 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CoordFill: Efficient High-Resolution Image Inpainting via Parameterized Coordinate Querying
Mar 15, 2023

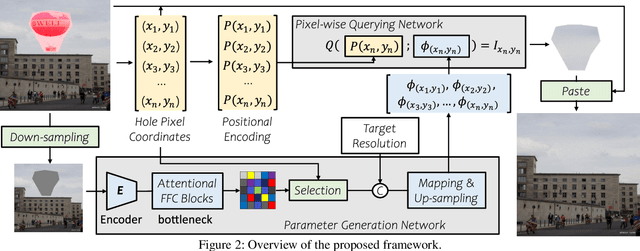
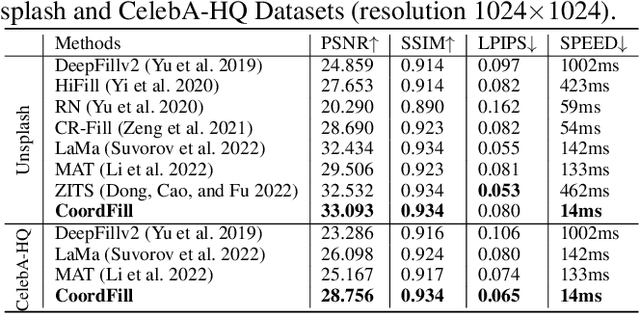
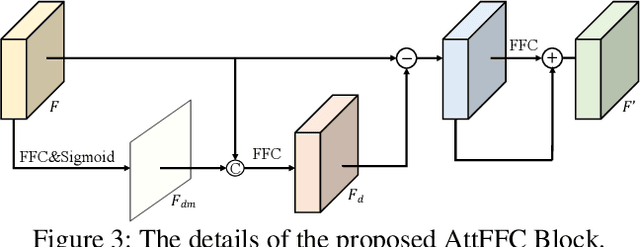
Image inpainting aims to fill the missing hole of the input. It is hard to solve this task efficiently when facing high-resolution images due to two reasons: (1) Large reception field needs to be handled for high-resolution image inpainting. (2) The general encoder and decoder network synthesizes many background pixels synchronously due to the form of the image matrix. In this paper, we try to break the above limitations for the first time thanks to the recent development of continuous implicit representation. In detail, we down-sample and encode the degraded image to produce the spatial-adaptive parameters for each spatial patch via an attentional Fast Fourier Convolution(FFC)-based parameter generation network. Then, we take these parameters as the weights and biases of a series of multi-layer perceptron(MLP), where the input is the encoded continuous coordinates and the output is the synthesized color value. Thanks to the proposed structure, we only encode the high-resolution image in a relatively low resolution for larger reception field capturing. Then, the continuous position encoding will be helpful to synthesize the photo-realistic high-frequency textures by re-sampling the coordinate in a higher resolution. Also, our framework enables us to query the coordinates of missing pixels only in parallel, yielding a more efficient solution than the previous methods. Experiments show that the proposed method achieves real-time performance on the 2048$\times$2048 images using a single GTX 2080 Ti GPU and can handle 4096$\times$4096 images, with much better performance than existing state-of-the-art methods visually and numerically. The code is available at: https://github.com/NiFangBaAGe/CoordFill.
Acoustic source localization in the spherical harmonics domain exploiting low-rank approximations
Mar 15, 2023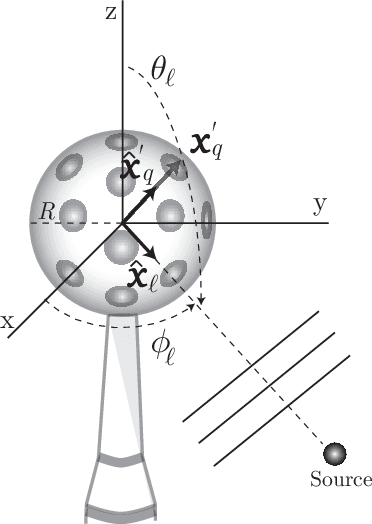
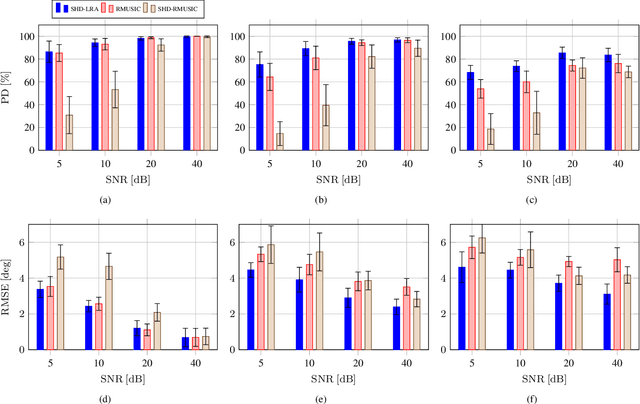
Acoustic signal processing in the spherical harmonics domain (SHD) is an active research area that exploits the signals acquired by higher order microphone arrays. A very important task is that concerning the localization of active sound sources. In this paper, we propose a simple yet effective method to localize prominent acoustic sources in adverse acoustic scenarios. By using a proper normalization and arrangement of the estimated spherical harmonic coefficients, we exploit low-rank approximations to estimate the far field modal directional pattern of the dominant source at each time-frame. The experiments confirm the validity of the proposed approach, with superior performance compared to other recent SHD-based approaches.
* To appear in ICASSP 2023
Route to Time and Time to Route: Travel Time Estimation from Sparse Trajectories
Jun 21, 2022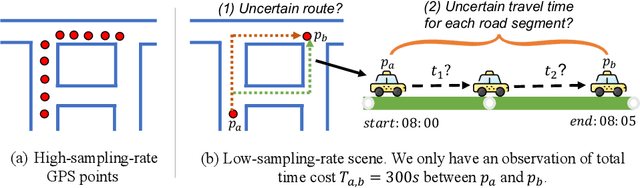
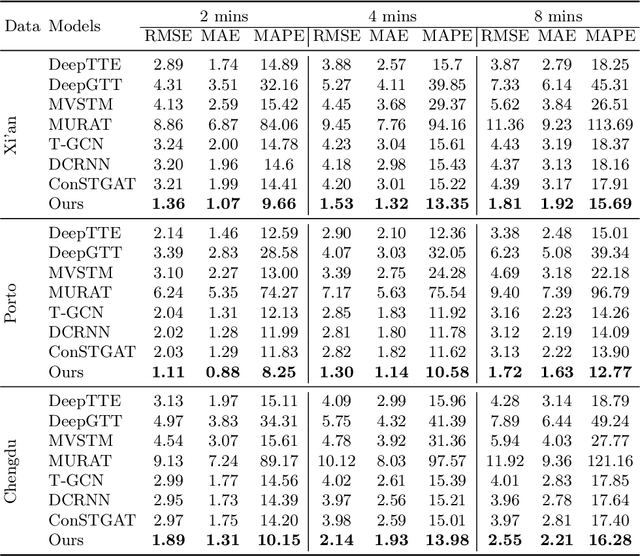
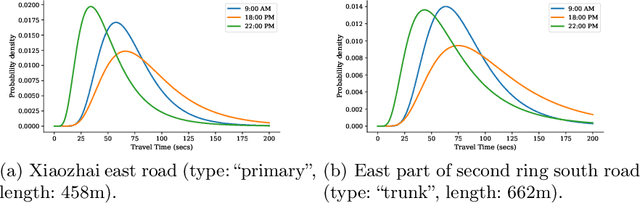
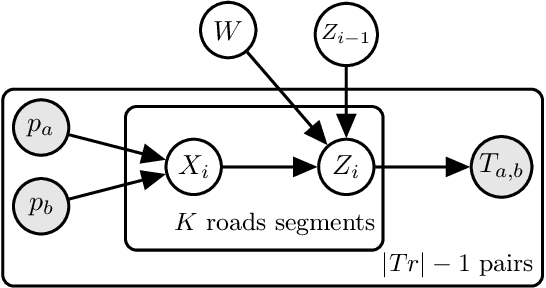
Due to the rapid development of Internet of Things (IoT) technologies, many online web apps (e.g., Google Map and Uber) estimate the travel time of trajectory data collected by mobile devices. However, in reality, complex factors, such as network communication and energy constraints, make multiple trajectories collected at a low sampling rate. In this case, this paper aims to resolve the problem of travel time estimation (TTE) and route recovery in sparse scenarios, which often leads to the uncertain label of travel time and route between continuously sampled GPS points. We formulate this problem as an inexact supervision problem in which the training data has coarsely grained labels and jointly solve the tasks of TTE and route recovery. And we argue that both two tasks are complementary to each other in the model-learning procedure and hold such a relation: more precise travel time can lead to better inference for routes, in turn, resulting in a more accurate time estimation). Based on this assumption, we propose an EM algorithm to alternatively estimate the travel time of inferred route through weak supervision in E step and retrieve the route based on estimated travel time in M step for sparse trajectories. We conducted experiments on three real-world trajectory datasets and demonstrated the effectiveness of the proposed method.
Hard Nominal Example-aware Template Mutual Matching for Industrial Anomaly Detection
Mar 29, 2023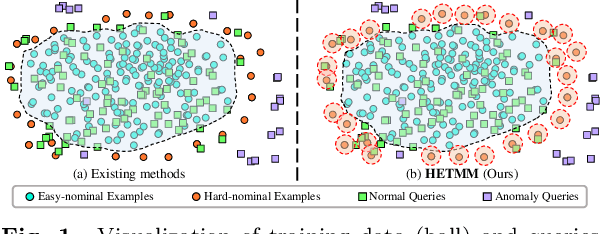
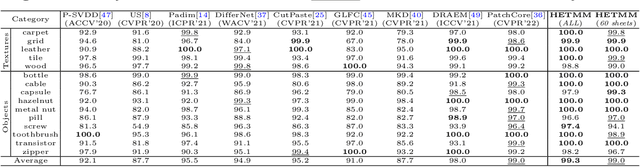
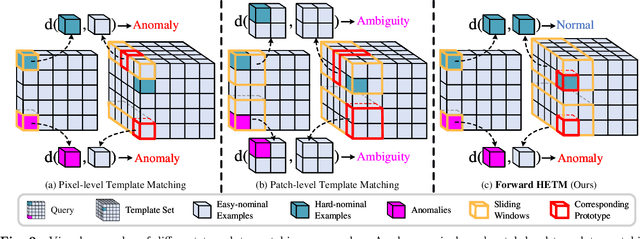
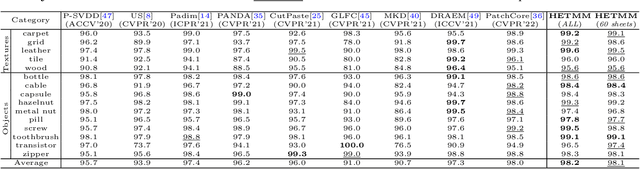
Anomaly detectors are widely used in industrial production to detect and localize unknown defects in query images. These detectors are trained on nominal images and have shown success in distinguishing anomalies from most normal samples. However, hard-nominal examples are scattered and far apart from most normalities, they are often mistaken for anomalies by existing anomaly detectors. To address this problem, we propose a simple yet efficient method: \textbf{H}ard Nominal \textbf{E}xample-aware \textbf{T}emplate \textbf{M}utual \textbf{M}atching (HETMM). Specifically, \textit{HETMM} aims to construct a robust prototype-based decision boundary, which can precisely distinguish between hard-nominal examples and anomalies, yielding fewer false-positive and missed-detection rates. Moreover, \textit{HETMM} mutually explores the anomalies in two directions between queries and the template set, and thus it is capable to capture the logical anomalies. This is a significant advantage over most anomaly detectors that frequently fail to detect logical anomalies. Additionally, to meet the speed-accuracy demands, we further propose \textbf{P}ixel-level \textbf{T}emplate \textbf{S}election (PTS) to streamline the original template set. \textit{PTS} selects cluster centres and hard-nominal examples to form a tiny set, maintaining the original decision boundaries. Comprehensive experiments on five real-world datasets demonstrate that our methods yield outperformance than existing advances under the real-time inference speed. Furthermore, \textit{HETMM} can be hot-updated by inserting novel samples, which may promptly address some incremental learning issues.
Using Connected Vehicle Trajectory Data to Evaluate the Effects of Speeding
Mar 29, 2023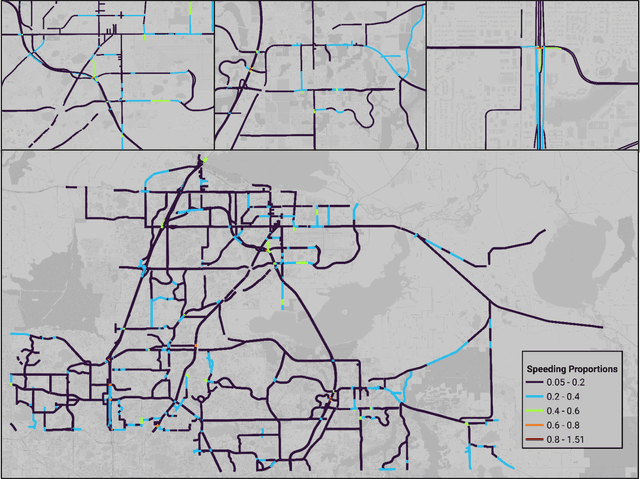
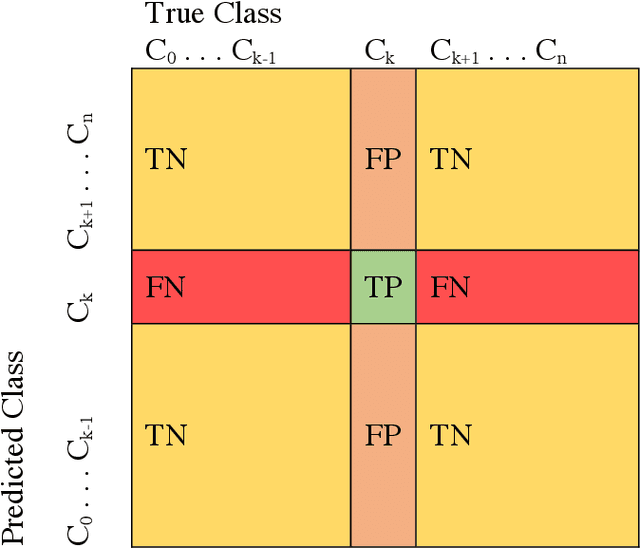
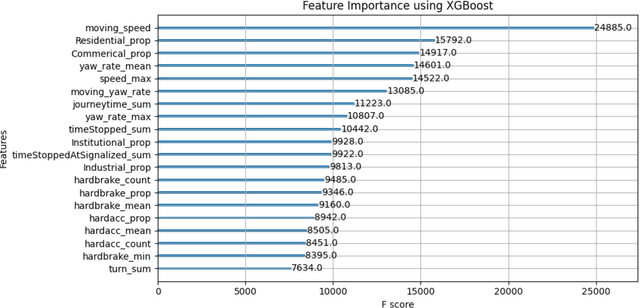
Speeding has been and continues to be a major contributing factor to traffic fatalities. Various transportation agencies have proposed speed management strategies to reduce the amount of speeding on arterials. While there have been various studies done on the analysis of speeding proportions above the speed limit, few studies have considered the effect on the individual's journey. Many studies utilized speed data from detectors, which is limited in that there is no information of the route that the driver took. This study aims to explore the effects of various roadway features an individual experiences for a given journey on speeding proportions. Connected vehicle trajectory data was utilized to identify the path that a driver took, along with the vehicle related variables. The level of speeding proportion is predicted using multiple learning models. The model with the best performance, Extreme Gradient Boosting, achieved an accuracy of 0.756. The proposed model can be used to understand how the environment and vehicle's path effects the drivers' speeding behavior, as well as predict the areas with high levels of speeding proportions. The results suggested that features related to an individual driver's trip, i.e., total travel time, has a significant contribution towards speeding. Features that are related to the environment of the individual driver's trip, i.e., proportion of residential area, also had a significant effect on reducing speeding proportions. It is expected that the findings could help inform transportation agencies more on the factors related to speeding for an individual driver's trip.
Analysis of Expected Hitting Time for Designing Evolutionary Neural Architecture Search Algorithms
Oct 11, 2022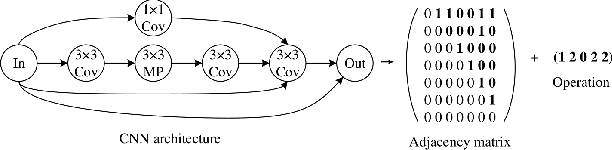
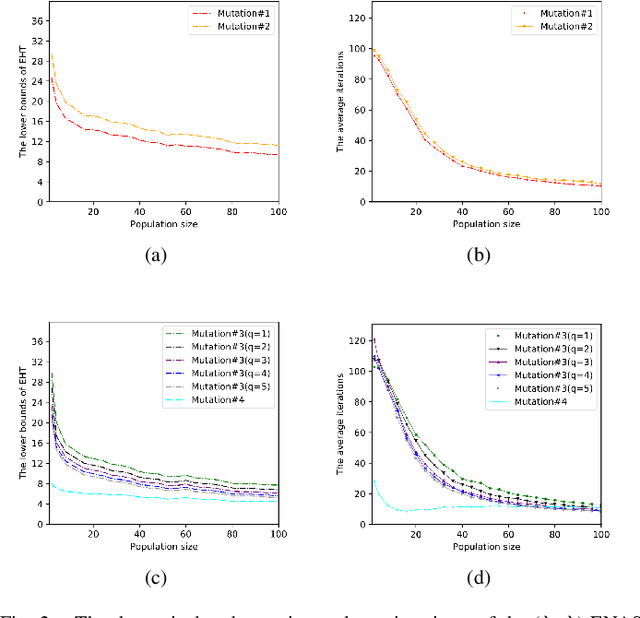
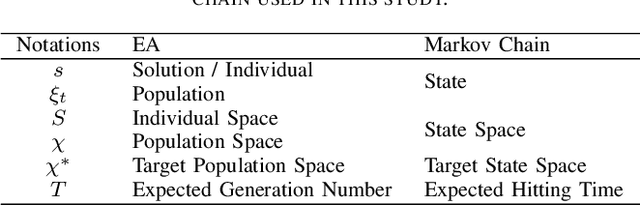
Evolutionary computation-based neural architecture search (ENAS) is a popular technique for automating architecture design of deep neural networks. In recent years, various ENAS algorithms have been proposed and shown promising performance on diverse real-world applications. In contrast to these groundbreaking applications, there is no theoretical guideline for assigning a reasonable running time (mainly affected by the generation number, population size, and evolution operator) given both the anticipated performance and acceptable computation budget on ENAS problems. The expected hitting time (EHT), which refers to the average generations, is considered to analyze the running time of ENAS algorithms. This paper proposes a general framework for estimating the EHT of ENAS algorithms, which includes common configuration, search space partition, transition probability estimation, and hitting time analysis. By exploiting the proposed framework, we consider the so-called ($\lambda$+$\lambda$)-ENAS algorithms with different mutation operators and manage to estimate the lower bounds of the EHT {which are critical for the algorithm to find the global optimum}. Furthermore, we study the theoretical results on the NAS-Bench-101 architecture searching problem, and the results show that the one-bit mutation with "bit-based fair mutation" strategy needs less time than the "offspring-based fair mutation" strategy, and the bitwise mutation operator needs less time than the $q$-bit mutation operator. To the best of our knowledge, this is the first work focusing on the theory of ENAS, and the above observation will be substantially helpful in designing efficient ENAS algorithms.
Development of Real-time Rendering Technology for High-Precision Models in Autonomous Driving
Feb 01, 2023



Our autonomous driving simulation lab produces a high-precision 3D model simulating the parking lot. However, the current model still has poor rendering quality in some aspects. In this work, we develop a system to improve the rendering of the model and evaluate the quality of the rendered model.
RGB-D-Inertial SLAM in Indoor Dynamic Environments with Long-term Large Occlusion
Mar 23, 2023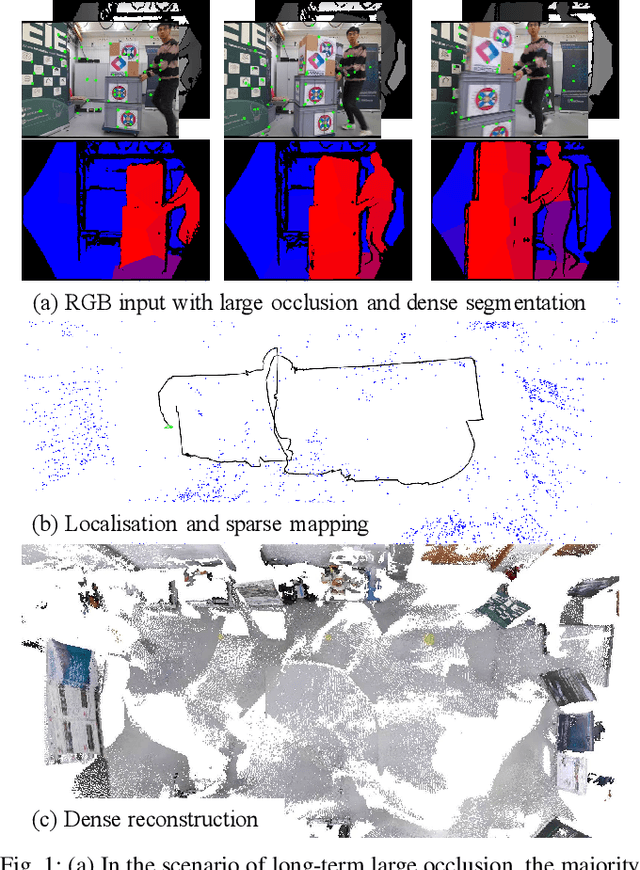
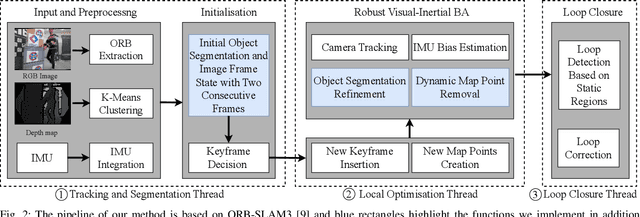

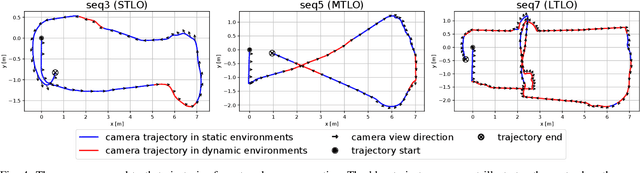
This work presents a novel RGB-D-inertial dynamic SLAM method that can enable accurate localisation when the majority of the camera view is occluded by multiple dynamic objects over a long period of time. Most dynamic SLAM approaches either remove dynamic objects as outliers when they account for a minor proportion of the visual input, or detect dynamic objects using semantic segmentation before camera tracking. Therefore, dynamic objects that cause large occlusions are difficult to detect without prior information. The remaining visual information from the static background is also not enough to support localisation when large occlusion lasts for a long period. To overcome these problems, our framework presents a robust visual-inertial bundle adjustment that simultaneously tracks camera, estimates cluster-wise dense segmentation of dynamic objects and maintains a static sparse map by combining dense and sparse features. The experiment results demonstrate that our method achieves promising localisation and object segmentation performance compared to other state-of-the-art methods in the scenario of long-term large occlusion.
Continuous Indeterminate Probability Neural Network
Mar 23, 2023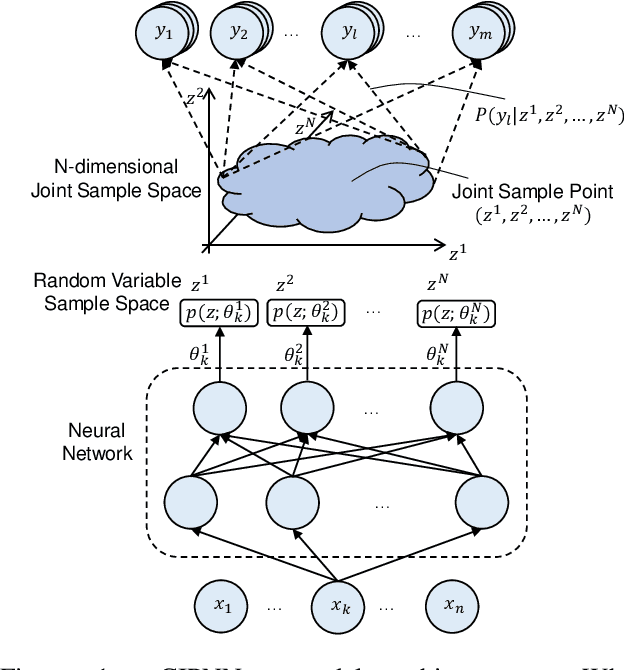
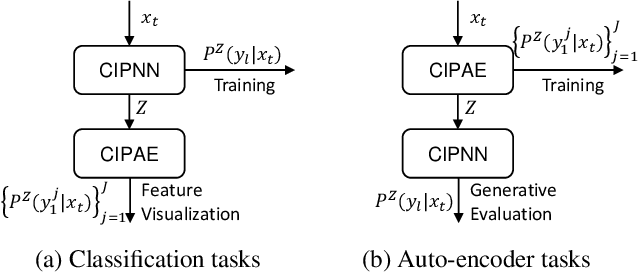


This paper introduces a general model called CIPNN - Continuous Indeterminate Probability Neural Network, and this model is based on IPNN, which is used for discrete latent random variables. Currently, posterior of continuous latent variables is regarded as intractable, with the new theory proposed by IPNN this problem can be solved. Our contributions are Four-fold. First, we derive the analytical solution of the posterior calculation of continuous latent random variables and propose a general classification model (CIPNN). Second, we propose a general auto-encoder called CIPAE - Continuous Indeterminate Probability Auto-Encoder, the decoder part is not a neural network and uses a fully probabilistic inference model for the first time. Third, we propose a new method to visualize the latent random variables, we use one of N dimensional latent variables as a decoder to reconstruct the input image, which can work even for classification tasks, in this way, we can see what each latent variable has learned. Fourth, IPNN has shown great classification capability, CIPNN has pushed this classification capability to infinity. Theoretical advantages are reflected in experimental results.
Defining Quality Requirements for a Trustworthy AI Wildflower Monitoring Platform
Mar 23, 2023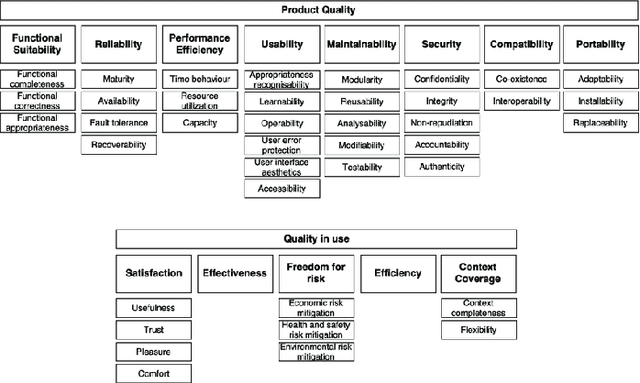
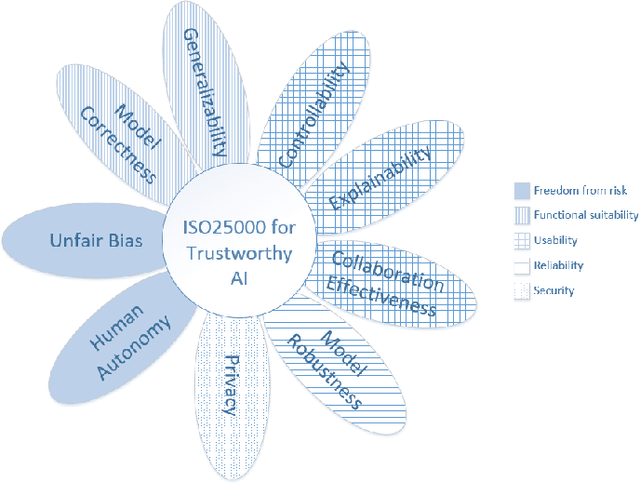
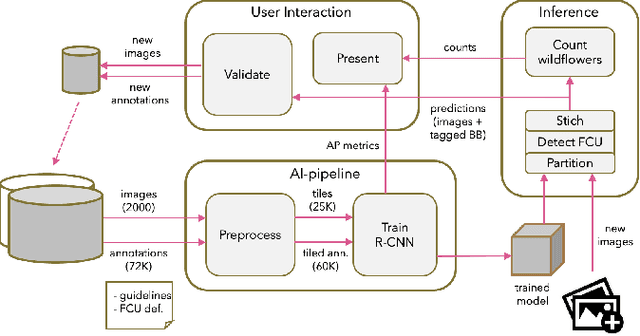

For an AI solution to evolve from a trained machine learning model into a production-ready AI system, many more things need to be considered than just the performance of the machine learning model. A production-ready AI system needs to be trustworthy, i.e. of high quality. But how to determine this in practice? For traditional software, ISO25000 and its predecessors have since long time been used to define and measure quality characteristics. Recently, quality models for AI systems, based on ISO25000, have been introduced. This paper applies one such quality model to a real-life case study: a deep learning platform for monitoring wildflowers. The paper presents three realistic scenarios sketching what it means to respectively use, extend and incrementally improve the deep learning platform for wildflower identification and counting. Next, it is shown how the quality model can be used as a structured dictionary to define quality requirements for data, model and software. Future work remains to extend the quality model with metrics, tools and best practices to aid AI engineering practitioners in implementing trustworthy AI systems.