 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PDFormer: Propagation Delay-aware Dynamic Long-range Transformer for Traffic Flow Prediction
Jan 19, 2023
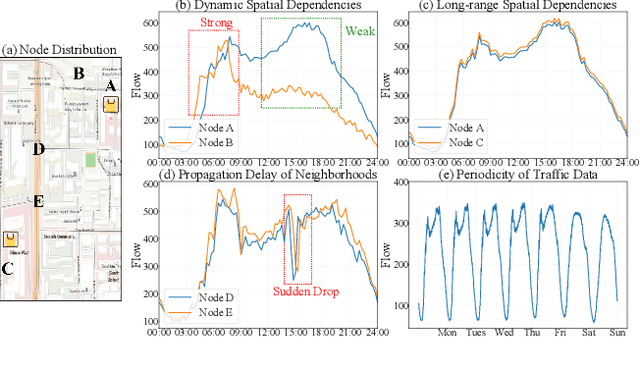
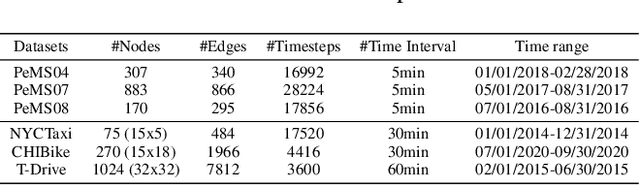
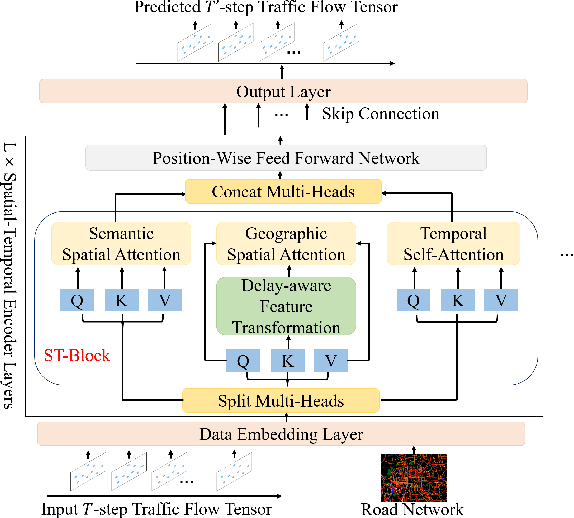
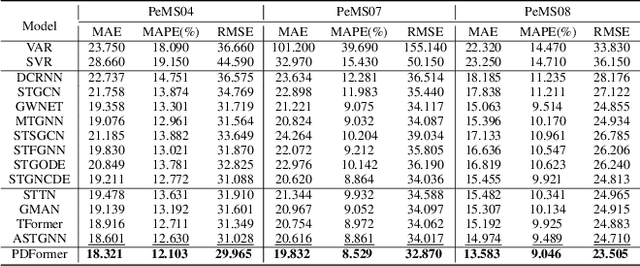
As a core technology of Intelligent Transportation System, traffic flow prediction has a wide range of applications. The fundamental challenge in traffic flow prediction is to effectively model the complex spatial-temporal dependencies in traffic data. Spatial-temporal Graph Neural Network (GNN) models have emerged as one of the most promising methods to solve this problem. However, GNN-based models have three major limitations for traffic prediction: i) Most methods model spatial dependencies in a static manner, which limits the ability to learn dynamic urban traffic patterns; ii) Most methods only consider short-range spatial information and are unable to capture long-range spatial dependencies; iii) These methods ignore the fact that the propagation of traffic conditions between locations has a time delay in traffic systems. To this end, we propose a novel Propagation Delay-aware dynamic long-range transFormer, namely PDFormer, for accurate traffic flow prediction. Specifically, we design a spatial self-attention module to capture the dynamic spatial dependencies. Then, two graph masking matrices are introduced to highlight spatial dependencies from short- and long-range views. Moreover, a traffic delay-aware feature transformation module is proposed to empower PDFormer with the capability of explicitly modeling the time delay of spatial information propagation. Extensive experimental results on six real-world public traffic datasets show that our method can not only achieve state-of-the-art performance but also exhibit competitive computational efficiency. Moreover, we visualize the learned spatial-temporal attention map to make our model highly interpretable.
Utilizing Expert Features for Contrastive Learning of Time-Series Representations
Jun 23, 2022
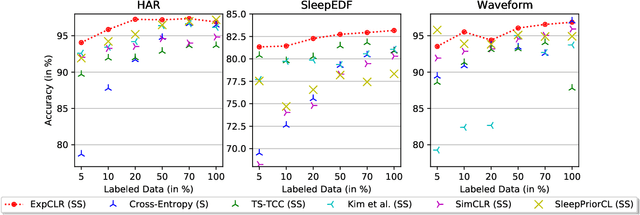
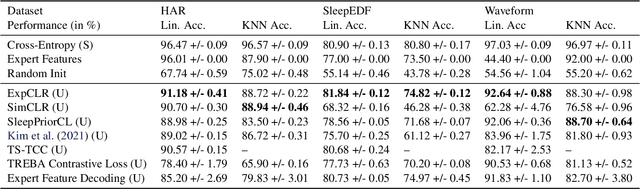
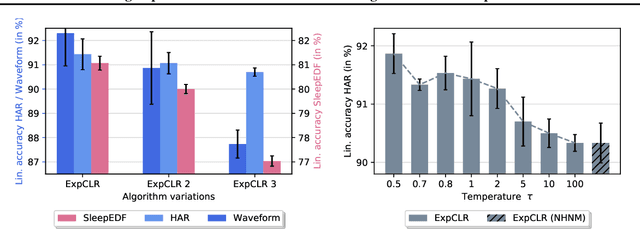
We present an approach that incorporates expert knowledge for time-series representation learning. Our method employs expert features to replace the commonly used data transformations in previous contrastive learning approaches. We do this since time-series data frequently stems from the industrial or medical field where expert features are often available from domain experts, while transformations are generally elusive for time-series data. We start by proposing two properties that useful time-series representations should fulfill and show that current representation learning approaches do not ensure these properties. We therefore devise ExpCLR, a novel contrastive learning approach built on an objective that utilizes expert features to encourage both properties for the learned representation. Finally, we demonstrate on three real-world time-series datasets that ExpCLR surpasses several state-of-the-art methods for both unsupervised and semi-supervised representation learning.
Sequential Graph Attention Learning for Predicting Dynamic Stock Trends (Student Abstract)
Jan 15, 2023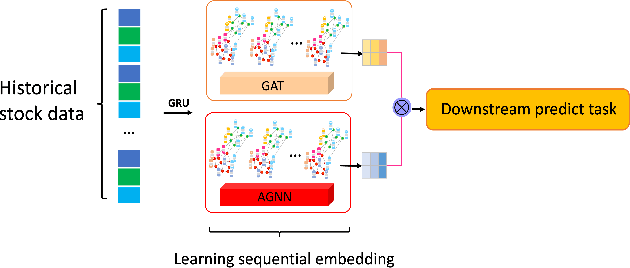
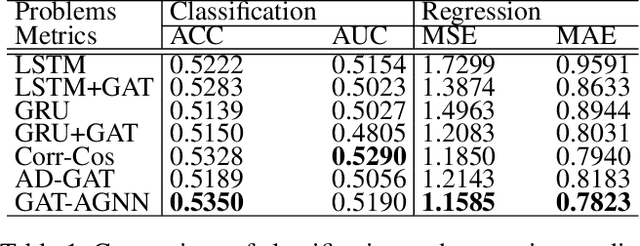

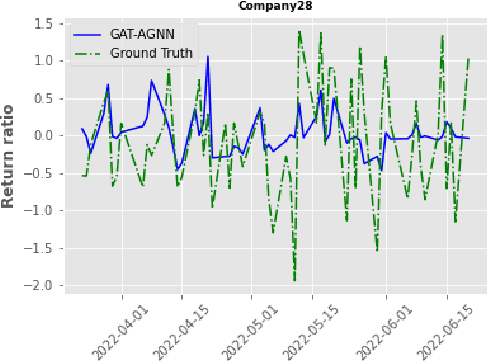
The stock market is characterized by a complex relationship between companies and the market. This study combines a sequential graph structure with attention mechanisms to learn global and local information within temporal time. Specifically, our proposed "GAT-AGNN" module compares model performance across multiple industries as well as within single industries. The results show that the proposed framework outperforms the state-of-the-art methods in predicting stock trends across multiple industries on Taiwan Stock datasets.
Generalizable Memory-driven Transformer for Multivariate Long Sequence Time-series Forecasting
Jul 16, 2022
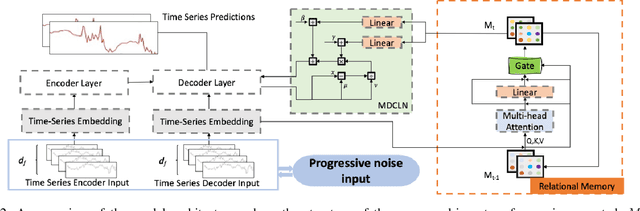
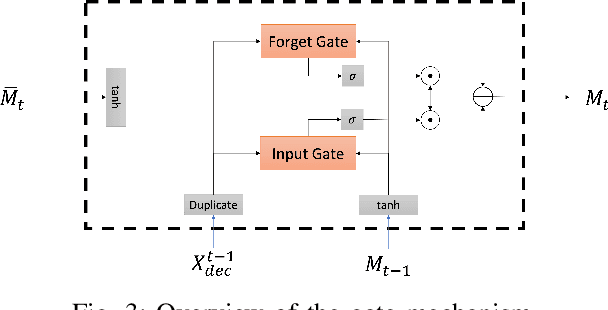
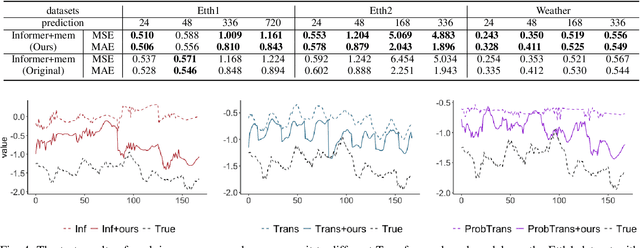
Multivariate long sequence time-series forecasting (M-LSTF) is a practical but challenging problem. Unlike traditional timer-series forecasting tasks, M-LSTF tasks are more challenging from two aspects: 1) M-LSTF models need to learn time-series patterns both within and between multiple time features; 2) Under the rolling forecasting setting, the similarity between two consecutive training samples increases with the increasing prediction length, which makes models more prone to overfitting. In this paper, we propose a generalizable memory-driven Transformer to target M-LSTF problems. Specifically, we first propose a global-level memory component to drive the forecasting procedure by integrating multiple time-series features. In addition, we adopt a progressive fashion to train our model to increase its generalizability, in which we gradually introduce Bernoulli noises to training samples. Extensive experiments have been performed on five different datasets across multiple fields. Experimental results demonstrate that our approach can be seamlessly plugged into varying Transformer-based models to improve their performances up to roughly 30%. Particularly, this is the first work to specifically focus on the M-LSTF tasks to the best of our knowledge.
Discovering and Explaining Driver Behaviour under HoS Regulations
Jan 12, 2023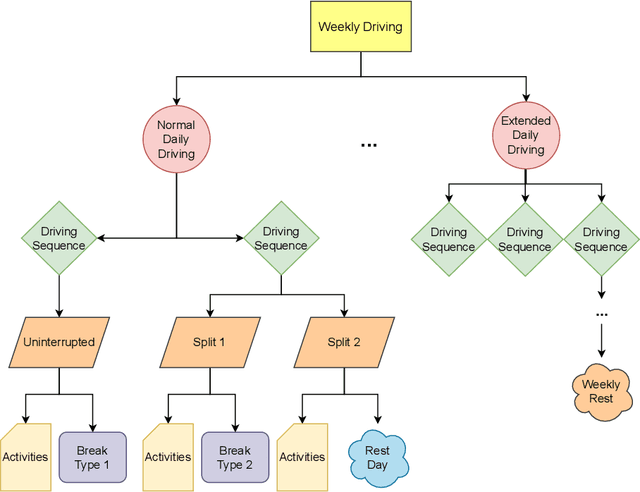
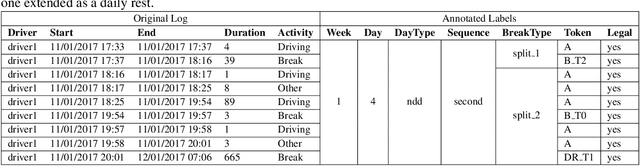


World wide transport authorities are imposing complex Hours of Service regulations to drivers, which constraint the amount of working, driving and resting time when delivering a service. As a consequence, transport companies are responsible not only of scheduling driving plans aligned with laws that define the legal behaviour of a driver, but also of monitoring and identifying as soon as possible problematic patterns that can incur in costs due to sanctions. Transport experts are frequently in charge of many drivers and lack time to analyse the vast amount of data recorded by the onboard sensors, and companies have grown accustomed to pay sanctions rather than predict and forestall wrongdoings. This paper exposes an application for summarising raw driver activity logs according to these regulations and for explaining driver behaviour in a human readable format. The system employs planning, constraint, and clustering techniques to extract and describe what the driver has been doing while identifying infractions and the activities that originate them. Furthermore, it groups drivers based on similar driving patterns. An experimentation in real world data indicates that recurring driving patterns can be clustered from short basic driving sequences to whole drivers working days.
Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning
Jan 27, 2023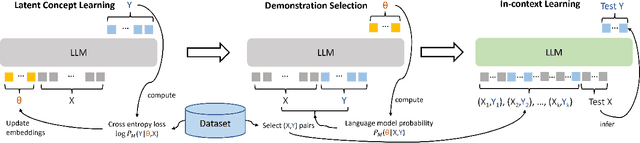
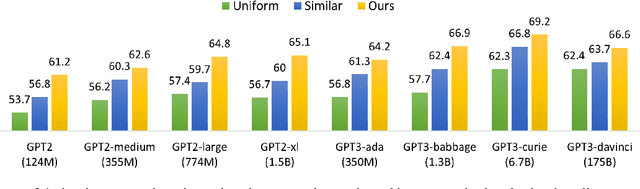
In recent years, pre-trained large language models have demonstrated remarkable efficiency in achieving an inference-time few-shot learning capability known as in-context learning. However, existing literature has highlighted the sensitivity of this capability to the selection of few-shot demonstrations. The underlying mechanisms by which this capability arises from regular language model pretraining objectives remain poorly understood. In this study, we aim to examine the in-context learning phenomenon through a Bayesian lens, viewing large language models as topic models that implicitly infer task-related information from demonstrations. On this premise, we propose an algorithm for selecting optimal demonstrations from a set of annotated data and demonstrate a significant 12.5% improvement relative to the random selection baseline, averaged over eight GPT2 and GPT3 models on eight different real-world text classification datasets. Our empirical findings support our hypothesis that large language models implicitly infer a latent concept variable.
Byte Pair Encoding for Symbolic Music
Jan 27, 2023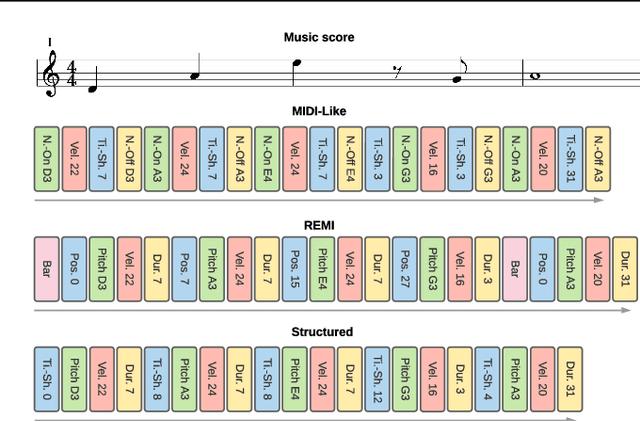
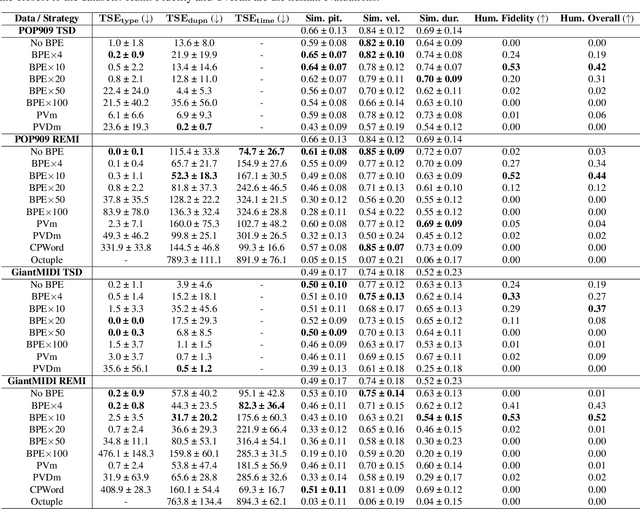
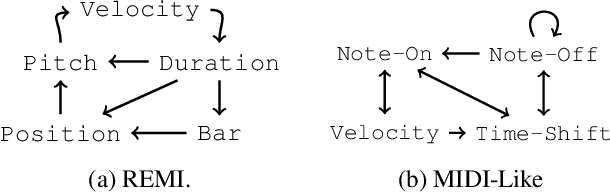
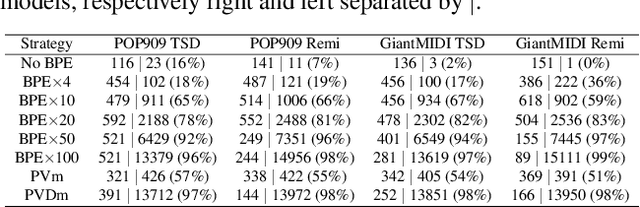
The symbolic music modality is nowadays mostly represented as discrete and used with sequential models such as Transformers, for deep learning tasks. Recent research put efforts on the tokenization, i.e. the conversion of data into sequences of integers intelligible to such models. This can be achieved by many ways as music can be composed of simultaneous tracks, of simultaneous notes with several attributes. Until now, the proposed tokenizations are based on small vocabularies describing the note attributes and time events, resulting in fairly long token sequences. In this paper, we show how Byte Pair Encoding (BPE) can improve the results of deep learning models while improving its performances. We experiment on music generation and composer classification, and study the impact of BPE on how models learn the embeddings, and show that it can help to increase their isotropy, i.e., the uniformity of the variance of their positions in the space.
PyGlove: Efficiently Exchanging ML Ideas as Code
Feb 03, 2023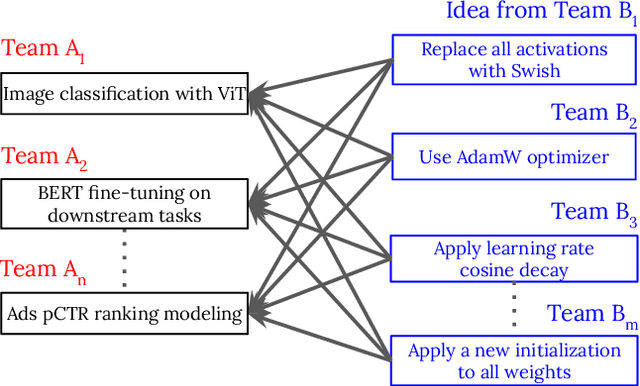



The increasing complexity and scale of machine learning (ML) has led to the need for more efficient collaboration among multiple teams. For example, when a research team invents a new architecture like "ResNet," it is desirable for multiple engineering teams to adopt it. However, the effort required for each team to study and understand the invention does not scale well with the number of teams or inventions. In this paper, we present an extension of our PyGlove library to easily and scalably share ML ideas. PyGlove represents ideas as symbolic rule-based patches, enabling researchers to write down the rules for models they have not seen. For example, an inventor can write rules that will "add skip-connections." This permits a network effect among teams: at once, any team can issue patches to all other teams. Such a network effect allows users to quickly surmount the cost of adopting PyGlove by writing less code quicker, providing a benefit that scales with time. We describe the new paradigm of organizing ML through symbolic patches and compare it to existing approaches. We also perform a case study of a large codebase where PyGlove led to an 80% reduction in the number of lines of code.
SCCAM: Supervised Contrastive Convolutional Attention Mechanism for Ante-hoc Interpretable Fault Diagnosis with Limited Fault Samples
Feb 03, 2023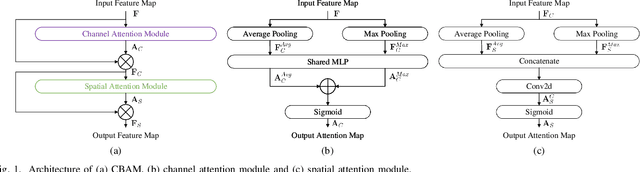

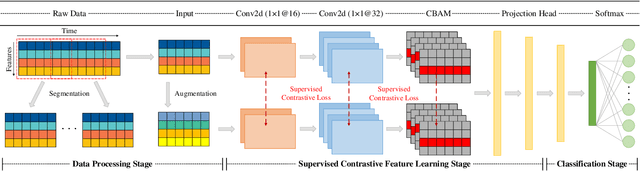
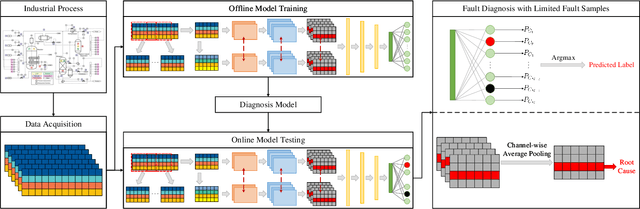
In real industrial processes, fault diagnosis methods are required to learn from limited fault samples since the procedures are mainly under normal conditions and the faults rarely occur. Although attention mechanisms have become popular in the field of fault diagnosis, the existing attention-based methods are still unsatisfying for the above practical applications. First, pure attention-based architectures like transformers need a large number of fault samples to offset the lack of inductive biases thus performing poorly under limited fault samples. Moreover, the poor fault classification dilemma further leads to the failure of the existing attention-based methods to identify the root causes. To address the aforementioned issues, we innovatively propose a supervised contrastive convolutional attention mechanism (SCCAM) with ante-hoc interpretability, which solves the root cause analysis problem under limited fault samples for the first time. The proposed SCCAM method is tested on a continuous stirred tank heater and the Tennessee Eastman industrial process benchmark. Three common fault diagnosis scenarios are covered, including a balanced scenario for additional verification and two scenarios with limited fault samples (i.e., imbalanced scenario and long-tail scenario). The comprehensive results demonstrate that the proposed SCCAM method can achieve better performance compared with the state-of-the-art methods on fault classification and root cause analysis.
GRU-TV: Time- and velocity-aware GRU for patient representation on multivariate clinical time-series data
May 04, 2022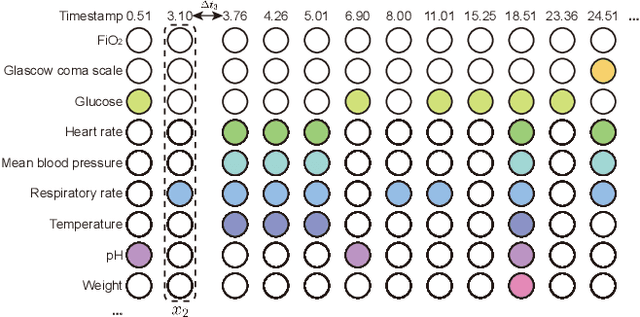
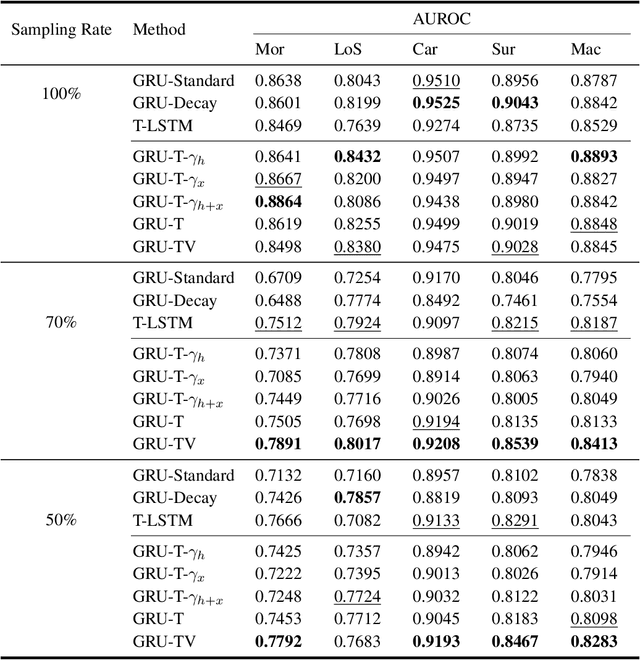
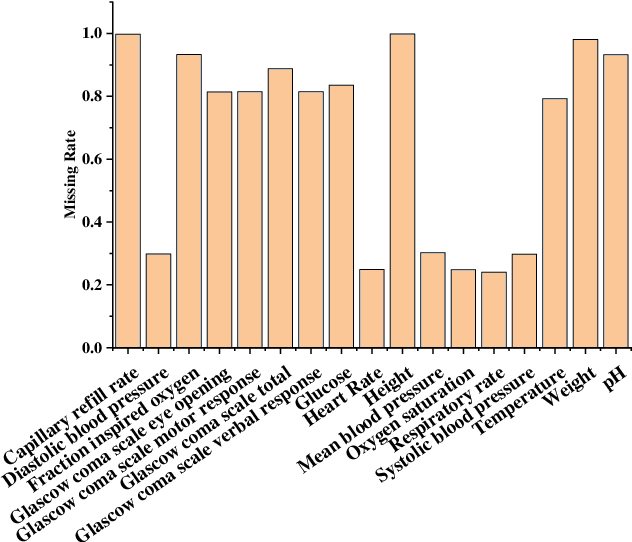
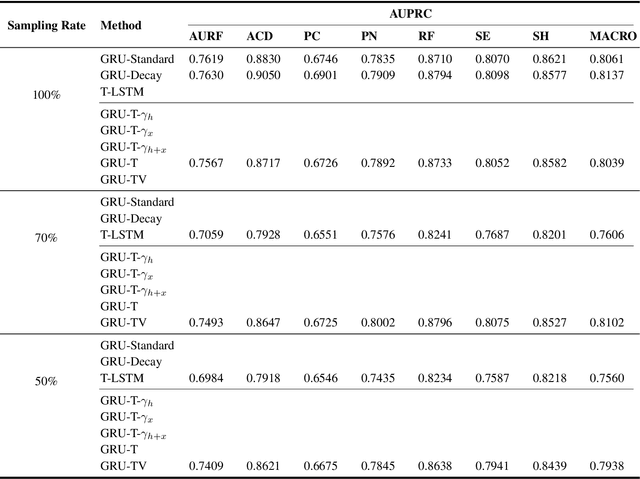
Electronic health records (EHRs) provide a rich repository to track a patient's health status. EHRs seek to fully document the patient's physiological status, and include data that is is high dimensional, heterogeneous, and multimodal. The significant differences in the sampling frequency of clinical variables can result in high missing rates and uneven time intervals between adjacent records in the multivariate clinical time-series data extracted from EHRs. Current studies using clinical time-series data for patient characterization view the patient's physiological status as a discrete process described by sporadically collected values, while the dynamics in patient's physiological status are time-continuous. In addition, recurrent neural networks (RNNs) models widely used for patient representation learning lack the perception of time intervals and velocity, which limits the ability of the model to represent the physiological status of the patient. In this paper, we propose an improved gated recurrent unit (GRU), namely time- and velocity-aware GRU (GRU-TV), for patient representation learning of clinical multivariate time-series data in a time-continuous manner. In proposed GRU-TV, the neural ordinary differential equations (ODEs) and velocity perception mechanism are used to perceive the time interval between records in the time-series data and changing rate of the patient's physiological status, respectively. Experimental results on two real-world clinical EHR datasets(PhysioNet2012, MIMIC-III) show that GRU-TV achieve state-of-the-art performance in computer aided diagnosis (CAD) tasks, and is more advantageous in processing sampled data.