 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-modal Detection System for Infrastructure-based Freight Signal Priority
Feb 19, 2026Freight vehicles approaching signalized intersections require reliable detection and motion estimation to support infrastructure-based Freight Signal Priority (FSP). Accurate and timely perception of vehicle type, position, and speed is essential for enabling effective priority control strategies. This paper presents the design, deployment, and evaluation of an infrastructure-based multi-modal freight vehicle detection system integrating LiDAR and camera sensors. A hybrid sensing architecture is adopted, consisting of an intersection-mounted subsystem and a midblock subsystem, connected via wireless communication for synchronized data transmission. The perception pipeline incorporates both clustering-based and deep learning-based detection methods with Kalman filter tracking to achieve stable real-time performance. LiDAR measurements are registered into geodetic reference frames to support lane-level localization and consistent vehicle tracking. Field evaluations demonstrate that the system can reliably monitor freight vehicle movements at high spatio-temporal resolution. The design and deployment provide practical insights for developing infrastructure-based sensing systems to support FSP applications.
Enhancing LLM-Based Data Annotation with Error Decomposition
Jan 17, 2026Large language models offer a scalable alternative to human coding for data annotation tasks, enabling the scale-up of research across data-intensive domains. While LLMs are already achieving near-human accuracy on objective annotation tasks, their performance on subjective annotation tasks, such as those involving psychological constructs, is less consistent and more prone to errors. Standard evaluation practices typically collapse all annotation errors into a single alignment metric, but this simplified approach may obscure different kinds of errors that affect final analytical conclusions in different ways. Here, we propose a diagnostic evaluation paradigm that incorporates a human-in-the-loop step to separate task-inherent ambiguity from model-driven inaccuracies and assess annotation quality in terms of their potential downstream impacts. We refine this paradigm on ordinal annotation tasks, which are common in subjective annotation. The refined paradigm includes: (1) a diagnostic taxonomy that categorizes LLM annotation errors along two dimensions: source (model-specific vs. task-inherent) and type (boundary ambiguity vs. conceptual misidentification); (2) a lightweight human annotation test to estimate task-inherent ambiguity from LLM annotations; and (3) a computational method to decompose observed LLM annotation errors following our taxonomy. We validate this paradigm on four educational annotation tasks, demonstrating both its conceptual validity and practical utility. Theoretically, our work provides empirical evidence for why excessively high alignment is unrealistic in specific annotation tasks and why single alignment metrics inadequately reflect the quality of LLM annotations. In practice, our paradigm can be a low-cost diagnostic tool that assesses the suitability of a given task for LLM annotation and provides actionable insights for further technical optimization.
Bottom-Up Synthesis of Knowledge-Grounded Task-Oriented Dialogues with Iteratively Self-Refined Prompts
Apr 19, 2025Training conversational question-answering (QA) systems requires a substantial amount of in-domain data, which is often scarce in practice. A common solution to this challenge is to generate synthetic data. Traditional methods typically follow a top-down approach, where a large language model (LLM) generates multi-turn dialogues from a broad prompt. Although this method produces coherent conversations, it offers limited fine-grained control over the content and is susceptible to hallucinations. We introduce a bottom-up conversation synthesis approach, where QA pairs are generated first and then combined into a coherent dialogue. This method offers greater control and precision by dividing the process into two distinct steps, allowing refined instructions and validations to be handled separately. Additionally, this structure allows the use of non-local models in stages that do not involve proprietary knowledge, enhancing the overall quality of the generated data. Both human and automated evaluations demonstrate that our approach produces more realistic and higher-quality dialogues compared to top-down methods.
PDB: Not All Drivers Are the Same -- A Personalized Dataset for Understanding Driving Behavior
Mar 09, 2025


Driving behavior is inherently personal, influenced by individual habits, decision-making styles, and physiological states. However, most existing datasets treat all drivers as homogeneous, overlooking driver-specific variability. To address this gap, we introduce the Personalized Driving Behavior (PDB) dataset, a multi-modal dataset designed to capture personalization in driving behavior under naturalistic driving conditions. Unlike conventional datasets, PDB minimizes external influences by maintaining consistent routes, vehicles, and lighting conditions across sessions. It includes sources from 128-line LiDAR, front-facing camera video, GNSS, 9-axis IMU, CAN bus data (throttle, brake, steering angle), and driver-specific signals such as facial video and heart rate. The dataset features 12 participants, approximately 270,000 LiDAR frames, 1.6 million images, and 6.6 TB of raw sensor data. The processed trajectory dataset consists of 1,669 segments, each spanning 10 seconds with a 0.2-second interval. By explicitly capturing drivers' behavior, PDB serves as a unique resource for human factor analysis, driver identification, and personalized mobility applications, contributing to the development of human-centric intelligent transportation systems.
Investigating Personalized Driving Behaviors in Dilemma Zones: Analysis and Prediction of Stop-or-Go Decisions
May 06, 2024Dilemma zones at signalized intersections present a commonly occurring but unsolved challenge for both drivers and traffic operators. Onsets of the yellow lights prompt varied responses from different drivers: some may brake abruptly, compromising the ride comfort, while others may accelerate, increasing the risk of red-light violations and potential safety hazards. Such diversity in drivers' stop-or-go decisions may result from not only surrounding traffic conditions, but also personalized driving behaviors. To this end, identifying personalized driving behaviors and integrating them into advanced driver assistance systems (ADAS) to mitigate the dilemma zone problem presents an intriguing scientific question. In this study, we employ a game engine-based (i.e., CARLA-enabled) driving simulator to collect high-resolution vehicle trajectories, incoming traffic signal phase and timing information, and stop-or-go decisions from four subject drivers in various scenarios. This approach allows us to analyze personalized driving behaviors in dilemma zones and develop a Personalized Transformer Encoder to predict individual drivers' stop-or-go decisions. The results show that the Personalized Transformer Encoder improves the accuracy of predicting driver decision-making in the dilemma zone by 3.7% to 12.6% compared to the Generic Transformer Encoder, and by 16.8% to 21.6% over the binary logistic regression model.
Benchmarking and Improving Generator-Validator Consistency of Language Models
Oct 03, 2023As of September 2023, ChatGPT correctly answers "what is 7+8" with 15, but when asked "7+8=15, True or False" it responds with "False". This inconsistency between generating and validating an answer is prevalent in language models (LMs) and erodes trust. In this paper, we propose a framework for measuring the consistency between generation and validation (which we call generator-validator consistency, or GV-consistency), finding that even GPT-4, a state-of-the-art LM, is GV-consistent only 76% of the time. To improve the consistency of LMs, we propose to finetune on the filtered generator and validator responses that are GV-consistent, and call this approach consistency fine-tuning. We find that this approach improves GV-consistency of Alpaca-30B from 60% to 93%, and the improvement extrapolates to unseen tasks and domains (e.g., GV-consistency for positive style transfers extrapolates to unseen styles like humor). In addition to improving consistency, consistency fine-tuning improves both generator quality and validator accuracy without using any labeled data. Evaluated across 6 tasks, including math questions, knowledge-intensive QA, and instruction following, our method improves the generator quality by 16% and the validator accuracy by 6.3% across all tasks.
Color Me Intrigued: Quantifying Usage of Colors in Fiction
Jan 09, 2023



We present preliminary results in quantitative analyses of color usage in selected authors' works from LitBank. Using Glasgow Norms, human ratings on 5000+ words, we measure attributes of nouns dependent on color terms. Early results demonstrate a significant increase in noun concreteness over time. We also propose future research directions for computational literary color analytics.
Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference
Nov 21, 2022



While large pre-trained language models are powerful, their predictions often lack logical consistency across test inputs. For example, a state-of-the-art Macaw question-answering (QA) model answers 'Yes' to 'Is a sparrow a bird?' and 'Does a bird have feet?' but answers 'No' to 'Does a sparrow have feet?'. To address this failure mode, we propose a framework, Consistency Correction through Relation Detection, or ConCoRD, for boosting the consistency and accuracy of pre-trained NLP models using pre-trained natural language inference (NLI) models without fine-tuning or re-training. Given a batch of test inputs, ConCoRD samples several candidate outputs for each input and instantiates a factor graph that accounts for both the model's belief about the likelihood of each answer choice in isolation and the NLI model's beliefs about pair-wise answer choice compatibility. We show that a weighted MaxSAT solver can efficiently compute high-quality answer choices under this factor graph, improving over the raw model's predictions. Our experiments demonstrate that ConCoRD consistently boosts accuracy and consistency of off-the-shelf closed-book QA and VQA models using off-the-shelf NLI models, notably increasing accuracy of LXMERT on ConVQA by 5% absolute. See https://ericmitchell.ai/emnlp-2022-concord/ for code and data.
Systematicity in GPT-3's Interpretation of Novel English Noun Compounds
Oct 18, 2022
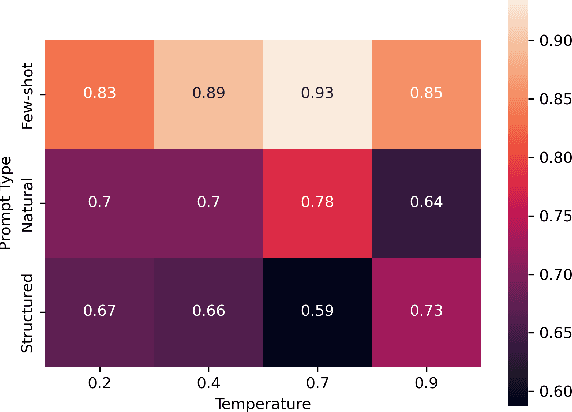
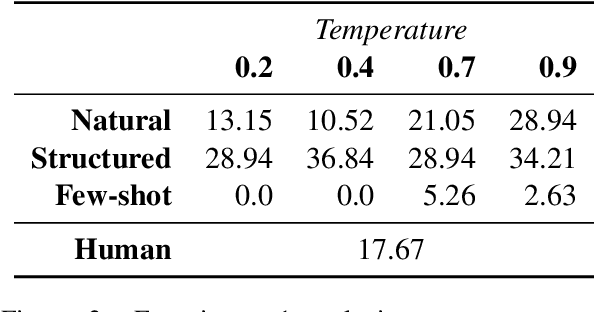
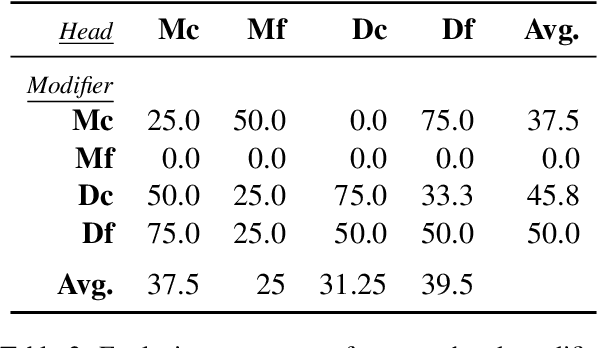
Levin et al. (2019) show experimentally that the interpretations of novel English noun compounds (e.g., stew skillet), while not fully compositional, are highly predictable based on whether the modifier and head refer to artifacts or natural kinds. Is the large language model GPT-3 governed by the same interpretive principles? To address this question, we first compare Levin et al.'s experimental data with GPT-3 generations, finding a high degree of similarity. However, this evidence is consistent with GPT3 reasoning only about specific lexical items rather than the more abstract conceptual categories of Levin et al.'s theory. To probe more deeply, we construct prompts that require the relevant kind of conceptual reasoning. Here, we fail to find convincing evidence that GPT-3 is reasoning about more than just individual lexical items. These results highlight the importance of controlling for low-level distributional regularities when assessing whether a large language model latently encodes a deeper theory.
When can I Speak? Predicting initiation points for spoken dialogue agents
Aug 07, 2022



Current spoken dialogue systems initiate their turns after a long period of silence (700-1000ms), which leads to little real-time feedback, sluggish responses, and an overall stilted conversational flow. Humans typically respond within 200ms and successfully predicting initiation points in advance would allow spoken dialogue agents to do the same. In this work, we predict the lead-time to initiation using prosodic features from a pre-trained speech representation model (wav2vec 1.0) operating on user audio and word features from a pre-trained language model (GPT-2) operating on incremental transcriptions. To evaluate errors, we propose two metrics w.r.t. predicted and true lead times. We train and evaluate the models on the Switchboard Corpus and find that our method outperforms features from prior work on both metrics and vastly outperforms the common approach of waiting for 700ms of silence.