 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diving with Penguins: Detecting Penguins and their Prey in Animal-borne Underwater Videos via Deep Learning
Aug 14, 2023




African penguins (Spheniscus demersus) are an endangered species. Little is known regarding their underwater hunting strategies and associated predation success rates, yet this is essential for guiding conservation. Modern bio-logging technology has the potential to provide valuable insights, but manually analysing large amounts of data from animal-borne video recorders (AVRs) is time-consuming. In this paper, we publish an animal-borne underwater video dataset of penguins and introduce a ready-to-deploy deep learning system capable of robustly detecting penguins (mAP50@98.0%) and also instances of fish (mAP50@73.3%). We note that the detectors benefit explicitly from air-bubble learning to improve accuracy. Extending this detector towards a dual-stream behaviour recognition network, we also provide the first results for identifying predation behaviour in penguin underwater videos. Whilst results are promising, further work is required for useful applicability of predation behaviour detection in field scenarios. In summary, we provide a highly reliable underwater penguin detector, a fish detector, and a valuable first attempt towards an automated visual detection of complex behaviours in a marine predator. We publish the networks, the DivingWithPenguins video dataset, annotations, splits, and weights for full reproducibility and immediate usability by practitioners.
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Aug 14, 2023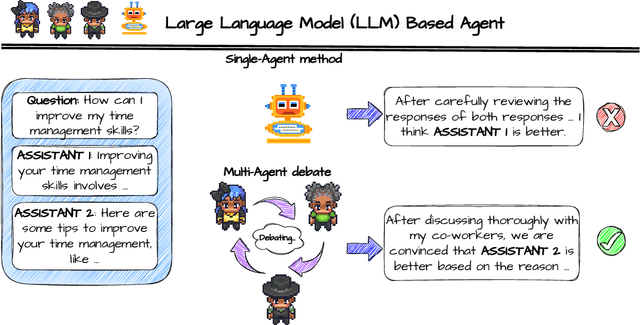
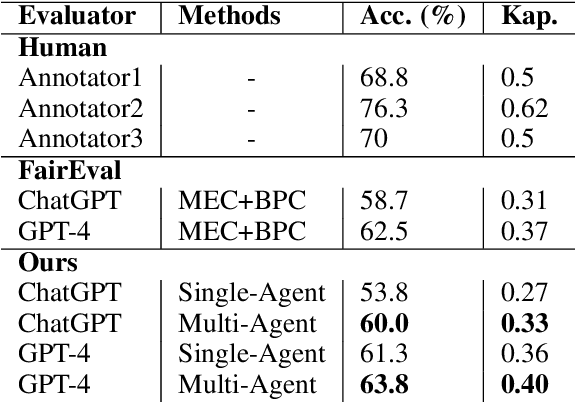
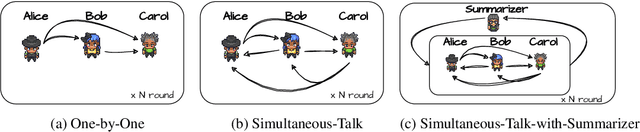
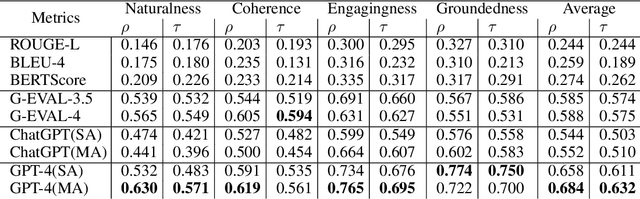
Text evaluation has historically posed significant challenges, often demanding substantial labor and time cost. With the emergence of large language models (LLMs), researchers have explored LLMs' potential as alternatives for human evaluation. While these single-agent-based approaches show promise, experimental results suggest that further advancements are needed to bridge the gap between their current effectiveness and human-level evaluation quality. Recognizing that best practices of human evaluation processes often involve multiple human annotators collaborating in the evaluation, we resort to a multi-agent debate framework, moving beyond single-agent prompting strategies. The multi-agent-based approach enables a group of LLMs to synergize with an array of intelligent counterparts, harnessing their distinct capabilities and expertise to enhance efficiency and effectiveness in handling intricate tasks. In this paper, we construct a multi-agent referee team called ChatEval to autonomously discuss and evaluate the quality of generated responses from different models on open-ended questions and traditional natural language generation (NLG) tasks. Our analysis shows that ChatEval transcends mere textual scoring, offering a human-mimicking evaluation process for reliable assessments. Our code is available at https://github.com/chanchimin/ChatEval.
AutoSeqRec: Autoencoder for Efficient Sequential Recommendation
Aug 14, 2023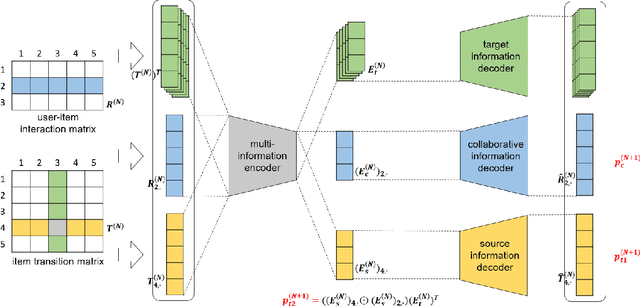
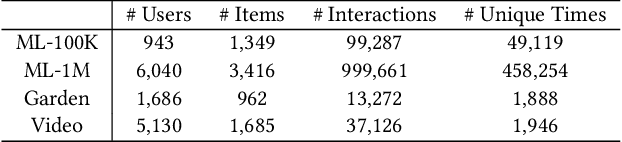
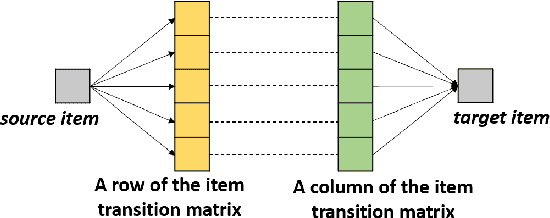
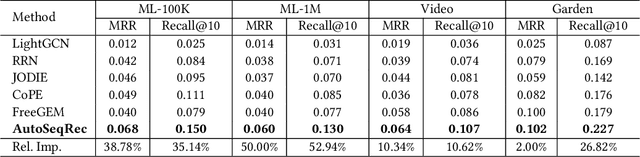
Sequential recommendation demonstrates the capability to recommend items by modeling the sequential behavior of users. Traditional methods typically treat users as sequences of items, overlooking the collaborative relationships among them. Graph-based methods incorporate collaborative information by utilizing the user-item interaction graph. However, these methods sometimes face challenges in terms of time complexity and computational efficiency. To address these limitations, this paper presents AutoSeqRec, an incremental recommendation model specifically designed for sequential recommendation tasks. AutoSeqRec is based on autoencoders and consists of an encoder and three decoders within the autoencoder architecture. These components consider both the user-item interaction matrix and the rows and columns of the item transition matrix. The reconstruction of the user-item interaction matrix captures user long-term preferences through collaborative filtering. In addition, the rows and columns of the item transition matrix represent the item out-degree and in-degree hopping behavior, which allows for modeling the user's short-term interests. When making incremental recommendations, only the input matrices need to be updated, without the need to update parameters, which makes AutoSeqRec very efficient. Comprehensive evaluations demonstrate that AutoSeqRec outperforms existing methods in terms of accuracy, while showcasing its robustness and efficiency.
Semantic Similarity Loss for Neural Source Code Summarization
Aug 14, 2023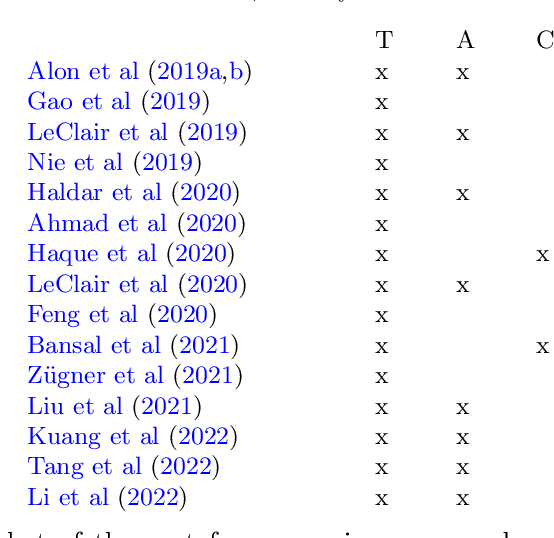

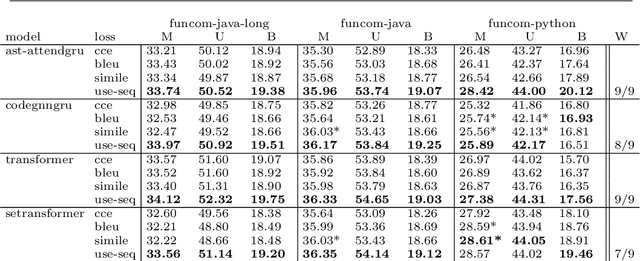
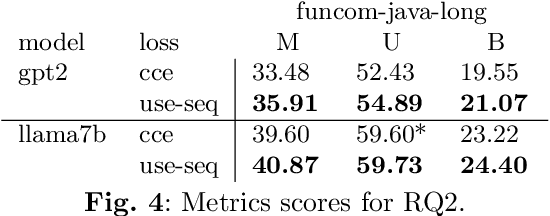
This paper presents an improved loss function for neural source code summarization. Code summarization is the task of writing natural language descriptions of source code. Neural code summarization refers to automated techniques for generating these descriptions using neural networks. Almost all current approaches involve neural networks as either standalone models or as part of a pretrained large language models e.g., GPT, Codex, LLaMA. Yet almost all also use a categorical cross-entropy (CCE) loss function for network optimization. Two problems with CCE are that 1) it computes loss over each word prediction one-at-a-time, rather than evaluating a whole sentence, and 2) it requires a perfect prediction, leaving no room for partial credit for synonyms. We propose and evaluate a loss function to alleviate this problem. In essence, we propose to use a semantic similarity metric to calculate loss over the whole output sentence prediction per training batch, rather than just loss for each word. We also propose to combine our loss with traditional CCE for each word, which streamlines the training process compared to baselines. We evaluate our approach over several baselines and report an improvement in the vast majority of conditions.
SMURF: Spatial Multi-Representation Fusion for 3D Object Detection with 4D Imaging Radar
Aug 02, 2023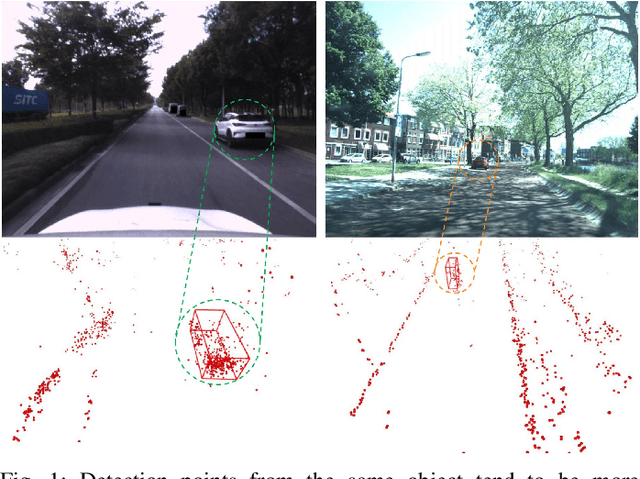
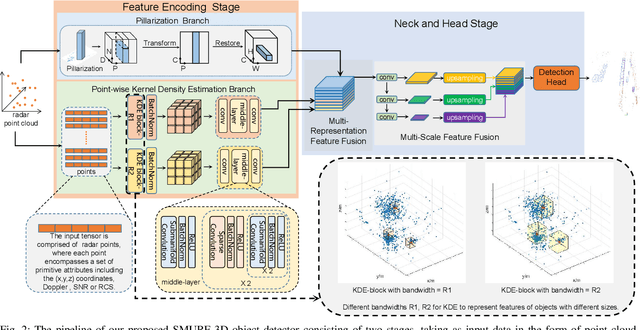
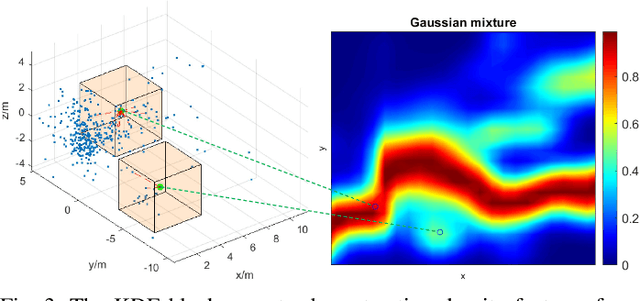
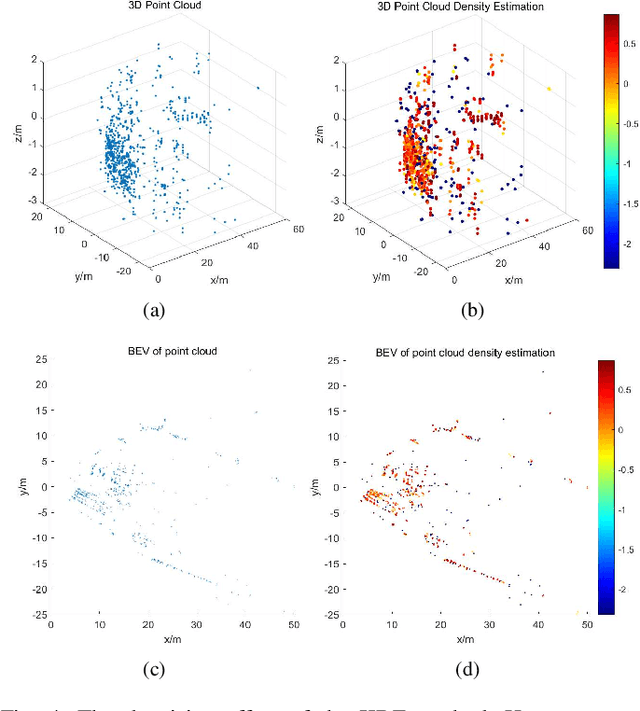
The 4D Millimeter wave (mmWave) radar is a promising technology for vehicle sensing due to its cost-effectiveness and operability in adverse weather conditions. However, the adoption of this technology has been hindered by sparsity and noise issues in radar point cloud data. This paper introduces spatial multi-representation fusion (SMURF), a novel approach to 3D object detection using a single 4D imaging radar. SMURF leverages multiple representations of radar detection points, including pillarization and density features of a multi-dimensional Gaussian mixture distribution through kernel density estimation (KDE). KDE effectively mitigates measurement inaccuracy caused by limited angular resolution and multi-path propagation of radar signals. Additionally, KDE helps alleviate point cloud sparsity by capturing density features. Experimental evaluations on View-of-Delft (VoD) and TJ4DRadSet datasets demonstrate the effectiveness and generalization ability of SMURF, outperforming recently proposed 4D imaging radar-based single-representation models. Moreover, while using 4D imaging radar only, SMURF still achieves comparable performance to the state-of-the-art 4D imaging radar and camera fusion-based method, with an increase of 1.22% in the mean average precision on bird's-eye view of TJ4DRadSet dataset and 1.32% in the 3D mean average precision on the entire annotated area of VoD dataset. Our proposed method demonstrates impressive inference time and addresses the challenges of real-time detection, with the inference time no more than 0.05 seconds for most scans on both datasets. This research highlights the benefits of 4D mmWave radar and is a strong benchmark for subsequent works regarding 3D object detection with 4D imaging radar.
A degree of image identification at sub-human scales could be possible with more advanced clusters
Aug 09, 2023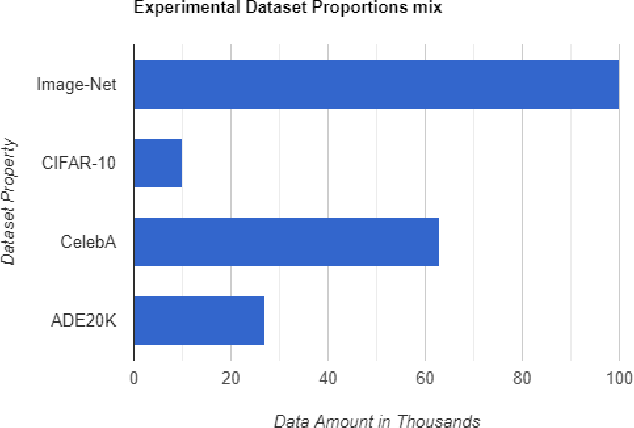
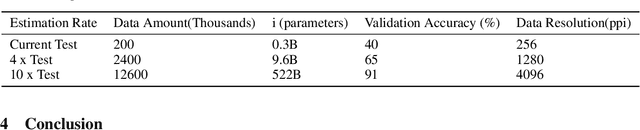
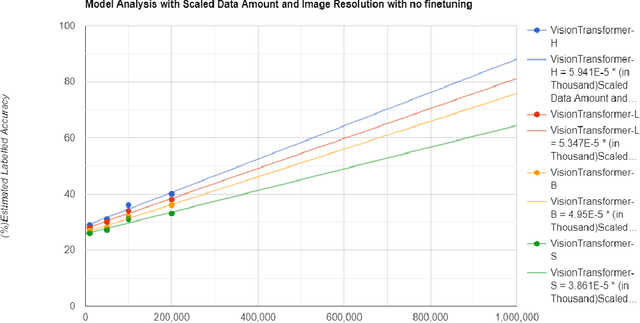
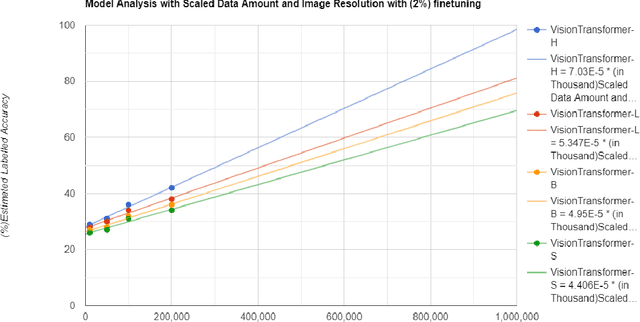
The purpose of the research is to determine if currently available self-supervised learning techniques can accomplish human level comprehension of visual images using the same degree and amount of sensory input that people acquire from. Initial research on this topic solely considered data volume scaling. Here, we scale both the volume of data and the quality of the image. This scaling experiment is a self-supervised learning method that may be done without any outside financing. We find that scaling up data volume and picture resolution at the same time enables human-level item detection performance at sub-human sizes.We run a scaling experiment with vision transformers trained on up to 200000 images up to 256 ppi.
pTSE: A Multi-model Ensemble Method for Probabilistic Time Series Forecasting
May 16, 2023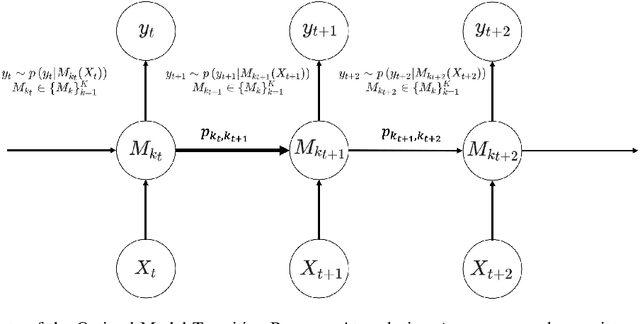
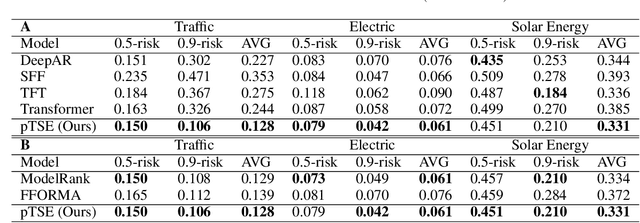
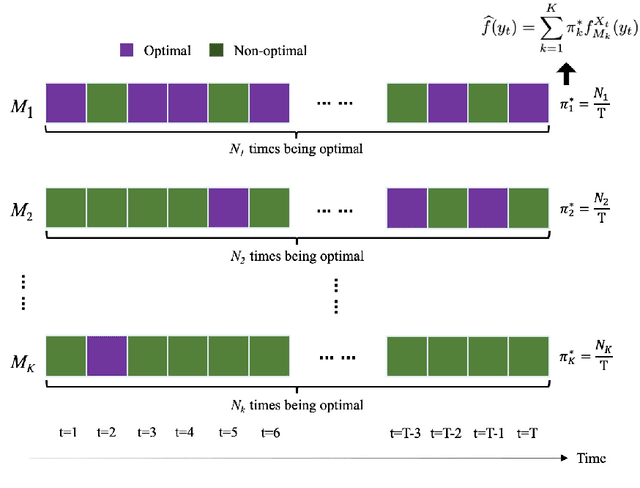
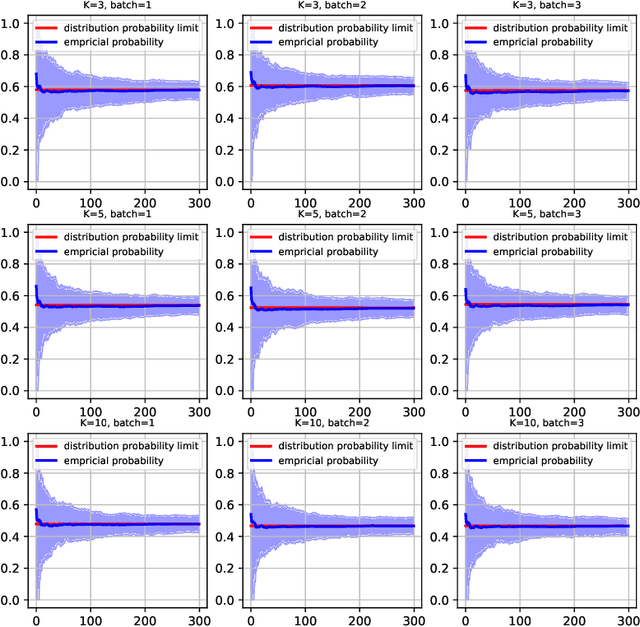
Various probabilistic time series forecasting models have sprung up and shown remarkably good performance. However, the choice of model highly relies on the characteristics of the input time series and the fixed distribution that the model is based on. Due to the fact that the probability distributions cannot be averaged over different models straightforwardly, the current time series model ensemble methods cannot be directly applied to improve the robustness and accuracy of forecasting. To address this issue, we propose pTSE, a multi-model distribution ensemble method for probabilistic forecasting based on Hidden Markov Model (HMM). pTSE only takes off-the-shelf outputs from member models without requiring further information about each model. Besides, we provide a complete theoretical analysis of pTSE to prove that the empirical distribution of time series subject to an HMM will converge to the stationary distribution almost surely. Experiments on benchmarks show the superiority of pTSE overall member models and competitive ensemble methods.
HTP: Exploiting Holistic Temporal Patterns for Sequential Recommendation
Jul 22, 2023
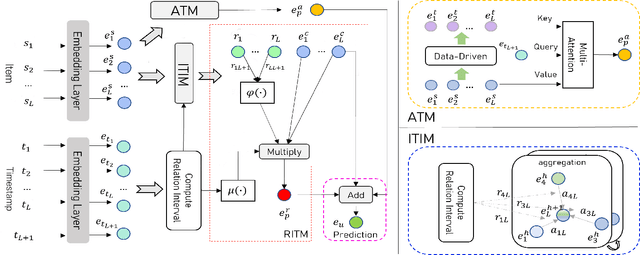

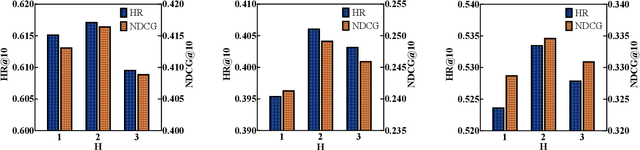
Sequential recommender systems have demonstrated a huge success for next-item recommendation by explicitly exploiting the temporal order of users' historical interactions. In practice, user interactions contain more useful temporal information beyond order, as shown by some pioneering studies. In this paper, we systematically investigate various temporal information for sequential recommendation and identify three types of advantageous temporal patterns beyond order, including absolute time information, relative item time intervals and relative recommendation time intervals. We are the first to explore item-oriented absolute time patterns. While existing models consider only one or two of these three patterns, we propose a novel holistic temporal pattern based neural network, named HTP, to fully leverage all these three patterns. In particular, we introduce novel components to address the subtle correlations between relative item time intervals and relative recommendation time intervals, which render a major technical challenge. Extensive experiments on three real-world benchmark datasets show that our HTP model consistently and substantially outperforms many state-of-the-art models. Our code is publically available at https://github.com/623851394/HTP/tree/main/HTP-main
Don't lose the message while paraphrasing: A study on content preserving style transfer
Aug 17, 2023Text style transfer techniques are gaining popularity in natural language processing allowing paraphrasing text in the required form: from toxic to neural, from formal to informal, from old to the modern English language, etc. Solving the task is not sufficient to generate some neural/informal/modern text, but it is important to preserve the original content unchanged. This requirement becomes even more critical in some applications such as style transfer of goal-oriented dialogues where the factual information shall be kept to preserve the original message, e.g. ordering a certain type of pizza to a certain address at a certain time. The aspect of content preservation is critical for real-world applications of style transfer studies, but it has received little attention. To bridge this gap we perform a comparison of various style transfer models on the example of the formality transfer domain. To perform a study of the content preservation abilities of various style transfer methods we create a parallel dataset of formal vs. informal task-oriented dialogues. The key difference between our dataset and the existing ones like GYAFC [17] is the presence of goal-oriented dialogues with predefined semantic slots essential to be kept during paraphrasing, e.g. named entities. This additional annotation allowed us to conduct a precise comparative study of several state-of-the-art techniques for style transfer. Another result of our study is a modification of the unsupervised method LEWIS [19] which yields a substantial improvement over the original method and all evaluated baselines on the proposed task.
Linguistically-Informed Neural Architectures for Lexical, Syntactic and Semantic Tasks in Sanskrit
Aug 17, 2023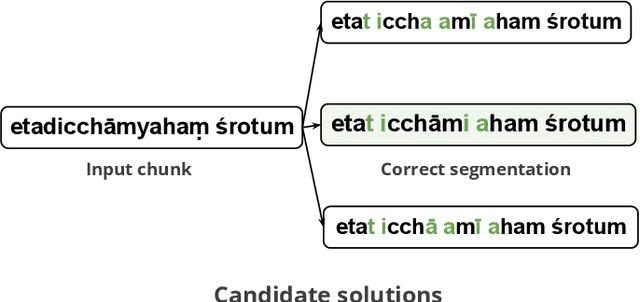
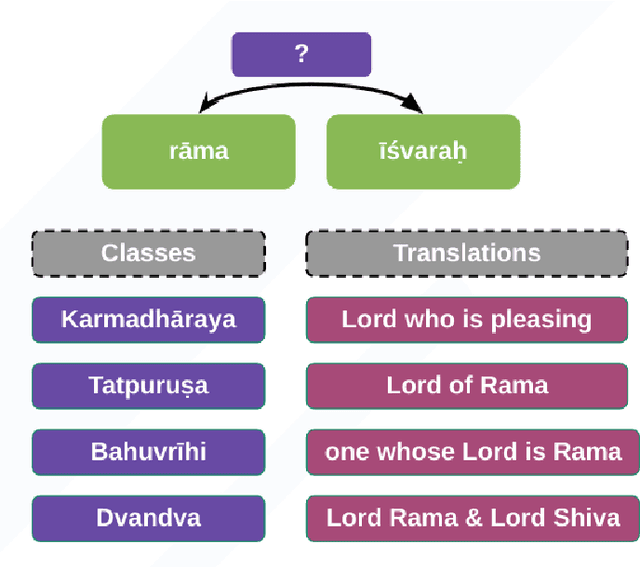
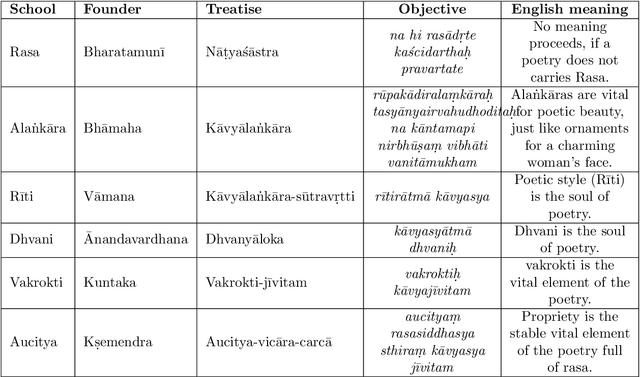
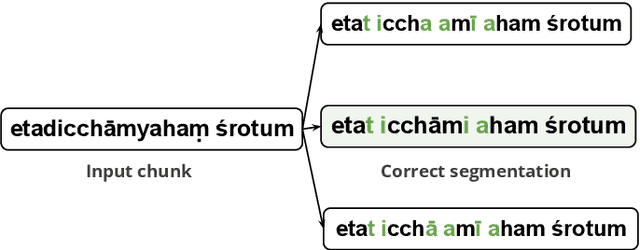
The primary focus of this thesis is to make Sanskrit manuscripts more accessible to the end-users through natural language technologies. The morphological richness, compounding, free word orderliness, and low-resource nature of Sanskrit pose significant challenges for developing deep learning solutions. We identify four fundamental tasks, which are crucial for developing a robust NLP technology for Sanskrit: word segmentation, dependency parsing, compound type identification, and poetry analysis. The first task, Sanskrit Word Segmentation (SWS), is a fundamental text processing task for any other downstream applications. However, it is challenging due to the sandhi phenomenon that modifies characters at word boundaries. Similarly, the existing dependency parsing approaches struggle with morphologically rich and low-resource languages like Sanskrit. Compound type identification is also challenging for Sanskrit due to the context-sensitive semantic relation between components. All these challenges result in sub-optimal performance in NLP applications like question answering and machine translation. Finally, Sanskrit poetry has not been extensively studied in computational linguistics. While addressing these challenges, this thesis makes various contributions: (1) The thesis proposes linguistically-informed neural architectures for these tasks. (2) We showcase the interpretability and multilingual extension of the proposed systems. (3) Our proposed systems report state-of-the-art performance. (4) Finally, we present a neural toolkit named SanskritShala, a web-based application that provides real-time analysis of input for various NLP tasks. Overall, this thesis contributes to making Sanskrit manuscripts more accessible by developing robust NLP technology and releasing various resources, datasets, and web-based toolkit.