 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned in ATCO2: 5000 hours of Air Traffic Control Communications for Robust Automatic Speech Recognition and Understanding
May 02, 2023



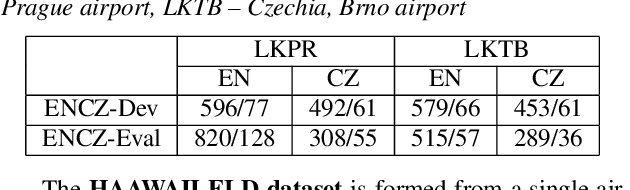
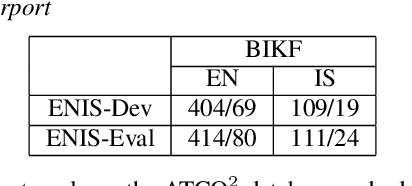
Voice communication between air traffic controllers (ATCos) and pilots is critical for ensuring safe and efficient air traffic control (ATC). This task requires high levels of awareness from ATCos and can be tedious and error-prone. Recent attempts have been made to integrate artificial intelligence (AI) into ATC in order to reduce the workload of ATCos. However, the development of data-driven AI systems for ATC demands large-scale annotated datasets, which are currently lacking in the field. This paper explores the lessons learned from the ATCO2 project, a project that aimed to develop a unique platform to collect and preprocess large amounts of ATC data from airspace in real time. Audio and surveillance data were collected from publicly accessible radio frequency channels with VHF receivers owned by a community of volunteers and later uploaded to Opensky Network servers, which can be considered an "unlimited source" of data. In addition, this paper reviews previous work from ATCO2 partners, including (i) robust automatic speech recognition, (ii) natural language processing, (iii) English language identification of ATC communications, and (iv) the integration of surveillance data such as ADS-B. We believe that the pipeline developed during the ATCO2 project, along with the open-sourcing of its data, will encourage research in the ATC field. A sample of the ATCO2 corpus is available on the following website: https://www.atco2.org/data, while the full corpus can be purchased through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. We demonstrated that ATCO2 is an appropriate dataset to develop ASR engines when little or near to no ATC in-domain data is available. For instance, with the CNN-TDNNf kaldi model, we reached the performance of as low as 17.9% and 24.9% WER on public ATC datasets which is 6.6/7.6% better than "out-of-domain" but supervised CNN-TDNNf model.
Detecting English Speech in the Air Traffic Control Voice Communication
Apr 06, 2021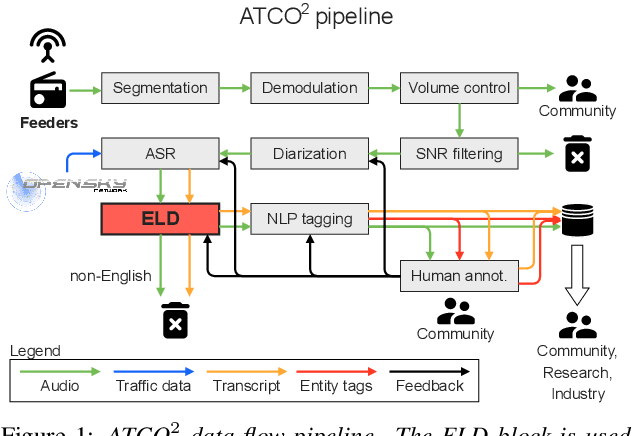

We launched a community platform for collecting the ATC speech world-wide in the ATCO2 project. Filtering out unseen non-English speech is one of the main components in the data processing pipeline. The proposed English Language Detection (ELD) system is based on the embeddings from Bayesian subspace multinomial model. It is trained on the word confusion network from an ASR system. It is robust, easy to train, and light weighted. We achieved 0.0439 equal-error-rate (EER), a 50% relative reduction as compared to the state-of-the-art acoustic ELD system based on x-vectors, in the in-domain scenario. Further, we achieved an EER of 0.1352, a 33% relative reduction as compared to the acoustic ELD, in the unseen language (out-of-domain) condition. We plan to publish the evaluation dataset from the ATCO2 project.