 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SciRE-Solver: Efficient Sampling of Diffusion Probabilistic Models by Score-integrand Solver with Recursive Derivative Estimation
Aug 16, 2023

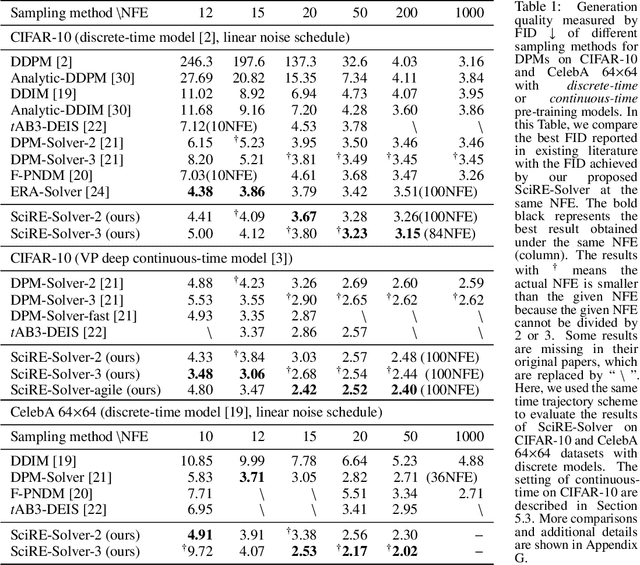
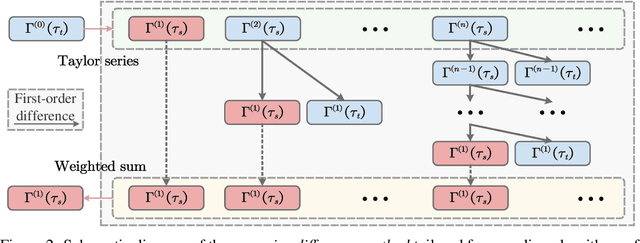
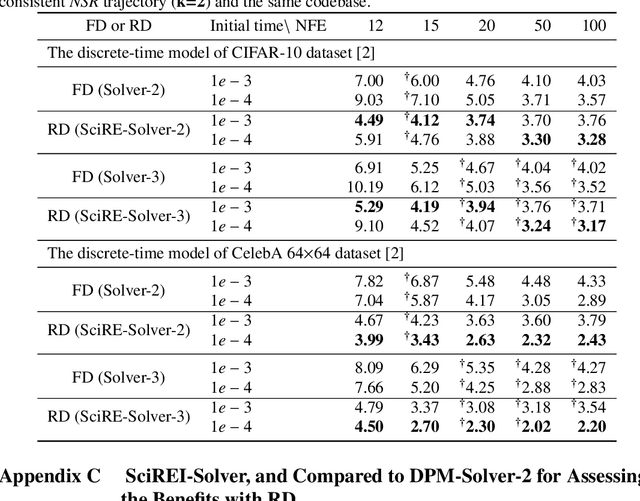
Diffusion probabilistic models (DPMs) are a powerful class of generative models known for their ability to generate high-fidelity image samples. A major challenge in the implementation of DPMs is the slow sampling process. In this work, we bring a high-efficiency sampler for DPMs. Specifically, we propose a score-based exact solution paradigm for the diffusion ODEs corresponding to the sampling process of DPMs, which introduces a new perspective on developing numerical algorithms for solving diffusion ODEs. To achieve an efficient sampler, we propose a recursive derivative estimation (RDE) method to reduce the estimation error. With our proposed solution paradigm and RDE method, we propose the score-integrand solver with the convergence order guarantee as efficient solver (SciRE-Solver) for solving diffusion ODEs. The SciRE-Solver attains state-of-the-art (SOTA) sampling performance with a limited number of score function evaluations (NFE) on both discrete-time and continuous-time DPMs in comparison to existing training-free sampling algorithms. Such as, we achieve $3.48$ FID with $12$ NFE and $2.42$ FID with $20$ NFE for continuous-time DPMs on CIFAR10, respectively. Different from other samplers, SciRE-Solver has the promising potential to surpass the FIDs achieved in the original papers of some pre-trained models with a small NFEs. For example, we reach SOTA value of $2.40$ FID with $100$ NFE for continuous-time DPM and of $3.15$ FID with $84$ NFE for discrete-time DPM on CIFAR-10, as well as of $2.17$ ($2.02$) FID with $18$ ($50$) NFE for discrete-time DPM on CelebA 64$\times$64.
TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting
Jun 14, 2023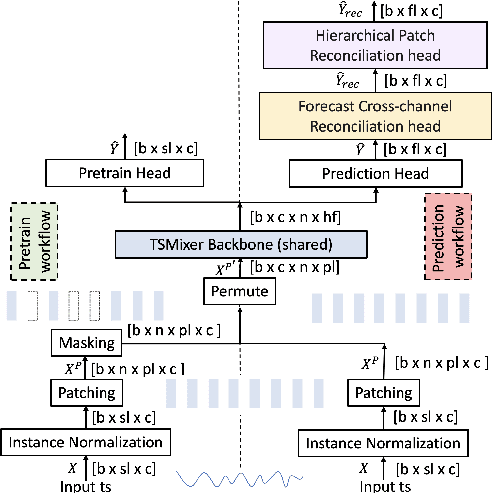
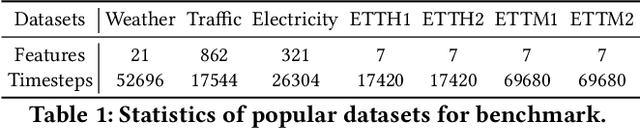
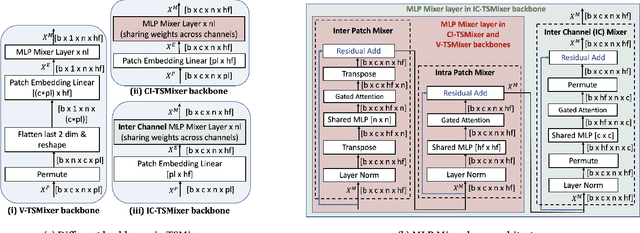
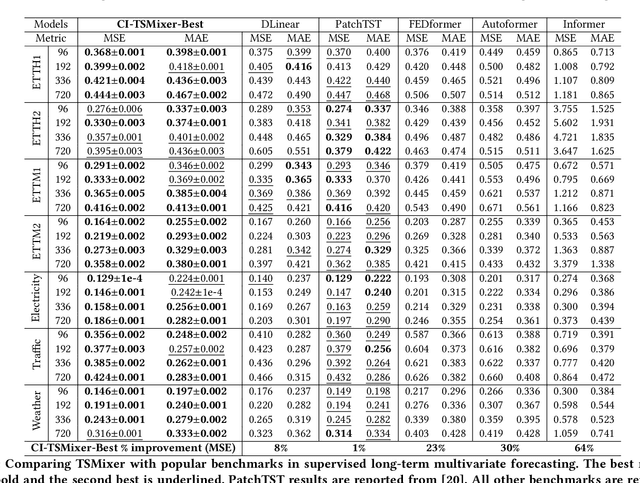
Transformers have gained popularity in time series forecasting for their ability to capture long-sequence interactions. However, their high memory and computing requirements pose a critical bottleneck for long-term forecasting. To address this, we propose TSMixer, a lightweight neural architecture exclusively composed of multi-layer perceptron (MLP) modules. TSMixer is designed for multivariate forecasting and representation learning on patched time series, providing an efficient alternative to Transformers. Our model draws inspiration from the success of MLP-Mixer models in computer vision. We demonstrate the challenges involved in adapting Vision MLP-Mixer for time series and introduce empirically validated components to enhance accuracy. This includes a novel design paradigm of attaching online reconciliation heads to the MLP-Mixer backbone, for explicitly modeling the time-series properties such as hierarchy and channel-correlations. We also propose a Hybrid channel modeling approach to effectively handle noisy channel interactions and generalization across diverse datasets, a common challenge in existing patch channel-mixing methods. Additionally, a simple gated attention mechanism is introduced in the backbone to prioritize important features. By incorporating these lightweight components, we significantly enhance the learning capability of simple MLP structures, outperforming complex Transformer models with minimal computing usage. Moreover, TSMixer's modular design enables compatibility with both supervised and masked self-supervised learning methods, making it a promising building block for time-series Foundation Models. TSMixer outperforms state-of-the-art MLP and Transformer models in forecasting by a considerable margin of 8-60%. It also outperforms the latest strong benchmarks of Patch-Transformer models (by 1-2%) with a significant reduction in memory and runtime (2-3X).
A flexible and accurate total variation and cascaded denoisers-based image reconstruction algorithm for hyperspectrally compressed ultrafast photography
Sep 06, 2023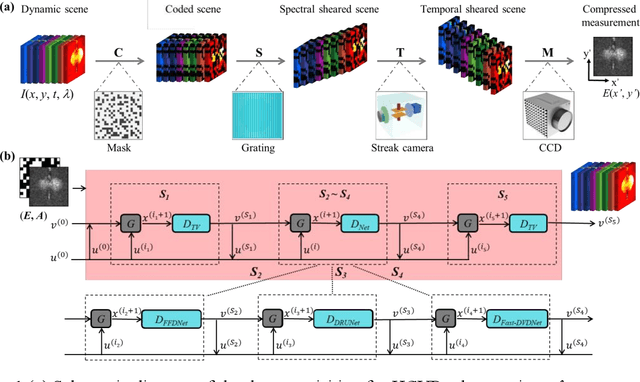
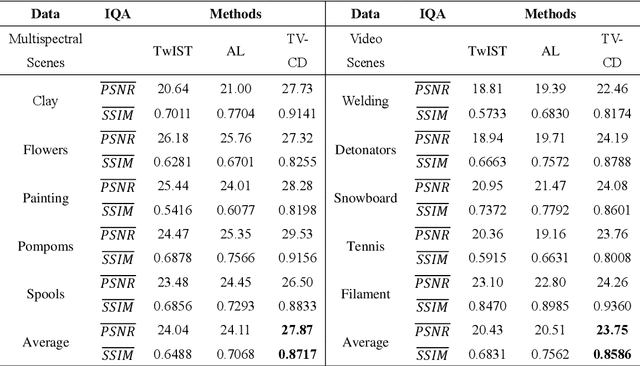
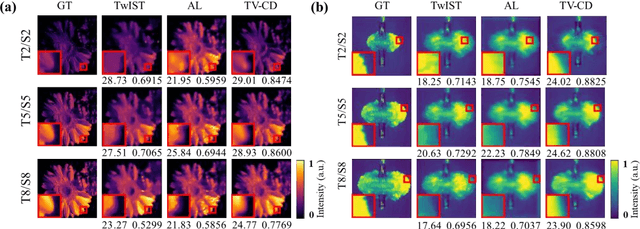
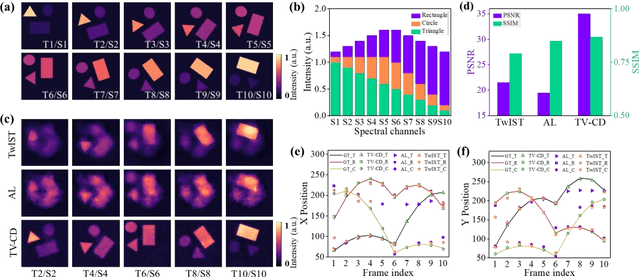
Hyperspectrally compressed ultrafast photography (HCUP) based on compressed sensing and the time- and spectrum-to-space mappings can simultaneously realize the temporal and spectral imaging of non-repeatable or difficult-to-repeat transient events passively in a single exposure. It possesses an incredibly high frame rate of tens of trillions of frames per second and a sequence depth of several hundred, and plays a revolutionary role in single-shot ultrafast optical imaging. However, due to the ultra-high data compression ratio induced by the extremely large sequence depth as well as the limited fidelities of traditional reconstruction algorithms over the reconstruction process, HCUP suffers from a poor image reconstruction quality and fails to capture fine structures in complex transient scenes. To overcome these restrictions, we propose a flexible image reconstruction algorithm based on the total variation (TV) and cascaded denoisers (CD) for HCUP, named the TV-CD algorithm. It applies the TV denoising model cascaded with several advanced deep learning-based denoising models in the iterative plug-and-play alternating direction method of multipliers framework, which can preserve the image smoothness while utilizing the deep denoising networks to obtain more priori, and thus solving the common sparsity representation problem in local similarity and motion compensation. Both simulation and experimental results show that the proposed TV-CD algorithm can effectively improve the image reconstruction accuracy and quality of HCUP, and further promote the practical applications of HCUP in capturing high-dimensional complex physical, chemical and biological ultrafast optical scenes.
Amortised Inference in Bayesian Neural Networks
Sep 06, 2023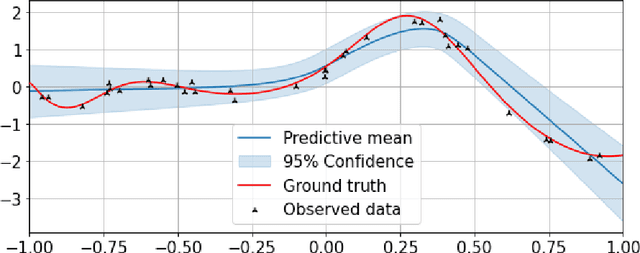

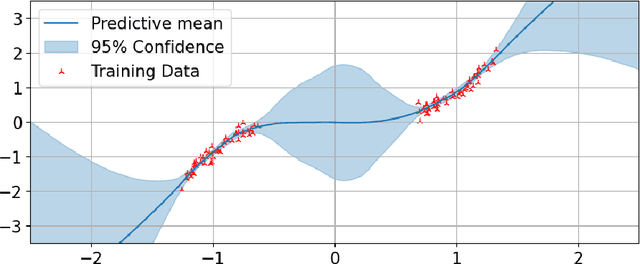
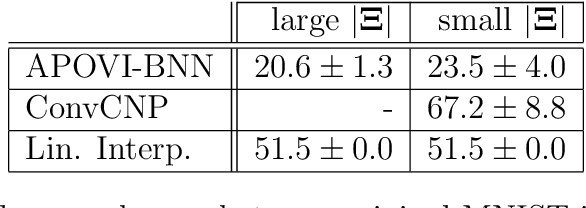
Meta-learning is a framework in which machine learning models train over a set of datasets in order to produce predictions on new datasets at test time. Probabilistic meta-learning has received an abundance of attention from the research community in recent years, but a problem shared by many existing probabilistic meta-models is that they require a very large number of datasets in order to produce high-quality predictions with well-calibrated uncertainty estimates. In many applications, however, such quantities of data are simply not available. In this dissertation we present a significantly more data-efficient approach to probabilistic meta-learning through per-datapoint amortisation of inference in Bayesian neural networks, introducing the Amortised Pseudo-Observation Variational Inference Bayesian Neural Network (APOVI-BNN). First, we show that the approximate posteriors obtained under our amortised scheme are of similar or better quality to those obtained through traditional variational inference, despite the fact that the amortised inference is performed in a single forward pass. We then discuss how the APOVI-BNN may be viewed as a new member of the neural process family, motivating the use of neural process training objectives for potentially better predictive performance on complex problems as a result. Finally, we assess the predictive performance of the APOVI-BNN against other probabilistic meta-models in both a one-dimensional regression problem and in a significantly more complex image completion setting. In both cases, when the amount of training data is limited, our model is the best in its class.
A recommender for the management of chronic pain in patients undergoing spinal cord stimulation
Sep 06, 2023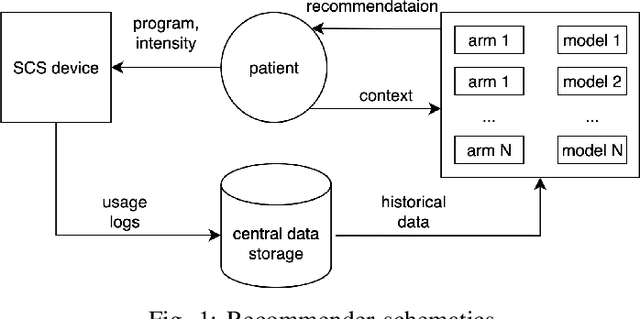
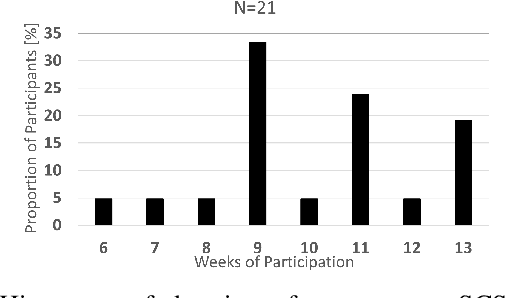
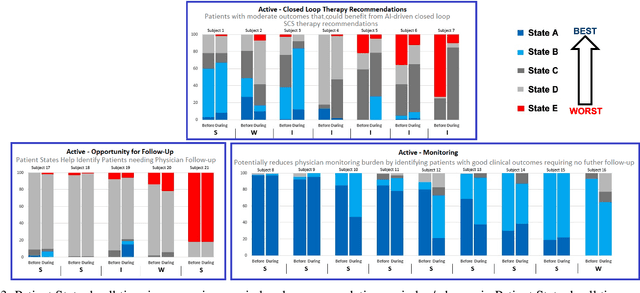
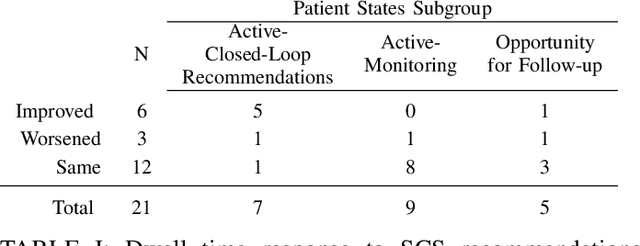
Spinal cord stimulation (SCS) is a therapeutic approach used for the management of chronic pain. It involves the delivery of electrical impulses to the spinal cord via an implanted device, which when given suitable stimulus parameters can mask or block pain signals. Selection of optimal stimulation parameters usually happens in the clinic under the care of a provider whereas at-home SCS optimization is managed by the patient. In this paper, we propose a recommender system for the management of pain in chronic pain patients undergoing SCS. In particular, we use a contextual multi-armed bandit (CMAB) approach to develop a system that recommends SCS settings to patients with the aim of improving their condition. These recommendations, sent directly to patients though a digital health ecosystem, combined with a patient monitoring system closes the therapeutic loop around a chronic pain patient over their entire patient journey. We evaluated the system in a cohort of SCS-implanted ENVISION study subjects (Clinicaltrials.gov ID: NCT03240588) using a combination of quality of life metrics and Patient States (PS), a novel measure of holistic outcomes. SCS recommendations provided statistically significant improvement in clinical outcomes (pain and/or QoL) in 85\% of all subjects (N=21). Among subjects in moderate PS (N=7) prior to receiving recommendations, 100\% showed statistically significant improvements and 5/7 had improved PS dwell time. This analysis suggests SCS patients may benefit from SCS recommendations, resulting in additional clinical improvement on top of benefits already received from SCS therapy.
Finite-time Lyapunov exponents of deep neural networks
Jun 21, 2023We compute how small input perturbations affect the output of deep neural networks, exploring an analogy between deep networks and dynamical systems, where the growth or decay of local perturbations is characterised by finite-time Lyapunov exponents. We show that the maximal exponent forms geometrical structures in input space, akin to coherent structures in dynamical systems. Ridges of large positive exponents divide input space into different regions that the network associates with different classes. These ridges visualise the geometry that deep networks construct in input space, shedding light on the fundamental mechanisms underlying their learning capabilities.
LEGO: Learning and Graph-Optimized Modular Tracker for Online Multi-Object Tracking with Point Clouds
Aug 19, 2023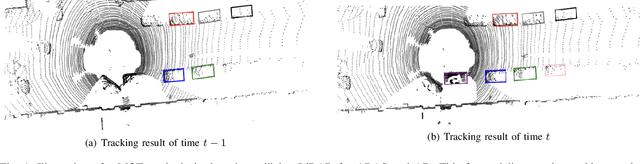
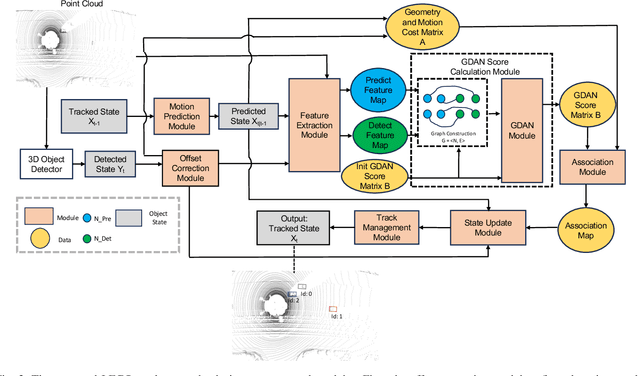
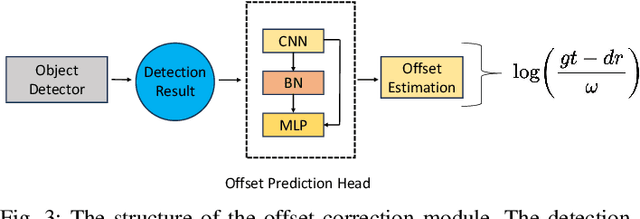
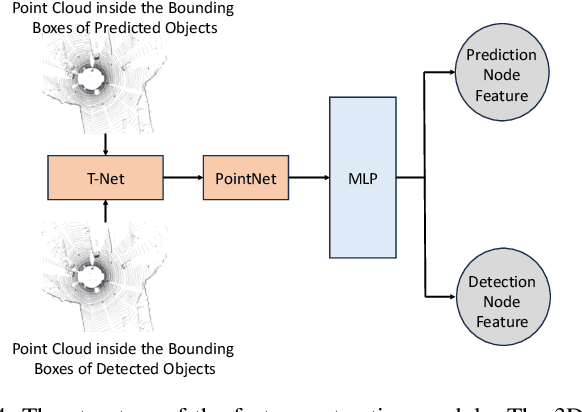
Online multi-object tracking (MOT) plays a pivotal role in autonomous systems. The state-of-the-art approaches usually employ a tracking-by-detection method, and data association plays a critical role. This paper proposes a learning and graph-optimized (LEGO) modular tracker to improve data association performance in the existing literature. The proposed LEGO tracker integrates graph optimization and self-attention mechanisms, which efficiently formulate the association score map, facilitating the accurate and efficient matching of objects across time frames. To further enhance the state update process, the Kalman filter is added to ensure consistent tracking by incorporating temporal coherence in the object states. Our proposed method utilizing LiDAR alone has shown exceptional performance compared to other online tracking approaches, including LiDAR-based and LiDAR-camera fusion-based methods. LEGO ranked 1st at the time of submitting results to KITTI object tracking evaluation ranking board and remains 2nd at the time of submitting this paper, among all online trackers in the KITTI MOT benchmark for cars1
Miriam: Exploiting Elastic Kernels for Real-time Multi-DNN Inference on Edge GPU
Jul 10, 2023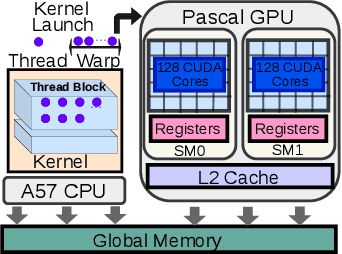

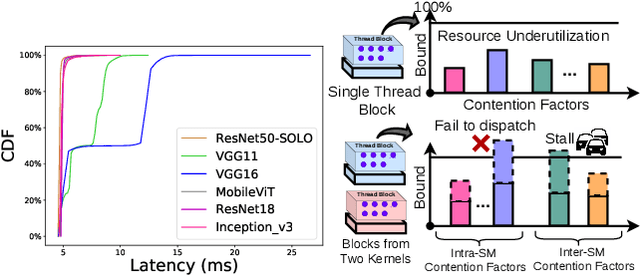

Many applications such as autonomous driving and augmented reality, require the concurrent running of multiple deep neural networks (DNN) that poses different levels of real-time performance requirements. However, coordinating multiple DNN tasks with varying levels of criticality on edge GPUs remains an area of limited study. Unlike server-level GPUs, edge GPUs are resource-limited and lack hardware-level resource management mechanisms for avoiding resource contention. Therefore, we propose Miriam, a contention-aware task coordination framework for multi-DNN inference on edge GPU. Miriam consolidates two main components, an elastic-kernel generator, and a runtime dynamic kernel coordinator, to support mixed critical DNN inference. To evaluate Miriam, we build a new DNN inference benchmark based on CUDA with diverse representative DNN workloads. Experiments on two edge GPU platforms show that Miriam can increase system throughput by 92% while only incurring less than 10\% latency overhead for critical tasks, compared to state of art baselines.
Neural Implicit Morphing of Face Images
Aug 26, 2023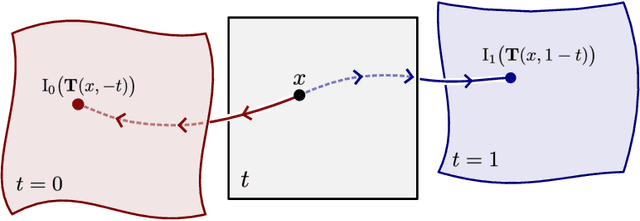



Face morphing is one of the seminal problems in computer graphics, with numerous artistic and forensic applications. It is notoriously challenging due to pose, lighting, gender, and ethnicity variations. Generally, this task consists of a warping for feature alignment and a blending for a seamless transition between the warped images. We propose to leverage coordinate-based neural networks to represent such warpings and blendings of face images. During training, we exploit the smoothness and flexibility of such networks, by combining energy functionals employed in classical approaches without discretizations. Additionally, our method is time-dependent, allowing a continuous warping, and blending of the target images. During warping inference, we need both direct and inverse transformations of the time-dependent warping. The first is responsible for morphing the target image into the source image, while the inverse is used for morphing in the opposite direction. Our neural warping stores those maps in a single network due to its inversible property, dismissing the hard task of inverting them. The results of our experiments indicate that our method is competitive with both classical and data-based neural techniques under the lens of face-morphing detection approaches. Aesthetically, the resulting images present a seamless blending of diverse faces not yet usual in the literature.
ICU Mortality Prediction Using Long Short-Term Memory Networks
Aug 18, 2023Extensive bedside monitoring in Intensive Care Units (ICUs) has resulted in complex temporal data regarding patient physiology, which presents an upscale context for clinical data analysis. In the other hand, identifying the time-series patterns within these data may provide a high aptitude to predict clinical events. Hence, we investigate, during this work, the implementation of an automatic data-driven system, which analyzes large amounts of multivariate temporal data derived from Electronic Health Records (EHRs), and extracts high-level information so as to predict in-hospital mortality and Length of Stay (LOS) early. Practically, we investigate the applicability of LSTM network by reducing the time-frame to 6-hour so as to enhance clinical tasks. The experimental results highlight the efficiency of LSTM model with rigorous multivariate time-series measurements for building real-world prediction engines.