 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable AI for clinical and remote health applications: a survey on tabular and time series data
Sep 14, 2022

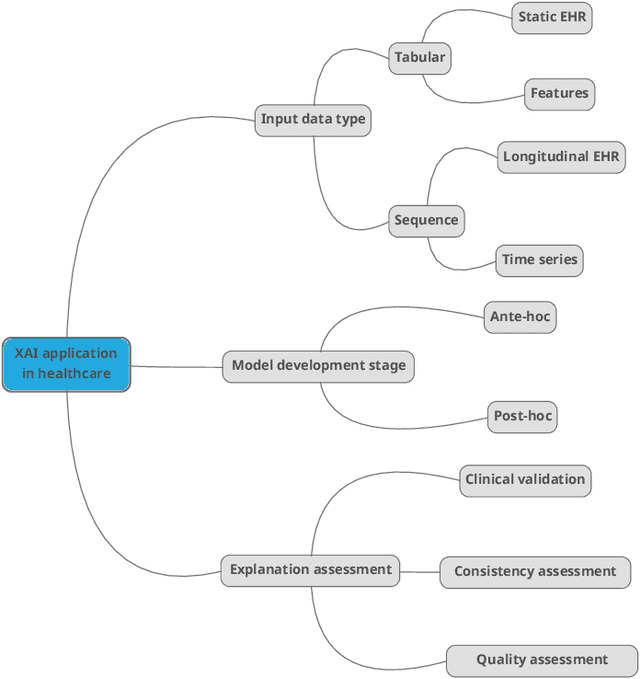


Nowadays Artificial Intelligence (AI) has become a fundamental component of healthcare applications, both clinical and remote, but the best performing AI systems are often too complex to be self-explaining. Explainable AI (XAI) techniques are defined to unveil the reasoning behind the system's predictions and decisions, and they become even more critical when dealing with sensitive and personal health data. It is worth noting that XAI has not gathered the same attention across different research areas and data types, especially in healthcare. In particular, many clinical and remote health applications are based on tabular and time series data, respectively, and XAI is not commonly analysed on these data types, while computer vision and Natural Language Processing (NLP) are the reference applications. To provide an overview of XAI methods that are most suitable for tabular and time series data in the healthcare domain, this paper provides a review of the literature in the last 5 years, illustrating the type of generated explanations and the efforts provided to evaluate their relevance and quality. Specifically, we identify clinical validation, consistency assessment, objective and standardised quality evaluation, and human-centered quality assessment as key features to ensure effective explanations for the end users. Finally, we highlight the main research challenges in the field as well as the limitations of existing XAI methods.
In-situ monitoring additive manufacturing process with AI edge computing
Jan 02, 2023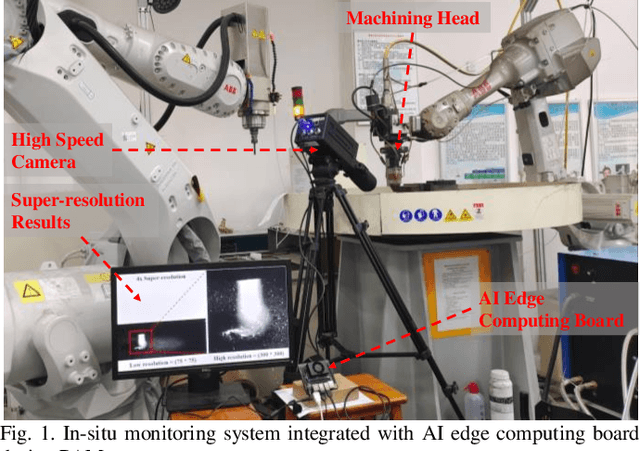
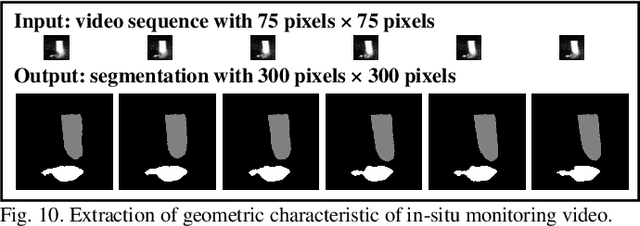
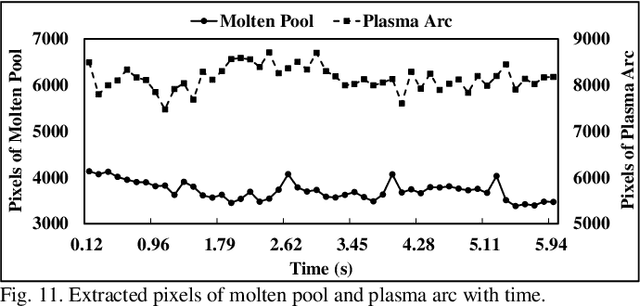

In-situ monitoring system can be used to monitor the quality of additive manufacturing (AM) processes. In the case of digital image correlation (DIC) based in-situ monitoring systems, high-speed cameras were used to capture images of high resolutions. This paper proposed a novel in-situ monitoring system to accelerate the process of digital images using artificial intelligence (AI) edge computing board. It built a visual transformer based video super resolution (ViTSR) network to reconstruct high resolution (HR) videos frames. Fully convolutional network (FCN) was used to simultaneously extract the geometric characteristics of molten pool and plasma arc during the AM processes. Compared with 6 state-of-the-art super resolution methods, ViTSR ranks first in terms of peak signal to noise ratio (PSNR). The PSNR of ViTSR for 4x super resolution reached 38.16 dB on test data with input size of 75 pixels x 75 pixels. Inference time of ViTSR and FCN was optimized to 50.97 ms and 67.86 ms on AI edge board after operator fusion and model pruning. The total inference time of the proposed system was 118.83 ms, which meets the requirement of real-time quality monitoring with low cost in-situ monitoring equipment during AM processes. The proposed system achieved an accuracy of 96.34% on the multi-objects extraction task and can be applied to different AM processes.
Space-time tradeoffs of lenses and optics via higher category theory
Sep 19, 2022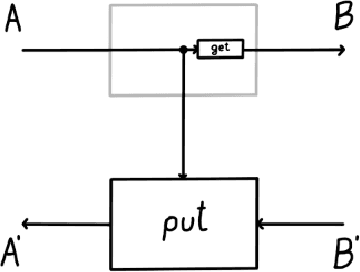
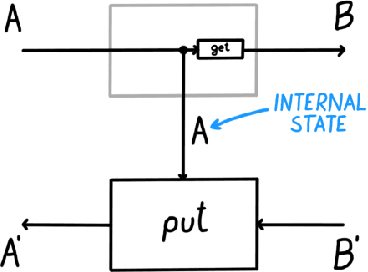
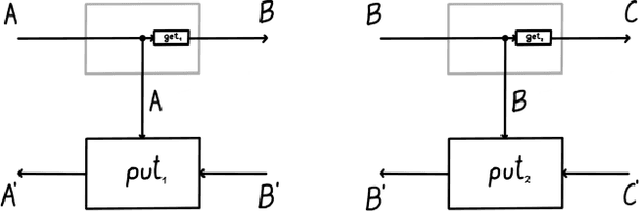
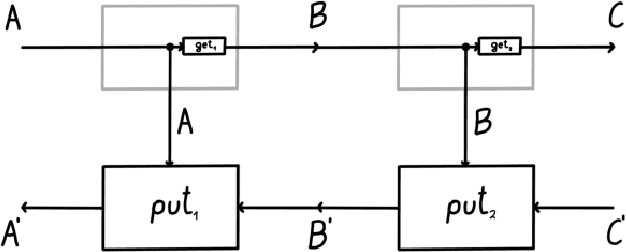
Optics and lenses are abstract categorical gadgets that model systems with bidirectional data flow. In this paper we observe that the denotational definition of optics - identifying two optics as equivalent by observing their behaviour from the outside - is not suitable for operational, software oriented approaches where optics are not merely observed, but built with their internal setups in mind. We identify operational differences between denotationally isomorphic categories of cartesian optics and lenses: their different composition rule and corresponding space-time tradeoffs, positioning them at two opposite ends of a spectrum. With these motivations we lift the existing categorical constructions and their relationships to the 2-categorical level, showing that the relevant operational concerns become visible. We define the 2-category $\textbf{2-Optic}(\mathcal{C})$ whose 2-cells explicitly track optics' internal configuration. We show that the 1-category $\textbf{Optic}(\mathcal{C})$ arises by locally quotienting out the connected components of this 2-category. We show that the embedding of lenses into cartesian optics gets weakened from a functor to an oplax functor whose oplaxator now detects the different composition rule. We determine the difficulties in showing this functor forms a part of an adjunction in any of the standard 2-categories. We establish a conjecture that the well-known isomorphism between cartesian lenses and optics arises out of the lax 2-adjunction between their double-categorical counterparts. In addition to presenting new research, this paper is also meant to be an accessible introduction to the topic.
Cumulative Stay-time Representation for Electronic Health Records in Medical Event Time Prediction
Apr 28, 2022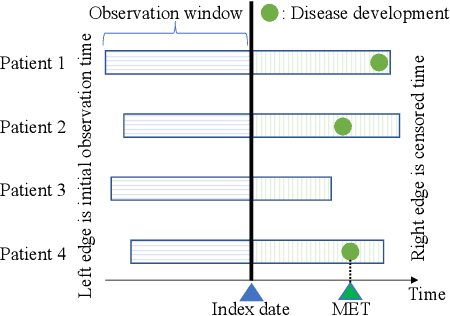
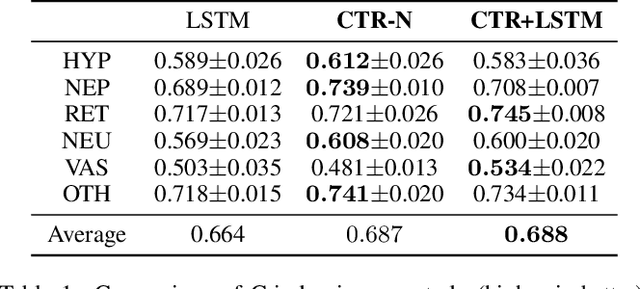
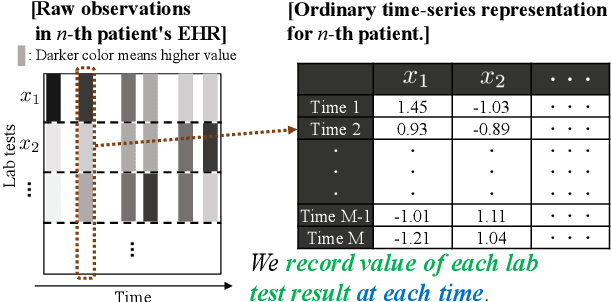

We address the problem of predicting when a disease will develop, i.e., medical event time (MET), from a patient's electronic health record (EHR). The MET of non-communicable diseases like diabetes is highly correlated to cumulative health conditions, more specifically, how much time the patient spent with specific health conditions in the past. The common time-series representation is indirect in extracting such information from EHR because it focuses on detailed dependencies between values in successive observations, not cumulative information. We propose a novel data representation for EHR called cumulative stay-time representation (CTR), which directly models such cumulative health conditions. We derive a trainable construction of CTR based on neural networks that has the flexibility to fit the target data and scalability to handle high-dimensional EHR. Numerical experiments using synthetic and real-world datasets demonstrate that CTR alone achieves a high prediction performance, and it enhances the performance of existing models when combined with them.
A Holistic Cascade System, benchmark, and Human Evaluation Protocol for Expressive Speech-to-Speech Translation
Jan 25, 2023
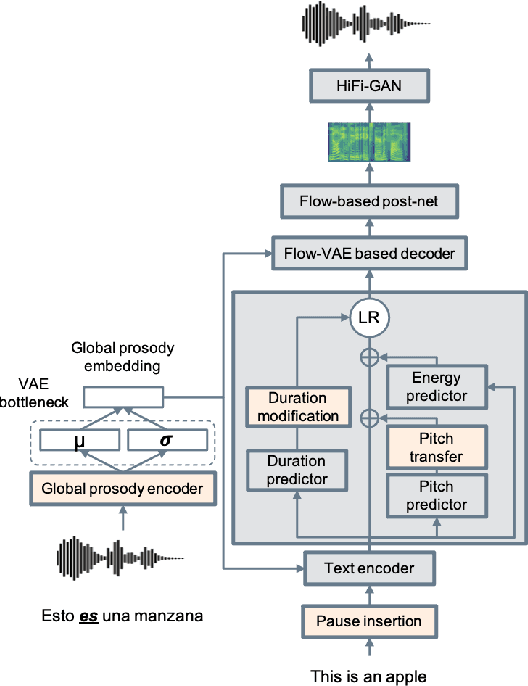

Expressive speech-to-speech translation (S2ST) aims to transfer prosodic attributes of source speech to target speech while maintaining translation accuracy. Existing research in expressive S2ST is limited, typically focusing on a single expressivity aspect at a time. Likewise, this research area lacks standard evaluation protocols and well-curated benchmark datasets. In this work, we propose a holistic cascade system for expressive S2ST, combining multiple prosody transfer techniques previously considered only in isolation. We curate a benchmark expressivity test set in the TV series domain and explored a second dataset in the audiobook domain. Finally, we present a human evaluation protocol to assess multiple expressive dimensions across speech pairs. Experimental results indicate that bi-lingual annotators can assess the quality of expressive preservation in S2ST systems, and the holistic modeling approach outperforms single-aspect systems. Audio samples can be accessed through our demo webpage: https://facebookresearch.github.io/speech_translation/cascade_expressive_s2st.
Leveraging Planning Landmarks for Hybrid Online Goal Recognition
Jan 25, 2023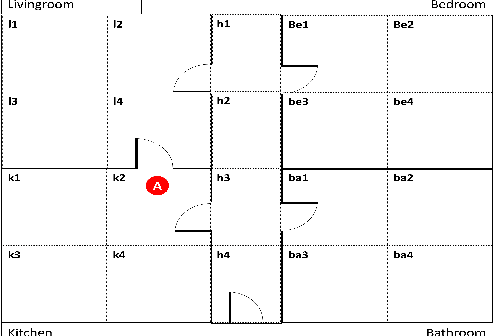
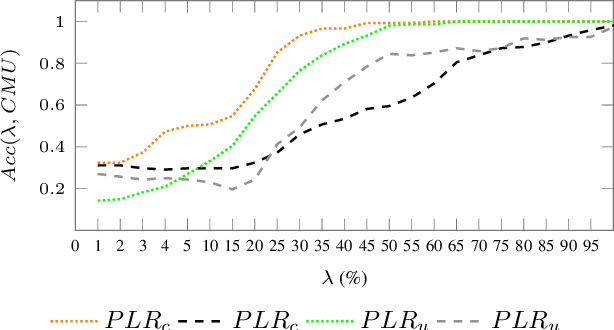
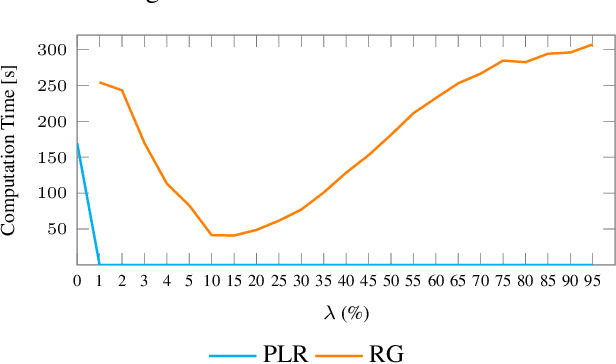
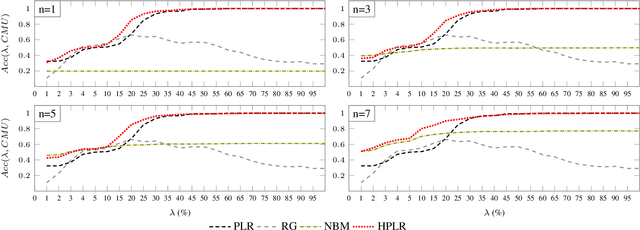
Goal recognition is an important problem in many application domains (e.g., pervasive computing, intrusion detection, computer games, etc.). In many application scenarios it is important that goal recognition algorithms can recognize goals of an observed agent as fast as possible and with minimal domain knowledge. Hence, in this paper, we propose a hybrid method for online goal recognition that combines a symbolic planning landmark based approach and a data-driven goal recognition approach and evaluate it in a real-world cooking scenario. The empirical results show that the proposed method is not only significantly more efficient in terms of computation time than the state-of-the-art but also improves goal recognition performance. Furthermore, we show that the utilized planning landmark based approach, which was so far only evaluated on artificial benchmark domains, achieves also good recognition performance when applied to a real-world cooking scenario.
Real-Time Portrait Stylization on the Edge
Jun 02, 2022
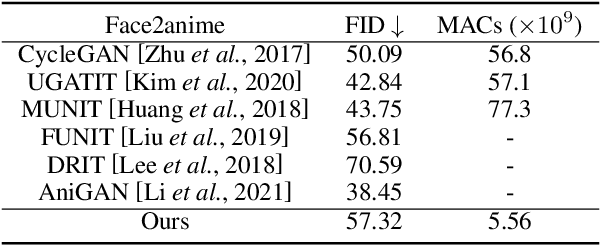


In this work we demonstrate real-time portrait stylization, specifically, translating self-portrait into cartoon or anime style on mobile devices. We propose a latency-driven differentiable architecture search method, maintaining realistic generative quality. With our framework, we obtain $10\times$ computation reduction on the generative model and achieve real-time video stylization on off-the-shelf smartphone using mobile GPUs.
Agility and Target Distribution in the Dynamic Stochastic Traveling Salesman Problem
Feb 01, 2023An important variant of the classic Traveling Salesman Problem (TSP) is the Dynamic TSP, in which a system with dynamic constraints is tasked with visiting a set of n target locations (in any order) in the shortest amount of time. Such tasks arise naturally in many robotic motion planning problems, particularly in exploration, surveillance and reconnaissance, and classical TSP algorithms on graphs are typically inapplicable in this setting. An important question about such problems is: if the target points are random, what is the length of the tour (either in expectation or as a concentration bound) as n grows? This problem is the Dynamic Stochastic TSP (DSTSP), and has been studied both for specific important vehicle models and for general dynamic systems; however, in general only the order of growth is known. In this work, we explore the connection between the distribution from which the targets are drawn and the dynamics of the system, yielding a more precise lower bound on tour length as well as a matching upper bound for the case of symmetric (or driftless) systems. We then extend the symmetric dynamics results to the case when the points are selected by a (non-random) adversary whose goal is to maximize the length, thus showing worst-case bounds on the tour length.
What Makes Good Examples for Visual In-Context Learning?
Feb 01, 2023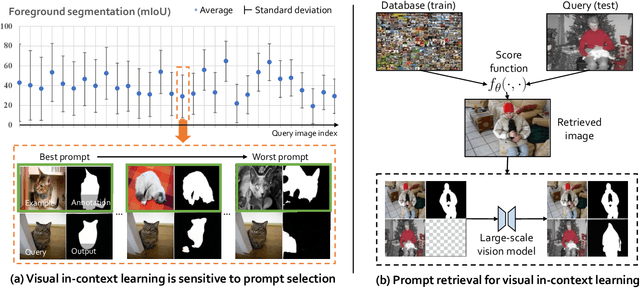

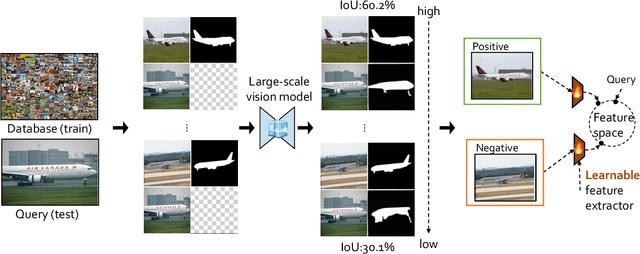
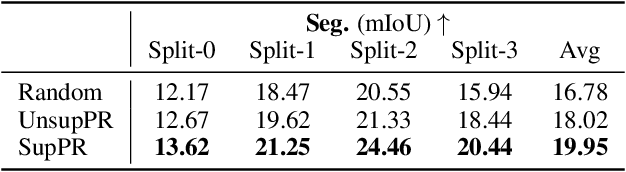
Large-scale models trained on broad data have recently become the mainstream architecture in computer vision due to their strong generalization performance. In this paper, the main focus is on an emergent ability in large vision models, known as in-context learning, which allows inference on unseen tasks by conditioning on in-context examples (a.k.a.~prompt) without updating the model parameters. This concept has been well-known in natural language processing but has only been studied very recently for large vision models. We for the first time provide a comprehensive investigation on the impact of in-context examples in computer vision, and find that the performance is highly sensitive to the choice of in-context examples. To overcome the problem, we propose a prompt retrieval framework to automate the selection of in-context examples. Specifically, we present (1) an unsupervised prompt retrieval method based on nearest example search using an off-the-shelf model, and (2) a supervised prompt retrieval method, which trains a neural network to choose examples that directly maximize in-context learning performance. The results demonstrate that our methods can bring non-trivial improvements to visual in-context learning in comparison to the commonly-used random selection.
Efficient Meta-Learning via Error-based Context Pruning for Implicit Neural Representations
Feb 01, 2023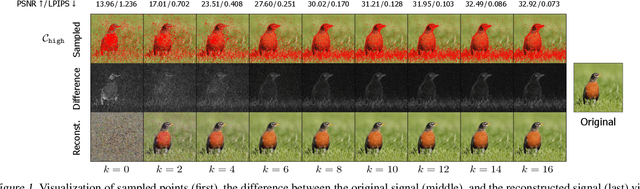
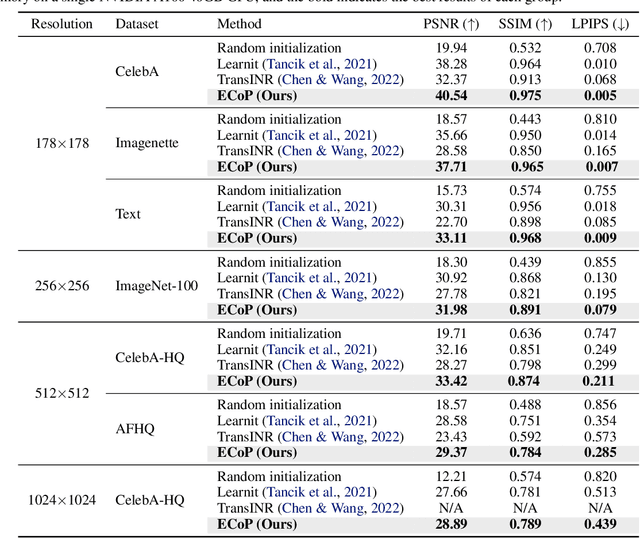
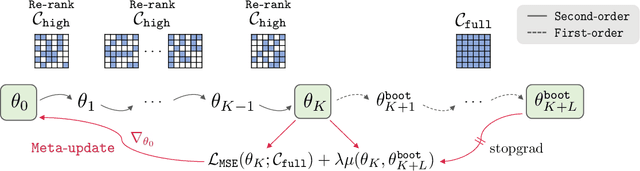
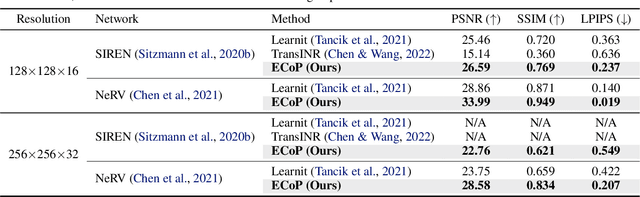
We introduce an efficient optimization-based meta-learning technique for learning large-scale implicit neural representations (INRs). Our main idea is designing an online selection of context points, which can significantly reduce memory requirements for meta-learning in any established setting. By doing so, we expect additional memory savings which allows longer per-signal adaptation horizons (at a given memory budget), leading to better meta-initializations by reducing myopia and, more crucially, enabling learning on high-dimensional signals. To implement such context pruning, our technical novelty is three-fold. First, we propose a selection scheme that adaptively chooses a subset at each adaptation step based on the predictive error, leading to the modeling of the global structure of the signal in early steps and enabling the later steps to capture its high-frequency details. Second, we counteract any possible information loss from context pruning by minimizing the parameter distance to a bootstrapped target model trained on a full context set. Finally, we suggest using the full context set with a gradient scaling scheme at test-time. Our technique is model-agnostic, intuitive, and straightforward to implement, showing significant reconstruction improvements for a wide range of signals. Code is available at https://github.com/jihoontack/ECoP