 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine Learning Approach and Extreme Value Theory to Correlated Stochastic Time Series with Application to Tree Ring Data
Jan 27, 2023
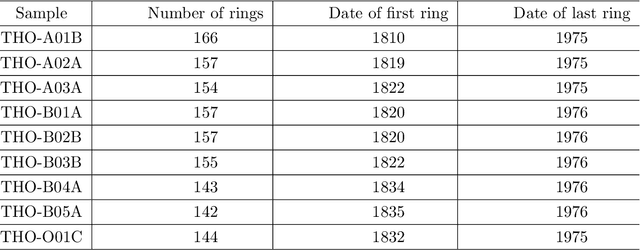
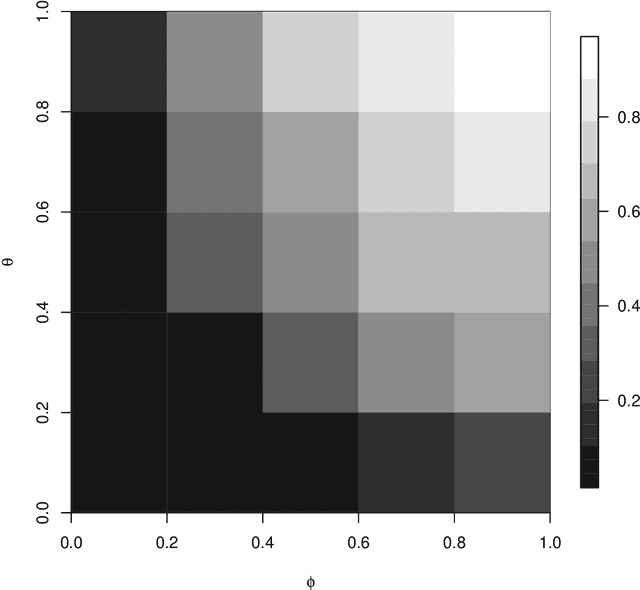
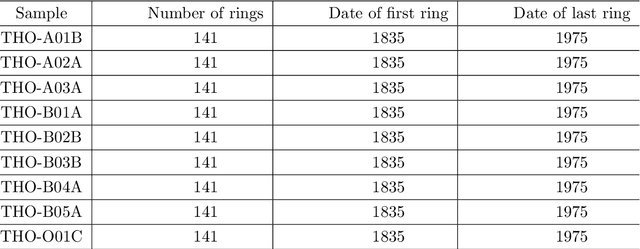
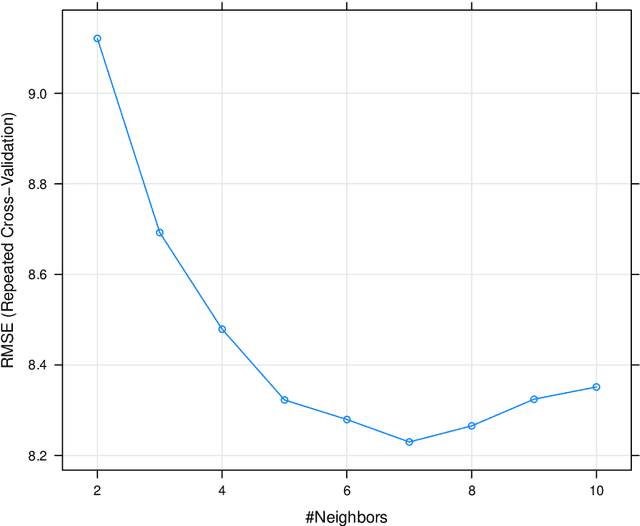
The main goal of machine learning (ML) is to study and improve mathematical models which can be trained with data provided by the environment to infer the future and to make decisions without necessarily having complete knowledge of all influencing elements. In this work, we describe how ML can be a powerful tool in studying climate modeling. Tree ring growth was used as an implementation in different aspects, for example, studying the history of buildings and environment. By growing and via the time, a new layer of wood to beneath its bark by the tree. After years of growing, time series can be applied via a sequence of tree ring widths. The purpose of this paper is to use ML algorithms and Extreme Value Theory in order to analyse a set of tree ring widths data from nine trees growing in Nottinghamshire. Initially, we start by exploring the data through a variety of descriptive statistical approaches. Transforming data is important at this stage to find out any problem in modelling algorithm. We then use algorithm tuning and ensemble methods to improve the k-nearest neighbors (KNN) algorithm. A comparison between the developed method in this study ad other methods are applied. Also, extreme value of the dataset will be more investigated. The results of the analysis study show that the ML algorithms in the Random Forest method would give accurate results in the analysis of tree ring widths data from nine trees growing in Nottinghamshire with the lowest Root Mean Square Error value. Also, we notice that as the assumed ARMA model parameters increased, the probability of selecting the true model also increased. In terms of the Extreme Value Theory, the Weibull distribution would be a good choice to model tree ring data.
TimelyFL: Heterogeneity-aware Asynchronous Federated Learning with Adaptive Partial Training
Apr 14, 2023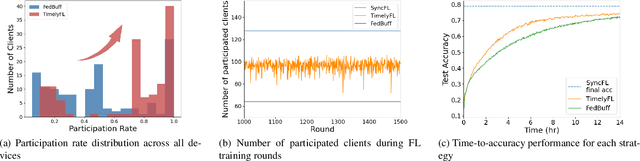
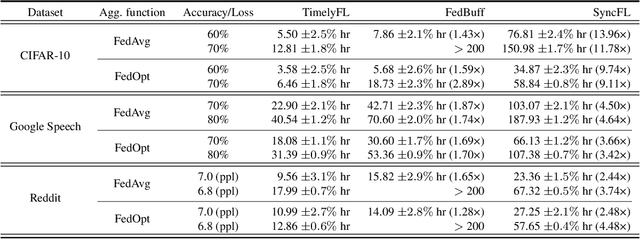
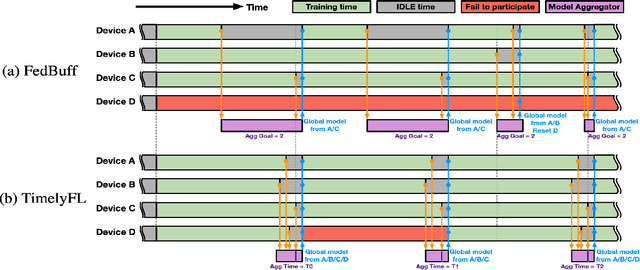

In cross-device Federated Learning (FL) environments, scaling synchronous FL methods is challenging as stragglers hinder the training process. Moreover, the availability of each client to join the training is highly variable over time due to system heterogeneities and intermittent connectivity. Recent asynchronous FL methods (e.g., FedBuff) have been proposed to overcome these issues by allowing slower users to continue their work on local training based on stale models and to contribute to aggregation when ready. However, we show empirically that this method can lead to a substantial drop in training accuracy as well as a slower convergence rate. The primary reason is that fast-speed devices contribute to many more rounds of aggregation while others join more intermittently or not at all, and with stale model updates. To overcome this barrier, we propose TimelyFL, a heterogeneity-aware asynchronous FL framework with adaptive partial training. During the training, TimelyFL adjusts the local training workload based on the real-time resource capabilities of each client, aiming to allow more available clients to join in the global update without staleness. We demonstrate the performance benefits of TimelyFL by conducting extensive experiments on various datasets (e.g., CIFAR-10, Google Speech, and Reddit) and models (e.g., ResNet20, VGG11, and ALBERT). In comparison with the state-of-the-art (i.e., FedBuff), our evaluations reveal that TimelyFL improves participation rate by 21.13%, harvests 1.28x - 2.89x more efficiency on convergence rate, and provides a 6.25% increment on test accuracy.
Towards Automated 3D Search Planning for Emergency Response Missions
Apr 07, 2023The ability to efficiently plan and execute automated and precise search missions using unmanned aerial vehicles (UAVs) during emergency response situations is imperative. Precise navigation between obstacles and time-efficient searching of 3D structures and buildings are essential for locating survivors and people in need in emergency response missions. In this work we address this challenging problem by proposing a unified search planning framework that automates the process of UAV-based search planning in 3D environments. Specifically, we propose a novel search planning framework which enables automated planning and execution of collision-free search trajectories in 3D by taking into account low-level mission constrains (e.g., the UAV dynamical and sensing model), mission objectives (e.g., the mission execution time and the UAV energy efficiency) and user-defined mission specifications (e.g., the 3D structures to be searched and minimum detection probability constraints). The capabilities and performance of the proposed approach are demonstrated through extensive simulated 3D search scenarios.
* Journal of Intelligent & Robotic Systems 103.1 (2021): 2
Analysis of vocal breath sounds before and after administering Bronchodilator in Asthmatic patients
Apr 29, 2023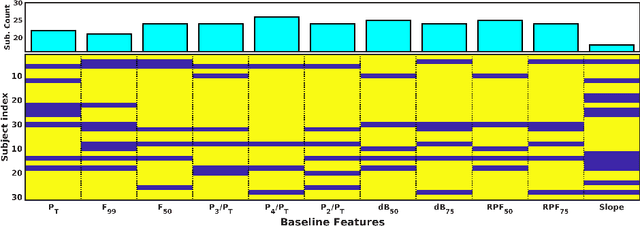
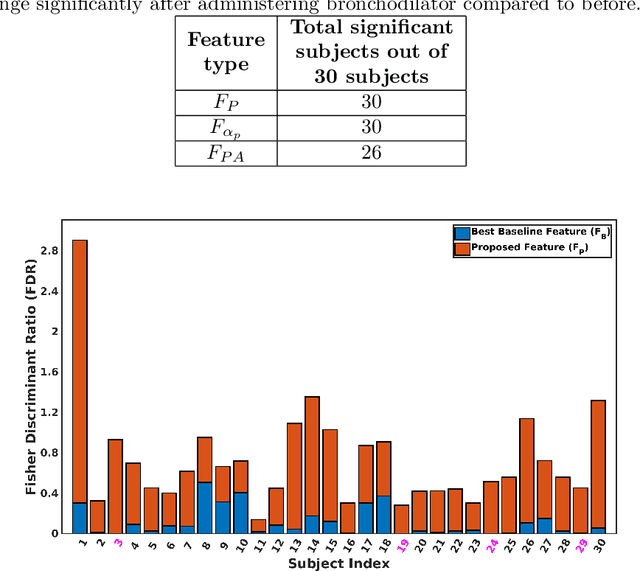
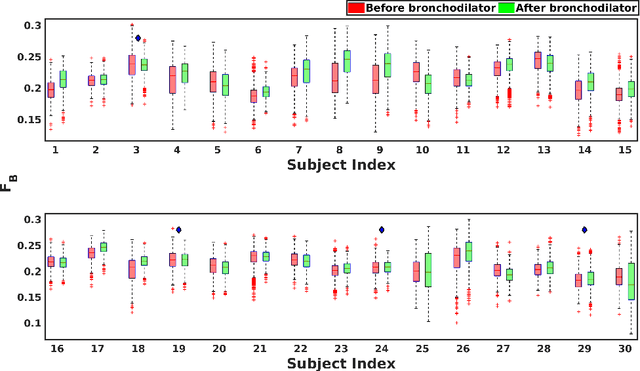
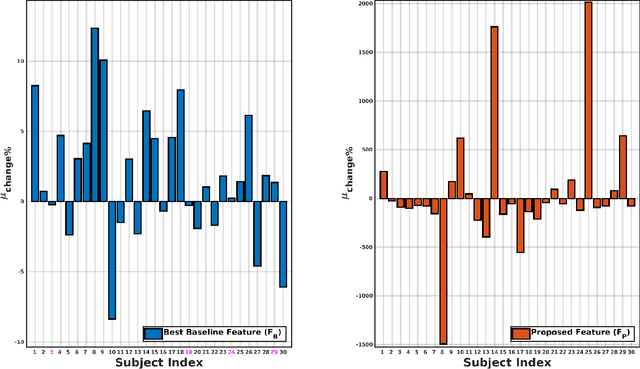
Asthma is one of the chronic inflammatory diseases of the airways, which causes chest tightness, wheezing, breathlessness, and cough. Spirometry is an effort-dependent test used to monitor and diagnose lung conditions like Asthma. Vocal breath sound (VBS) based analysis can be an alternative to spirometry as VBS characteristics change depending on the lung condition. VBS test consumes less time, and it also requires less effort, unlike spirometry. In this work, VBS characteristics are analyzed before and after administering bronchodilator in a subject-dependent manner using linear discriminant analysis (LDA). We find that features learned through LDA show a significant difference between VBS recorded before and after administering bronchodilator in all 30 subjects considered in this work, whereas the baseline features could achieve a significant difference between VBS only for 26 subjects. We also observe that all frequency ranges do not contribute equally to the discrimination between pre and post bronchodilator conditions. From experiments, we find that two frequency ranges, namely 400-500Hz and 1480-1900Hz, maximally contribute to the discrimination of all the subjects. The study presented in this paper analyzes the pre and post-bronchodilator effect on the inhalation sound recorded at the mouth in a subject-dependent manner. The findings of this work suggest that, inhalation sound recorded at mouth can be a good stimulus to discriminate pre and post-bronchodilator conditions in asthmatic subjects. Inhale sound-based pre and post-bronchodilator discrimination can be of potential use in clinical settings.
Towards machine learning guided by best practices
Apr 29, 2023Nowadays, machine learning (ML) is being used in software systems with multiple application fields, from medicine to software engineering (SE). On the one hand, the popularity of ML in the industry can be seen in the statistics showing its growth and adoption. On the other hand, its popularity can also be seen in research, particularly in SE, where not only have multiple studies been published in SE conferences and journals but also in the multiple workshops and co-located conferences in software engineering conferences. At the same time, researchers and practitioners have shown that machine learning has some particular challenges and pitfalls. In particular, research has shown that ML-enabled systems have a different development process than traditional SE, which also describes some of the challenges of ML applications. In order to mitigate some of the identified challenges and pitfalls, white and gray literature has proposed a set of recommendations based on their own experiences and focused on their domain (e.g., biomechanics), but for the best of our knowledge, there is no guideline focused on the SE community. This thesis aims to reduce this gap by answering research questions that help to understand the practices used and discussed by practitioners and researchers in the SE community by analyzing possible sources of practices such as question and answer communities and also previous research studies to present a set of practices with an SE perspective.
Inductive Graph Transformer for Delivery Time Estimation
Nov 05, 2022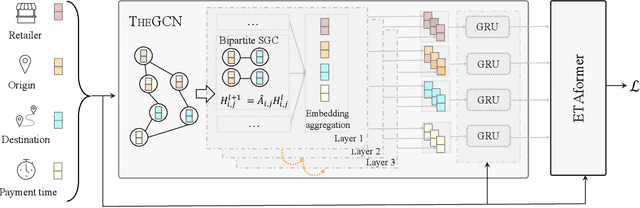
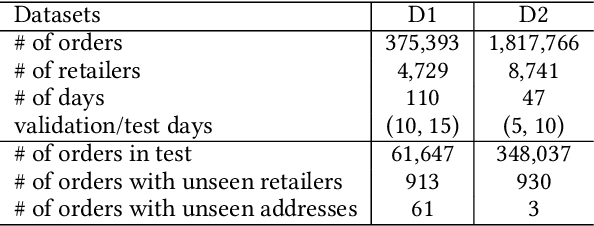

Providing accurate estimated time of package delivery on users' purchasing pages for e-commerce platforms is of great importance to their purchasing decisions and post-purchase experiences. Although this problem shares some common issues with the conventional estimated time of arrival (ETA), it is more challenging with the following aspects: 1) Inductive inference. Models are required to predict ETA for orders with unseen retailers and addresses; 2) High-order interaction of order semantic information. Apart from the spatio-temporal features, the estimated time also varies greatly with other factors, such as the packaging efficiency of retailers, as well as the high-order interaction of these factors. In this paper, we propose an inductive graph transformer (IGT) that leverages raw feature information and structural graph data to estimate package delivery time. Different from previous graph transformer architectures, IGT adopts a decoupled pipeline and trains transformer as a regression function that can capture the multiplex information from both raw feature and dense embeddings encoded by a graph neural network (GNN). In addition, we further simplify the GNN structure by removing its non-linear activation and the learnable linear transformation matrix. The reduced parameter search space and linear information propagation in the simplified GNN enable the IGT to be applied in large-scale industrial scenarios. Experiments on real-world logistics datasets show that our proposed model can significantly outperform the state-of-the-art methods on estimation of delivery time. The source code is available at: https://github.com/enoche/IGT-WSDM23.
Robust Time Series Chain Discovery with Incremental Nearest Neighbors
Nov 03, 2022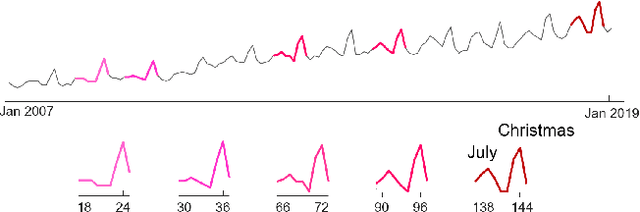
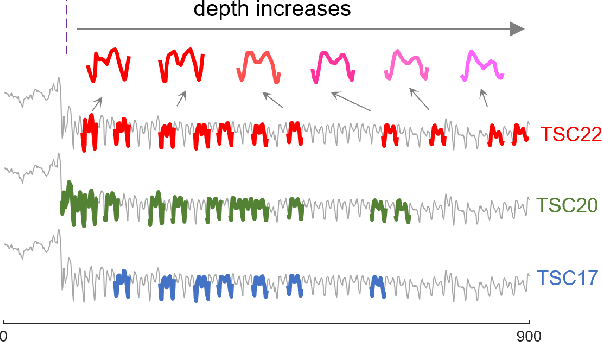
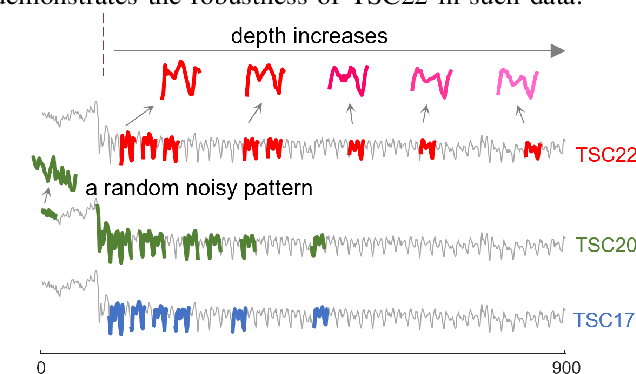
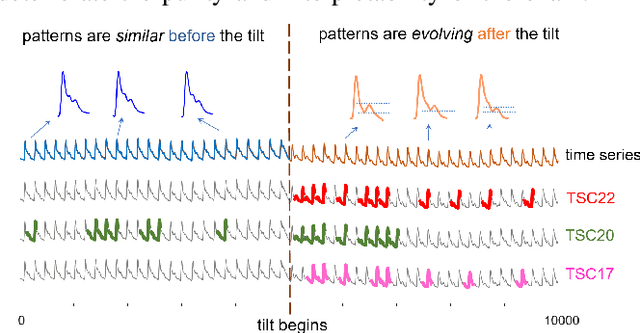
Time series motif discovery has been a fundamental task to identify meaningful repeated patterns in time series. Recently, time series chains were introduced as an expansion of time series motifs to identify the continuous evolving patterns in time series data. Informally, a time series chain (TSC) is a temporally ordered set of time series subsequences, in which every subsequence is similar to the one that precedes it, but the last and the first can be arbitrarily dissimilar. TSCs are shown to be able to reveal latent continuous evolving trends in the time series, and identify precursors of unusual events in complex systems. Despite its promising interpretability, unfortunately, we have observed that existing TSC definitions lack the ability to accurately cover the evolving part of a time series: the discovered chains can be easily cut by noise and can include non-evolving patterns, making them impractical in real-world applications. Inspired by a recent work that tracks how the nearest neighbor of a time series subsequence changes over time, we introduce a new TSC definition which is much more robust to noise in the data, in the sense that they can better locate the evolving patterns while excluding the non-evolving ones. We further propose two new quality metrics to rank the discovered chains. With extensive empirical evaluations, we demonstrate that the proposed TSC definition is significantly more robust to noise than the state of the art, and the top ranked chains discovered can reveal meaningful regularities in a variety of real world datasets.
Next-Generation Full Duplex Networking System Empowered by Reconfigurable Intelligent Surfaces
May 02, 2023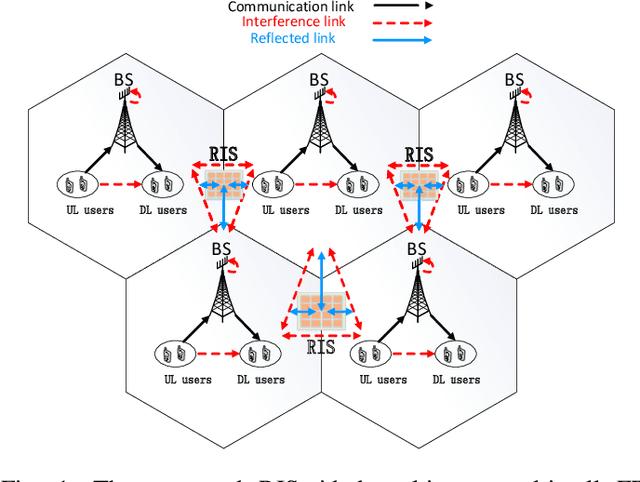
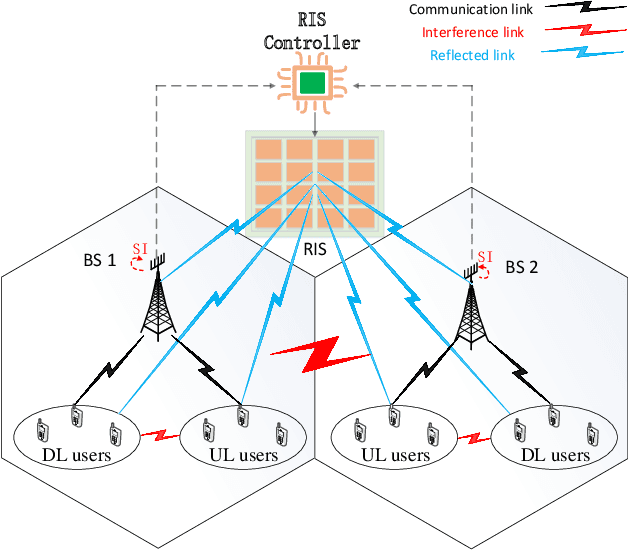
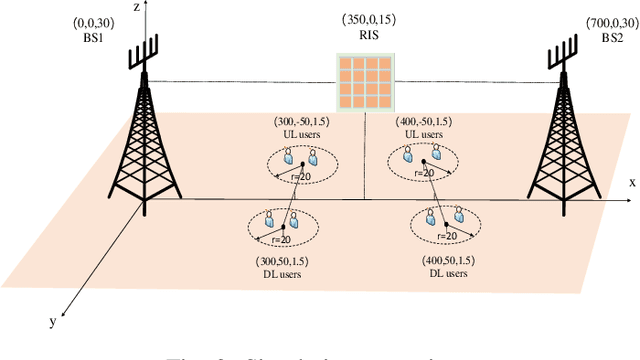
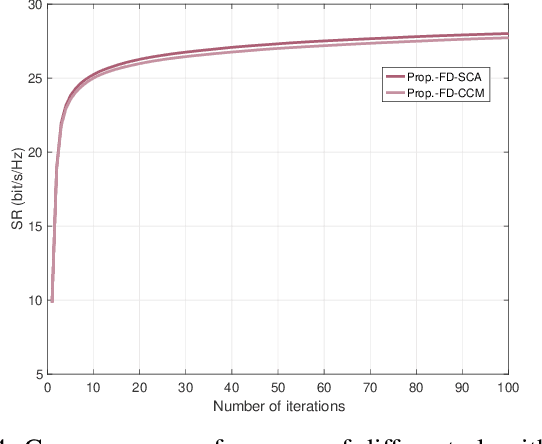
Full duplex (FD) radio has attracted extensive attention due to its co-time and co-frequency transceiving capability. {However, the potential gain brought by FD radios is closely related to the management of self-interference (SI), which imposes high or even stringent requirements on SI cancellation (SIC) techniques. When the FD deployment evolves into next-generation mobile networking, the SI problem becomes more complicated, significantly limiting its potential gains.} In this paper, we conceive a multi-cell FD networking scheme by deploying a reconfigurable intelligent surface (RIS) at the cell boundary to configure the radio environment proactively. To achieve the full potential of the system, we aim to maximize the sum rate (SR) of multiple cells by jointly optimizing the transmit precoding (TPC) matrices at FD base stations (BSs) and users and the phase shift matrix at RIS. Since the original problem is non-convex, we reformulate and decouple it into a pair of subproblems by utilizing the relationship between the SR and minimum mean square error (MMSE). The optimal solutions of TPC matrices are obtained in closed form, while both complex circle manifold (CCM) and successive convex approximation (SCA) based algorithms are developed to resolve the phase shift matrix suboptimally. Our simulation results show that introducing an RIS into an FD networking system not only improves the overall SR significantly but also enhances the cell edge performance prominently. More importantly, we validate that the RIS deployment with optimized phase shifts can reduce the requirement for SIC and the number of BS antennas, which further reduces the hardware cost and power consumption, especially with a sufficient number of reflecting elements. As a result, the utilization of an RIS enables the originally cumbersome FD networking system to become efficient and practical.
Lessons Learned in ATCO2: 5000 hours of Air Traffic Control Communications for Robust Automatic Speech Recognition and Understanding
May 02, 2023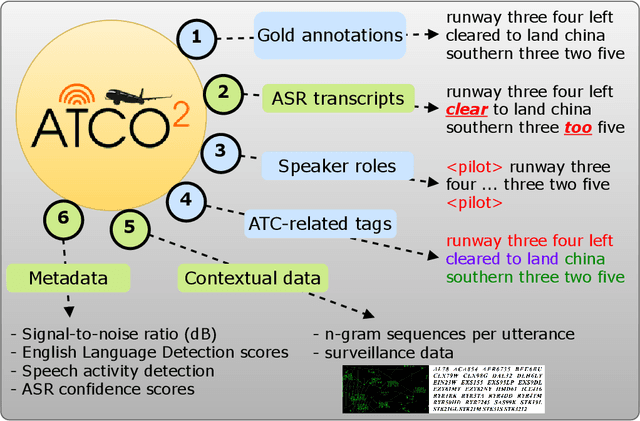
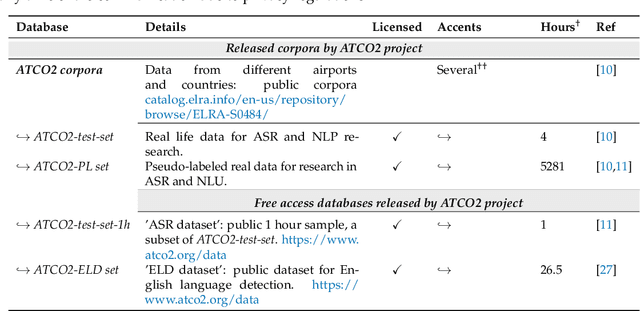
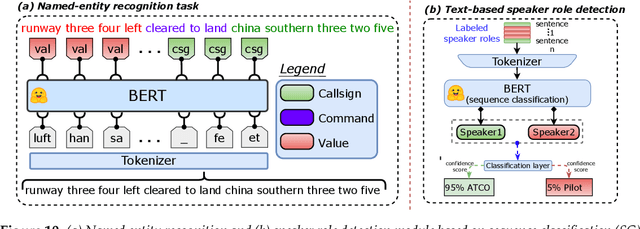
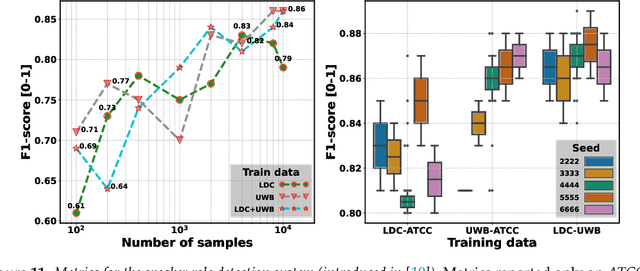
Voice communication between air traffic controllers (ATCos) and pilots is critical for ensuring safe and efficient air traffic control (ATC). This task requires high levels of awareness from ATCos and can be tedious and error-prone. Recent attempts have been made to integrate artificial intelligence (AI) into ATC in order to reduce the workload of ATCos. However, the development of data-driven AI systems for ATC demands large-scale annotated datasets, which are currently lacking in the field. This paper explores the lessons learned from the ATCO2 project, a project that aimed to develop a unique platform to collect and preprocess large amounts of ATC data from airspace in real time. Audio and surveillance data were collected from publicly accessible radio frequency channels with VHF receivers owned by a community of volunteers and later uploaded to Opensky Network servers, which can be considered an "unlimited source" of data. In addition, this paper reviews previous work from ATCO2 partners, including (i) robust automatic speech recognition, (ii) natural language processing, (iii) English language identification of ATC communications, and (iv) the integration of surveillance data such as ADS-B. We believe that the pipeline developed during the ATCO2 project, along with the open-sourcing of its data, will encourage research in the ATC field. A sample of the ATCO2 corpus is available on the following website: https://www.atco2.org/data, while the full corpus can be purchased through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. We demonstrated that ATCO2 is an appropriate dataset to develop ASR engines when little or near to no ATC in-domain data is available. For instance, with the CNN-TDNNf kaldi model, we reached the performance of as low as 17.9% and 24.9% WER on public ATC datasets which is 6.6/7.6% better than "out-of-domain" but supervised CNN-TDNNf model.
One Explanation Does Not Fit XIL
Apr 14, 2023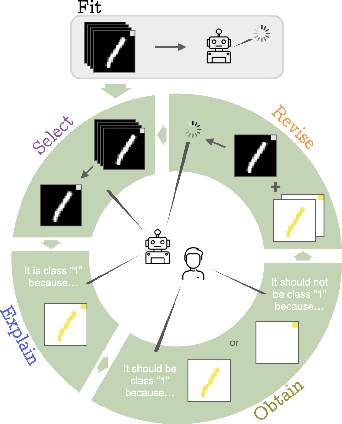


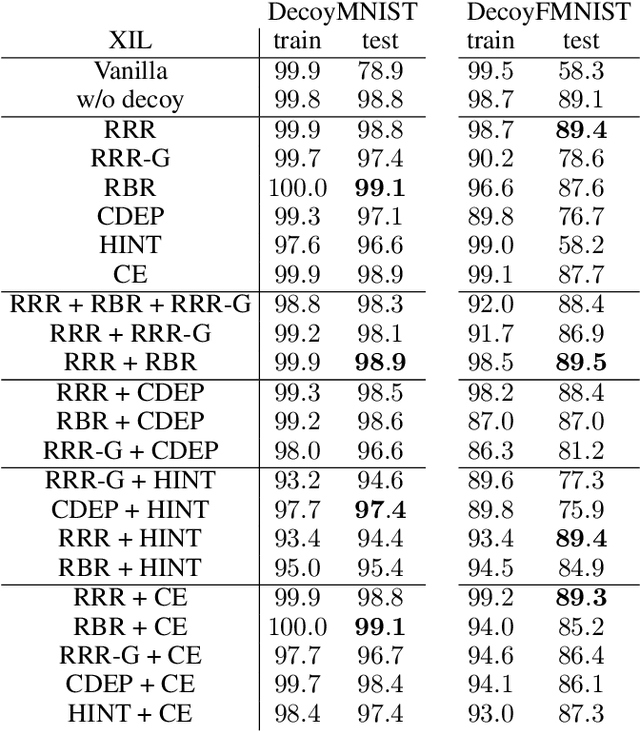
Current machine learning models produce outstanding results in many areas but, at the same time, suffer from shortcut learning and spurious correlations. To address such flaws, the explanatory interactive machine learning (XIL) framework has been proposed to revise a model by employing user feedback on a model's explanation. This work sheds light on the explanations used within this framework. In particular, we investigate simultaneous model revision through multiple explanation methods. To this end, we identified that \textit{one explanation does not fit XIL} and propose considering multiple ones when revising models via XIL.