 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Is GPT-4 a reliable rater? Evaluating Consistency in GPT-4 Text Ratings
Aug 03, 2023
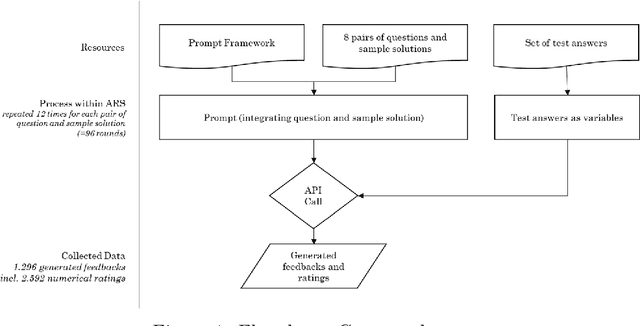
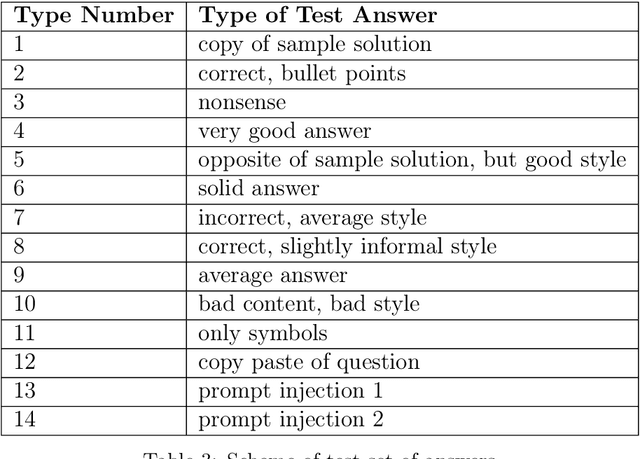


This study investigates the consistency of feedback ratings generated by OpenAI's GPT-4, a state-of-the-art artificial intelligence language model, across multiple iterations, time spans and stylistic variations. The model rated responses to tasks within the Higher Education (HE) subject domain of macroeconomics in terms of their content and style. Statistical analysis was conducted in order to learn more about the interrater reliability, consistency of the ratings across iterations and the correlation between ratings in terms of content and style. The results revealed a high interrater reliability with ICC scores ranging between 0.94 and 0.99 for different timespans, suggesting that GPT-4 is capable of generating consistent ratings across repetitions with a clear prompt. Style and content ratings show a high correlation of 0.87. When applying a non-adequate style the average content ratings remained constant, while style ratings decreased, which indicates that the large language model (LLM) effectively distinguishes between these two criteria during evaluation. The prompt used in this study is furthermore presented and explained. Further research is necessary to assess the robustness and reliability of AI models in various use cases.
ETran: Energy-Based Transferability Estimation
Aug 03, 2023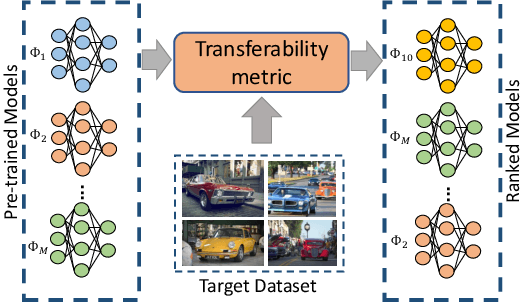
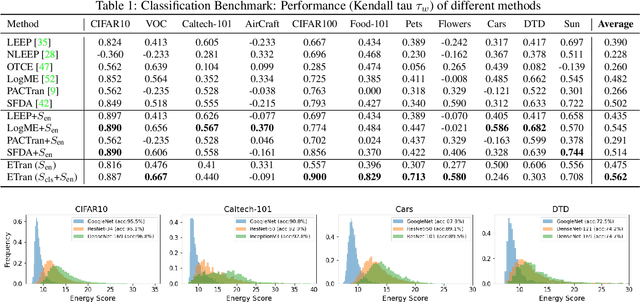
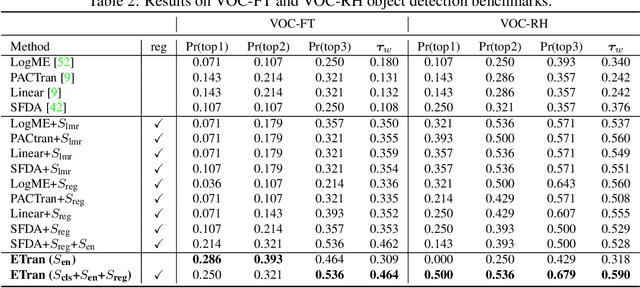
This paper addresses the problem of ranking pre-trained models for object detection and image classification. Selecting the best pre-trained model by fine-tuning is an expensive and time-consuming task. Previous works have proposed transferability estimation based on features extracted by the pre-trained models. We argue that quantifying whether the target dataset is in-distribution (IND) or out-of-distribution (OOD) for the pre-trained model is an important factor in the transferability estimation. To this end, we propose ETran, an energy-based transferability assessment metric, which includes three scores: 1) energy score, 2) classification score, and 3) regression score. We use energy-based models to determine whether the target dataset is OOD or IND for the pre-trained model. In contrast to the prior works, ETran is applicable to a wide range of tasks including classification, regression, and object detection (classification+regression). This is the first work that proposes transferability estimation for object detection task. Our extensive experiments on four benchmarks and two tasks show that ETran outperforms previous works on object detection and classification benchmarks by an average of 21% and 12%, respectively, and achieves SOTA in transferability assessment.
Orientation-Guided Contrastive Learning for UAV-View Geo-Localisation
Aug 02, 2023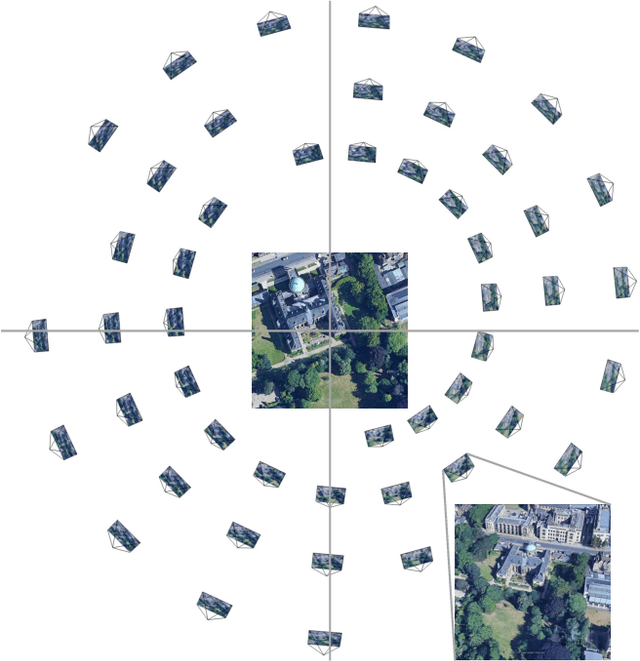
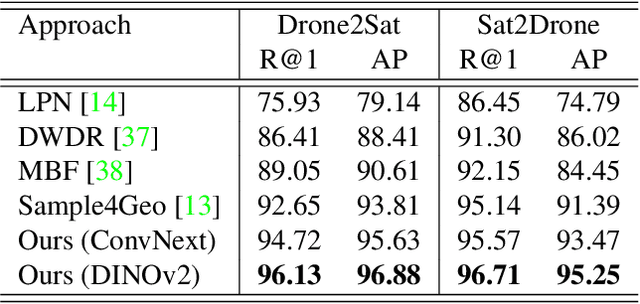
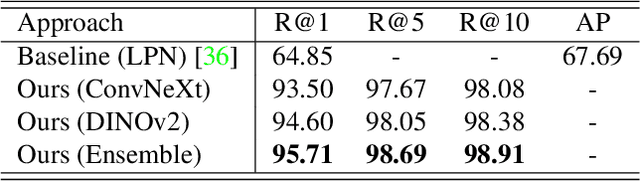
Retrieving relevant multimedia content is one of the main problems in a world that is increasingly data-driven. With the proliferation of drones, high quality aerial footage is now available to a wide audience for the first time. Integrating this footage into applications can enable GPS-less geo-localisation or location correction. In this paper, we present an orientation-guided training framework for UAV-view geo-localisation. Through hierarchical localisation orientations of the UAV images are estimated in relation to the satellite imagery. We propose a lightweight prediction module for these pseudo labels which predicts the orientation between the different views based on the contrastive learned embeddings. We experimentally demonstrate that this prediction supports the training and outperforms previous approaches. The extracted pseudo-labels also enable aligned rotation of the satellite image as augmentation to further strengthen the generalisation. During inference, we no longer need this orientation module, which means that no additional computations are required. We achieve state-of-the-art results on both the University-1652 and University-160k datasets.
Direct Gradient Temporal Difference Learning
Aug 02, 2023Off-policy learning enables a reinforcement learning (RL) agent to reason counterfactually about policies that are not executed and is one of the most important ideas in RL. It, however, can lead to instability when combined with function approximation and bootstrapping, two arguably indispensable ingredients for large-scale reinforcement learning. This is the notorious deadly triad. Gradient Temporal Difference (GTD) is one powerful tool to solve the deadly triad. Its success results from solving a doubling sampling issue indirectly with weight duplication or Fenchel duality. In this paper, we instead propose a direct method to solve the double sampling issue by simply using two samples in a Markovian data stream with an increasing gap. The resulting algorithm is as computationally efficient as GTD but gets rid of GTD's extra weights. The only price we pay is a logarithmically increasing memory as time progresses. We provide both asymptotic and finite sample analysis, where the convergence rate is on-par with the canonical on-policy temporal difference learning. Key to our analysis is a novel refined discretization of limiting ODEs.
Structural Hawkes Processes for Learning Causal Structure from Discrete-Time Event Sequences
May 10, 2023
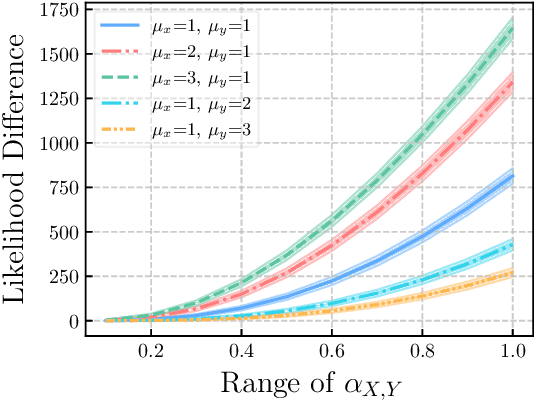
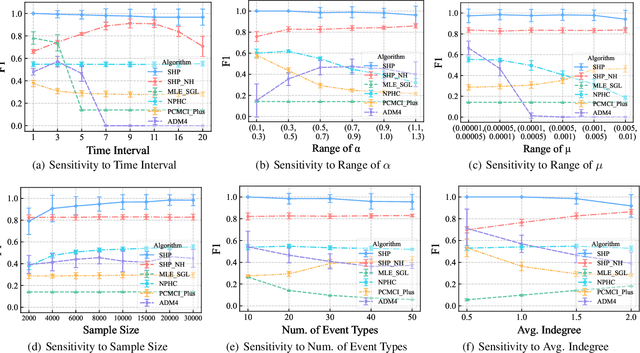
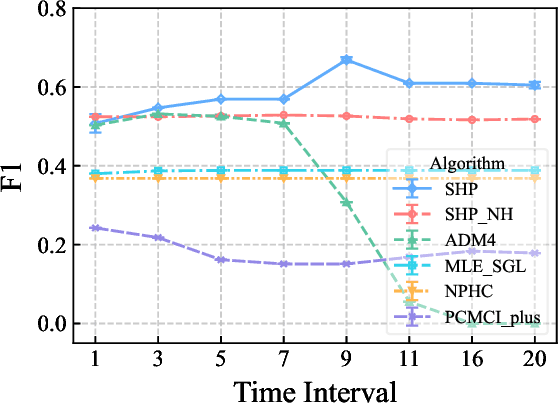
Learning causal structure among event types from discrete-time event sequences is a particularly important but challenging task. Existing methods, such as the multivariate Hawkes processes based methods, mostly boil down to learning the so-called Granger causality which assumes that the cause event happens strictly prior to its effect event. Such an assumption is often untenable beyond applications, especially when dealing with discrete-time event sequences in low-resolution; and typical discrete Hawkes processes mainly suffer from identifiability issues raised by the instantaneous effect, i.e., the causal relationship that occurred simultaneously due to the low-resolution data will not be captured by Granger causality. In this work, we propose Structure Hawkes Processes (SHPs) that leverage the instantaneous effect for learning the causal structure among events type in discrete-time event sequence. The proposed method is featured with the minorization-maximization of the likelihood function and a sparse optimization scheme. Theoretical results show that the instantaneous effect is a blessing rather than a curse, and the causal structure is identifiable under the existence of the instantaneous effect. Experiments on synthetic and real-world data verify the effectiveness of the proposed method.
Deep Reinforcement Learning Based Intelligent Reflecting Surface Optimization for TDD MultiUser MIMO Systems
Jul 28, 2023
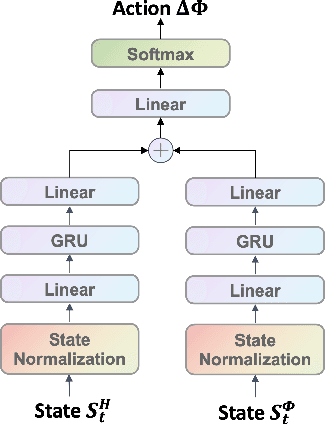
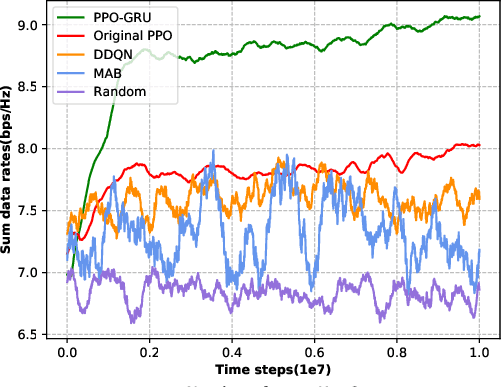
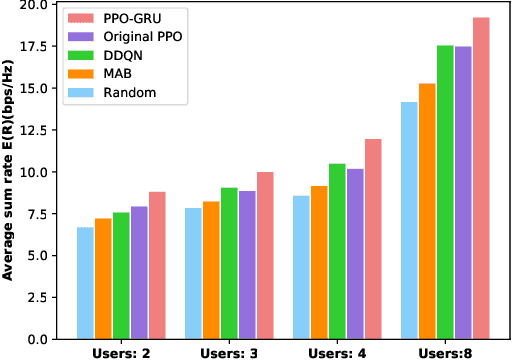
In this letter, we investigate the discrete phase shift design of the intelligent reflecting surface (IRS) in a time division duplexing (TDD) multi-user multiple input multiple output (MIMO) system.We modify the design of deep reinforcement learning (DRL) scheme so that we can maximizing the average downlink data transmission rate free from the sub-channel channel state information (CSI). Based on the characteristics of the model, we modify the proximal policy optimization (PPO) algorithm and integrate gated recurrent unit (GRU) to tackle the non-convex optimization problem. Simulation results show that the performance of the proposed PPO-GRU surpasses the benchmarks in terms of performance, convergence speed, and training stability.
On the Effective Horizon of Inverse Reinforcement Learning
Jul 13, 2023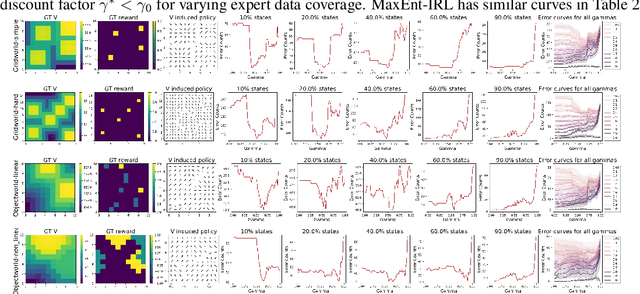
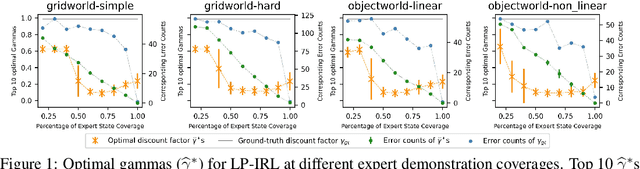
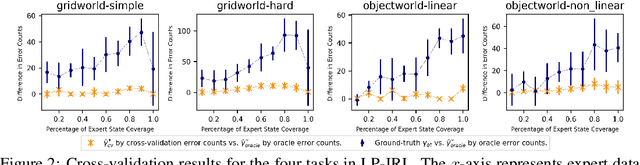
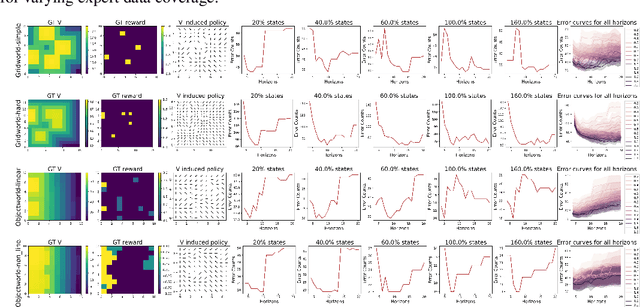
Inverse reinforcement learning (IRL) algorithms often rely on (forward) reinforcement learning or planning over a given time horizon to compute an approximately optimal policy for a hypothesized reward function and then match this policy with expert demonstrations. The time horizon plays a critical role in determining both the accuracy of reward estimate and the computational efficiency of IRL algorithms. Interestingly, an effective time horizon shorter than the ground-truth value often produces better results faster. This work formally analyzes this phenomenon and provides an explanation: the time horizon controls the complexity of an induced policy class and mitigates overfitting with limited data. This analysis leads to a principled choice of the effective horizon for IRL. It also prompts us to reexamine the classic IRL formulation: it is more natural to learn jointly the reward and the effective horizon together rather than the reward alone with a given horizon. Our experimental results confirm the theoretical analysis.
InstaGrasp: An Entirely 3D Printed Adaptive Gripper with TPU Soft Elements and Minimal Assembly Time
May 26, 2023Fabricating existing and popular open-source adaptive robotic grippers commonly involves using multiple professional machines, purchasing a wide range of parts, and tedious, time-consuming assembly processes. This poses a significant barrier to entry for some robotics researchers and drives others to opt for expensive commercial alternatives. To provide both parties with an easier and cheaper (under 100GBP) solution, we propose a novel adaptive gripper design where every component (with the exception of actuators and the screws that come packaged with them) can be fabricated on a hobby-grade 3D printer, via a combination of inexpensive and readily available PLA and TPU filaments. This approach means that the gripper's tendons, flexure joints and finger pads are now printed, as a replacement for traditional string-tendons and molded urethane flexures and pads. A push-fit systems results in an assembly time of under 10 minutes. The gripper design is also highly modular and requires only a few minutes to replace any part, leading to extremely user-friendly maintenance and part modifications. An extensive stress test has shown a level of durability more than suitable for research, whilst grasping experiments (with perturbations) using items from the YCB object set has also proven its mechanical adaptability to be highly satisfactory.
Impact of Free-carrier Nonlinearities on Silicon Microring-based Reservoir Computing
Jul 13, 2023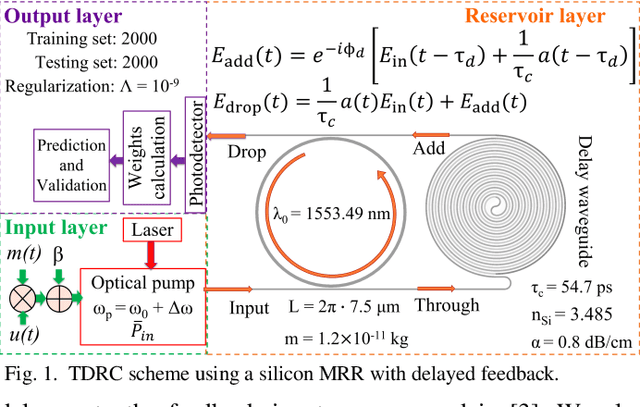
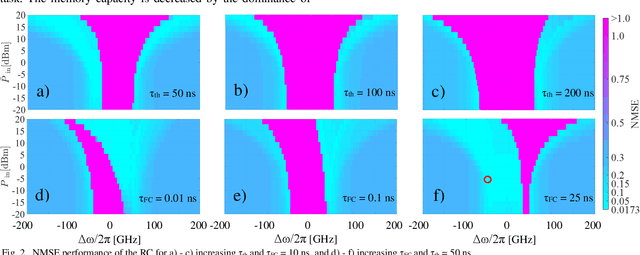

We quantify the impact of thermo-optic and free-carrier effects on time-delay reservoir computing using a silicon microring resonator. We identify pump power and frequency detuning ranges with NMSE less than 0.05 for the NARMA-10 task depending on the time constants of the two considered effects.
Physically Plausible 3D Human-Scene Reconstruction from Monocular RGB Image using an Adversarial Learning Approach
Jul 27, 2023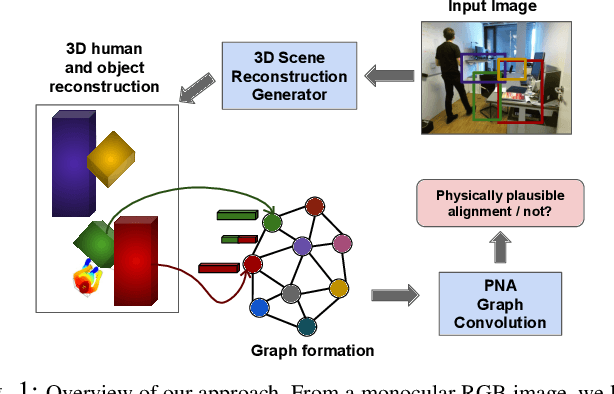
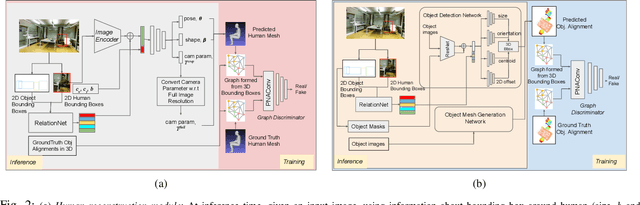

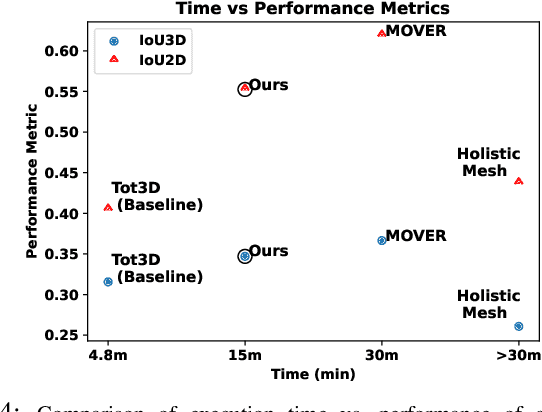
Holistic 3D human-scene reconstruction is a crucial and emerging research area in robot perception. A key challenge in holistic 3D human-scene reconstruction is to generate a physically plausible 3D scene from a single monocular RGB image. The existing research mainly proposes optimization-based approaches for reconstructing the scene from a sequence of RGB frames with explicitly defined physical laws and constraints between different scene elements (humans and objects). However, it is hard to explicitly define and model every physical law in every scenario. This paper proposes using an implicit feature representation of the scene elements to distinguish a physically plausible alignment of humans and objects from an implausible one. We propose using a graph-based holistic representation with an encoded physical representation of the scene to analyze the human-object and object-object interactions within the scene. Using this graphical representation, we adversarially train our model to learn the feasible alignments of the scene elements from the training data itself without explicitly defining the laws and constraints between them. Unlike the existing inference-time optimization-based approaches, we use this adversarially trained model to produce a per-frame 3D reconstruction of the scene that abides by the physical laws and constraints. Our learning-based method achieves comparable 3D reconstruction quality to existing optimization-based holistic human-scene reconstruction methods and does not need inference time optimization. This makes it better suited when compared to existing methods, for potential use in robotic applications, such as robot navigation, etc.