 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Color Me Intrigued: Quantifying Usage of Colors in Fiction
Jan 09, 2023
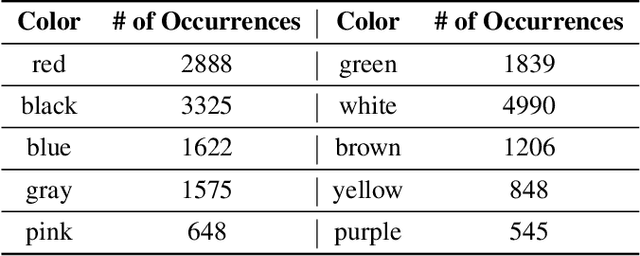
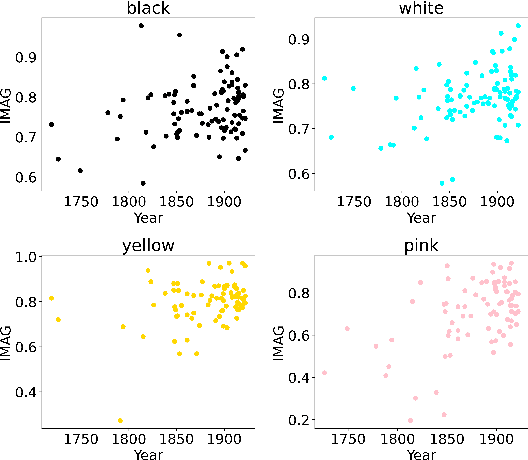
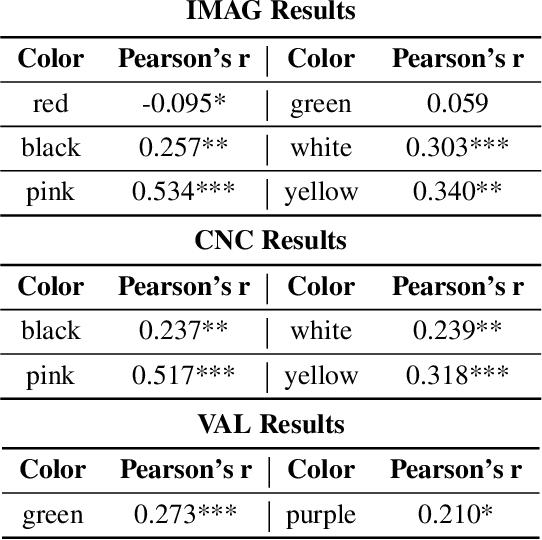
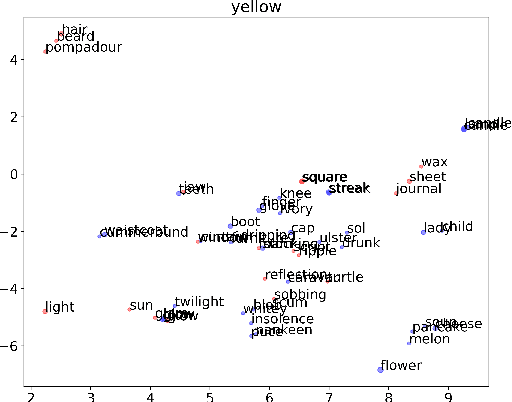
We present preliminary results in quantitative analyses of color usage in selected authors' works from LitBank. Using Glasgow Norms, human ratings on 5000+ words, we measure attributes of nouns dependent on color terms. Early results demonstrate a significant increase in noun concreteness over time. We also propose future research directions for computational literary color analytics.
Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models
Sep 15, 2022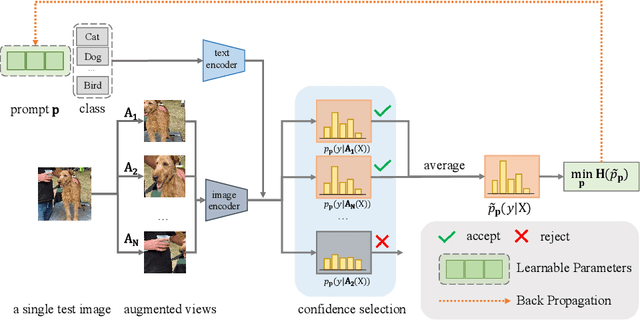
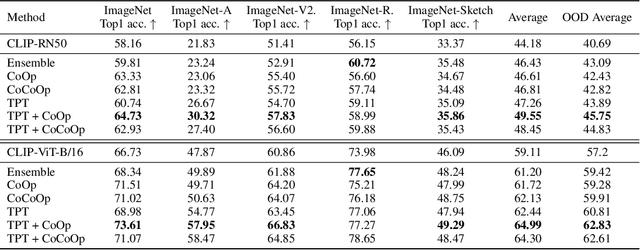
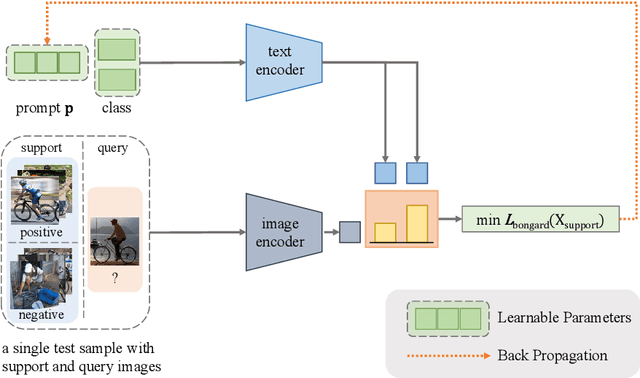
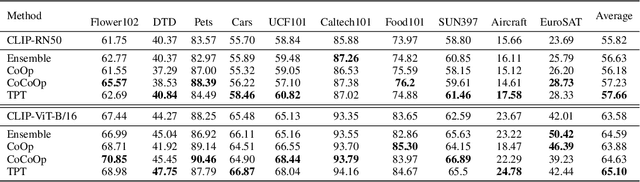
Pre-trained vision-language models (e.g., CLIP) have shown promising zero-shot generalization in many downstream tasks with properly designed text prompts. Instead of relying on hand-engineered prompts, recent works learn prompts using the training data from downstream tasks. While effective, training on domain-specific data reduces a model's generalization capability to unseen new domains. In this work, we propose test-time prompt tuning (TPT), a method that can learn adaptive prompts on the fly with a single test sample. For image classification, TPT optimizes the prompt by minimizing the entropy with confidence selection so that the model has consistent predictions across different augmented views of each test sample. In evaluating generalization to natural distribution shifts, TPT improves the zero-shot top-1 accuracy of CLIP by 3.6% on average, surpassing previous prompt tuning approaches that require additional task-specific training data. In evaluating cross-dataset generalization with unseen categories, TPT performs on par with the state-of-the-art approaches that use additional training data. Project page: https://azshue.github.io/TPT.
Proceedings of AAAI 2022 Fall Symposium: The Role of AI in Responding to Climate Challenges
Jan 06, 2023Climate change is one of the most pressing challenges of our time, requiring rapid action across society. As artificial intelligence tools (AI) are rapidly deployed, it is therefore crucial to understand how they will impact climate action. On the one hand, AI can support applications in climate change mitigation (reducing or preventing greenhouse gas emissions), adaptation (preparing for the effects of a changing climate), and climate science. These applications have implications in areas ranging as widely as energy, agriculture, and finance. At the same time, AI is used in many ways that hinder climate action (e.g., by accelerating the use of greenhouse gas-emitting fossil fuels). In addition, AI technologies have a carbon and energy footprint themselves. This symposium brought together participants from across academia, industry, government, and civil society to explore these intersections of AI with climate change, as well as how each of these sectors can contribute to solutions.
Federated Learning under Heterogeneous and Correlated Client Availability
Jan 11, 2023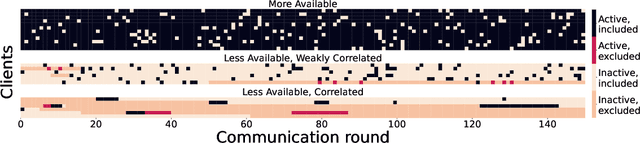
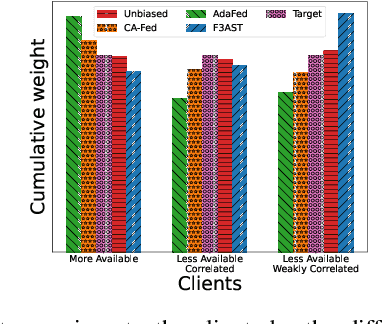
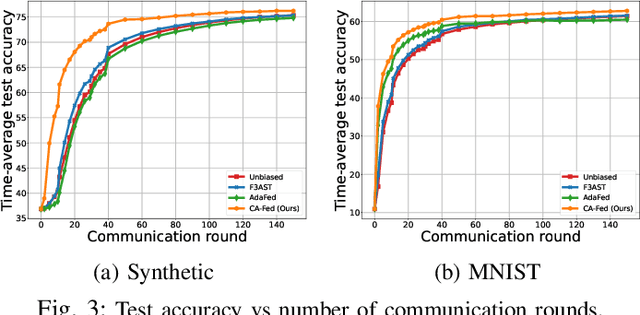
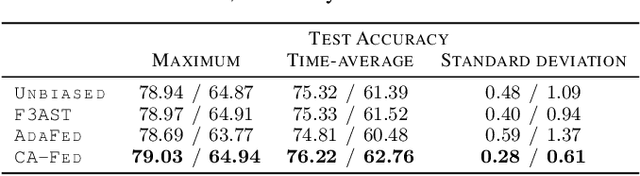
The enormous amount of data produced by mobile and IoT devices has motivated the development of federated learning (FL), a framework allowing such devices (or clients) to collaboratively train machine learning models without sharing their local data. FL algorithms (like FedAvg) iteratively aggregate model updates computed by clients on their own datasets. Clients may exhibit different levels of participation, often correlated over time and with other clients. This paper presents the first convergence analysis for a FedAvg-like FL algorithm under heterogeneous and correlated client availability. Our analysis highlights how correlation adversely affects the algorithm's convergence rate and how the aggregation strategy can alleviate this effect at the cost of steering training toward a biased model. Guided by the theoretical analysis, we propose CA-Fed, a new FL algorithm that tries to balance the conflicting goals of maximizing convergence speed and minimizing model bias. To this purpose, CA-Fed dynamically adapts the weight given to each client and may ignore clients with low availability and large correlation. Our experimental results show that CA-Fed achieves higher time-average accuracy and a lower standard deviation than state-of-the-art AdaFed and F3AST, both on synthetic and real datasets.
On the Importance of Noise Scheduling for Diffusion Models
Jan 26, 2023
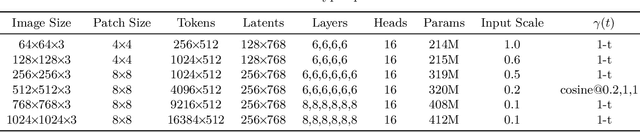

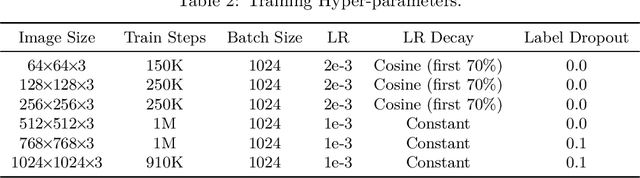
We empirically study the effect of noise scheduling strategies for denoising diffusion generative models. There are three findings: (1) the noise scheduling is crucial for the performance, and the optimal one depends on the task (e.g., image sizes), (2) when increasing the image size, the optimal noise scheduling shifts towards a noisier one (due to increased redundancy in pixels), and (3) simply scaling the input data by a factor of $b$ while keeping the noise schedule function fixed (equivalent to shifting the logSNR by $\log b$) is a good strategy across image sizes. This simple recipe, when combined with recently proposed Recurrent Interface Network (RIN), yields state-of-the-art pixel-based diffusion models for high-resolution images on ImageNet, enabling single-stage, end-to-end generation of diverse and high-fidelity images at 1024$\times$1024 resolution for the first time (without upsampling/cascades).
Scheduling Policy for Value-of-Information (VoI) in Trajectory Estimation for Digital Twins
Jan 26, 2023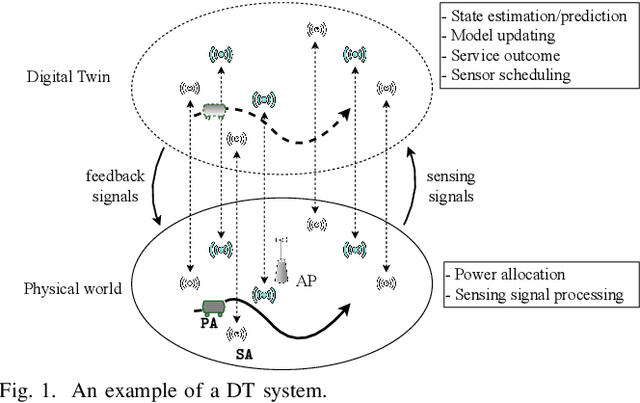
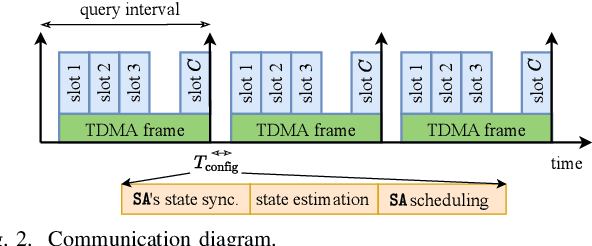
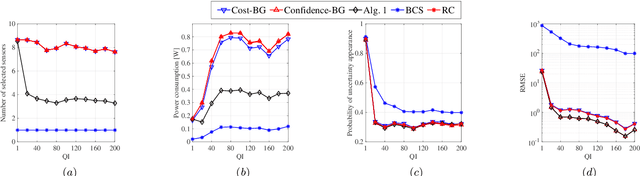
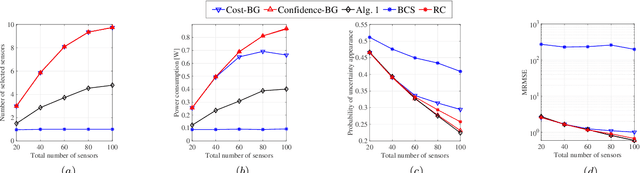
This paper presents an approach to schedule observations from different sensors in an environment to ensure their timely delivery and build a digital twin (DT) model of the system dynamics. At the cloud platform, DT models estimate and predict the system's state, then compute the optimal scheduling policy and resource allocation strategy to be executed in the physical world. However, given limited network resources, partial state vector information, and measurement errors at the distributed sensing agents, the acquisition of data (i.e., observations) for efficient state estimation of system dynamics is a non-trivial problem. We propose a Value of Information (VoI)-based algorithm that provides a polynomial-time solution for selecting the most informative subset of sensing agents to improve confidence in the state estimation of DT models. Numerical results confirm that the proposed method outperforms other benchmarks, reducing the communication overhead by half while maintaining the required estimation accuracy.
MoE-Fusion: Instance Embedded Mixture-of-Experts for Infrared and Visible Image Fusion
Feb 02, 2023
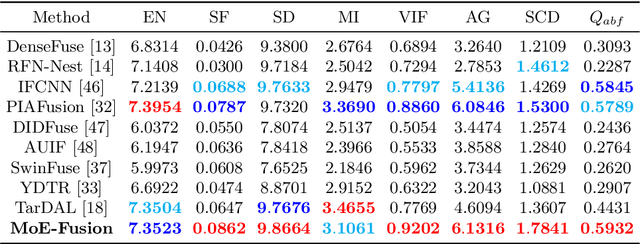
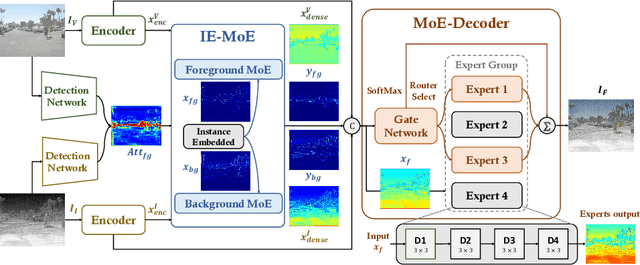
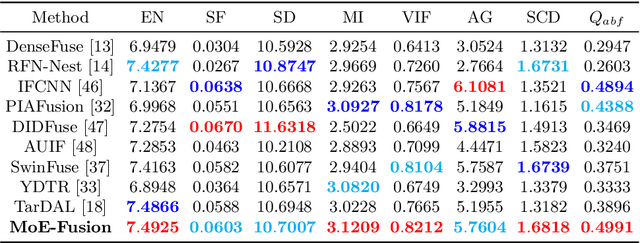
Infrared and visible image fusion can compensate for the incompleteness of single-modality imaging and provide a more comprehensive scene description based on cross-modal complementarity. Most works focus on learning the overall cross-modal features by high- and low-frequency constraints at the image level alone, ignoring the fact that cross-modal instance-level features often contain more valuable information. To fill this gap, we model cross-modal instance-level features by embedding instance information into a set of Mixture-of-Experts (MoEs) for the first time, prompting image fusion networks to specifically learn instance-level information. We propose a novel framework with instance embedded Mixture-of-Experts for infrared and visible image fusion, termed MoE-Fusion, which contains an instance embedded MoE group (IE-MoE), an MoE-Decoder, two encoders, and two auxiliary detection networks. By embedding the instance-level information learned in the auxiliary network, IE-MoE achieves specialized learning of cross-modal foreground and background features. MoE-Decoder can adaptively select suitable experts for cross-modal feature decoding and obtain fusion results dynamically. Extensive experiments show that our MoE-Fusion outperforms state-of-the-art methods in preserving contrast and texture details by learning instance-level information in cross-modal images.
Real-time 3D Single Object Tracking with Transformer
Sep 02, 2022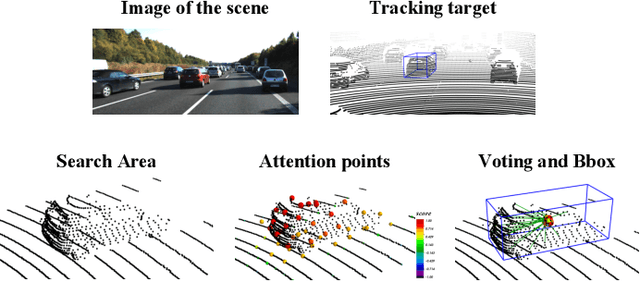
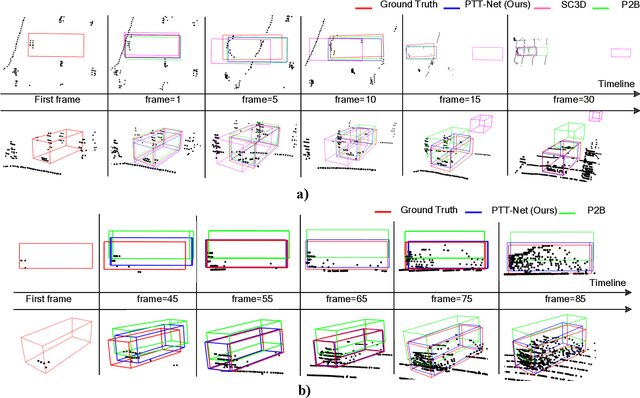
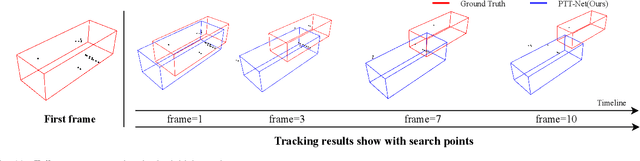
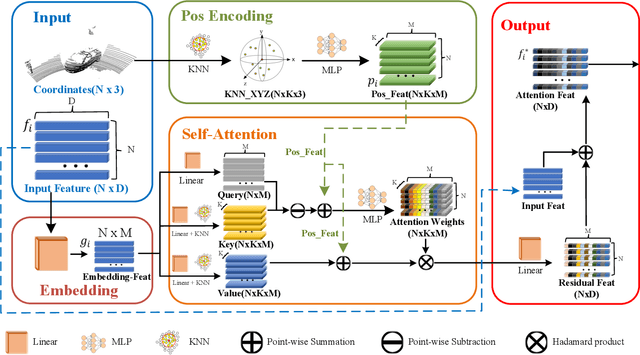
LiDAR-based 3D single object tracking is a challenging issue in robotics and autonomous driving. Currently, existing approaches usually suffer from the problem that objects at long distance often have very sparse or partially-occluded point clouds, which makes the features extracted by the model ambiguous. Ambiguous features will make it hard to locate the target object and finally lead to bad tracking results. To solve this problem, we utilize the powerful Transformer architecture and propose a Point-Track-Transformer (PTT) module for point cloud-based 3D single object tracking task. Specifically, PTT module generates fine-tuned attention features by computing attention weights, which guides the tracker focusing on the important features of the target and improves the tracking ability in complex scenarios. To evaluate our PTT module, we embed PTT into the dominant method and construct a novel 3D SOT tracker named PTT-Net. In PTT-Net, we embed PTT into the voting stage and proposal generation stage, respectively. PTT module in the voting stage could model the interactions among point patches, which learns context-dependent features. Meanwhile, PTT module in the proposal generation stage could capture the contextual information between object and background. We evaluate our PTT-Net on KITTI and NuScenes datasets. Experimental results demonstrate the effectiveness of PTT module and the superiority of PTT-Net, which surpasses the baseline by a noticeable margin, ~10% in the Car category. Meanwhile, our method also has a significant performance improvement in sparse scenarios. In general, the combination of transformer and tracking pipeline enables our PTT-Net to achieve state-of-the-art performance on both two datasets. Additionally, PTT-Net could run in real-time at 40FPS on NVIDIA 1080Ti GPU. Our code is open-sourced for the research community at https://github.com/shanjiayao/PTT.
On the Computational Complexity of Ethics: Moral Tractability for Minds and Machines
Feb 08, 2023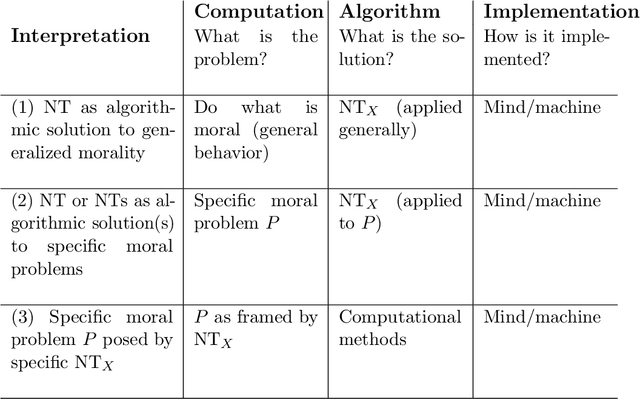
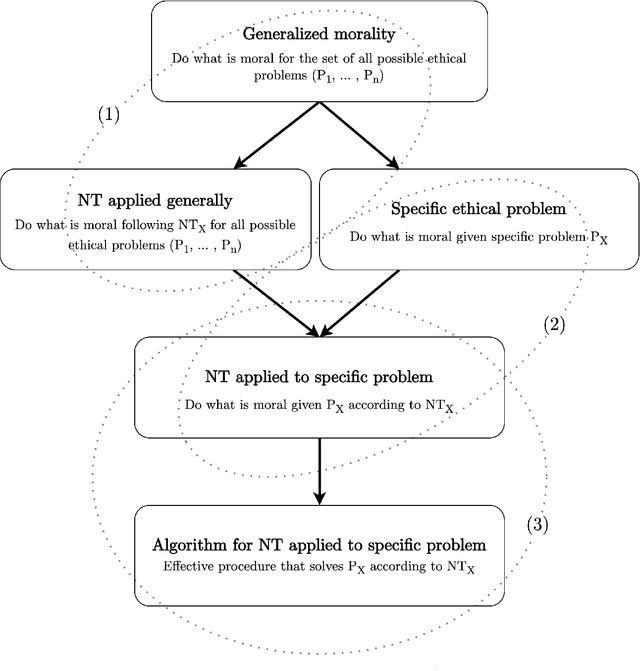
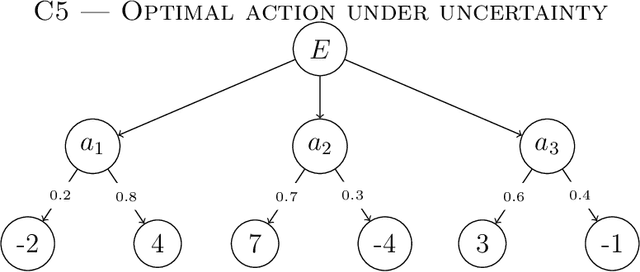
Why should moral philosophers, moral psychologists, and machine ethicists care about computational complexity? Debates on whether artificial intelligence (AI) can or should be used to solve problems in ethical domains have mainly been driven by what AI can or cannot do in terms of human capacities. In this paper, we tackle the problem from the other end by exploring what kind of moral machines are possible based on what computational systems can or cannot do. To do so, we analyze normative ethics through the lens of computational complexity. First, we introduce computational complexity for the uninitiated reader and discuss how the complexity of ethical problems can be framed within Marr's three levels of analysis. We then study a range of ethical problems based on consequentialism, deontology, and virtue ethics, with the aim of elucidating the complexity associated with the problems themselves (e.g., due to combinatorics, uncertainty, strategic dynamics), the computational methods employed (e.g., probability, logic, learning), and the available resources (e.g., time, knowledge, learning). The results indicate that most problems the normative frameworks pose lead to tractability issues in every category analyzed. Our investigation also provides several insights about the computational nature of normative ethics, including the differences between rule- and outcome-based moral strategies, and the implementation-variance with regard to moral resources. We then discuss the consequences complexity results have for the prospect of moral machines in virtue of the trade-off between optimality and efficiency. Finally, we elucidate how computational complexity can be used to inform both philosophical and cognitive-psychological research on human morality by advancing the Moral Tractability Thesis (MTT).
The XPRESS Challenge: Xray Projectomic Reconstruction -- Extracting Segmentation with Skeletons
Feb 08, 2023
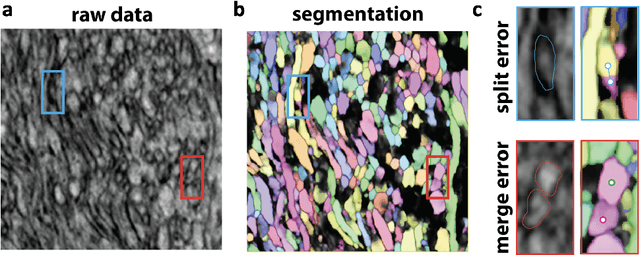
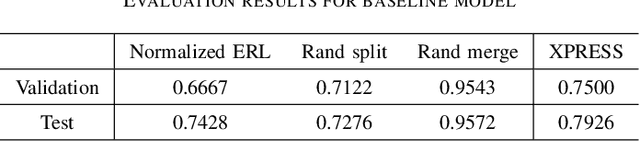

The wiring and connectivity of neurons form a structural basis for the function of the nervous system. Advances in volume electron microscopy (EM) and image segmentation have enabled mapping of circuit diagrams (connectomics) within local regions of the mouse brain. However, applying volume EM over the whole brain is not currently feasible due to technological challenges. As a result, comprehensive maps of long-range connections between brain regions are lacking. Recently, we demonstrated that X-ray holographic nanotomography (XNH) can provide high-resolution images of brain tissue at a much larger scale than EM. In particular, XNH is wellsuited to resolve large, myelinated axon tracts (white matter) that make up the bulk of long-range connections (projections) and are critical for inter-region communication. Thus, XNH provides an imaging solution for brain-wide projectomics. However, because XNH data is typically collected at lower resolutions and larger fields-of-view than EM, accurate segmentation of XNH images remains an important challenge that we present here. In this task, we provide volumetric XNH images of cortical white matter axons from the mouse brain along with ground truth annotations for axon trajectories. Manual voxel-wise annotation of ground truth is a time-consuming bottleneck for training segmentation networks. On the other hand, skeleton-based ground truth is much faster to annotate, and sufficient to determine connectivity. Therefore, we encourage participants to develop methods to leverage skeleton-based training. To this end, we provide two types of ground-truth annotations: a small volume of voxel-wise annotations and a larger volume with skeleton-based annotations. Entries will be evaluated on how accurately the submitted segmentations agree with the ground-truth skeleton annotations.