 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lie-Poisson Neural Networks (LPNets): Data-Based Computing of Hamiltonian Systems with Symmetries
Aug 29, 2023
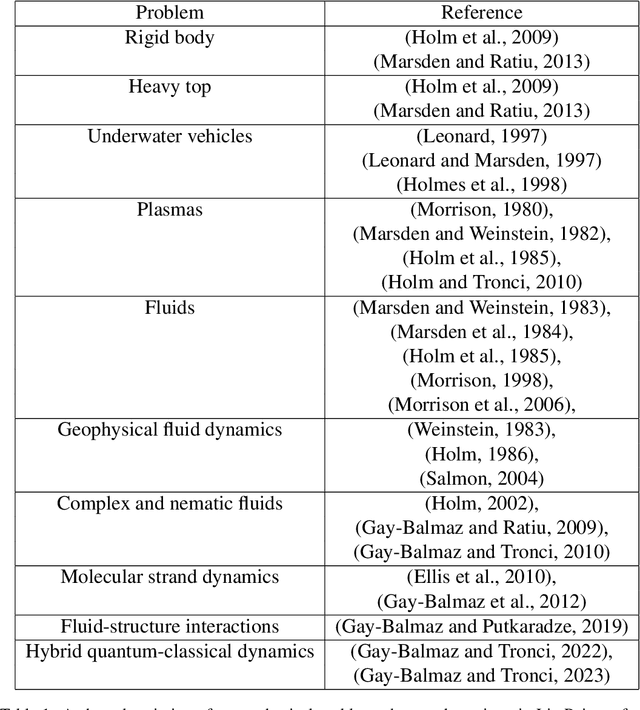
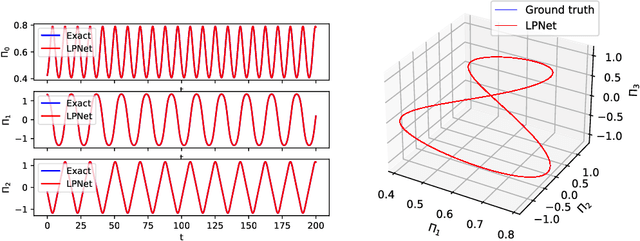
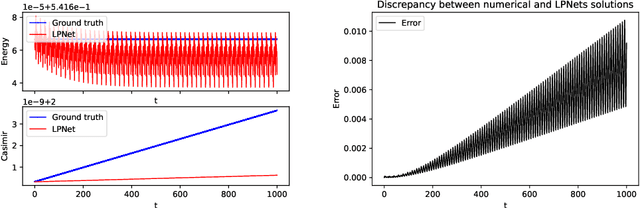
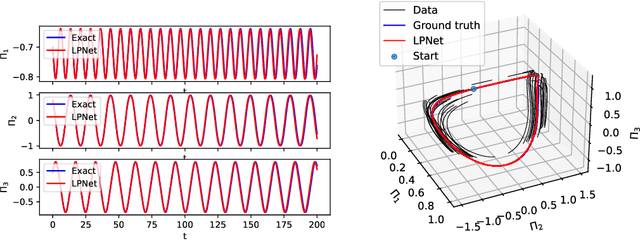
An accurate data-based prediction of the long-term evolution of Hamiltonian systems requires a network that preserves the appropriate structure under each time step. Every Hamiltonian system contains two essential ingredients: the Poisson bracket and the Hamiltonian. Hamiltonian systems with symmetries, whose paradigm examples are the Lie-Poisson systems, have been shown to describe a broad category of physical phenomena, from satellite motion to underwater vehicles, fluids, geophysical applications, complex fluids, and plasma physics. The Poisson bracket in these systems comes from the symmetries, while the Hamiltonian comes from the underlying physics. We view the symmetry of the system as primary, hence the Lie-Poisson bracket is known exactly, whereas the Hamiltonian is regarded as coming from physics and is considered not known, or known approximately. Using this approach, we develop a network based on transformations that exactly preserve the Poisson bracket and the special functions of the Lie-Poisson systems (Casimirs) to machine precision. We present two flavors of such systems: one, where the parameters of transformations are computed from data using a dense neural network (LPNets), and another, where the composition of transformations is used as building blocks (G-LPNets). We also show how to adapt these methods to a larger class of Poisson brackets. We apply the resulting methods to several examples, such as rigid body (satellite) motion, underwater vehicles, a particle in a magnetic field, and others. The methods developed in this paper are important for the construction of accurate data-based methods for simulating the long-term dynamics of physical systems.
ReFit: Recurrent Fitting Network for 3D Human Recovery
Aug 22, 2023We present Recurrent Fitting (ReFit), a neural network architecture for single-image, parametric 3D human reconstruction. ReFit learns a feedback-update loop that mirrors the strategy of solving an inverse problem through optimization. At each iterative step, it reprojects keypoints from the human model to feature maps to query feedback, and uses a recurrent-based updater to adjust the model to fit the image better. Because ReFit encodes strong knowledge of the inverse problem, it is faster to train than previous regression models. At the same time, ReFit improves state-of-the-art performance on standard benchmarks. Moreover, ReFit applies to other optimization settings, such as multi-view fitting and single-view shape fitting. Project website: https://yufu-wang.github.io/refit_humans/
FFPN: Fourier Feature Pyramid Network for Ultrasound Image Segmentation
Aug 26, 2023
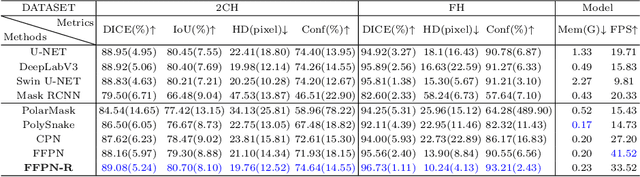
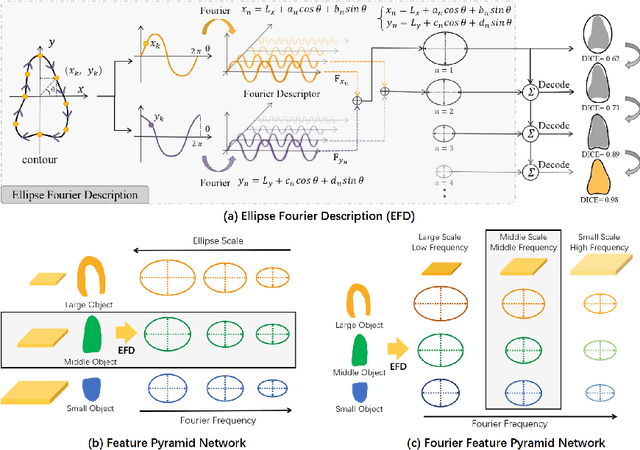
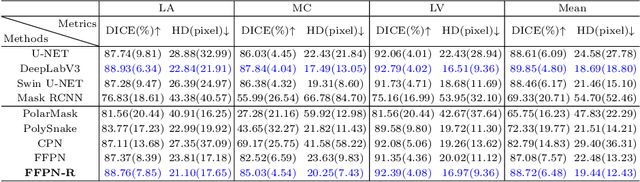
Ultrasound (US) image segmentation is an active research area that requires real-time and highly accurate analysis in many scenarios. The detect-to-segment (DTS) frameworks have been recently proposed to balance accuracy and efficiency. However, existing approaches may suffer from inadequate contour encoding or fail to effectively leverage the encoded results. In this paper, we introduce a novel Fourier-anchor-based DTS framework called Fourier Feature Pyramid Network (FFPN) to address the aforementioned issues. The contributions of this paper are two fold. First, the FFPN utilizes Fourier Descriptors to adequately encode contours. Specifically, it maps Fourier series with similar amplitudes and frequencies into the same layer of the feature map, thereby effectively utilizing the encoded Fourier information. Second, we propose a Contour Sampling Refinement (CSR) module based on the contour proposals and refined features produced by the FFPN. This module extracts rich features around the predicted contours to further capture detailed information and refine the contours. Extensive experimental results on three large and challenging datasets demonstrate that our method outperforms other DTS methods in terms of accuracy and efficiency. Furthermore, our framework can generalize well to other detection or segmentation tasks.
Point-Query Quadtree for Crowd Counting, Localization, and More
Aug 26, 2023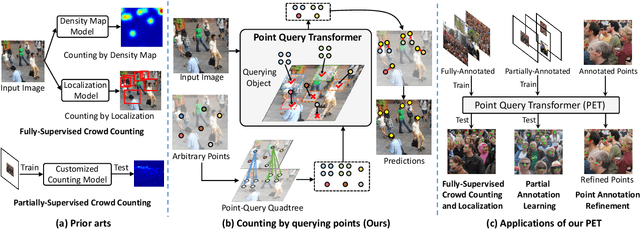
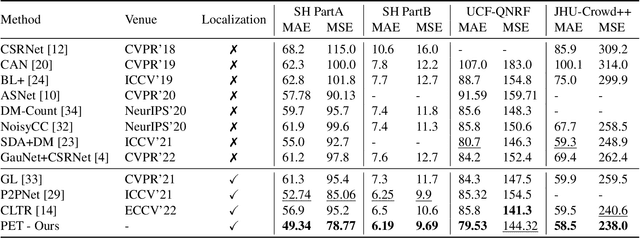
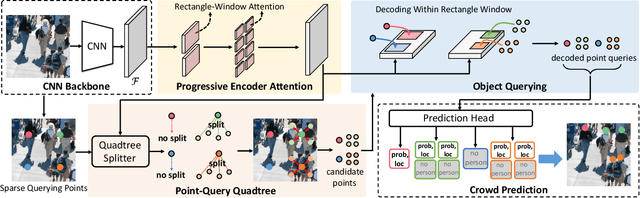
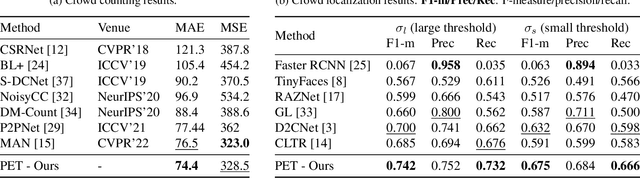
We show that crowd counting can be viewed as a decomposable point querying process. This formulation enables arbitrary points as input and jointly reasons whether the points are crowd and where they locate. The querying processing, however, raises an underlying problem on the number of necessary querying points. Too few imply underestimation; too many increase computational overhead. To address this dilemma, we introduce a decomposable structure, i.e., the point-query quadtree, and propose a new counting model, termed Point quEry Transformer (PET). PET implements decomposable point querying via data-dependent quadtree splitting, where each querying point could split into four new points when necessary, thus enabling dynamic processing of sparse and dense regions. Such a querying process yields an intuitive, universal modeling of crowd as both the input and output are interpretable and steerable. We demonstrate the applications of PET on a number of crowd-related tasks, including fully-supervised crowd counting and localization, partial annotation learning, and point annotation refinement, and also report state-of-the-art performance. For the first time, we show that a single counting model can address multiple crowd-related tasks across different learning paradigms. Code is available at https://github.com/cxliu0/PET.
A Cognitive Network Architecture for Vehicle-to-Network (V2N) Communications over Smart Meters for URLLC
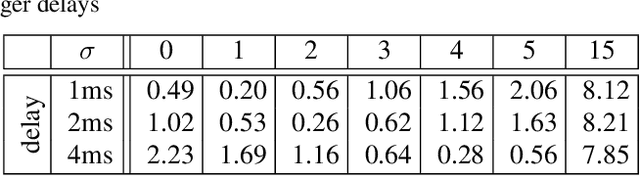
Aug 26, 2023With the rapid advancement of smart city infrastructure, vehicle-to-network (V2N) communication has emerged as a crucial technology to enable intelligent transportation systems (ITS). The investigation of new methods to improve V2N communications is sparked by the growing need for high-speed and dependable communications in vehicular networks. To achieve ultra-reliable low latency communication (URLLC) for V2N scenarios, we propose a smart meter (SM)-based cognitive network (CN) architecture for V2N communications. Our scheme makes use of SMs' available underutilized time resources to let them serve as distributed access points (APs) for V2N communications to increase reliability and decrease latency. We propose and investigate two algorithms for efficiently associating vehicles with the appropriate SMs. Extensive simulations are carried out for comprehensive performance evaluation of our proposed architecture and algorithms under diverse system scenarios. Performance is investigated with particular emphasis on communication latency and reliability, which are also compared with the conventional base station (BS)-based V2N architecture for further validation. The results highlight the value of incorporating SMs into the current infrastructure and open the door for future ITSs to utilize more effective and dependable V2N communications.
Towards Zero Memory Footprint Spiking Neural Network Training
Aug 16, 2023Biologically-inspired Spiking Neural Networks (SNNs), processing information using discrete-time events known as spikes rather than continuous values, have garnered significant attention due to their hardware-friendly and energy-efficient characteristics. However, the training of SNNs necessitates a considerably large memory footprint, given the additional storage requirements for spikes or events, leading to a complex structure and dynamic setup. In this paper, to address memory constraint in SNN training, we introduce an innovative framework, characterized by a remarkably low memory footprint. We \textbf{(i)} design a reversible SNN node that retains a high level of accuracy. Our design is able to achieve a $\mathbf{58.65\times}$ reduction in memory usage compared to the current SNN node. We \textbf{(ii)} propose a unique algorithm to streamline the backpropagation process of our reversible SNN node. This significantly trims the backward Floating Point Operations Per Second (FLOPs), thereby accelerating the training process in comparison to current reversible layer backpropagation method. By using our algorithm, the training time is able to be curtailed by $\mathbf{23.8\%}$ relative to existing reversible layer architectures.
Textureless Deformable Surface Reconstruction with Invisible Markers
Aug 25, 2023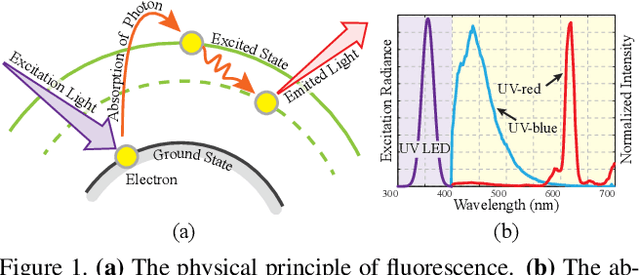

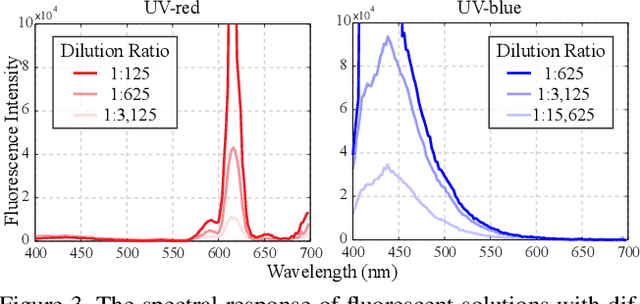
Reconstructing and tracking deformable surface with little or no texture has posed long-standing challenges. Fundamentally, the challenges stem from textureless surfaces lacking features for establishing cross-image correspondences. In this work, we present a novel type of markers to proactively enrich the object's surface features, and thereby ease the 3D surface reconstruction and correspondence tracking. Our markers are made of fluorescent dyes, visible only under the ultraviolet (UV) light and invisible under regular lighting condition. Leveraging the markers, we design a multi-camera system that captures surface deformation under the UV light and the visible light in a time multiplexing fashion. Under the UV light, markers on the object emerge to enrich its surface texture, allowing high-quality 3D shape reconstruction and tracking. Under the visible light, markers become invisible, allowing us to capture the object's original untouched appearance. We perform experiments on various challenging scenes, including hand gestures, facial expressions, waving cloth, and hand-object interaction. In all these cases, we demonstrate that our system is able to produce robust, high-quality 3D reconstruction and tracking.
WellXplain: Wellness Concept Extraction and Classification in Reddit Posts for Mental Health Analysis
Aug 25, 2023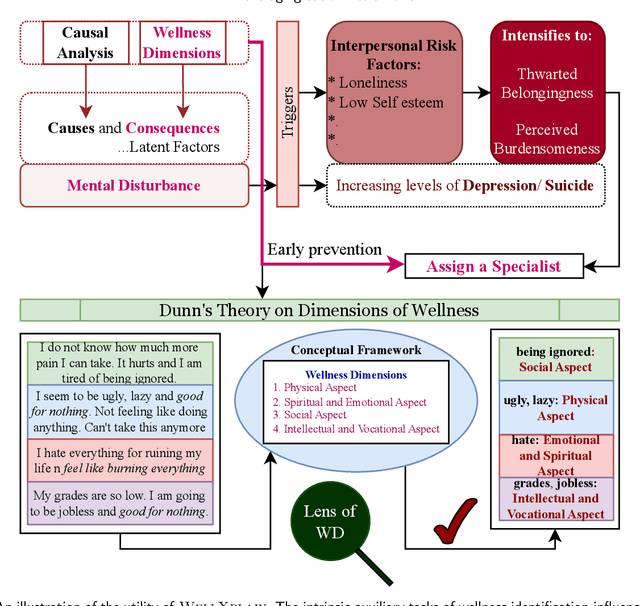
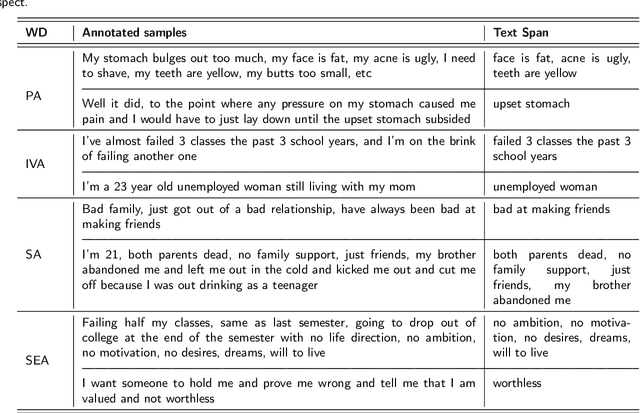
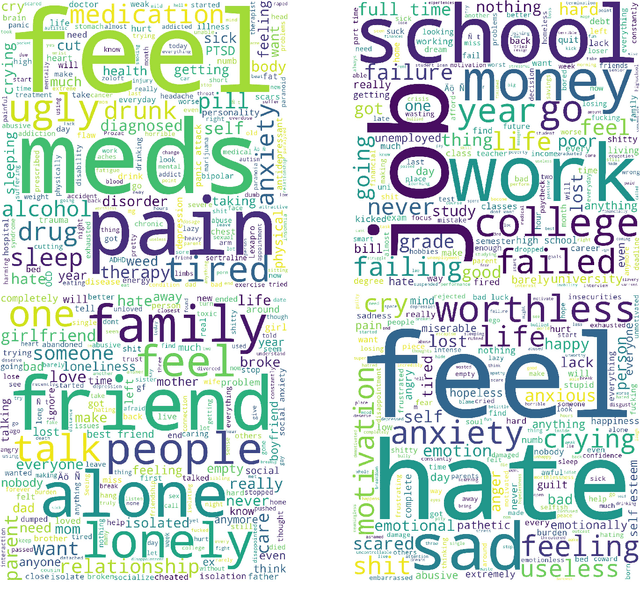
During the current mental health crisis, the importance of identifying potential indicators of mental issues from social media content has surged. Overlooking the multifaceted nature of mental and social well-being can have detrimental effects on one's mental state. In traditional therapy sessions, professionals manually pinpoint the origins and outcomes of underlying mental challenges, a process both detailed and time-intensive. We introduce an approach to this intricate mental health analysis by framing the identification of wellness dimensions in Reddit content as a wellness concept extraction and categorization challenge. We've curated a unique dataset named WELLXPLAIN, comprising 3,092 entries and totaling 72,813 words. Drawing from Halbert L. Dunn's well-regarded wellness theory, our team formulated an annotation framework along with guidelines. This dataset also includes human-marked textual segments, offering clear reasoning for decisions made in the wellness concept categorization process. Our aim in publishing this dataset and analyzing initial benchmarks is to spearhead the creation of advanced language models tailored for healthcare-focused concept extraction and categorization.
JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading
Aug 25, 2023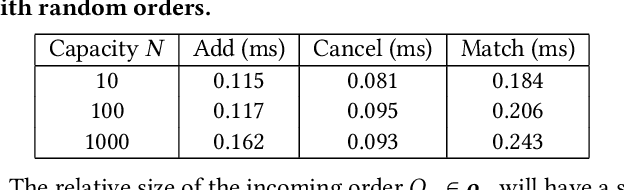
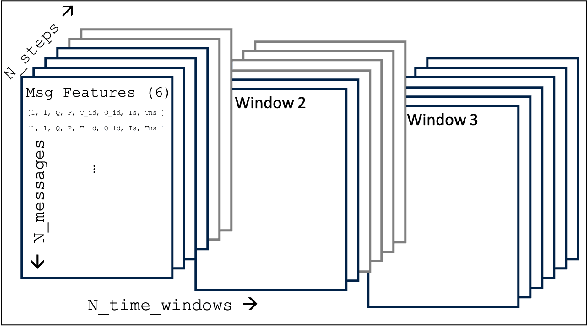
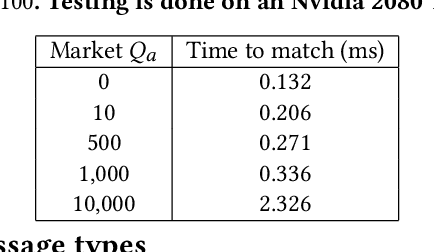
Financial exchanges across the world use limit order books (LOBs) to process orders and match trades. For research purposes it is important to have large scale efficient simulators of LOB dynamics. LOB simulators have previously been implemented in the context of agent-based models (ABMs), reinforcement learning (RL) environments, and generative models, processing order flows from historical data sets and hand-crafted agents alike. For many applications, there is a requirement for processing multiple books, either for the calibration of ABMs or for the training of RL agents. We showcase the first GPU-enabled LOB simulator designed to process thousands of books in parallel, with a notably reduced per-message processing time. The implementation of our simulator - JAX-LOB - is based on design choices that aim to best exploit the powers of JAX without compromising on the realism of LOB-related mechanisms. We integrate JAX-LOB with other JAX packages, to provide an example of how one may address an optimal execution problem with reinforcement learning, and to share some preliminary results from end-to-end RL training on GPUs.
Learning and Optimization of Implicit Negative Feedback for Industrial Short-video Recommender System
Aug 25, 2023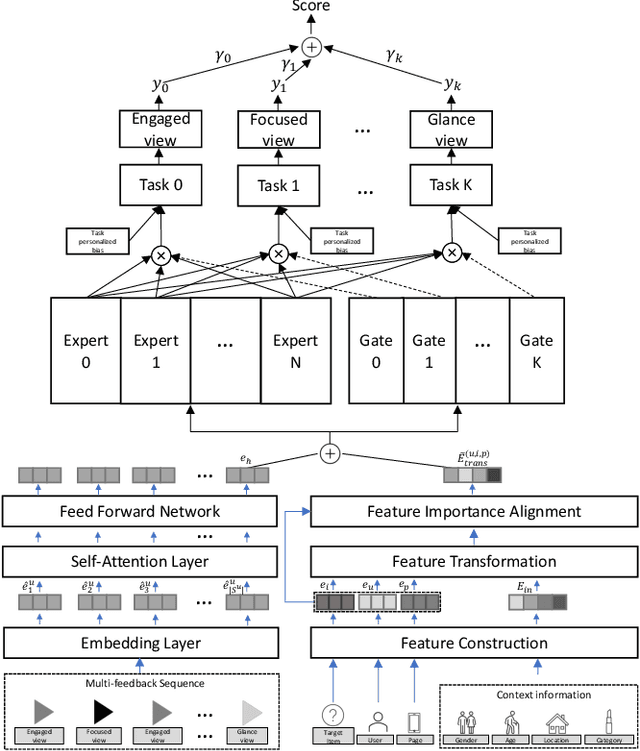

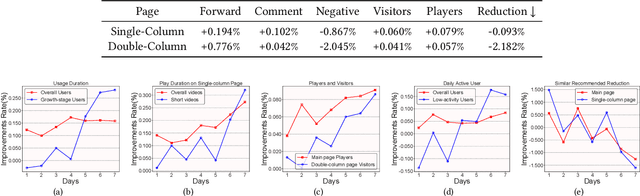
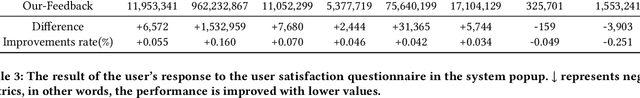
Short-video recommendation is one of the most important recommendation applications in today's industrial information systems. Compared with other recommendation tasks, the enormous amount of feedback is the most typical characteristic. Specifically, in short-video recommendation, the easiest-to-collect user feedback is from the skipping behaviors, which leads to two critical challenges for the recommendation model. First, the skipping behavior reflects implicit user preferences, and thus it is challenging for interest extraction. Second, the kind of special feedback involves multiple objectives, such as total watching time, which is also very challenging. In this paper, we present our industrial solution in Kuaishou, which serves billion-level users every day. Specifically, we deploy a feedback-aware encoding module which well extracts user preference taking the impact of context into consideration. We further design a multi-objective prediction module which well distinguishes the relation and differences among different model objectives in the short-video recommendation. We conduct extensive online A/B testing, along with detailed and careful analysis, which verifies the effectiveness of our solution.