 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerating genetic optimization of nonlinear model predictive control by learning optimal search space size
May 14, 2023
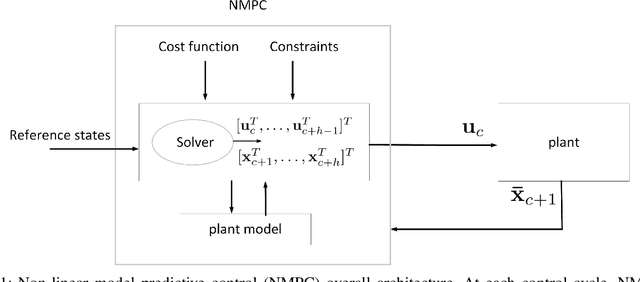
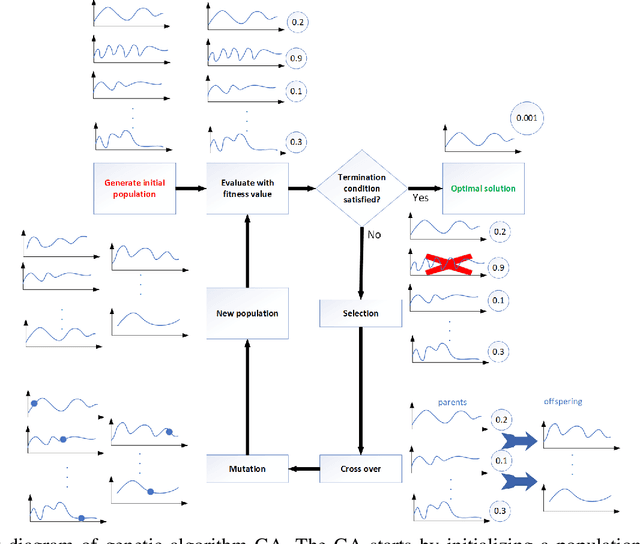
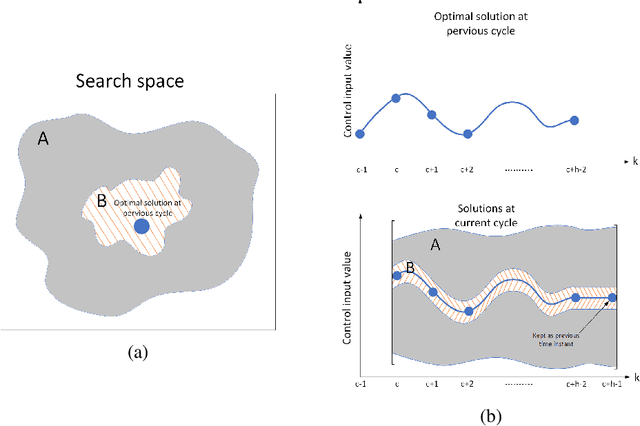
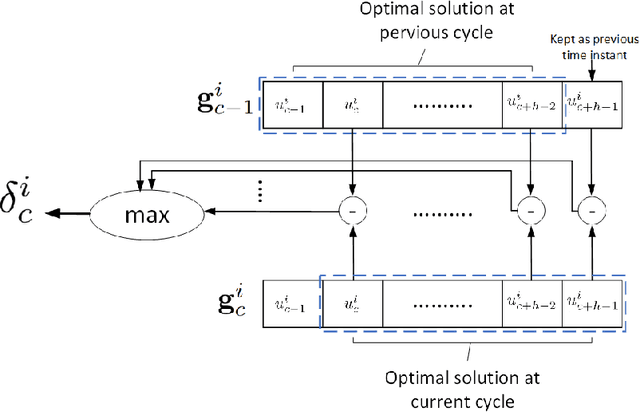
Nonlinear model predictive control (NMPC) solves a multivariate optimization problem to estimate the system's optimal control inputs in each control cycle. Such optimization is made more difficult by several factors, such as nonlinearities inherited in the system, highly coupled inputs, and various constraints related to the system's physical limitations. These factors make the optimization to be non-convex and hard to solve traditionally. Genetic algorithm (GA) is typically used extensively to tackle such optimization in several application domains because it does not involve differential calculation or gradient evaluation in its solution estimation. However, the size of the search space in which the GA searches for the optimal control inputs is crucial for the applicability of the GA with systems that require fast response. This paper proposes an approach to accelerate the genetic optimization of NMPC by learning optimal search space size. The proposed approach trains a multivariate regression model to adaptively predict the best smallest search space in every control cycle. The estimated best smallest size of search space is fed to the GA to allow for searching the optimal control inputs within this search space. The proposed approach not only reduces the GA's computational time but also improves the chance of obtaining the optimal control inputs in each cycle. The proposed approach was evaluated on two nonlinear systems and compared with two other genetic-based NMPC approaches implemented on the GPU of a Nvidia Jetson TX2 embedded platform in a processor-in-the-loop (PIL) fashion. The results show that the proposed approach provides a 39-53\% reduction in computational time. Additionally, it increases the convergence percentage to the optimal control inputs within the cycle's time by 48-56\%, resulting in a significant performance enhancement. The source code is available on GitHub.
Compositional Generalization without Trees using Multiset Tagging and Latent Permutations
May 26, 2023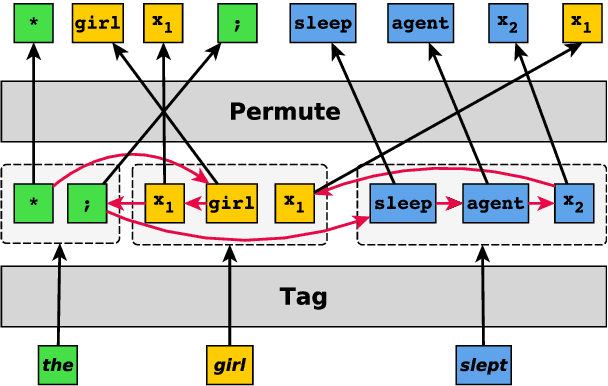
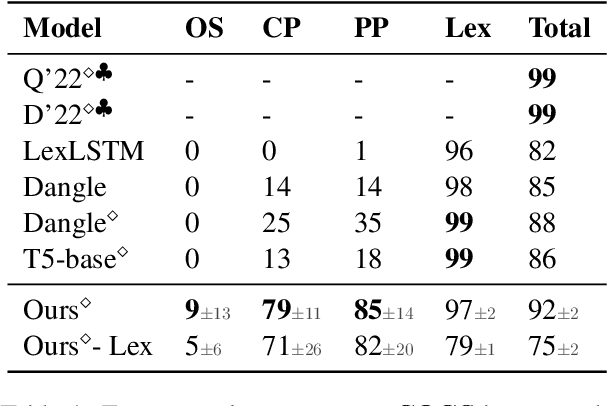

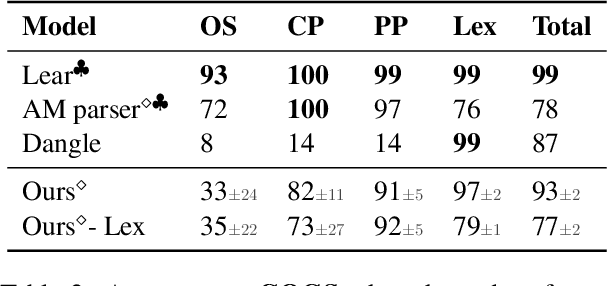
Seq2seq models have been shown to struggle with compositional generalization in semantic parsing, i.e. generalizing to unseen compositions of phenomena that the model handles correctly in isolation. We phrase semantic parsing as a two-step process: we first tag each input token with a multiset of output tokens. Then we arrange the tokens into an output sequence using a new way of parameterizing and predicting permutations. We formulate predicting a permutation as solving a regularized linear program and we backpropagate through the solver. In contrast to prior work, our approach does not place a priori restrictions on possible permutations, making it very expressive. Our model outperforms pretrained seq2seq models and prior work on realistic semantic parsing tasks that require generalization to longer examples. We also outperform non-tree-based models on structural generalization on the COGS benchmark. For the first time, we show that a model without an inductive bias provided by trees achieves high accuracy on generalization to deeper recursion.
Dramatic Conversation Disentanglement
May 26, 2023


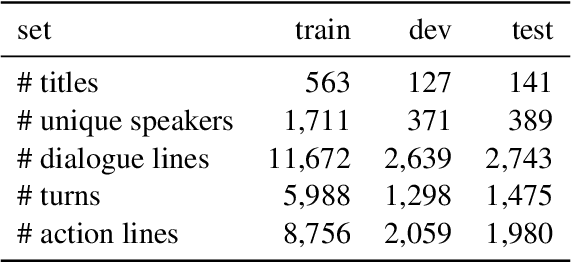
We present a new dataset for studying conversation disentanglement in movies and TV series. While previous work has focused on conversation disentanglement in IRC chatroom dialogues, movies and TV shows provide a space for studying complex pragmatic patterns of floor and topic change in face-to-face multi-party interactions. In this work, we draw on theoretical research in sociolinguistics, sociology, and film studies to operationalize a conversational thread (including the notion of a floor change) in dramatic texts, and use that definition to annotate a dataset of 10,033 dialogue turns (comprising 2,209 threads) from 831 movies. We compare the performance of several disentanglement models on this dramatic dataset, and apply the best-performing model to disentangle 808 movies. We see that, contrary to expectation, average thread lengths do not decrease significantly over the past 40 years, and characters portrayed by actors who are women, while underrepresented, initiate more new conversational threads relative to their speaking time.
Communication-Efficient Reinforcement Learning in Swarm Robotic Networks for Maze Exploration
May 26, 2023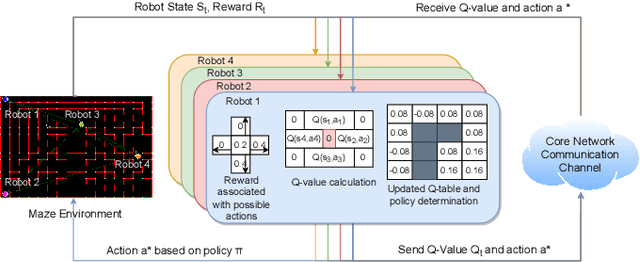
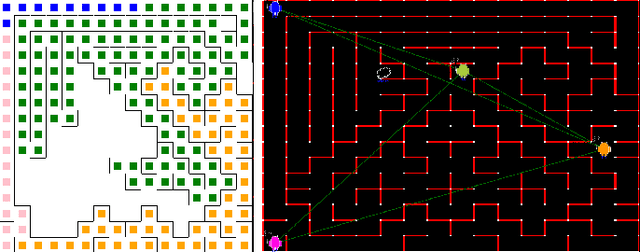
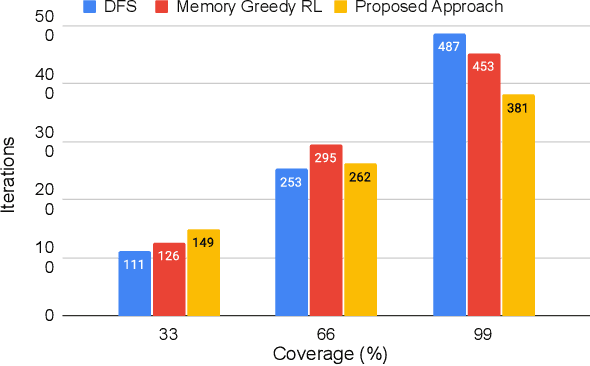
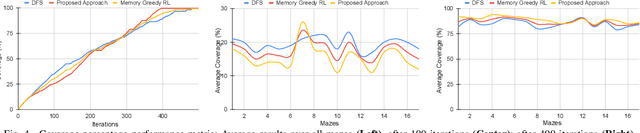
Smooth coordination within a swarm robotic system is essential for the effective execution of collective robot missions. Having efficient communication is key to the successful coordination of swarm robots. This paper proposes a new communication-efficient decentralized cooperative reinforcement learning algorithm for coordinating swarm robots. It is made efficient by hierarchically building on the use of local information exchanges. We consider a case study application of maze solving through cooperation among a group of robots, where the time and costs are minimized while avoiding inter-robot collisions and path overlaps during exploration. With a solid theoretical basis, we extensively analyze the algorithm with realistic CORE network simulations and evaluate it against state-of-the-art solutions in terms of maze coverage percentage and efficiency under communication-degraded environments. The results demonstrate significantly higher coverage accuracy and efficiency while reducing costs and overlaps even in high packet loss and low communication range scenarios.
AudioDec: An Open-source Streaming High-fidelity Neural Audio Codec
May 26, 2023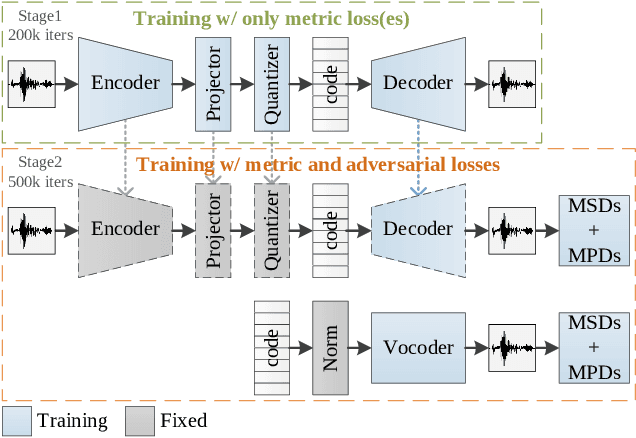
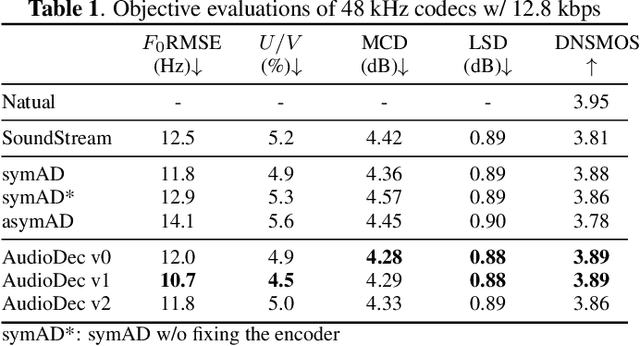

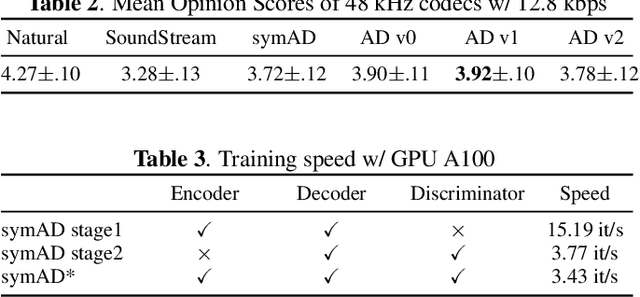
A good audio codec for live applications such as telecommunication is characterized by three key properties: (1) compression, i.e.\ the bitrate that is required to transmit the signal should be as low as possible; (2) latency, i.e.\ encoding and decoding the signal needs to be fast enough to enable communication without or with only minimal noticeable delay; and (3) reconstruction quality of the signal. In this work, we propose an open-source, streamable, and real-time neural audio codec that achieves strong performance along all three axes: it can reconstruct highly natural sounding 48~kHz speech signals while operating at only 12~kbps and running with less than 6~ms (GPU)/10~ms (CPU) latency. An efficient training paradigm is also demonstrated for developing such neural audio codecs for real-world scenarios. Both objective and subjective evaluations using the VCTK corpus are provided. To sum up, AudioDec is a well-developed plug-and-play benchmark for audio codec applications.
Flow Matching for Scalable Simulation-Based Inference
May 26, 2023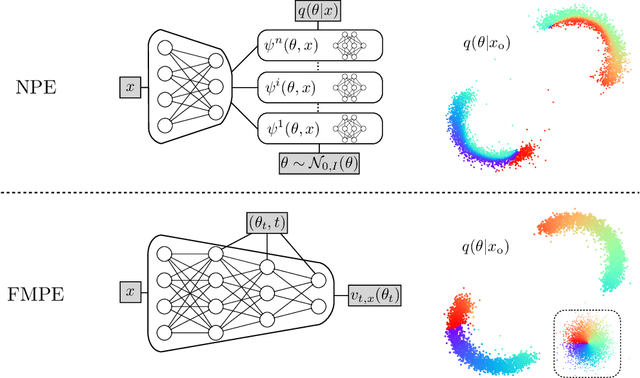

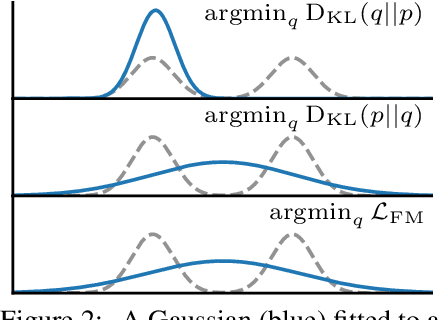

Neural posterior estimation methods based on discrete normalizing flows have become established tools for simulation-based inference (SBI), but scaling them to high-dimensional problems can be challenging. Building on recent advances in generative modeling, we here present flow matching posterior estimation (FMPE), a technique for SBI using continuous normalizing flows. Like diffusion models, and in contrast to discrete flows, flow matching allows for unconstrained architectures, providing enhanced flexibility for complex data modalities. Flow matching, therefore, enables exact density evaluation, fast training, and seamless scalability to large architectures--making it ideal for SBI. We show that FMPE achieves competitive performance on an established SBI benchmark, and then demonstrate its improved scalability on a challenging scientific problem: for gravitational-wave inference, FMPE outperforms methods based on comparable discrete flows, reducing training time by 30% with substantially improved accuracy. Our work underscores the potential of FMPE to enhance performance in challenging inference scenarios, thereby paving the way for more advanced applications to scientific problems.
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023
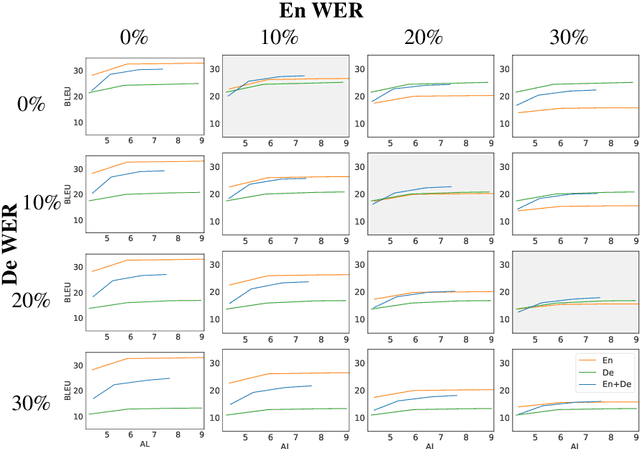

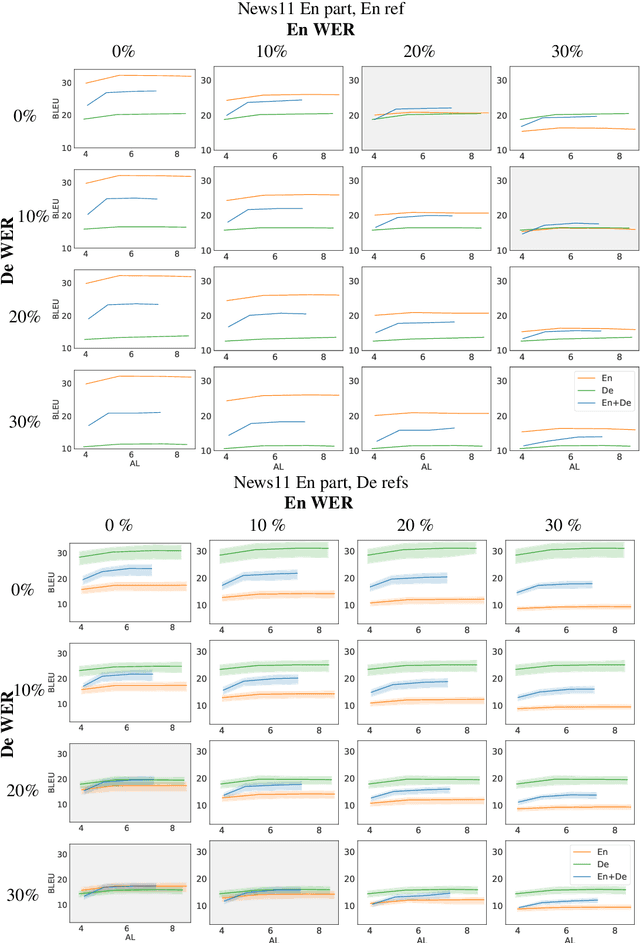
Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
Sample-efficient Real-time Planning with Curiosity Cross-Entropy Method and Contrastive Learning
Mar 07, 2023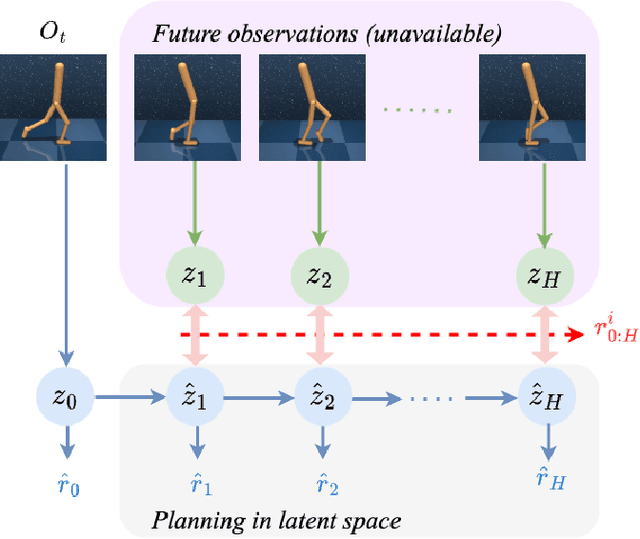
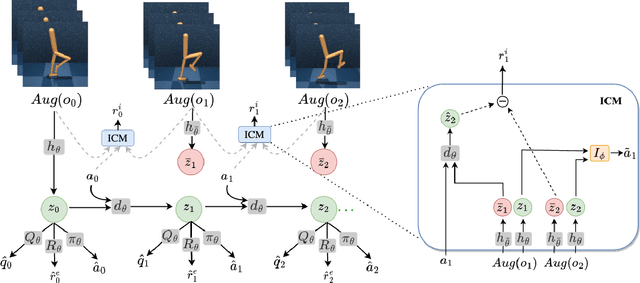

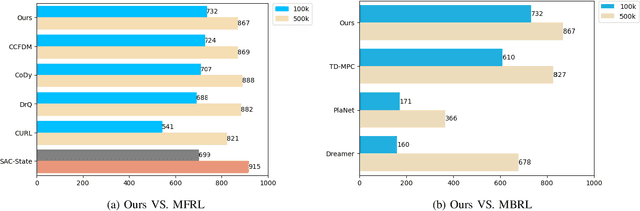
Model-based reinforcement learning (MBRL) with real-time planning has shown great potential in locomotion and manipulation control tasks. However, the existing planning methods, such as the Cross-Entropy Method (CEM), do not scale well to complex high-dimensional environments. One of the key reasons for underperformance is the lack of exploration, as these planning methods only aim to maximize the cumulative extrinsic reward over the planning horizon. Furthermore, planning inside the compact latent space in the absence of observations makes it challenging to use curiosity-based intrinsic motivation. We propose Curiosity CEM (CCEM), an improved version of the CEM algorithm for encouraging exploration via curiosity. Our proposed method maximizes the sum of state-action Q values over the planning horizon, in which these Q values estimate the future extrinsic and intrinsic reward, hence encouraging reaching novel observations. In addition, our model uses contrastive representation learning to efficiently learn latent representations. Experiments on image-based continuous control tasks from the DeepMind Control suite show that CCEM is by a large margin more sample-efficient than previous MBRL algorithms and compares favorably with the best model-free RL methods.
Probabilistic RRT Connect with intermediate goal selection for online planning of autonomous vehicles
May 14, 2023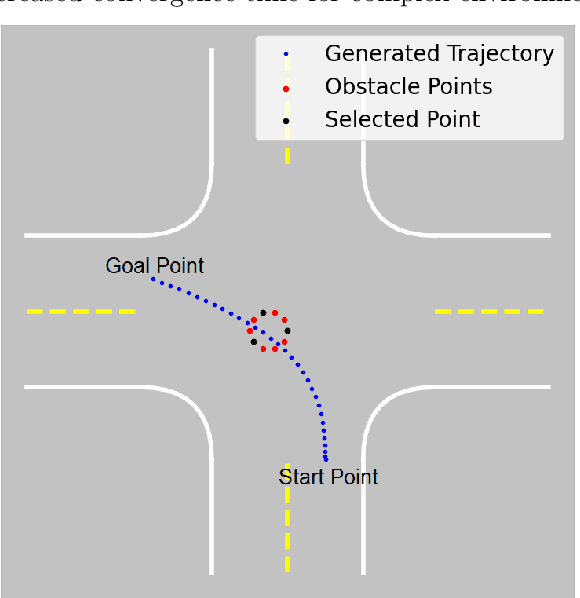
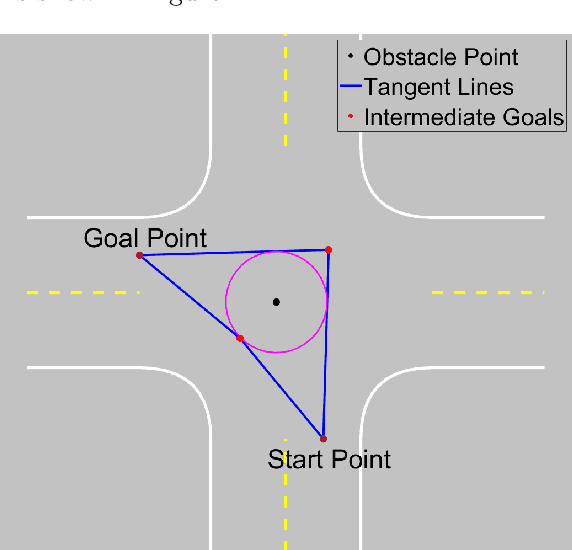
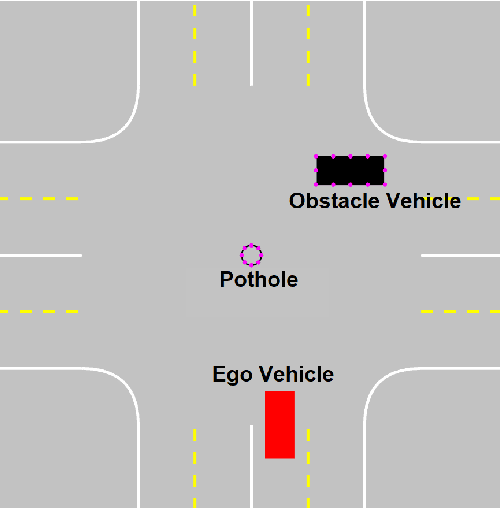
Rapidly Exploring Random Trees (RRT) is one of the most widely used algorithms for motion planning in the field of robotics. To reduce the exploration time, RRT-Connect was introduced where two trees are simultaneously formed and eventually connected. Probabilistic RRT used the concept of position probability map to introduce goal biasing for faster convergence. In this paper, we propose a modified method to combine the pRRT and RRT-Connect techniques and obtain a feasible trajectory around the obstacles quickly. Instead of forming a single tree from the start point to the destination point, intermediate goal points are selected around the obstacles. Multiple trees are formed to connect the start, destination, and intermediate goal points. These partial trees are eventually connected to form an overall safe path around the obstacles. The obtained path is tracked using an MPC + Stanley controller which results in a trajectory with control commands at each time step. The trajectories generated by the proposed methods are more optimal and in accordance with human intuition. The algorithm is compared with the standard RRT and pRRT for studying its relative performance.
Distilling Efficient Language-Specific Models for Cross-Lingual Transfer
Jun 02, 2023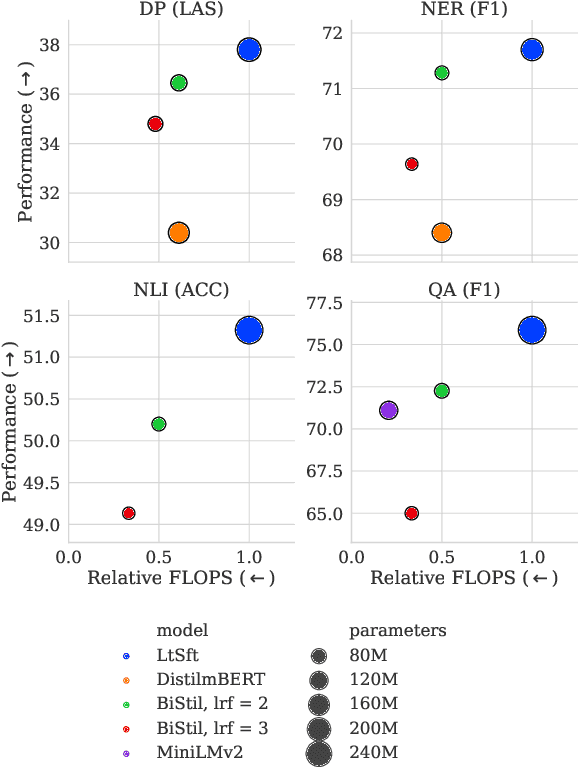
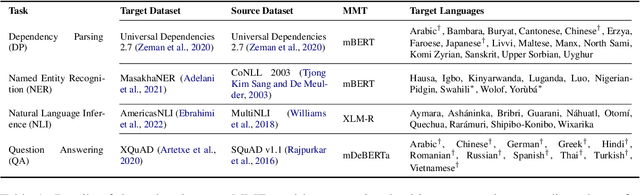
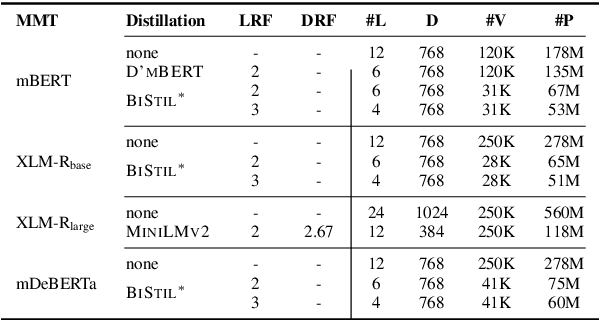

Massively multilingual Transformers (MMTs), such as mBERT and XLM-R, are widely used for cross-lingual transfer learning. While these are pretrained to represent hundreds of languages, end users of NLP systems are often interested only in individual languages. For such purposes, the MMTs' language coverage makes them unnecessarily expensive to deploy in terms of model size, inference time, energy, and hardware cost. We thus propose to extract compressed, language-specific models from MMTs which retain the capacity of the original MMTs for cross-lingual transfer. This is achieved by distilling the MMT bilingually, i.e., using data from only the source and target language of interest. Specifically, we use a two-phase distillation approach, termed BiStil: (i) the first phase distils a general bilingual model from the MMT, while (ii) the second, task-specific phase sparsely fine-tunes the bilingual "student" model using a task-tuned variant of the original MMT as its "teacher". We evaluate this distillation technique in zero-shot cross-lingual transfer across a number of standard cross-lingual benchmarks. The key results indicate that the distilled models exhibit minimal degradation in target language performance relative to the base MMT despite being significantly smaller and faster. Furthermore, we find that they outperform multilingually distilled models such as DistilmBERT and MiniLMv2 while having a very modest training budget in comparison, even on a per-language basis. We also show that bilingual models distilled from MMTs greatly outperform bilingual models trained from scratch. Our code and models are available at https://github.com/AlanAnsell/bistil.