 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokaMind: A Multi-Modal Transformer Foundation Model for Tokamak Plasma Dynamics
Feb 16, 2026We present TokaMind, an open-source foundation model framework for fusion plasma modeling, based on a Multi-Modal Transformer (MMT) and trained on heterogeneous tokamak diagnostics from the publicly available MAST dataset. TokaMind supports multiple data modalities (time-series, 2D profiles, and videos) with different sampling rates, robust missing-signal handling, and efficient task adaptation via selectively loading and freezing four model components. To represent multi-modal signals, we use a training-free Discrete Cosine Transform embedding (DCT3D) and provide a clean interface for alternative embeddings (e.g., Variational Autoencoders - VAEs). We evaluate TokaMind on the recently introduced MAST benchmark TokaMark, comparing training and embedding strategies. Our results show that fine-tuned TokaMind outperforms the benchmark baseline on all but one task, and that, for several tasks, lightweight fine-tuning yields better performance than training the same architecture from scratch under a matched epoch budget. These findings highlight the benefits of multi-modal pretraining for tokamak plasma dynamics and provide a practical, extensible foundation for future fusion modeling tasks. Training code and model weights will be made publicly available.
TokaMark: A Comprehensive Benchmark for MAST Tokamak Plasma Models
Feb 12, 2026Development and operation of commercially viable fusion energy reactors such as tokamaks require accurate predictions of plasma dynamics from sparse, noisy, and incomplete sensors readings. The complexity of the underlying physics and the heterogeneity of experimental data pose formidable challenges for conventional numerical methods, while simultaneously highlight the promise of modern data-native AI approaches. A major obstacle in realizing this potential is, however, the lack of curated, openly available datasets and standardized benchmarks. Existing fusion datasets are scarce, fragmented across institutions, facility-specific, and inconsistently annotated, which limits reproducibility and prevents a fair and scalable comparison of AI approaches. In this paper, we introduce TokaMark, a structured benchmark to evaluate AI models on real experimental data collected from the Mega Ampere Spherical Tokamak (MAST). TokaMark provides a comprehensive suite of tools designed to (i) unify access to multi-modal heterogeneous fusion data, and (ii) harmonize formats, metadata, temporal alignment and evaluation protocols to enable consistent cross-model and cross-task comparisons. The benchmark includes a curated list of 14 tasks spanning a range of physical mechanisms, exploiting a variety of diagnostics and covering multiple operational use cases. A baseline model is provided to facilitate transparent comparison and validation within a unified framework. By establishing a unified benchmark for both the fusion and AI-for-science communities, TokaMark aims to accelerate progress in data-driven AI-based plasma modeling, contributing to the broader goal of achieving sustainable and stable fusion energy. The benchmark, documentation, and tooling will be fully open sourced upon acceptance to encourage community adoption and contribution.
WaveGAS: Waveform Relaxation for Scaling Graph Neural Networks
Feb 27, 2025



With the ever-growing size of real-world graphs, numerous techniques to overcome resource limitations when training Graph Neural Networks (GNNs) have been developed. One such approach, GNNAutoScale (GAS), uses graph partitioning to enable training under constrained GPU memory. GAS also stores historical embedding vectors, which are retrieved from one-hop neighbors in other partitions, ensuring critical information is captured across partition boundaries. The historical embeddings which come from the previous training iteration are stale compared to the GAS estimated embeddings, resulting in approximation errors of the training algorithm. Furthermore, these errors accumulate over multiple layers, leading to suboptimal node embeddings. To address this shortcoming, we propose two enhancements: first, WaveGAS, inspired by waveform relaxation, performs multiple forward passes within GAS before the backward pass, refining the approximation of historical embeddings and gradients to improve accuracy; second, a gradient-tracking method that stores and utilizes more accurate historical gradients during training. Empirical results show that WaveGAS enhances GAS and achieves better accuracy, even outperforming methods that train on full graphs, thanks to its robust estimation of node embeddings.
Information Flow in Graph Neural Networks: A Clinical Triage Use Case
Sep 12, 2023Graph Neural Networks (GNNs) have gained popularity in healthcare and other domains due to their ability to process multi-modal and multi-relational graphs. However, efficient training of GNNs remains challenging, with several open research questions. In this paper, we investigate how the flow of embedding information within GNNs affects the prediction of links in Knowledge Graphs (KGs). Specifically, we propose a mathematical model that decouples the GNN connectivity from the connectivity of the graph data and evaluate the performance of GNNs in a clinical triage use case. Our results demonstrate that incorporating domain knowledge into the GNN connectivity leads to better performance than using the same connectivity as the KG or allowing unconstrained embedding propagation. Moreover, we show that negative edges play a crucial role in achieving good predictions, and that using too many GNN layers can degrade performance.
A recommender for the management of chronic pain in patients undergoing spinal cord stimulation
Sep 06, 2023



Spinal cord stimulation (SCS) is a therapeutic approach used for the management of chronic pain. It involves the delivery of electrical impulses to the spinal cord via an implanted device, which when given suitable stimulus parameters can mask or block pain signals. Selection of optimal stimulation parameters usually happens in the clinic under the care of a provider whereas at-home SCS optimization is managed by the patient. In this paper, we propose a recommender system for the management of pain in chronic pain patients undergoing SCS. In particular, we use a contextual multi-armed bandit (CMAB) approach to develop a system that recommends SCS settings to patients with the aim of improving their condition. These recommendations, sent directly to patients though a digital health ecosystem, combined with a patient monitoring system closes the therapeutic loop around a chronic pain patient over their entire patient journey. We evaluated the system in a cohort of SCS-implanted ENVISION study subjects (Clinicaltrials.gov ID: NCT03240588) using a combination of quality of life metrics and Patient States (PS), a novel measure of holistic outcomes. SCS recommendations provided statistically significant improvement in clinical outcomes (pain and/or QoL) in 85\% of all subjects (N=21). Among subjects in moderate PS (N=7) prior to receiving recommendations, 100\% showed statistically significant improvements and 5/7 had improved PS dwell time. This analysis suggests SCS patients may benefit from SCS recommendations, resulting in additional clinical improvement on top of benefits already received from SCS therapy.
Otter-Knowledge: benchmarks of multimodal knowledge graph representation learning from different sources for drug discovery
Jun 23, 2023Recent research in representation learning utilizes large databases of proteins or molecules to acquire knowledge of drug and protein structures through unsupervised learning techniques. These pre-trained representations have proven to significantly enhance the accuracy of subsequent tasks, such as predicting the affinity between drugs and target proteins. In this study, we demonstrate that by incorporating knowledge graphs from diverse sources and modalities into the sequences or SMILES representation, we can further enrich the representation and achieve state-of-the-art results on established benchmark datasets. We provide preprocessed and integrated data obtained from 7 public sources, which encompass over 30M triples. Additionally, we make available the pre-trained models based on this data, along with the reported outcomes of their performance on three widely-used benchmark datasets for drug-target binding affinity prediction found in the Therapeutic Data Commons (TDC) benchmarks. Additionally, we make the source code for training models on benchmark datasets publicly available. Our objective in releasing these pre-trained models, accompanied by clean data for model pretraining and benchmark results, is to encourage research in knowledge-enhanced representation learning.
Super Resolution for Turbulent Flows in 2D: Stabilized Physics Informed Neural Networks
Apr 15, 2022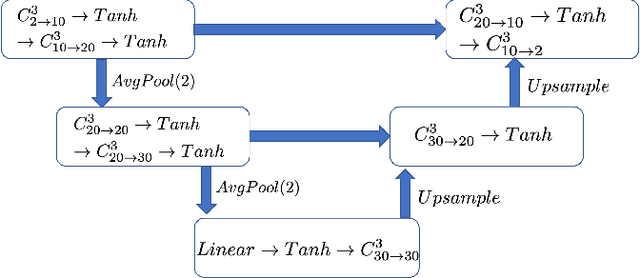
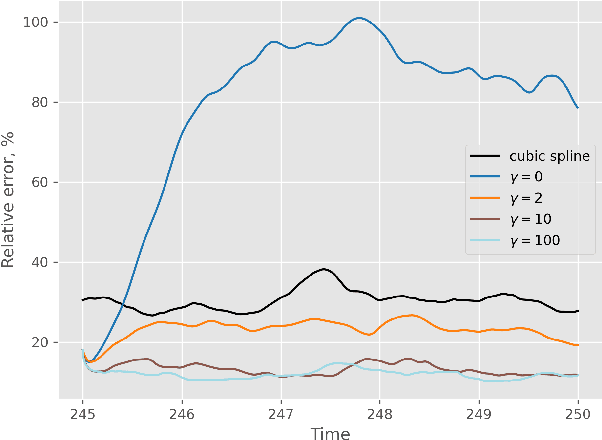
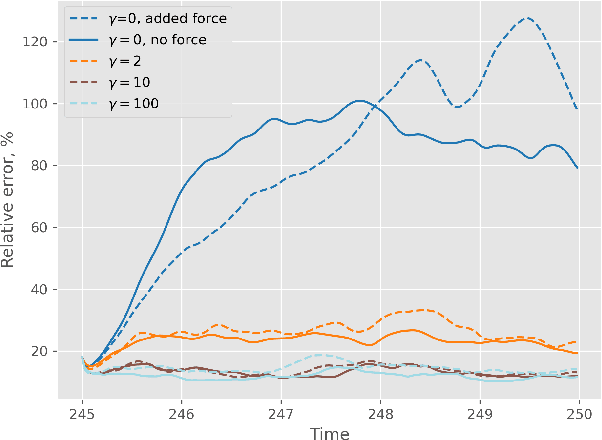
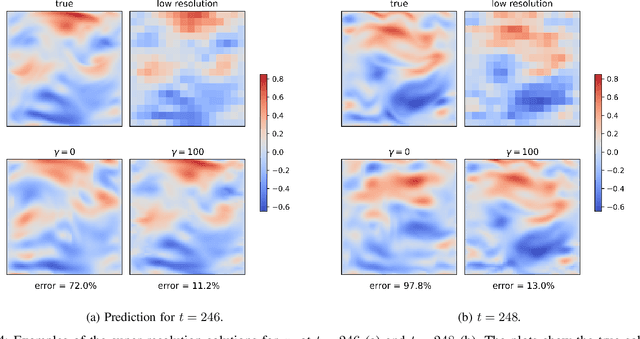
We propose a new design of a neural network for solving a zero shot super resolution problem for turbulent flows. We embed Luenberger-type observer into the network's architecture to inform the network of the physics of the process, and to provide error correction and stabilization mechanisms. In addition, to compensate for decrease of observer's performance due to the presence of unknown destabilizing forcing, the network is designed to estimate the contribution of the unknown forcing implicitly from the data over the course of training. By running a set of numerical experiments, we demonstrate that the proposed network does recover unknown forcing from data and is capable of predicting turbulent flows in high resolution from low resolution noisy observations.