 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
Mar 15, 2024
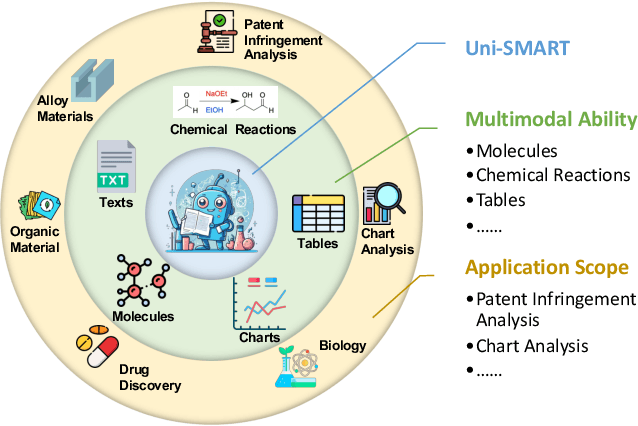
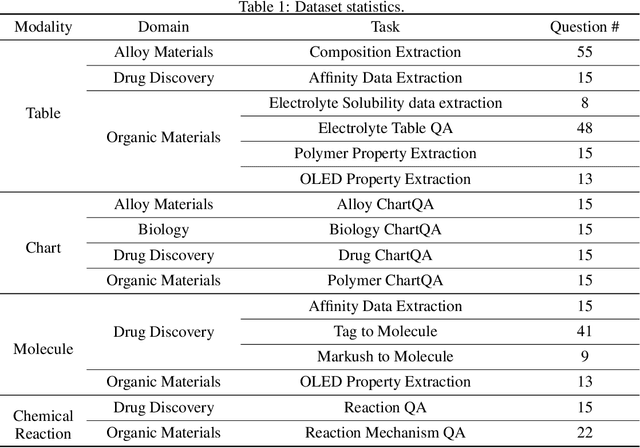
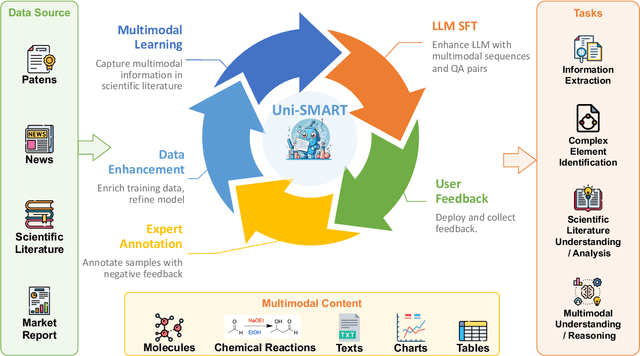
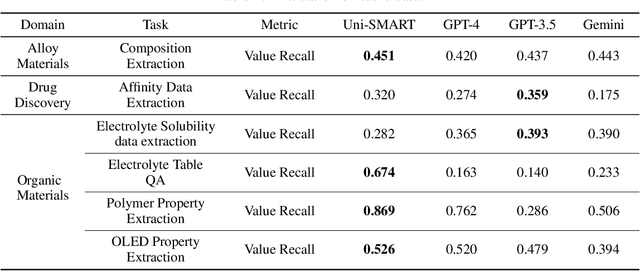
In scientific research and its application, scientific literature analysis is crucial as it allows researchers to build on the work of others. However, the fast growth of scientific knowledge has led to a massive increase in scholarly articles, making in-depth literature analysis increasingly challenging and time-consuming. The emergence of Large Language Models (LLMs) has offered a new way to address this challenge. Known for their strong abilities in summarizing texts, LLMs are seen as a potential tool to improve the analysis of scientific literature. However, existing LLMs have their own limits. Scientific literature often includes a wide range of multimodal elements, such as molecular structure, tables, and charts, which are hard for text-focused LLMs to understand and analyze. This issue points to the urgent need for new solutions that can fully understand and analyze multimodal content in scientific literature. To answer this demand, we present Uni-SMART (Universal Science Multimodal Analysis and Research Transformer), an innovative model designed for in-depth understanding of multimodal scientific literature. Through rigorous quantitative evaluation across several domains, Uni-SMART demonstrates superior performance over leading text-focused LLMs. Furthermore, our exploration extends to practical applications, including patent infringement detection and nuanced analysis of charts. These applications not only highlight Uni-SMART's adaptability but also its potential to revolutionize how we interact with scientific literature.
An Energy-Efficient Ensemble Approach for Mitigating Data Incompleteness in IoT Applications
Mar 15, 2024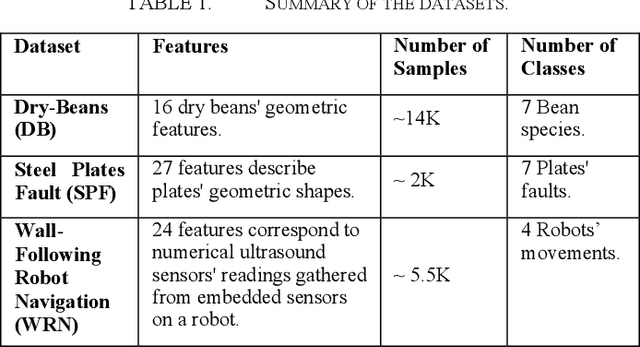

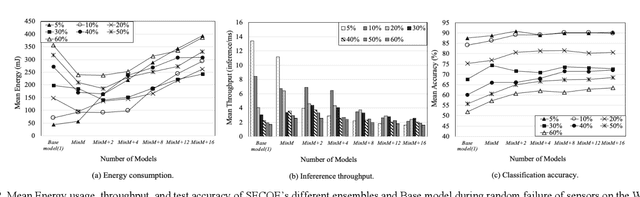
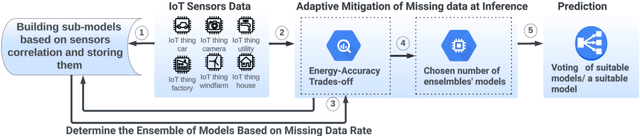
Machine Learning (ML) is becoming increasingly important for IoT-based applications. However, the dynamic and ad-hoc nature of many IoT ecosystems poses unique challenges to the efficacy of ML algorithms. One such challenge is data incompleteness, which is manifested as missing sensor readings. Many factors, including sensor failures and/or network disruption, can cause data incompleteness. Furthermore, most IoT systems are severely power-constrained. It is important that we build IoT-based ML systems that are robust against data incompleteness while simultaneously being energy efficient. This paper presents an empirical study of SECOE - a recent technique for alleviating data incompleteness in IoT - with respect to its energy bottlenecks. Towards addressing the energy bottlenecks of SECOE, we propose ENAMLE - a proactive, energy-aware technique for mitigating the impact of concurrent missing data. ENAMLE is unique in the sense that it builds an energy-aware ensemble of sub-models, each trained with a subset of sensors chosen carefully based on their correlations. Furthermore, at inference time, ENAMLE adaptively alters the number of the ensemble of models based on the amount of missing data rate and the energy-accuracy trade-off. ENAMLE's design includes several novel mechanisms for minimizing energy consumption while maintaining accuracy. We present extensive experimental studies on two distinct datasets that demonstrate the energy efficiency of ENAMLE and its ability to alleviate sensor failures.
Context-Semantic Quality Awareness Network for Fine-Grained Visual Categorization
Mar 15, 2024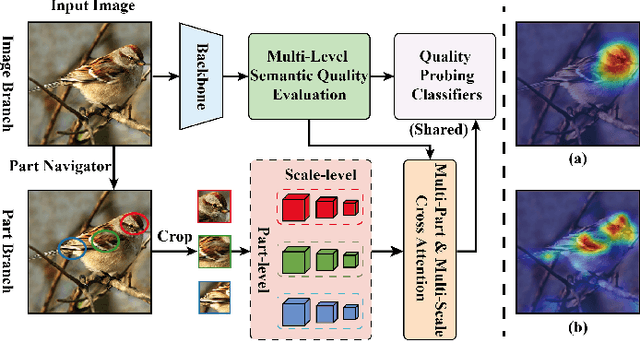
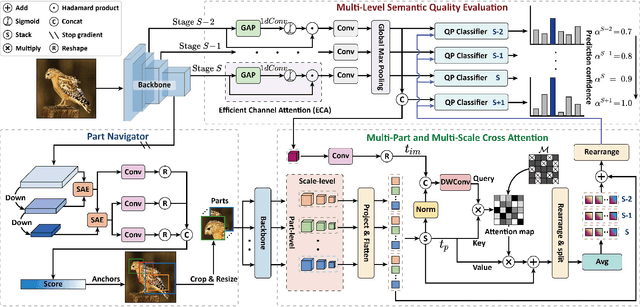
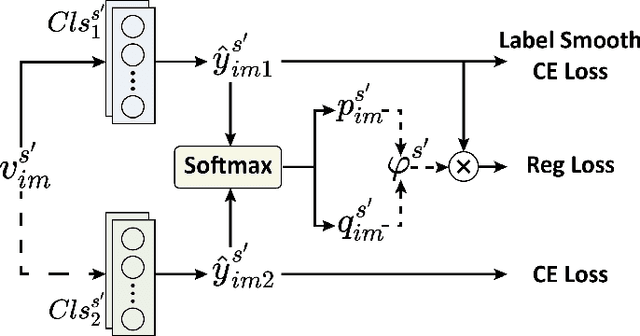
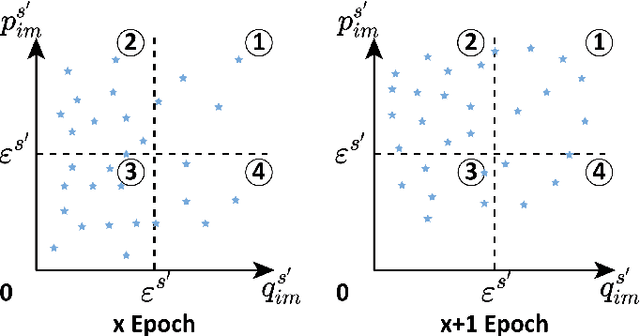
Exploring and mining subtle yet distinctive features between sub-categories with similar appearances is crucial for fine-grained visual categorization (FGVC). However, less effort has been devoted to assessing the quality of extracted visual representations. Intuitively, the network may struggle to capture discriminative features from low-quality samples, which leads to a significant decline in FGVC performance. To tackle this challenge, we propose a weakly supervised Context-Semantic Quality Awareness Network (CSQA-Net) for FGVC. In this network, to model the spatial contextual relationship between rich part descriptors and global semantics for capturing more discriminative details within the object, we design a novel multi-part and multi-scale cross-attention (MPMSCA) module. Before feeding to the MPMSCA module, the part navigator is developed to address the scale confusion problems and accurately identify the local distinctive regions. Furthermore, we propose a generic multi-level semantic quality evaluation module (MLSQE) to progressively supervise and enhance hierarchical semantics from different levels of the backbone network. Finally, context-aware features from MPMSCA and semantically enhanced features from MLSQE are fed into the corresponding quality probing classifiers to evaluate their quality in real-time, thus boosting the discriminability of feature representations. Comprehensive experiments on four popular and highly competitive FGVC datasets demonstrate the superiority of the proposed CSQA-Net in comparison with the state-of-the-art methods.
Angle estimation using mmWave RSS measurements with enhanced multipath information
Mar 14, 2024
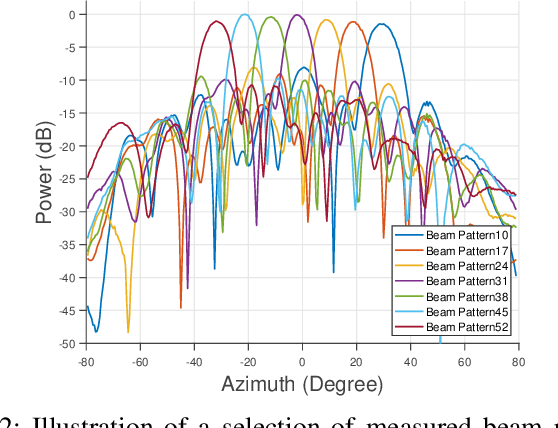
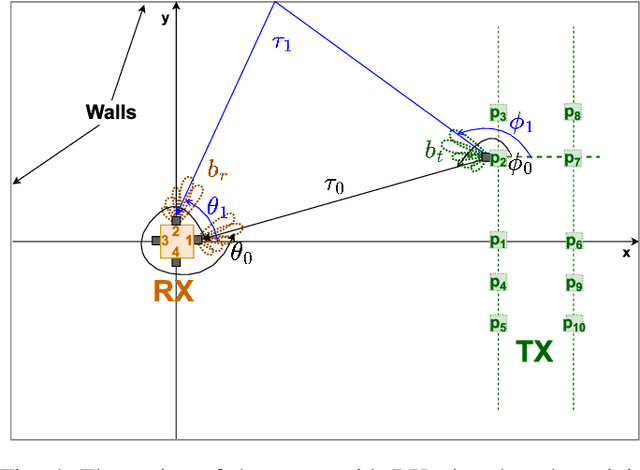
mmWave communication has come up as the unexplored spectrum for 5G services. With new standards for 5G NR positioning, more off-the-shelf platforms and algorithms are needed to perform indoor positioning. An object can be accurately positioned in a room either by using an angle and a delay estimate or two angle estimates or three delay estimates. We propose an algorithm to jointly estimate the angle of arrival (AoA) and angle of departure (AoD), based only on the received signal strength (RSS). We use mm-FLEX, an experimentation platform developed by IMDEA Networks Institute that can perform real-time signal processing for experimental validation of our proposed algorithm. Codebook-based beampatterns are used with a uniquely placed multi-antenna array setup to enhance the reception of multipath components and we obtain an AoA estimate per receiver thereby overcoming the line-of-sight (LoS) limitation of RSS-based localization systems. We further validate the results from measurements by emulating the setup with a simple ray-tracing approach.
Hyper-CL: Conditioning Sentence Representations with Hypernetworks
Mar 14, 2024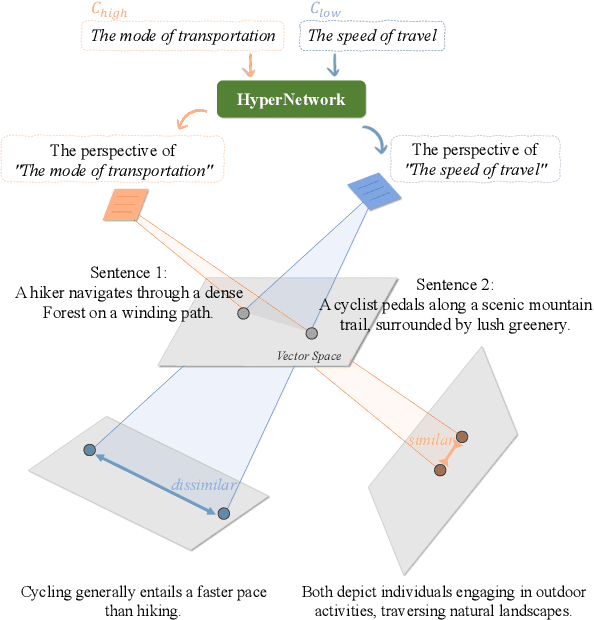
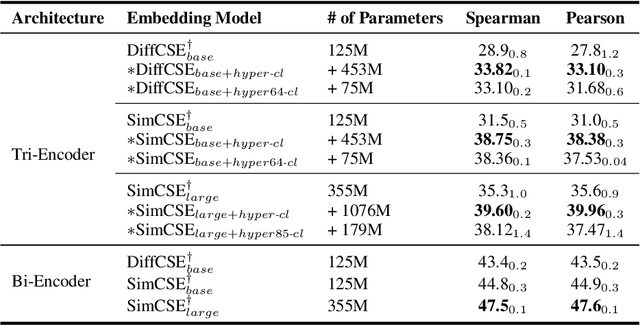
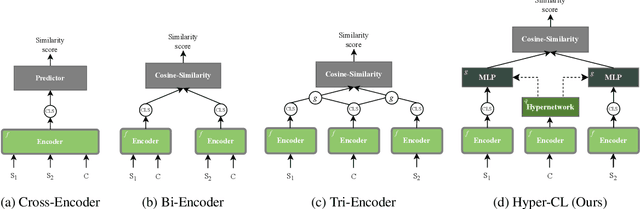
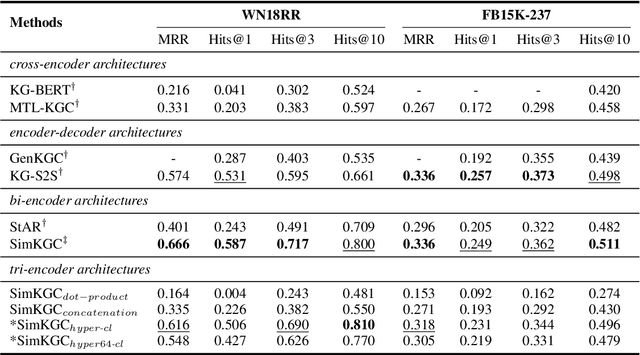
While the introduction of contrastive learning frameworks in sentence representation learning has significantly contributed to advancements in the field, it still remains unclear whether state-of-the-art sentence embeddings can capture the fine-grained semantics of sentences, particularly when conditioned on specific perspectives. In this paper, we introduce Hyper-CL, an efficient methodology that integrates hypernetworks with contrastive learning to compute conditioned sentence representations. In our proposed approach, the hypernetwork is responsible for transforming pre-computed condition embeddings into corresponding projection layers. This enables the same sentence embeddings to be projected differently according to various conditions. Evaluation on two representative conditioning benchmarks, namely conditional semantic text similarity and knowledge graph completion, demonstrates that Hyper-CL is effective in flexibly conditioning sentence representations, showcasing its computational efficiency at the same time. We also provide a comprehensive analysis of the inner workings of our approach, leading to a better interpretation of its mechanisms.
PaperBot: Learning to Design Real-World Tools Using Paper
Mar 14, 2024


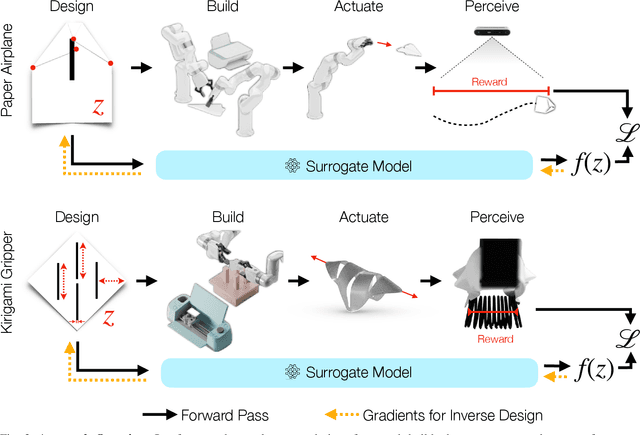
Paper is a cheap, recyclable, and clean material that is often used to make practical tools. Traditional tool design either relies on simulation or physical analysis, which is often inaccurate and time-consuming. In this paper, we propose PaperBot, an approach that directly learns to design and use a tool in the real world using paper without human intervention. We demonstrated the effectiveness and efficiency of PaperBot on two tool design tasks: 1. learning to fold and throw paper airplanes for maximum travel distance 2. learning to cut paper into grippers that exert maximum gripping force. We present a self-supervised learning framework that learns to perform a sequence of folding, cutting, and dynamic manipulation actions in order to optimize the design and use of a tool. We deploy our system to a real-world two-arm robotic system to solve challenging design tasks that involve aerodynamics (paper airplane) and friction (paper gripper) that are impossible to simulate accurately.
Leap: molecular synthesisability scoring with intermediates
Mar 14, 2024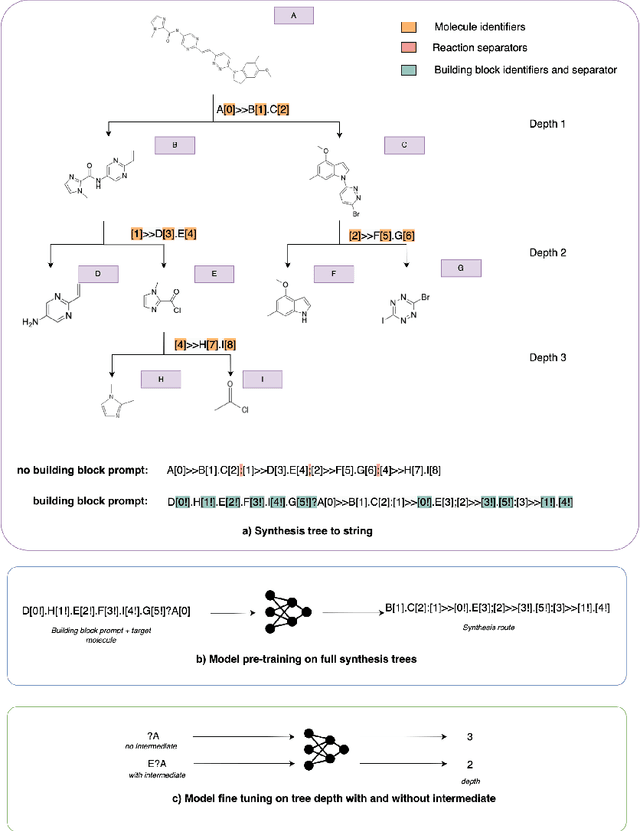
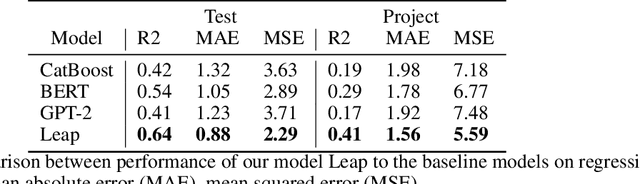
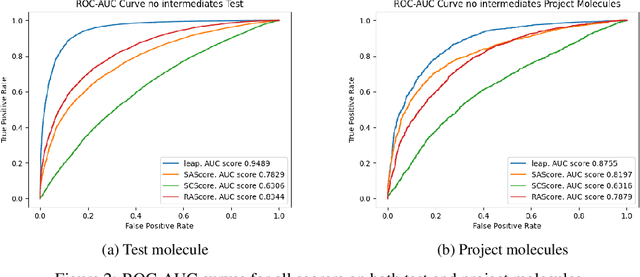
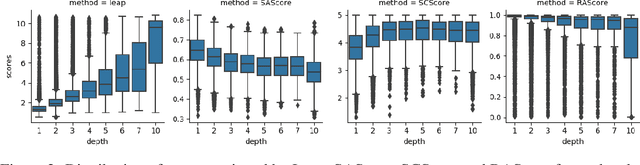
Assessing whether a molecule can be synthesised is a primary task in drug discovery. It enables computational chemists to filter for viable compounds or bias molecular generative models. The notion of synthesisability is dynamic as it evolves depending on the availability of key compounds. A common approach in drug discovery involves exploring the chemical space surrounding synthetically-accessible intermediates. This strategy improves the synthesisability of the derived molecules due to the availability of key intermediates. Existing synthesisability scoring methods such as SAScore, SCScore and RAScore, cannot condition on intermediates dynamically. Our approach, Leap, is a GPT-2 model trained on the depth, or longest linear path, of predicted synthesis routes that allows information on the availability of key intermediates to be included at inference time. We show that Leap surpasses all other scoring methods by at least 5% on AUC score when identifying synthesisable molecules, and can successfully adapt predicted scores when presented with a relevant intermediate compound.
StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting
Mar 12, 2024
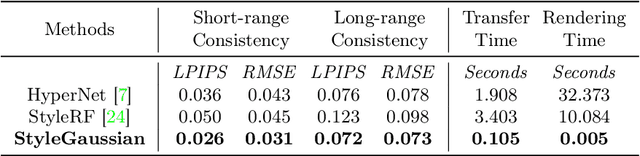

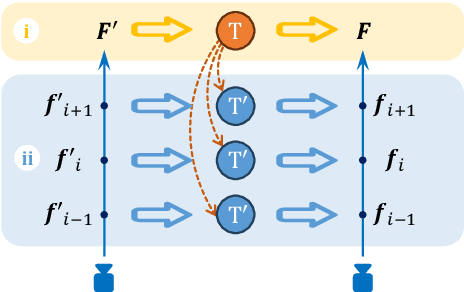
We introduce StyleGaussian, a novel 3D style transfer technique that allows instant transfer of any image's style to a 3D scene at 10 frames per second (fps). Leveraging 3D Gaussian Splatting (3DGS), StyleGaussian achieves style transfer without compromising its real-time rendering ability and multi-view consistency. It achieves instant style transfer with three steps: embedding, transfer, and decoding. Initially, 2D VGG scene features are embedded into reconstructed 3D Gaussians. Next, the embedded features are transformed according to a reference style image. Finally, the transformed features are decoded into the stylized RGB. StyleGaussian has two novel designs. The first is an efficient feature rendering strategy that first renders low-dimensional features and then maps them into high-dimensional features while embedding VGG features. It cuts the memory consumption significantly and enables 3DGS to render the high-dimensional memory-intensive features. The second is a K-nearest-neighbor-based 3D CNN. Working as the decoder for the stylized features, it eliminates the 2D CNN operations that compromise strict multi-view consistency. Extensive experiments show that StyleGaussian achieves instant 3D stylization with superior stylization quality while preserving real-time rendering and strict multi-view consistency. Project page: https://kunhao-liu.github.io/StyleGaussian/
Generative Probabilistic Time Series Forecasting and Applications in Grid Operations
Feb 21, 2024Generative probabilistic forecasting produces future time series samples according to the conditional probability distribution given past time series observations. Such techniques are essential in risk-based decision-making and planning under uncertainty with broad applications in grid operations, including electricity price forecasting, risk-based economic dispatch, and stochastic optimizations. Inspired by Wiener and Kallianpur's innovation representation, we propose a weak innovation autoencoder architecture and a learning algorithm to extract independent and identically distributed innovation sequences from nonparametric stationary time series. We show that the weak innovation sequence is Bayesian sufficient, which makes the proposed weak innovation autoencoder a canonical architecture for generative probabilistic forecasting. The proposed technique is applied to forecasting highly volatile real-time electricity prices, demonstrating superior performance across multiple forecasting measures over leading probabilistic and point forecasting techniques.
LSTM-Based Text Generation: A Study on Historical Datasets
Mar 11, 2024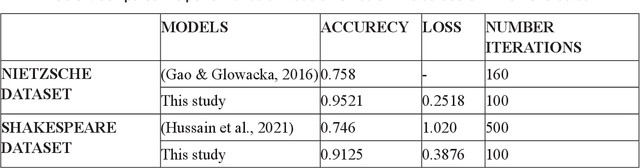
This paper presents an exploration of Long Short-Term Memory (LSTM) networks in the realm of text generation, focusing on the utilization of historical datasets for Shakespeare and Nietzsche. LSTMs, known for their effectiveness in handling sequential data, are applied here to model complex language patterns and structures inherent in historical texts. The study demonstrates that LSTM-based models, when trained on historical datasets, can not only generate text that is linguistically rich and contextually relevant but also provide insights into the evolution of language patterns over time. The finding presents models that are highly accurate and efficient in predicting text from works of Nietzsche, with low loss values and a training time of 100 iterations. The accuracy of the model is 0.9521, indicating high accuracy. The loss of the model is 0.2518, indicating its effectiveness. The accuracy of the model in predicting text from the work of Shakespeare is 0.9125, indicating a low error rate. The training time of the model is 100, mirroring the efficiency of the Nietzsche dataset. This efficiency demonstrates the effectiveness of the model design and training methodology, especially when handling complex literary texts. This research contributes to the field of natural language processing by showcasing the versatility of LSTM networks in text generation and offering a pathway for future explorations in historical linguistics and beyond.