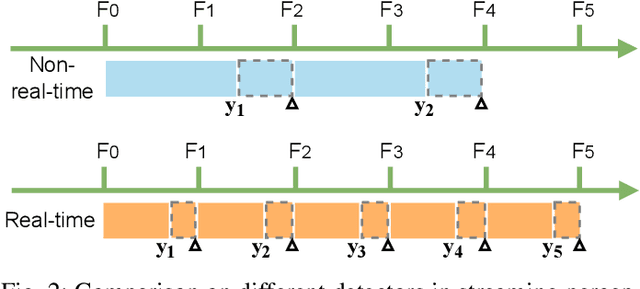
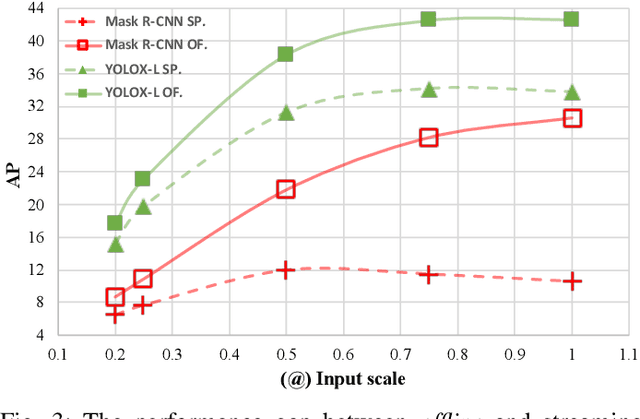
The perceptive models of autonomous driving require fast inference within a low latency for safety. While existing works ignore the inevitable environmental changes after processing, streaming perception jointly evaluates the latency and accuracy into a single metric for video online perception, guiding the previous works to search trade-offs between accuracy and speed. In this paper, we explore the performance of real time models on this metric and endow the models with the capacity of predicting the future, significantly improving the results for streaming perception. Specifically, we build a simple framework with two effective modules. One is a Dual Flow Perception module (DFP). It consists of dynamic flow and static flow in parallel to capture moving tendency and basic detection feature, respectively. Trend Aware Loss (TAL) is the other module which adaptively generates loss weight for each object with its moving speed. Realistically, we consider multiple velocities driving scene and further propose Velocity-awared streaming AP (VsAP) to jointly evaluate the accuracy. In this realistic setting, we design a efficient mix-velocity training strategy to guide detector perceive any velocities. Our simple method achieves the state-of-the-art performance on Argoverse-HD dataset and improves the sAP and VsAP by 4.7% and 8.2% respectively compared to the strong baseline, validating its effectiveness.
Towards Symbolic Time Series Representation Improved by Kernel Density Estimators
May 25, 2022This paper deals with symbolic time series representation. It builds up on the popular mapping technique Symbolic Aggregate approXimation algorithm (SAX), which is extensively utilized in sequence classification, pattern mining, anomaly detection, time series indexing and other data mining tasks. However, the disadvantage of this method is, that it works reliably only for time series with Gaussian-like distribution. In our previous work we have proposed an improvement of SAX, called dwSAX, which can deal with Gaussian as well as non-Gaussian data distribution. Recently we have made further progress in our solution - edwSAX. Our goal was to optimally cover the information space by means of sufficient alphabet utilization; and to satisfy lower bounding criterion as tight as possible. We describe here our approach, including evaluation on commonly employed tasks such as time series reconstruction error and Euclidean distance lower bounding with promising improvements over SAX.
Unsupervised Deep Learning for AC Optimal Power Flow via Lagrangian Duality
Dec 07, 2022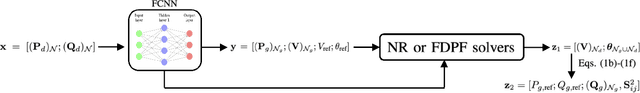
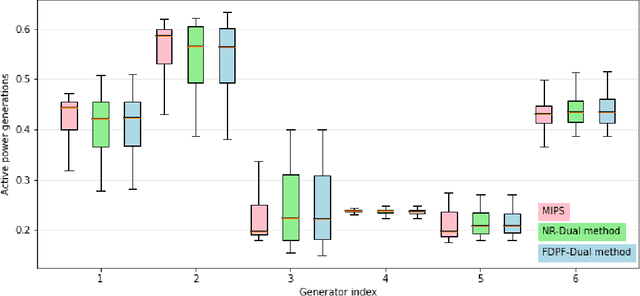
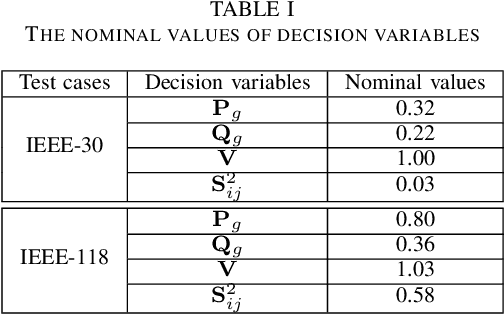
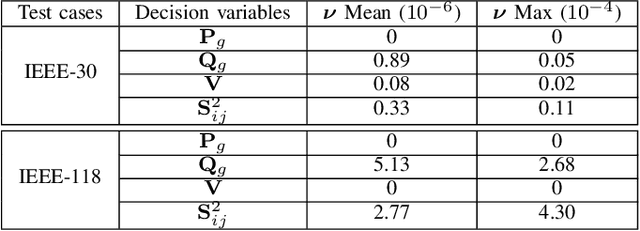
Non-convex AC optimal power flow (AC-OPF) is a fundamental optimization problem in power system analysis. The computational complexity of conventional solvers is typically high and not suitable for large-scale networks in real-time operation. Hence, deep learning based approaches have gained intensive attention to conduct the time-consuming training process offline. Supervised learning methods may yield a feasible AC-OPF solution with a small optimality gap. However, they often need conventional solvers to generate the training dataset. This paper proposes an end-to-end unsupervised learning based framework for AC-OPF. We develop a deep neural network to output a partial set of decision variables while the remaining variables are recovered by solving AC power flow equations. The fast decoupled power flow solver is adopted to further reduce the computational time. In addition, we propose using a modified augmented Lagrangian function as the training loss. The multipliers are adjusted dynamically based on the degree of constraint violation. Extensive numerical test results corroborate the advantages of our proposed approach over some existing methods.
Causal Inference (C-inf) -- asymmetric scenario of typical phase transitions
Jan 02, 2023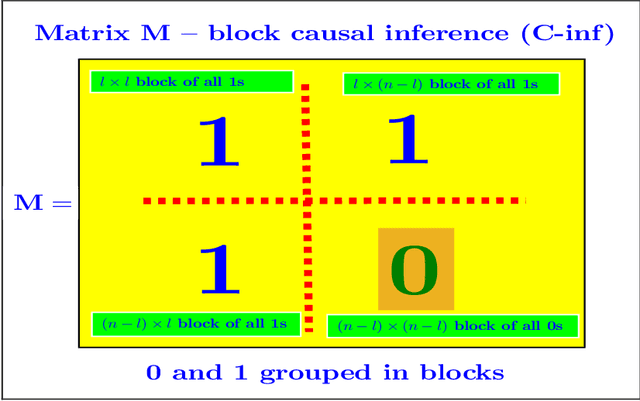
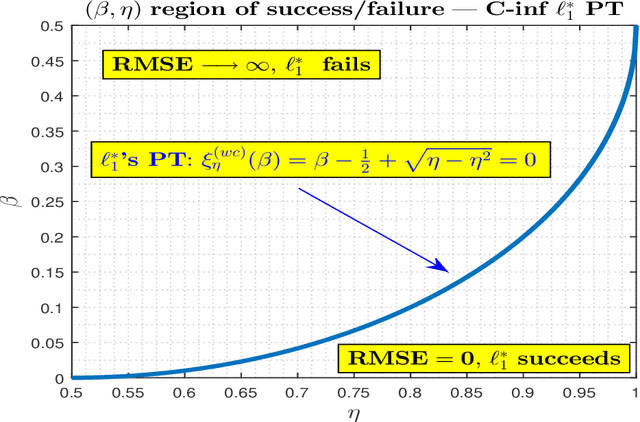
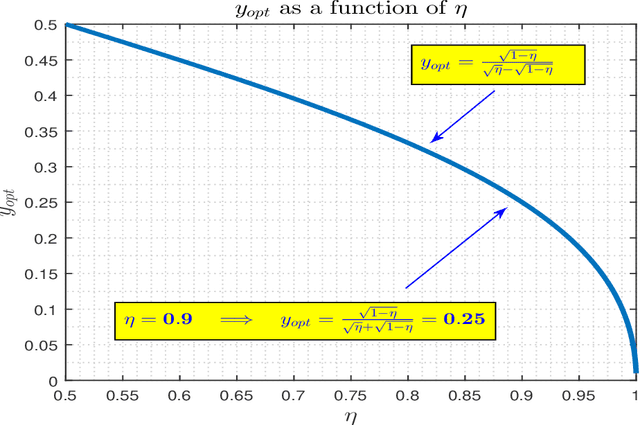
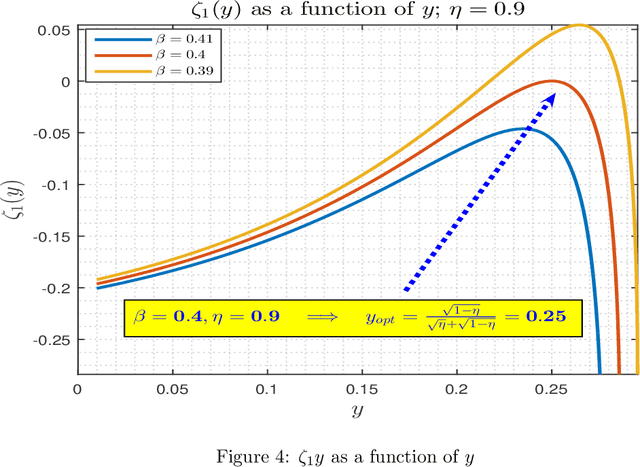
In this paper, we revisit and further explore a mathematically rigorous connection between Causal inference (C-inf) and the Low-rank recovery (LRR) established in [10]. Leveraging the Random duality - Free probability theory (RDT-FPT) connection, we obtain the exact explicit typical C-inf asymmetric phase transitions (PT). We uncover a doubling low-rankness phenomenon, which means that exactly two times larger low rankness is allowed in asymmetric scenarios compared to the symmetric worst case ones considered in [10]. Consequently, the final PT mathematical expressions are as elegant as those obtained in [10], and highlight direct relations between the targeted C-inf matrix low rankness and the time of treatment. Our results have strong implications for applications, where C-inf matrices are not necessarily symmetric.
Can Backdoor Attacks Survive Time-Varying Models?
Jun 08, 2022
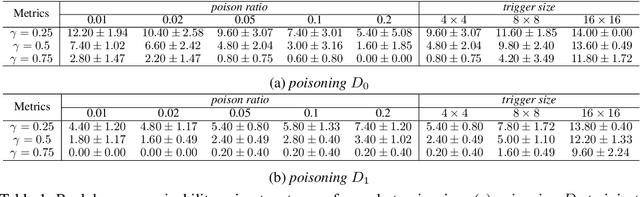
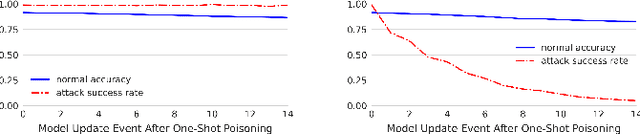

Backdoors are powerful attacks against deep neural networks (DNNs). By poisoning training data, attackers can inject hidden rules (backdoors) into DNNs, which only activate on inputs containing attack-specific triggers. While existing work has studied backdoor attacks on a variety of DNN models, they only consider static models, which remain unchanged after initial deployment. In this paper, we study the impact of backdoor attacks on a more realistic scenario of time-varying DNN models, where model weights are updated periodically to handle drifts in data distribution over time. Specifically, we empirically quantify the "survivability" of a backdoor against model updates, and examine how attack parameters, data drift behaviors, and model update strategies affect backdoor survivability. Our results show that one-shot backdoor attacks (i.e., only poisoning training data once) do not survive past a few model updates, even when attackers aggressively increase trigger size and poison ratio. To stay unaffected by model update, attackers must continuously introduce corrupted data into the training pipeline. Together, these results indicate that when models are updated to learn new data, they also "forget" backdoors as hidden, malicious features. The larger the distribution shift between old and new training data, the faster backdoors are forgotten. Leveraging these insights, we apply a smart learning rate scheduler to further accelerate backdoor forgetting during model updates, which prevents one-shot backdoors from surviving past a single model update.
Time-Optimal Trajectory Planning with Interaction with the Environment
Jul 12, 2022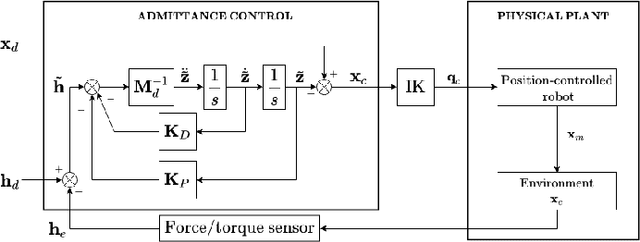
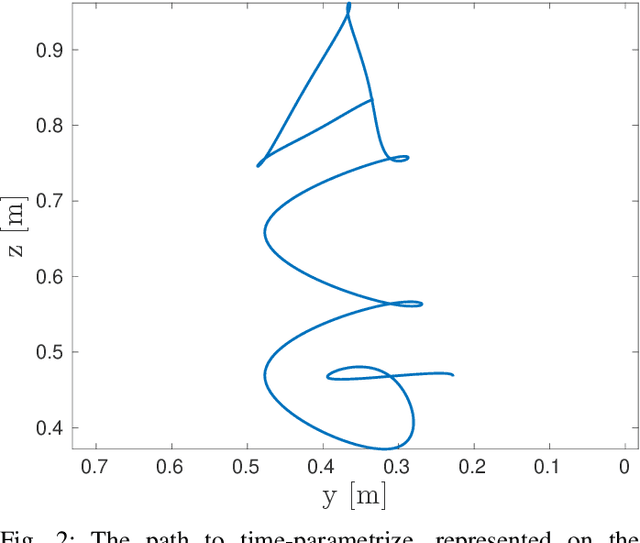

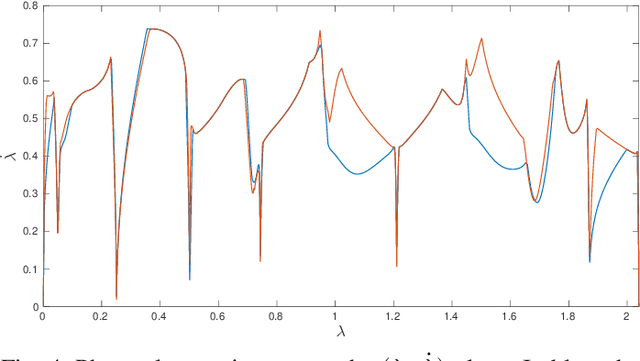
Optimal motion planning along prescribed paths can be solved with several techniques, but most of them do not take into account the wrenches exerted by the end-effector when in contact with the environment. When a dynamic model of the environment is not available, no consolidated methodology exists to consider the effect of the interaction. Regardless of the specific performance index to optimize, this article proposes a strategy to include external wrenches in the optimal planning algorithm, considering the task specifications. This procedure is instantiated for minimum-time trajectories and validated on a real robot performing an interaction task under admittance control. The results prove that the inclusion of end-effector wrenches affect the planned trajectory, in fact modifying the manipulator's dynamic capability.
Dynamic Local Feature Aggregation for Learning on Point Clouds
Jan 07, 2023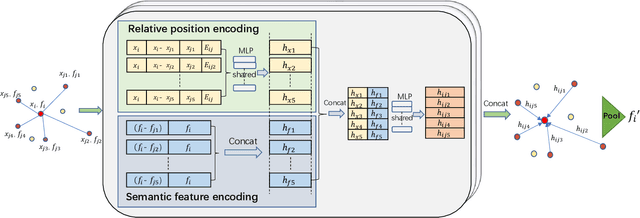
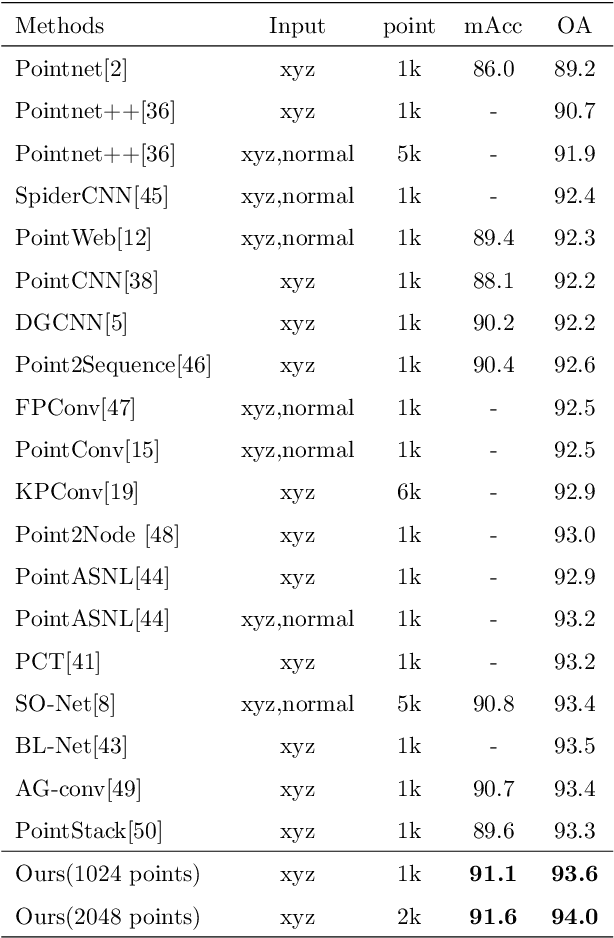
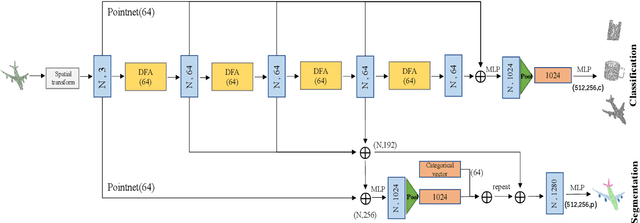

Existing point cloud learning methods aggregate features from neighbouring points relying on constructing graph in the spatial domain, which results in feature update for each point based on spatially-fixed neighbours throughout layers. In this paper, we propose a dynamic feature aggregation (DFA) method that can transfer information by constructing local graphs in the feature domain without spatial constraints. By finding k-nearest neighbors in the feature domain, we perform relative position encoding and semantic feature encoding to explore latent position and feature similarity information, respectively, so that rich local features can be learned. At the same time, we also learn low-dimensional global features from the original point cloud for enhancing feature representation. Between DFA layers, we dynamically update the constructed local graph structure, so that we can learn richer information, which greatly improves adaptability and efficiency. We demonstrate the superiority of our method by conducting extensive experiments on point cloud classification and segmentation tasks. Implementation code is available: https://github.com/jiamang/DFA.
Privacy and Efficiency of Communications in Federated Split Learning
Jan 07, 2023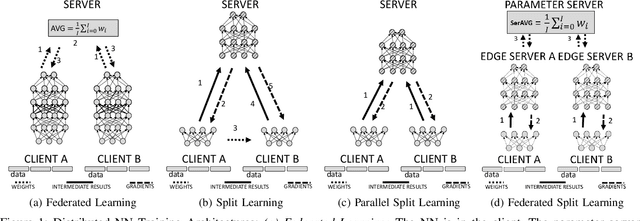
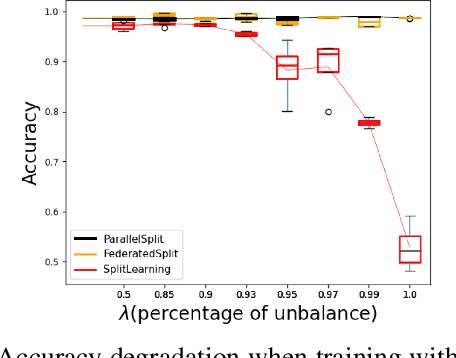
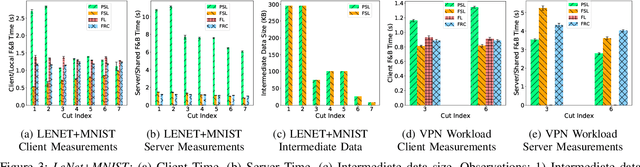
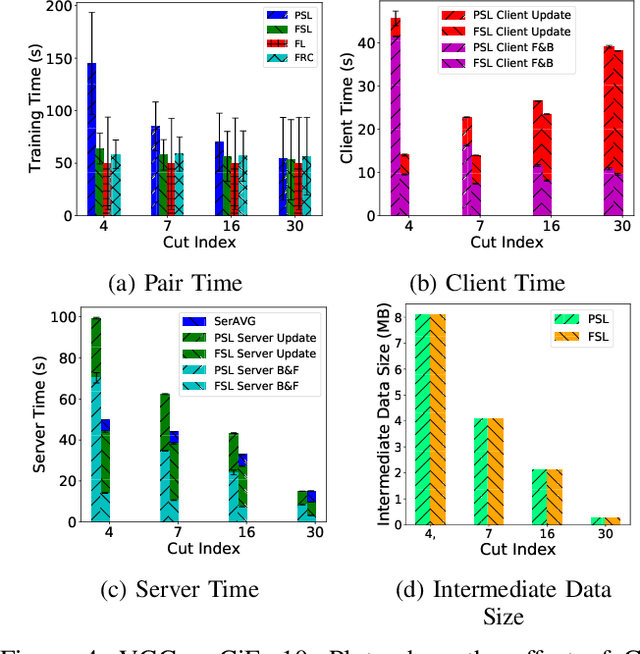
Everyday, large amounts of sensitive data is distributed across mobile phones, wearable devices, and other sensors. Traditionally, these enormous datasets have been processed on a single system, with complex models being trained to make valuable predictions. Distributed machine learning techniques such as Federated and Split Learning have recently been developed to protect user data and privacy better while ensuring high performance. Both of these distributed learning architectures have advantages and disadvantages. In this paper, we examine these tradeoffs and suggest a new hybrid Federated Split Learning architecture that combines the efficiency and privacy benefits of both. Our evaluation demonstrates how our hybrid Federated Split Learning approach can lower the amount of processing power required by each client running a distributed learning system, reduce training and inference time while keeping a similar accuracy. We also discuss the resiliency of our approach to deep learning privacy inference attacks and compare our solution to other recently proposed benchmarks.
E$^3$Pose: Energy-Efficient Edge-assisted Multi-camera System for Multi-human 3D Pose Estimation
Jan 21, 2023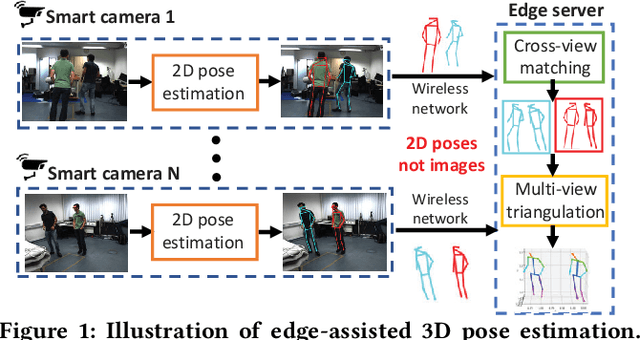
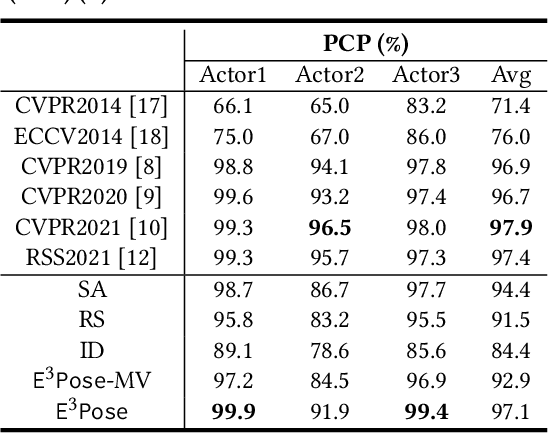
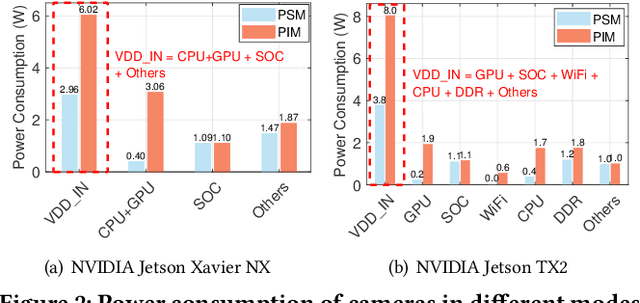
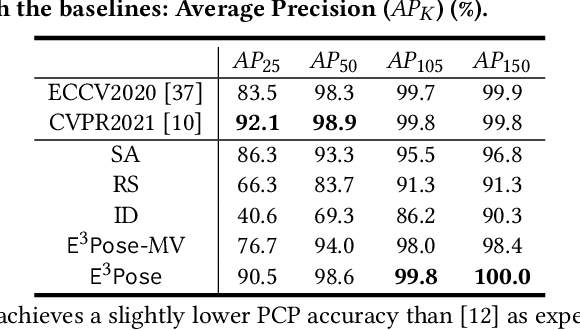
Multi-human 3D pose estimation plays a key role in establishing a seamless connection between the real world and the virtual world. Recent efforts adopted a two-stage framework that first builds 2D pose estimations in multiple camera views from different perspectives and then synthesizes them into 3D poses. However, the focus has largely been on developing new computer vision algorithms on the offline video datasets without much consideration on the energy constraints in real-world systems with flexibly-deployed and battery-powered cameras. In this paper, we propose an energy-efficient edge-assisted multiple-camera system, dubbed E$^3$Pose, for real-time multi-human 3D pose estimation, based on the key idea of adaptive camera selection. Instead of always employing all available cameras to perform 2D pose estimations as in the existing works, E$^3$Pose selects only a subset of cameras depending on their camera view qualities in terms of occlusion and energy states in an adaptive manner, thereby reducing the energy consumption (which translates to extended battery lifetime) and improving the estimation accuracy. To achieve this goal, E$^3$Pose incorporates an attention-based LSTM to predict the occlusion information of each camera view and guide camera selection before cameras are selected to process the images of a scene, and runs a camera selection algorithm based on the Lyapunov optimization framework to make long-term adaptive selection decisions. We build a prototype of E$^3$Pose on a 5-camera testbed, demonstrate its feasibility and evaluate its performance. Our results show that a significant energy saving (up to 31.21%) can be achieved while maintaining a high 3D pose estimation accuracy comparable to state-of-the-art methods.