 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PPDONet: Deep Operator Networks for Fast Prediction of Steady-State Solutions in Disk-Planet Systems
May 18, 2023
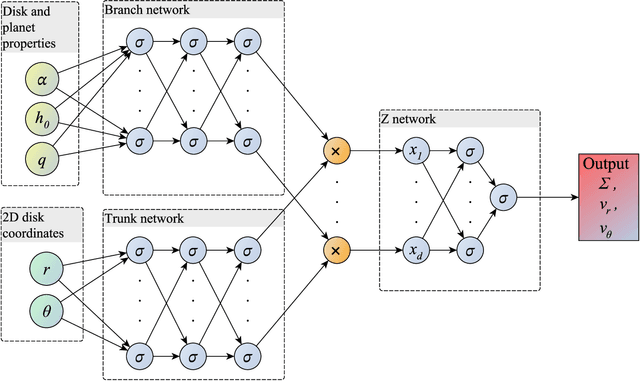

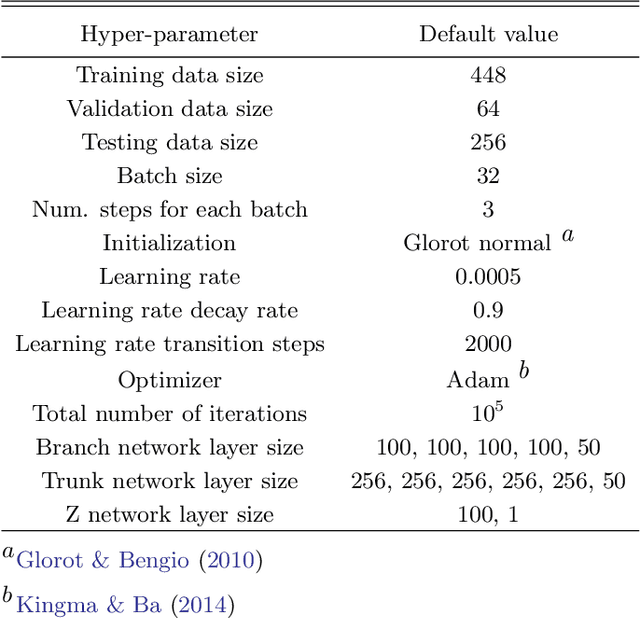
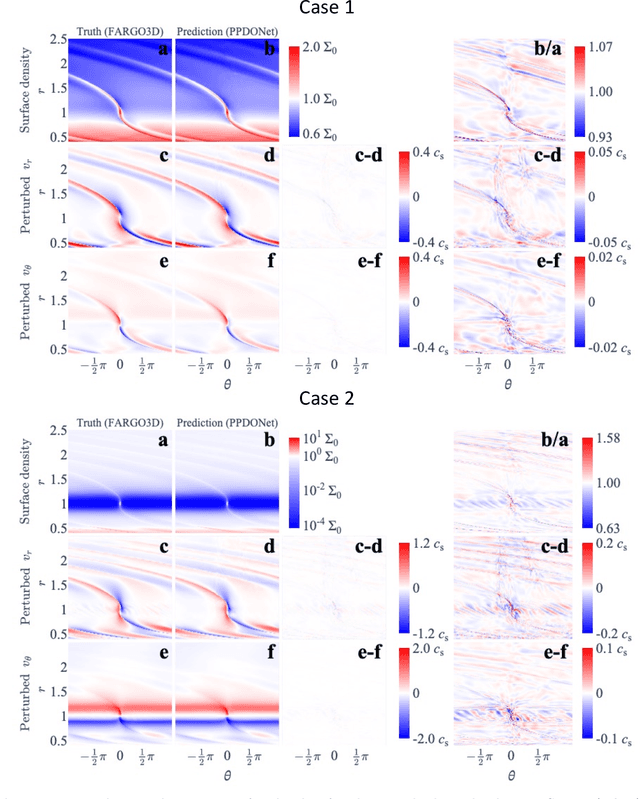
We develop a tool, which we name Protoplanetary Disk Operator Network (PPDONet), that can predict the solution of disk-planet interactions in protoplanetary disks in real-time. We base our tool on Deep Operator Networks (DeepONets), a class of neural networks capable of learning non-linear operators to represent deterministic and stochastic differential equations. With PPDONet we map three scalar parameters in a disk-planet system -- the Shakura \& Sunyaev viscosity $\alpha$, the disk aspect ratio $h_\mathrm{0}$, and the planet-star mass ratio $q$ -- to steady-state solutions of the disk surface density, radial velocity, and azimuthal velocity. We demonstrate the accuracy of the PPDONet solutions using a comprehensive set of tests. Our tool is able to predict the outcome of disk-planet interaction for one system in less than a second on a laptop. A public implementation of PPDONet is available at \url{https://github.com/smao-astro/PPDONet}.
ReGen: Zero-Shot Text Classification via Training Data Generation with Progressive Dense Retrieval
May 18, 2023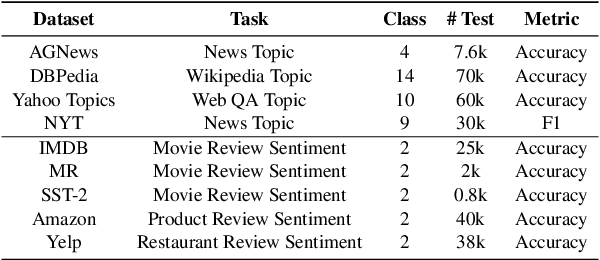
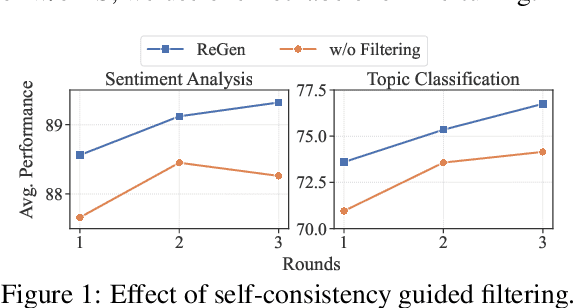
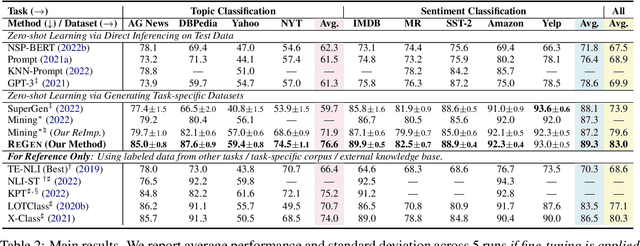
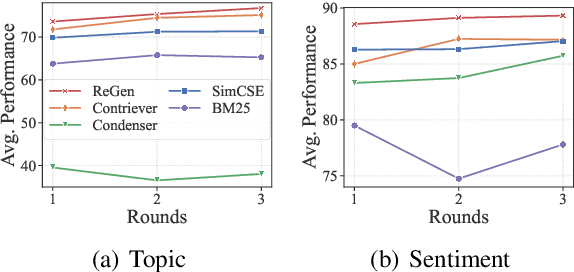
With the development of large language models (LLMs), zero-shot learning has attracted much attention for various NLP tasks. Different from prior works that generate training data with billion-scale natural language generation (NLG) models, we propose a retrieval-enhanced framework to create training data from a general-domain unlabeled corpus. To realize this, we first conduct contrastive pretraining to learn an unsupervised dense retriever for extracting the most relevant documents using class-descriptive verbalizers. We then further propose two simple strategies, namely Verbalizer Augmentation with Demonstrations and Self-consistency Guided Filtering to improve the topic coverage of the dataset while removing noisy examples. Experiments on nine datasets demonstrate that REGEN achieves 4.3% gain over the strongest baselines and saves around 70% of the time compared to baselines using large NLG models. Besides, REGEN can be naturally integrated with recently proposed large language models to boost performance.
AaKOS: Aspect-adaptive Knowledge-based Opinion Summarization
May 26, 2023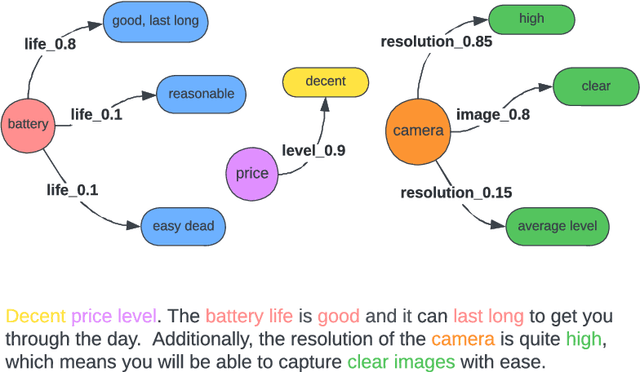

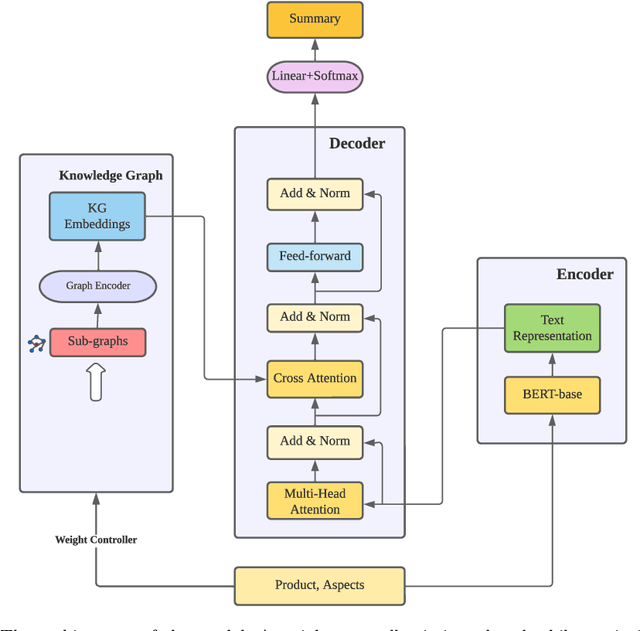
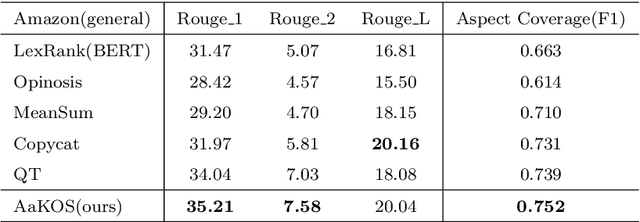
The rapid growth of information on the Internet has led to an overwhelming amount of opinions and comments on various activities, products, and services. This makes it difficult and time-consuming for users to process all the available information when making decisions. Text summarization, a Natural Language Processing (NLP) task, has been widely explored to help users quickly retrieve relevant information by generating short and salient content from long or multiple documents. Recent advances in pre-trained language models, such as ChatGPT, have demonstrated the potential of Large Language Models (LLMs) in text generation. However, LLMs require massive amounts of data and resources and are challenging to implement as offline applications. Furthermore, existing text summarization approaches often lack the ``adaptive" nature required to capture diverse aspects in opinion summarization, which is particularly detrimental to users with specific requirements or preferences. In this paper, we propose an Aspect-adaptive Knowledge-based Opinion Summarization model for product reviews, which effectively captures the adaptive nature required for opinion summarization. The model generates aspect-oriented summaries given a set of reviews for a particular product, efficiently providing users with useful information on specific aspects they are interested in, ensuring the generated summaries are more personalized and informative. Extensive experiments have been conducted using real-world datasets to evaluate the proposed model. The results demonstrate that our model outperforms state-of-the-art approaches and is adaptive and efficient in generating summaries that focus on particular aspects, enabling users to make well-informed decisions and catering to their diverse interests and preferences.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023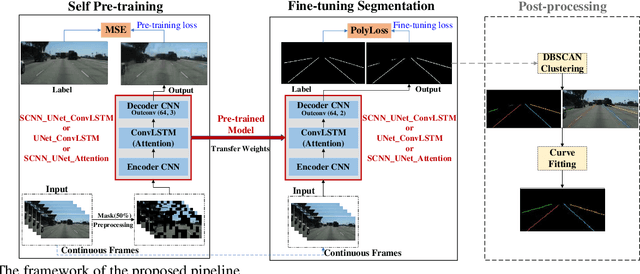
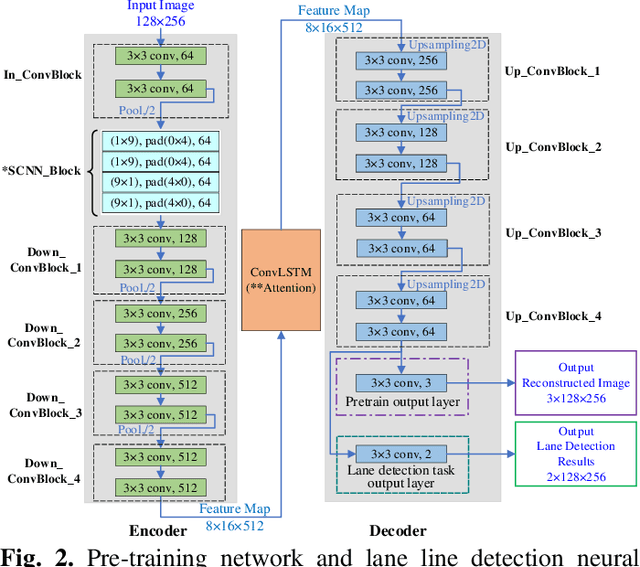
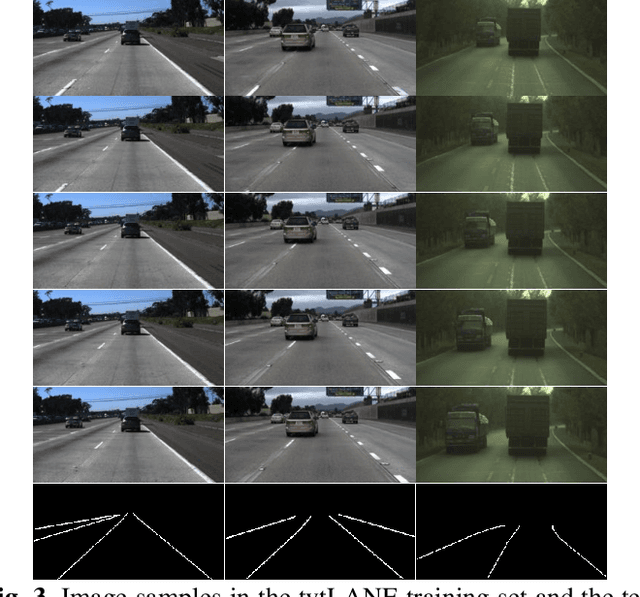

Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.
Referred by Multi-Modality: A Unified Temporal Transformer for Video Object Segmentation
May 25, 2023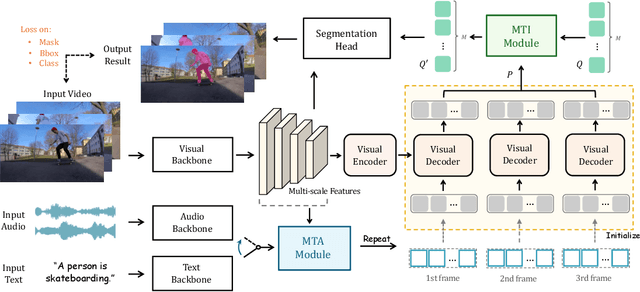
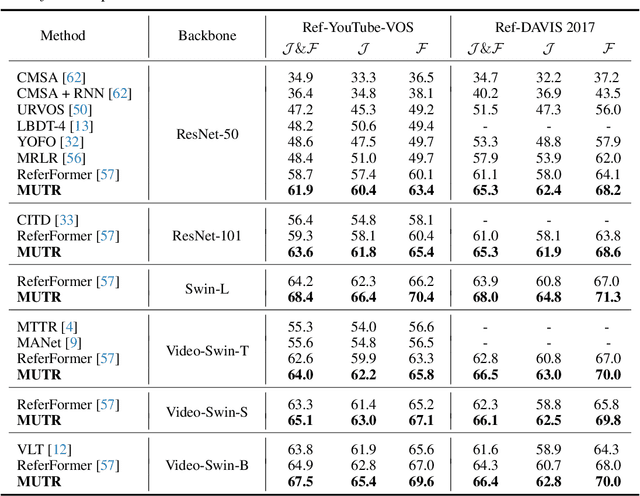
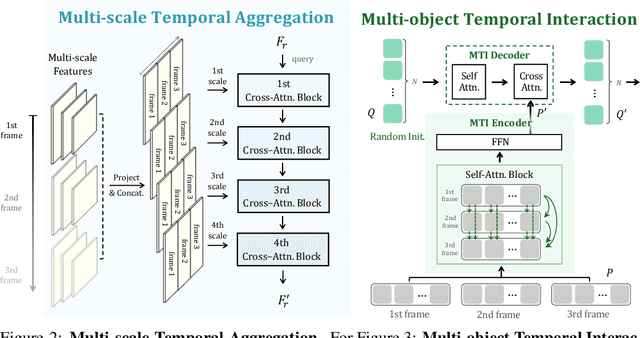
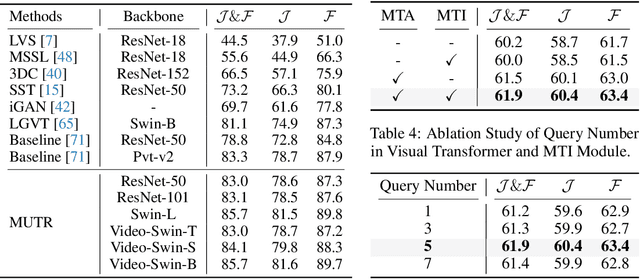
Recently, video object segmentation (VOS) referred by multi-modal signals, e.g., language and audio, has evoked increasing attention in both industry and academia. It is challenging for exploring the semantic alignment within modalities and the visual correspondence across frames. However, existing methods adopt separate network architectures for different modalities, and neglect the inter-frame temporal interaction with references. In this paper, we propose MUTR, a Multi-modal Unified Temporal transformer for Referring video object segmentation. With a unified framework for the first time, MUTR adopts a DETR-style transformer and is capable of segmenting video objects designated by either text or audio reference. Specifically, we introduce two strategies to fully explore the temporal relations between videos and multi-modal signals. Firstly, for low-level temporal aggregation before the transformer, we enable the multi-modal references to capture multi-scale visual cues from consecutive video frames. This effectively endows the text or audio signals with temporal knowledge and boosts the semantic alignment between modalities. Secondly, for high-level temporal interaction after the transformer, we conduct inter-frame feature communication for different object embeddings, contributing to better object-wise correspondence for tracking along the video. On Ref-YouTube-VOS and AVSBench datasets with respective text and audio references, MUTR achieves +4.2% and +4.2% J&F improvements to state-of-the-art methods, demonstrating our significance for unified multi-modal VOS. Code is released at https://github.com/OpenGVLab/MUTR.
Accelerated MR Fingerprinting with Low-Rank and Generative Subspace Modeling
May 25, 2023
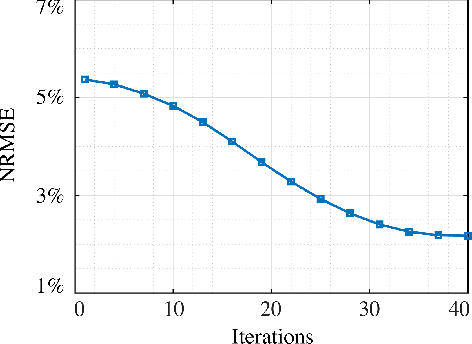
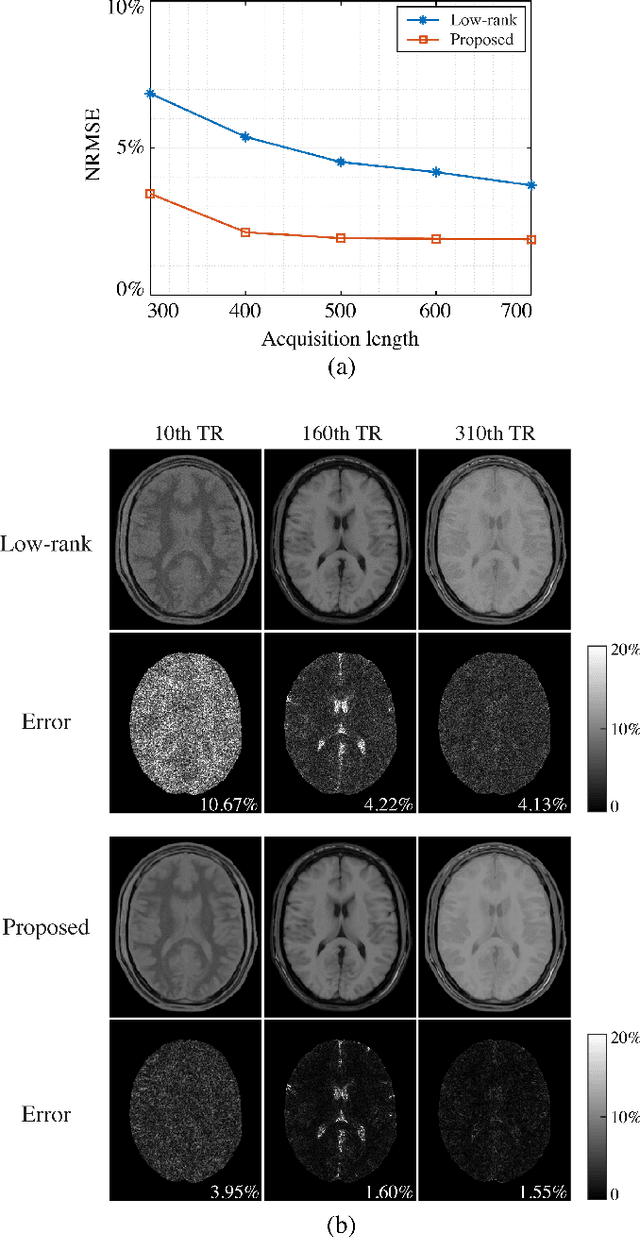
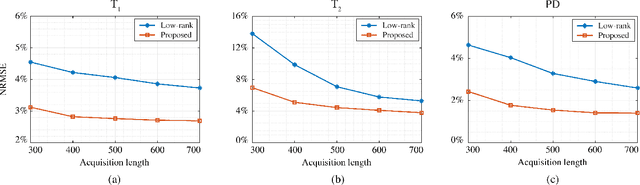
Magnetic Resonance (MR) Fingerprinting is an emerging multi-parametric quantitative MR imaging technique, for which image reconstruction methods utilizing low-rank and subspace constraints have achieved state-of-the-art performance. However, this class of methods often suffers from an ill-conditioned model-fitting issue, which degrades the performance as the data acquisition lengths become short and/or the signal-to-noise ratio becomes low. To address this problem, we present a new image reconstruction method for MR Fingerprinting, integrating low-rank and subspace modeling with a deep generative prior. Specifically, the proposed method captures the strong spatiotemporal correlation of contrast-weighted time-series images in MR Fingerprinting via a low-rank factorization. Further, it utilizes an untrained convolutional generative neural network to represent the spatial subspace of the low-rank model, while estimating the temporal subspace of the model from simulated magnetization evolutions generated based on spin physics. Here the architecture of the generative neural network serves as an effective regularizer for the ill-conditioned inverse problem without additional spatial training data that are often expensive to acquire. The proposed formulation results in a non-convex optimization problem, for which we develop an algorithm based on variable splitting and alternating direction method of multipliers.We evaluate the performance of the proposed method with numerical simulations and in vivo experiments and demonstrate that the proposed method outperforms the state-of-the-art low-rank and subspace reconstruction.
UMat: Uncertainty-Aware Single Image High Resolution Material Capture
May 25, 2023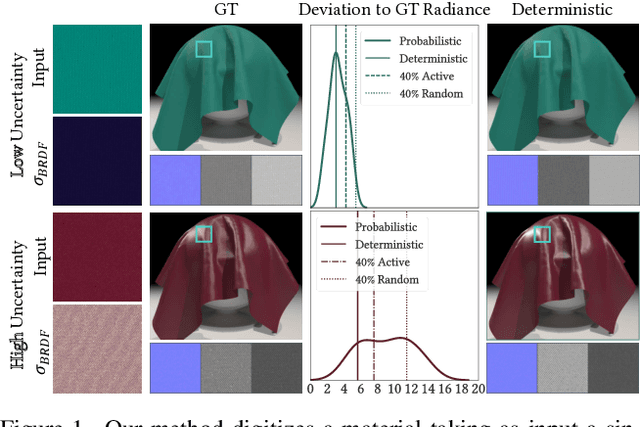
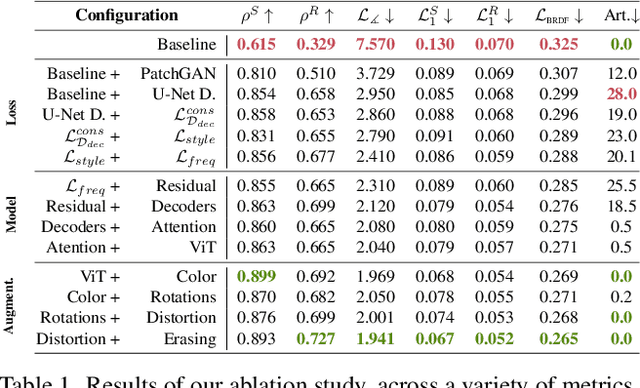

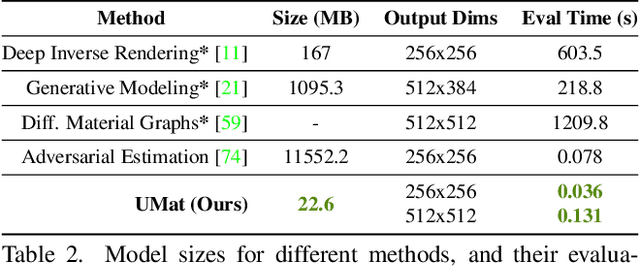
We propose a learning-based method to recover normals, specularity, and roughness from a single diffuse image of a material, using microgeometry appearance as our primary cue. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. In contrast, in this work, we propose a novel capture approach that leverages a generative network with attention and a U-Net discriminator, which shows outstanding performance integrating global information at reduced computational complexity. We showcase the performance of our method with a real dataset of digitized textile materials and show that a commodity flatbed scanner can produce the type of diffuse illumination required as input to our method. Additionally, because the problem might be illposed -more than a single diffuse image might be needed to disambiguate the specular reflection- or because the training dataset is not representative enough of the real distribution, we propose a novel framework to quantify the model's confidence about its prediction at test time. Our method is the first one to deal with the problem of modeling uncertainty in material digitization, increasing the trustworthiness of the process and enabling more intelligent strategies for dataset creation, as we demonstrate with an active learning experiment.
MixFormerV2: Efficient Fully Transformer Tracking
May 25, 2023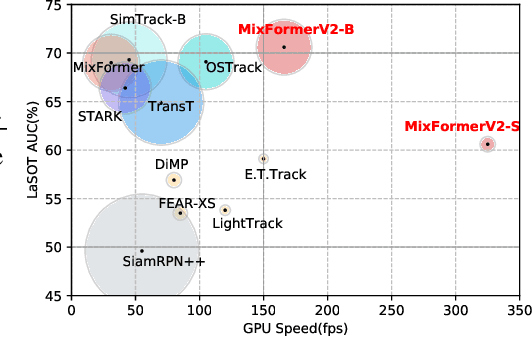
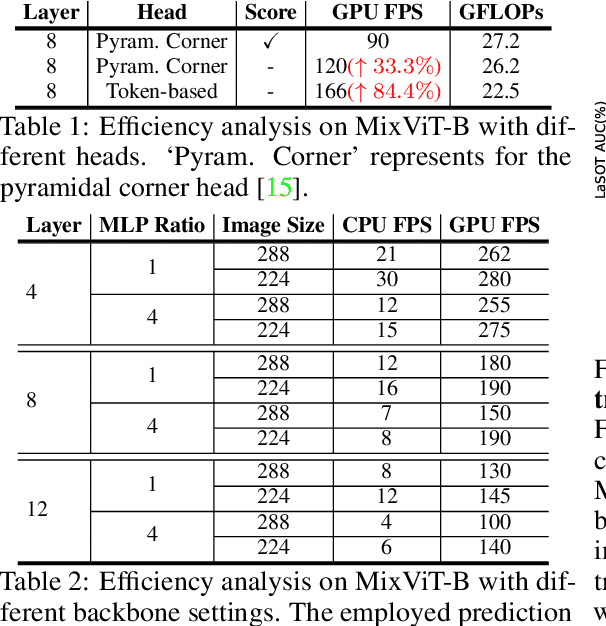
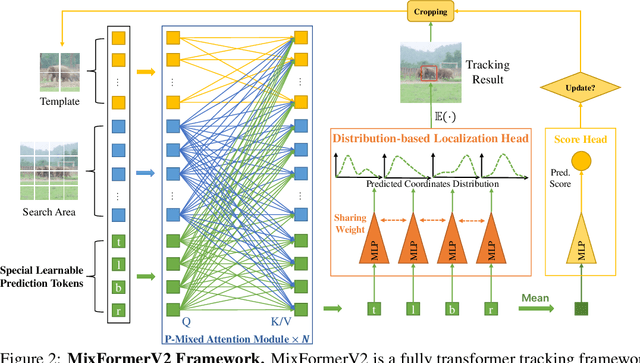

Transformer-based trackers have achieved strong accuracy on the standard benchmarks. However, their efficiency remains an obstacle to practical deployment on both GPU and CPU platforms. In this paper, to overcome this issue, we propose a fully transformer tracking framework, coined as \emph{MixFormerV2}, without any dense convolutional operation and complex score prediction module. Our key design is to introduce four special prediction tokens and concatenate them with the tokens from target template and search areas. Then, we apply the unified transformer backbone on these mixed token sequence. These prediction tokens are able to capture the complex correlation between target template and search area via mixed attentions. Based on them, we can easily predict the tracking box and estimate its confidence score through simple MLP heads. To further improve the efficiency of MixFormerV2, we present a new distillation-based model reduction paradigm, including dense-to-sparse distillation and deep-to-shallow distillation. The former one aims to transfer knowledge from the dense-head based MixViT to our fully transformer tracker, while the latter one is used to prune some layers of the backbone. We instantiate two types of MixForemrV2, where the MixFormerV2-B achieves an AUC of 70.6\% on LaSOT and an AUC of 57.4\% on TNL2k with a high GPU speed of 165 FPS, and the MixFormerV2-S surpasses FEAR-L by 2.7\% AUC on LaSOT with a real-time CPU speed.
Condensed Prototype Replay for Class Incremental Learning
May 25, 2023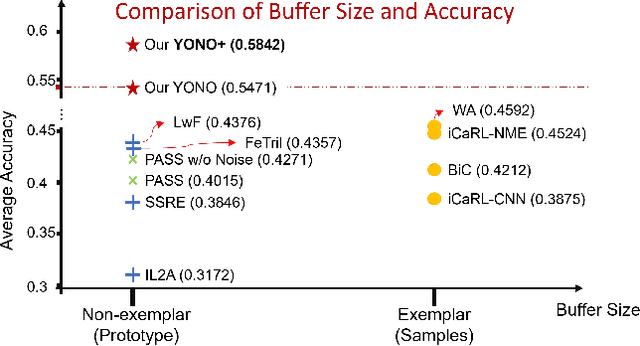
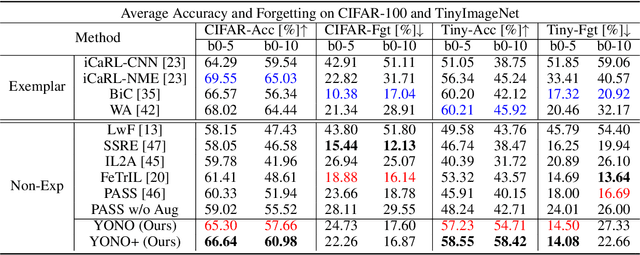
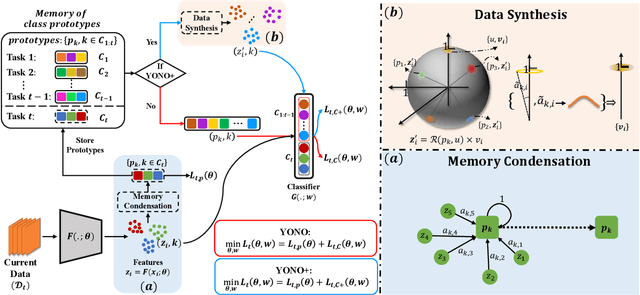
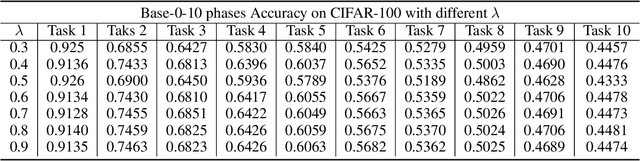
Incremental learning (IL) suffers from catastrophic forgetting of old tasks when learning new tasks. This can be addressed by replaying previous tasks' data stored in a memory, which however is usually prone to size limits and privacy leakage. Recent studies store only class centroids as prototypes and augment them with Gaussian noises to create synthetic data for replay. However, they cannot effectively avoid class interference near their margins that leads to forgetting. Moreover, the injected noises distort the rich structure between real data and prototypes, hence even detrimental to IL. In this paper, we propose YONO that You Only Need to replay One condensed prototype per class, which for the first time can even outperform memory-costly exemplar-replay methods. To this end, we develop a novel prototype learning method that (1) searches for more representative prototypes in high-density regions by an attentional mean-shift algorithm and (2) moves samples in each class to their prototype to form a compact cluster distant from other classes. Thereby, the class margins are maximized, which effectively reduces interference causing future forgetting. In addition, we extend YONO to YONO+, which creates synthetic replay data by random sampling in the neighborhood of each prototype in the representation space. We show that the synthetic data can further improve YONO. Extensive experiments on IL benchmarks demonstrate the advantages of YONO/YONO+ over existing IL methods in terms of both accuracy and forgetting.
Fake News Detection and Behavioral Analysis: Case of COVID-19
May 25, 2023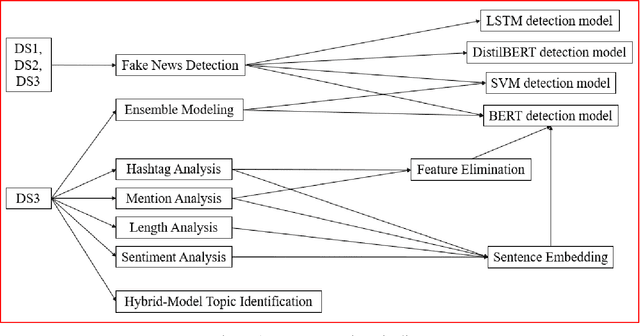


While the world has been combating COVID-19 for over three years, an ongoing "Infodemic" due to the spread of fake news regarding the pandemic has also been a global issue. The existence of the fake news impact different aspect of our daily lives, including politics, public health, economic activities, etc. Readers could mistake fake news for real news, and consequently have less access to authentic information. This phenomenon will likely cause confusion of citizens and conflicts in society. Currently, there are major challenges in fake news research. It is challenging to accurately identify fake news data in social media posts. In-time human identification is infeasible as the amount of the fake news data is overwhelming. Besides, topics discussed in fake news are hard to identify due to their similarity to real news. The goal of this paper is to identify fake news on social media to help stop the spread. We present Deep Learning approaches and an ensemble approach for fake news detection. Our detection models achieved higher accuracy than previous studies. The ensemble approach further improved the detection performance. We discovered feature differences between fake news and real news items. When we added them into the sentence embeddings, we found that they affected the model performance. We applied a hybrid method and built models for recognizing topics from posts. We found half of the identified topics were overlapping in fake news and real news, which could increase confusion in the population.