 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Agreement Tracking for Multi-Issue Negotiation Dialogues
Jul 13, 2023
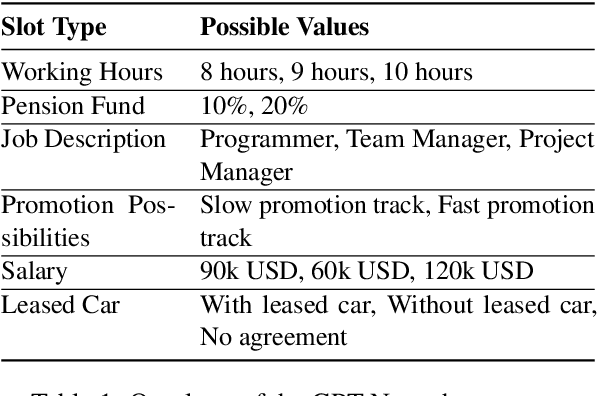


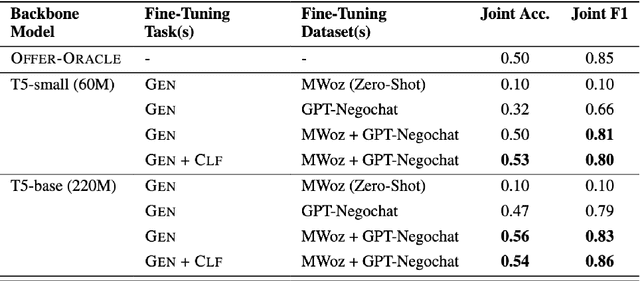
Automated negotiation support systems aim to help human negotiators reach more favorable outcomes in multi-issue negotiations (e.g., an employer and a candidate negotiating over issues such as salary, hours, and promotions before a job offer). To be successful, these systems must accurately track agreements reached by participants in real-time. Existing approaches either focus on task-oriented dialogues or produce unstructured outputs, rendering them unsuitable for this objective. Our work introduces the novel task of agreement tracking for two-party multi-issue negotiations, which requires continuous monitoring of agreements within a structured state space. To address the scarcity of annotated corpora with realistic multi-issue negotiation dialogues, we use GPT-3 to build GPT-Negochat, a synthesized dataset that we make publicly available. We present a strong initial baseline for our task by transfer-learning a T5 model trained on the MultiWOZ 2.4 corpus. Pre-training T5-small and T5-base on MultiWOZ 2.4's DST task enhances results by 21% and 9% respectively over training solely on GPT-Negochat. We validate our method's sample-efficiency via smaller training subset experiments. By releasing GPT-Negochat and our baseline models, we aim to encourage further research in multi-issue negotiation dialogue agreement tracking.
Energy-Efficient Mining for Blockchain-Enabled IoT Applications. An Optimal Multiple-Stopping Time Approach
May 09, 2023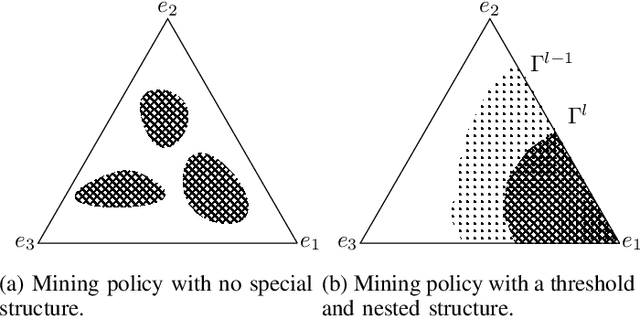
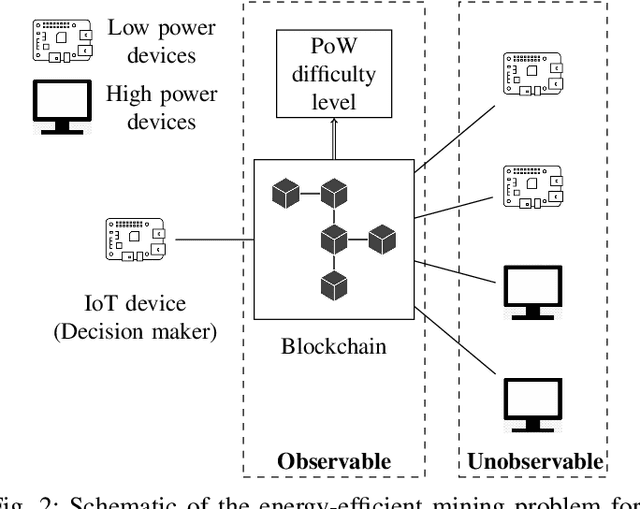

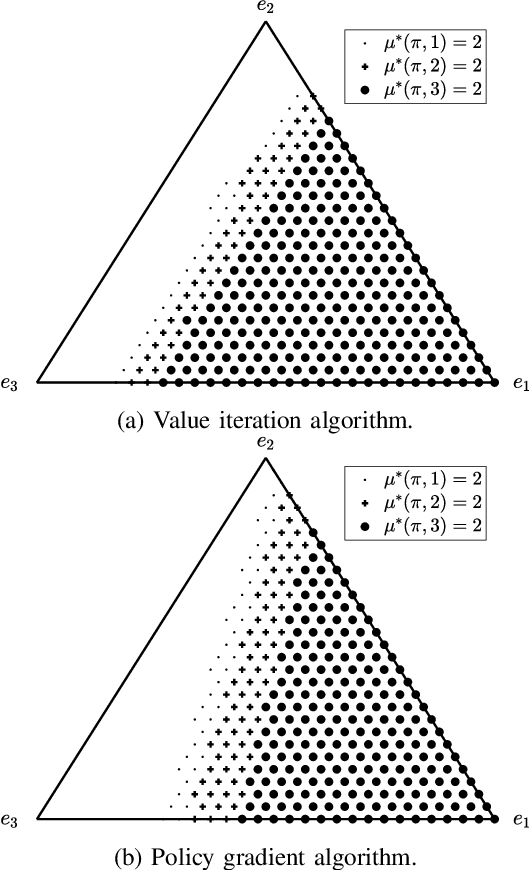
What are the optimal times for an Internet of Things (IoT) device to act as a blockchain miner? The aim is to minimize the energy consumed by low-power IoT devices that log their data into a secure (tamper-proof) distributed ledger. We formulate the energy-efficient blockchain mining for IoT devices as a multiple-stopping time partially observed Markov decision process (POMDP) to maximize the probability of adding a block in the blockchain; we also present a model to optimize the number of stops (mining instants). In general, POMDPs are computationally intractable to solve, but we show mathematically using submodularity that the optimal mining policy has a useful structure: 1) it is monotone in belief space, and 2) it exhibits a threshold structure, which divides the belief space into two connected sets. Exploiting the structural results, we formulate a computationally-efficient linear mining policy for the blockchain-enabled IoT device. We present a policy gradient technique to optimize the parameters of the linear mining policy. Finally, we use synthetic and real Bitcoin datasets to study the performance of our proposed mining policy. We demonstrate the energy efficiency achieved by the optimal linear mining policy in contrast to other heuristic strategies.
Reliable Learning for Test-time Attacks and Distribution Shift
Apr 06, 2023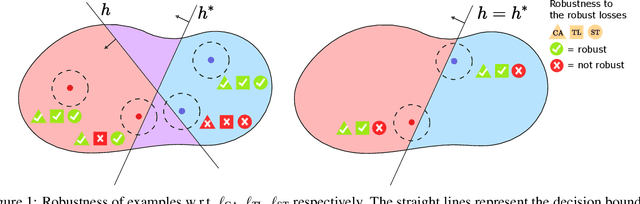
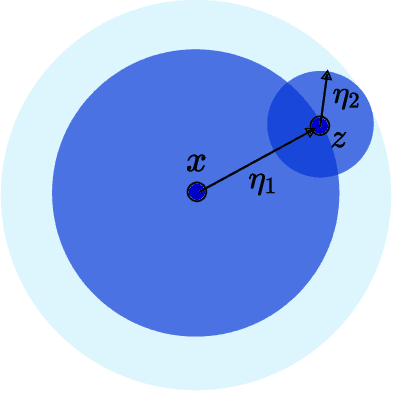
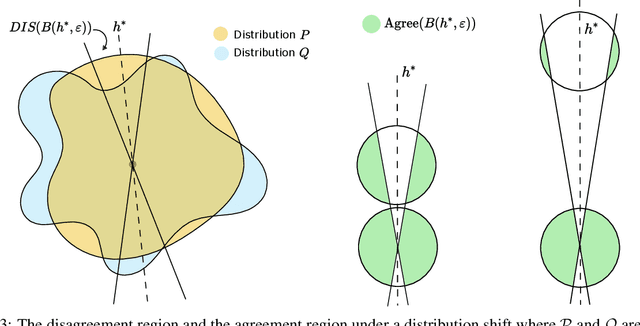
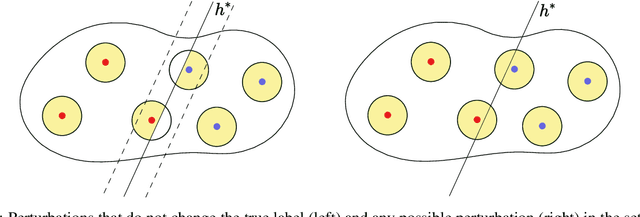
Machine learning algorithms are often used in environments which are not captured accurately even by the most carefully obtained training data, either due to the possibility of `adversarial' test-time attacks, or on account of `natural' distribution shift. For test-time attacks, we introduce and analyze a novel robust reliability guarantee, which requires a learner to output predictions along with a reliability radius $\eta$, with the meaning that its prediction is guaranteed to be correct as long as the adversary has not perturbed the test point farther than a distance $\eta$. We provide learners that are optimal in the sense that they always output the best possible reliability radius on any test point, and we characterize the reliable region, i.e. the set of points where a given reliability radius is attainable. We additionally analyze reliable learners under distribution shift, where the test points may come from an arbitrary distribution Q different from the training distribution P. For both cases, we bound the probability mass of the reliable region for several interesting examples, for linear separators under nearly log-concave and s-concave distributions, as well as for smooth boundary classifiers under smooth probability distributions.
DeepMem: ML Models as storage channels and their (mis-)applications
Jul 17, 2023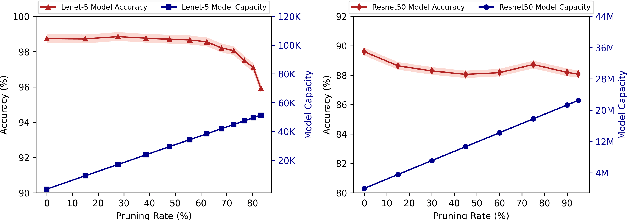
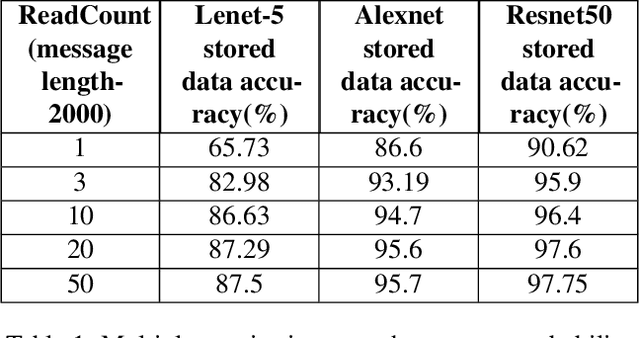
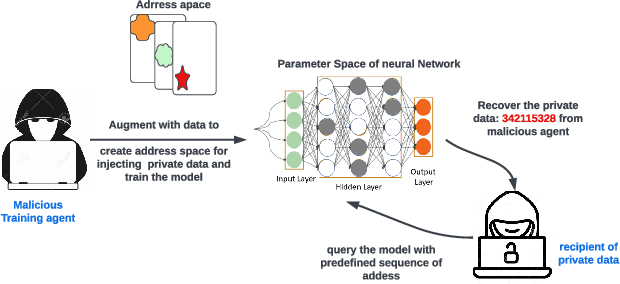
Machine learning (ML) models are overparameterized to support generality and avoid overfitting. Prior works have shown that these additional parameters can be used for both malicious (e.g., hiding a model covertly within a trained model) and beneficial purposes (e.g., watermarking a model). In this paper, we propose a novel information theoretic perspective of the problem; we consider the ML model as a storage channel with a capacity that increases with overparameterization. Specifically, we consider a sender that embeds arbitrary information in the model at training time, which can be extracted by a receiver with a black-box access to the deployed model. We derive an upper bound on the capacity of the channel based on the number of available parameters. We then explore black-box write and read primitives that allow the attacker to: (i) store data in an optimized way within the model by augmenting the training data at the transmitter side, and (ii) to read it by querying the model after it is deployed. We also analyze the detectability of the writing primitive and consider a new version of the problem which takes information storage covertness into account. Specifically, to obtain storage covertness, we introduce a new constraint such that the data augmentation used for the write primitives minimizes the distribution shift with the initial (baseline task) distribution. This constraint introduces a level of "interference" with the initial task, thereby limiting the channel's effective capacity. Therefore, we develop optimizations to improve the capacity in this case, including a novel ML-specific substitution based error correction protocol. We believe that the proposed modeling of the problem offers new tools to better understand and mitigate potential vulnerabilities of ML, especially in the context of increasingly large models.
Real Time Bearing Fault Diagnosis Based on Convolutional Neural Network and STM32 Microcontroller
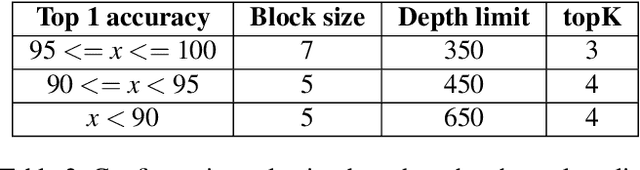
Apr 14, 2023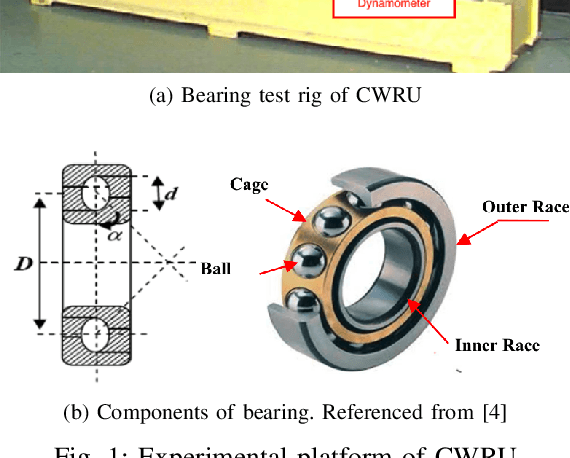
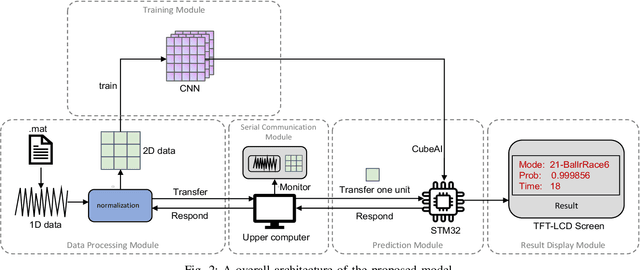
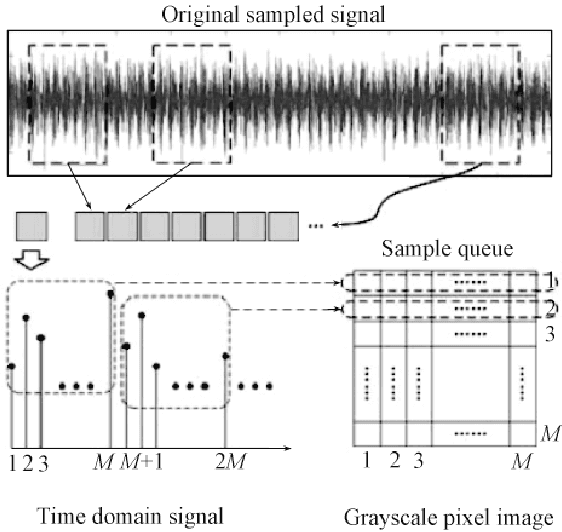
With the rapid development of big data and edge computing, many researchers focus on improving the accuracy of bearing fault classification using deep learning models, and implementing the deep learning classification model on limited resource platforms such as STM32. To this end, this paper realizes the identification of bearing fault vibration signal based on convolutional neural network, the fault identification accuracy of the optimised model can reach 98.9%. In addition, this paper successfully applies the convolutional neural network model to STM32H743VI microcontroller, the running time of each diagnosis is 19ms. Finally, a complete real-time communication framework between the host computer and the STM32 is designed, which can perfectly complete the data transmission through the serial port and display the diagnosis results on the TFT-LCD screen.
Detection and Estimation of Structural Breaks in High-Dimensional Functional Time Series
Apr 14, 2023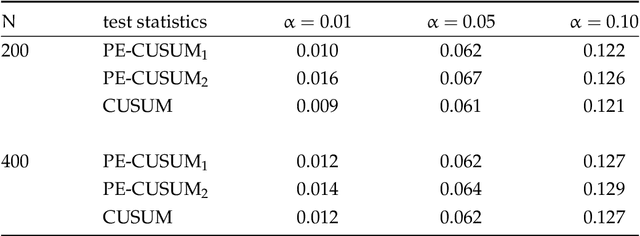
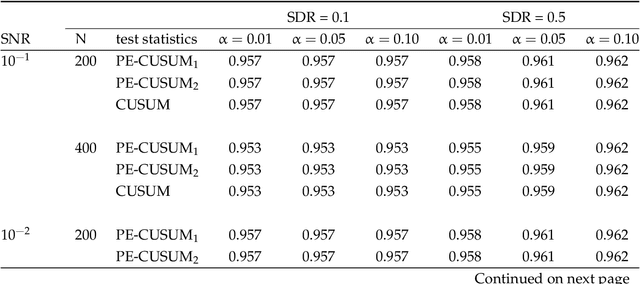
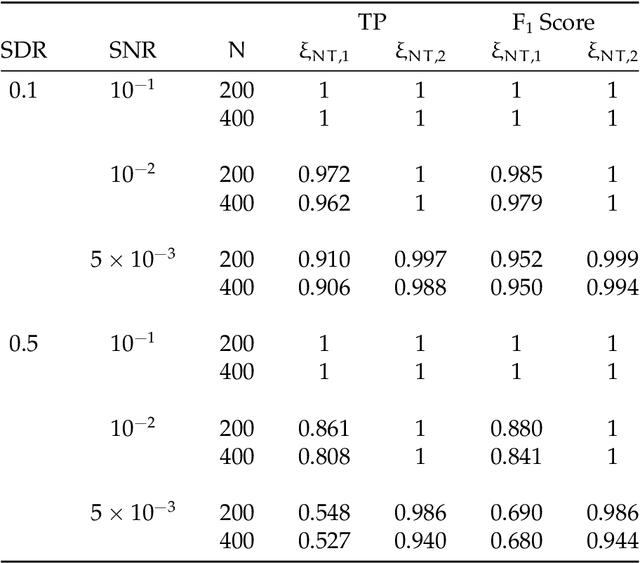
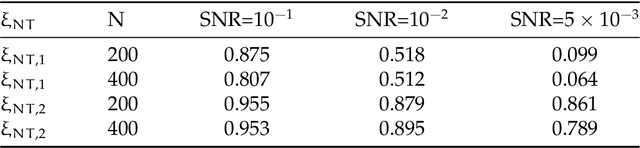
In this paper, we consider detecting and estimating breaks in heterogeneous mean functions of high-dimensional functional time series which are allowed to be cross-sectionally correlated and temporally dependent. A new test statistic combining the functional CUSUM statistic and power enhancement component is proposed with asymptotic null distribution theory comparable to the conventional CUSUM theory derived for a single functional time series. In particular, the extra power enhancement component enlarges the region where the proposed test has power, and results in stable power performance when breaks are sparse in the alternative hypothesis. Furthermore, we impose a latent group structure on the subjects with heterogeneous break points and introduce an easy-to-implement clustering algorithm with an information criterion to consistently estimate the unknown group number and membership. The estimated group structure can subsequently improve the convergence property of the post-clustering break point estimate. Monte-Carlo simulation studies and empirical applications show that the proposed estimation and testing techniques have satisfactory performance in finite samples.
Finite Time Lyapunov Exponent Analysis of Model Predictive Control and Reinforcement Learning
Apr 10, 2023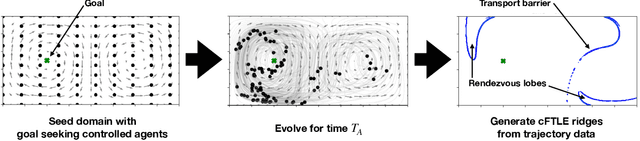
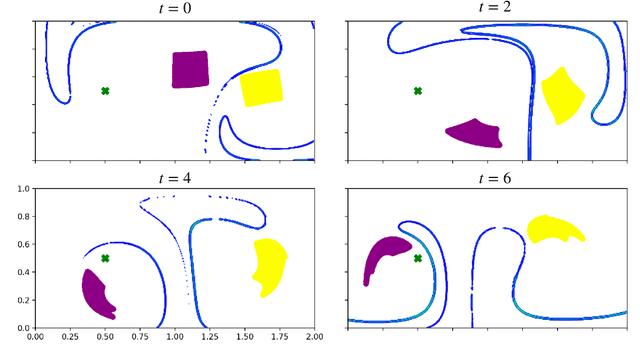
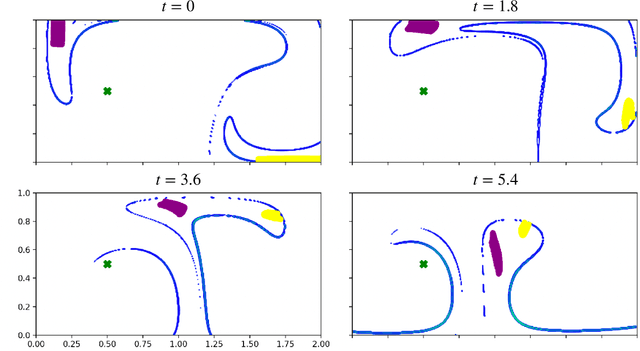
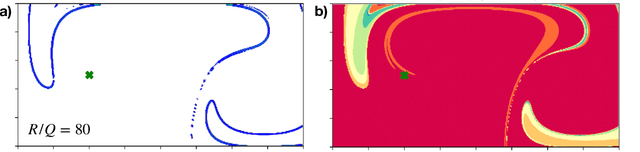
Finite-time Lyapunov exponents (FTLEs) provide a powerful approach to compute time-varying analogs of invariant manifolds in unsteady fluid flow fields. These manifolds are useful to visualize the transport mechanisms of passive tracers advecting with the flow. However, many vehicles and mobile sensors are not passive, but are instead actuated according to some intelligent trajectory planning or control law; for example, model predictive control and reinforcement learning are often used to design energy-efficient trajectories in a dynamically changing background flow. In this work, we investigate the use of FTLE on such controlled agents to gain insight into optimal transport routes for navigation in known unsteady flows. We find that these controlled FTLE (cFTLE) coherent structures separate the flow field into different regions with similar costs of transport to the goal location. These separatrices are functions of the planning algorithm's hyper-parameters, such as the optimization time horizon and the cost of actuation. Computing the invariant sets and manifolds of active agent dynamics in dynamic flow fields is useful in the context of robust motion control, hyperparameter tuning, and determining safe and collision-free trajectories for autonomous systems. Moreover, these cFTLE structures provide insight into effective deployment locations for mobile agents with actuation and energy constraints to traverse the ocean or atmosphere.
Volumetric Occupancy Detection: A Comparative Analysis of Mapping Algorithms
Jul 06, 2023Despite the growing interest in innovative functionalities for collaborative robotics, volumetric detection remains indispensable for ensuring basic security. However, there is a lack of widely used volumetric detection frameworks specifically tailored to this domain, and existing evaluation metrics primarily focus on time and memory efficiency. To bridge this gap, the authors present a detailed comparison using a simulation environment, ground truth extraction, and automated evaluation metrics calculation. This enables the evaluation of state-of-the-art volumetric mapping algorithms, including OctoMap, SkiMap, and Voxblox, providing valuable insights and comparisons through the impact of qualitative and quantitative analyses. The study not only compares different frameworks but also explores various parameters within each framework, offering additional insights into their performance.
KECOR: Kernel Coding Rate Maximization for Active 3D Object Detection
Jul 16, 2023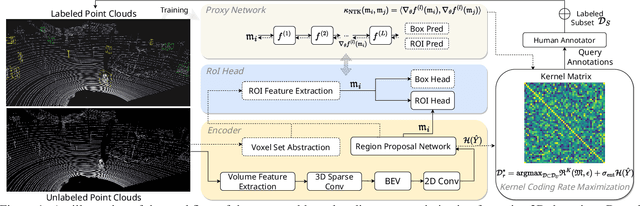
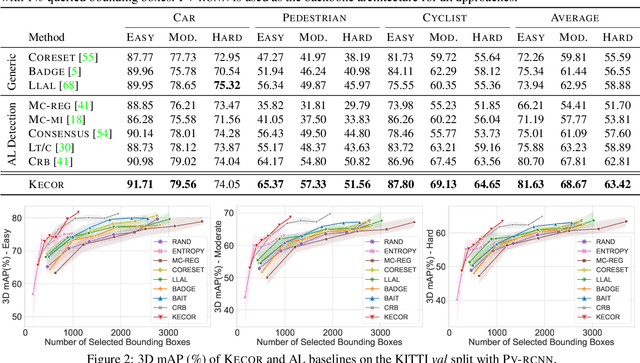
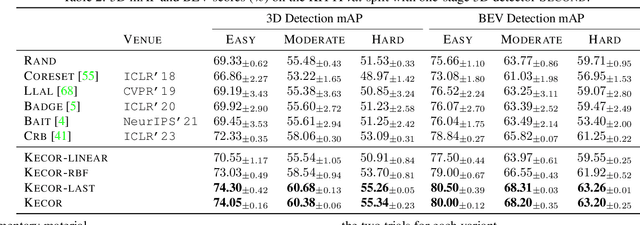
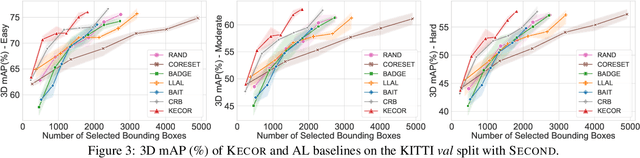
Achieving a reliable LiDAR-based object detector in autonomous driving is paramount, but its success hinges on obtaining large amounts of precise 3D annotations. Active learning (AL) seeks to mitigate the annotation burden through algorithms that use fewer labels and can attain performance comparable to fully supervised learning. Although AL has shown promise, current approaches prioritize the selection of unlabeled point clouds with high uncertainty and/or diversity, leading to the selection of more instances for labeling and reduced computational efficiency. In this paper, we resort to a novel kernel coding rate maximization (KECOR) strategy which aims to identify the most informative point clouds to acquire labels through the lens of information theory. Greedy search is applied to seek desired point clouds that can maximize the minimal number of bits required to encode the latent features. To determine the uniqueness and informativeness of the selected samples from the model perspective, we construct a proxy network of the 3D detector head and compute the outer product of Jacobians from all proxy layers to form the empirical neural tangent kernel (NTK) matrix. To accommodate both one-stage (i.e., SECOND) and two-stage detectors (i.e., PVRCNN), we further incorporate the classification entropy maximization and well trade-off between detection performance and the total number of bounding boxes selected for annotation. Extensive experiments conducted on two 3D benchmarks and a 2D detection dataset evidence the superiority and versatility of the proposed approach. Our results show that approximately 44% box-level annotation costs and 26% computational time are reduced compared to the state-of-the-art AL method, without compromising detection performance.
Planting a SEED of Vision in Large Language Model
Jul 16, 2023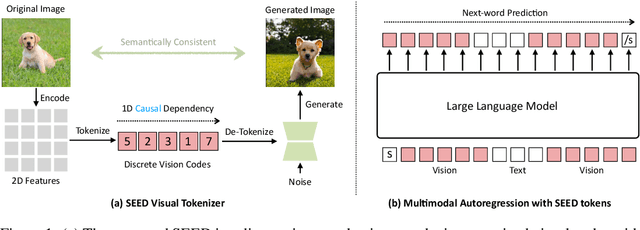


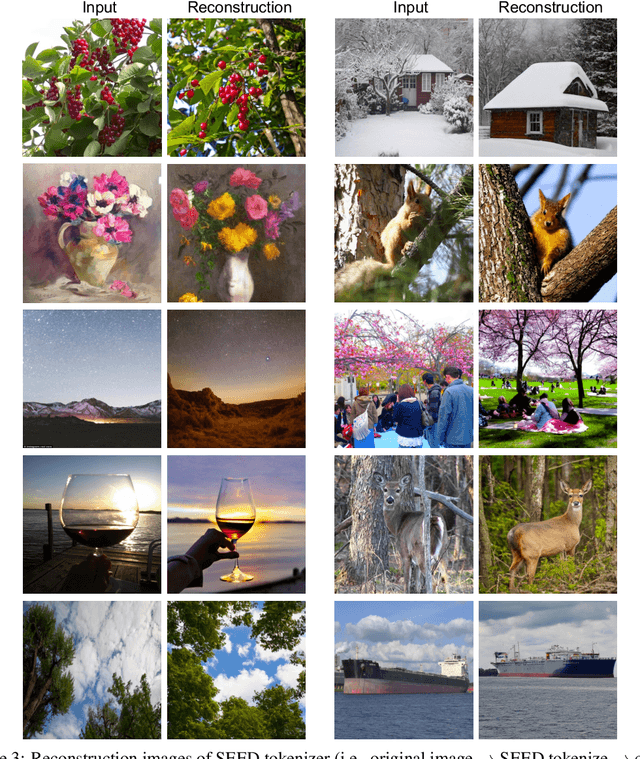
We present SEED, an elaborate image tokenizer that empowers Large Language Models (LLMs) with the emergent ability to SEE and Draw at the same time. Research on image tokenizers has previously reached an impasse, as frameworks employing quantized visual tokens have lost prominence due to subpar performance and convergence in multimodal comprehension (compared to BLIP-2, etc.) or generation (compared to Stable Diffusion, etc.). Despite the limitations, we remain confident in its natural capacity to unify visual and textual representations, facilitating scalable multimodal training with LLM's original recipe. In this study, we identify two crucial principles for the architecture and training of SEED that effectively ease subsequent alignment with LLMs. (1) Image tokens should be independent of 2D physical patch positions and instead be produced with a 1D causal dependency, exhibiting intrinsic interdependence that aligns with the left-to-right autoregressive prediction mechanism in LLMs. (2) Image tokens should capture high-level semantics consistent with the degree of semantic abstraction in words, and be optimized for both discriminativeness and reconstruction during the tokenizer training phase. As a result, the off-the-shelf LLM is able to perform both image-to-text and text-to-image generation by incorporating our SEED through efficient LoRA tuning. Comprehensive multimodal pretraining and instruction tuning, which may yield improved results, are reserved for future investigation. This version of SEED was trained in 5.7 days using only 64 V100 GPUs and 5M publicly available image-text pairs. Our preliminary study emphasizes the great potential of discrete visual tokens in versatile multimodal LLMs and the importance of proper image tokenizers in broader research.