 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokaMind: A Multi-Modal Transformer Foundation Model for Tokamak Plasma Dynamics
Feb 16, 2026We present TokaMind, an open-source foundation model framework for fusion plasma modeling, based on a Multi-Modal Transformer (MMT) and trained on heterogeneous tokamak diagnostics from the publicly available MAST dataset. TokaMind supports multiple data modalities (time-series, 2D profiles, and videos) with different sampling rates, robust missing-signal handling, and efficient task adaptation via selectively loading and freezing four model components. To represent multi-modal signals, we use a training-free Discrete Cosine Transform embedding (DCT3D) and provide a clean interface for alternative embeddings (e.g., Variational Autoencoders - VAEs). We evaluate TokaMind on the recently introduced MAST benchmark TokaMark, comparing training and embedding strategies. Our results show that fine-tuned TokaMind outperforms the benchmark baseline on all but one task, and that, for several tasks, lightweight fine-tuning yields better performance than training the same architecture from scratch under a matched epoch budget. These findings highlight the benefits of multi-modal pretraining for tokamak plasma dynamics and provide a practical, extensible foundation for future fusion modeling tasks. Training code and model weights will be made publicly available.
TokaMark: A Comprehensive Benchmark for MAST Tokamak Plasma Models
Feb 12, 2026Development and operation of commercially viable fusion energy reactors such as tokamaks require accurate predictions of plasma dynamics from sparse, noisy, and incomplete sensors readings. The complexity of the underlying physics and the heterogeneity of experimental data pose formidable challenges for conventional numerical methods, while simultaneously highlight the promise of modern data-native AI approaches. A major obstacle in realizing this potential is, however, the lack of curated, openly available datasets and standardized benchmarks. Existing fusion datasets are scarce, fragmented across institutions, facility-specific, and inconsistently annotated, which limits reproducibility and prevents a fair and scalable comparison of AI approaches. In this paper, we introduce TokaMark, a structured benchmark to evaluate AI models on real experimental data collected from the Mega Ampere Spherical Tokamak (MAST). TokaMark provides a comprehensive suite of tools designed to (i) unify access to multi-modal heterogeneous fusion data, and (ii) harmonize formats, metadata, temporal alignment and evaluation protocols to enable consistent cross-model and cross-task comparisons. The benchmark includes a curated list of 14 tasks spanning a range of physical mechanisms, exploiting a variety of diagnostics and covering multiple operational use cases. A baseline model is provided to facilitate transparent comparison and validation within a unified framework. By establishing a unified benchmark for both the fusion and AI-for-science communities, TokaMark aims to accelerate progress in data-driven AI-based plasma modeling, contributing to the broader goal of achieving sustainable and stable fusion energy. The benchmark, documentation, and tooling will be fully open sourced upon acceptance to encourage community adoption and contribution.
FactCorrector: A Graph-Inspired Approach to Long-Form Factuality Correction of Large Language Models
Jan 16, 2026Large language models (LLMs) are widely used in knowledge-intensive applications but often generate factually incorrect responses. A promising approach to rectify these flaws is correcting LLMs using feedback. Therefore, in this paper, we introduce FactCorrector, a new post-hoc correction method that adapts across domains without retraining and leverages structured feedback about the factuality of the original response to generate a correction. To support rigorous evaluations of factuality correction methods, we also develop the VELI5 benchmark, a novel dataset containing systematically injected factual errors and ground-truth corrections. Experiments on VELI5 and several popular long-form factuality datasets show that the FactCorrector approach significantly improves factual precision while preserving relevance, outperforming strong baselines. We release our code at https://ibm.biz/factcorrector.
Comprehensiveness Metrics for Automatic Evaluation of Factual Recall in Text Generation
Oct 09, 2025



Despite demonstrating remarkable performance across a wide range of tasks, large language models (LLMs) have also been found to frequently produce outputs that are incomplete or selectively omit key information. In sensitive domains, such omissions can result in significant harm comparable to that posed by factual inaccuracies, including hallucinations. In this study, we address the challenge of evaluating the comprehensiveness of LLM-generated texts, focusing on the detection of missing information or underrepresented viewpoints. We investigate three automated evaluation strategies: (1) an NLI-based method that decomposes texts into atomic statements and uses natural language inference (NLI) to identify missing links, (2) a Q&A-based approach that extracts question-answer pairs and compares responses across sources, and (3) an end-to-end method that directly identifies missing content using LLMs. Our experiments demonstrate the surprising effectiveness of the simple end-to-end approach compared to more complex methods, though at the cost of reduced robustness, interpretability and result granularity. We further assess the comprehensiveness of responses from several popular open-weight LLMs when answering user queries based on multiple sources.
Forging Time Series with Language: A Large Language Model Approach to Synthetic Data Generation
May 21, 2025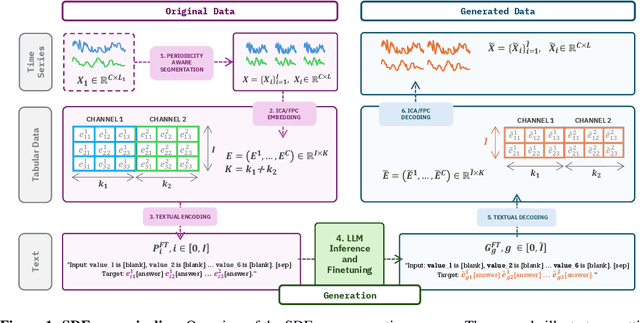
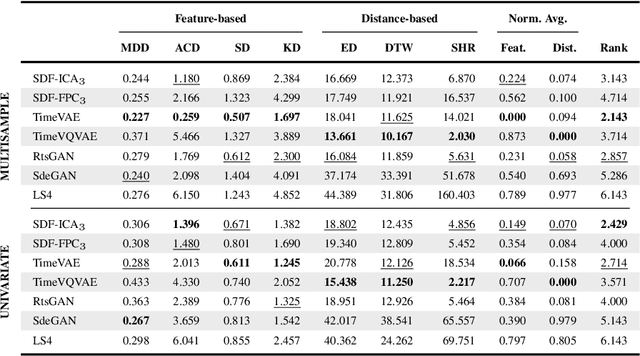
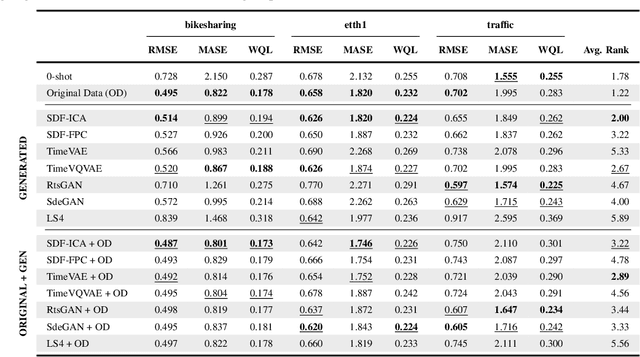
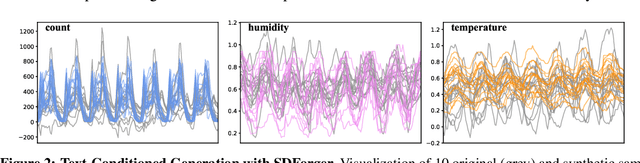
SDForger is a flexible and efficient framework for generating high-quality multivariate time series using LLMs. Leveraging a compact data representation, SDForger provides synthetic time series generation from a few samples and low-computation fine-tuning of any autoregressive LLM. Specifically, the framework transforms univariate and multivariate signals into tabular embeddings, which are then encoded into text and used to fine-tune the LLM. At inference, new textual embeddings are sampled and decoded into synthetic time series that retain the original data's statistical properties and temporal dynamics. Across a diverse range of datasets, SDForger outperforms existing generative models in many scenarios, both in similarity-based evaluations and downstream forecasting tasks. By enabling textual conditioning in the generation process, SDForger paves the way for multimodal modeling and the streamlined integration of time series with textual information. SDForger source code will be open-sourced soon.
Query-driven Document-level Scientific Evidence Extraction from Biomedical Studies
May 09, 2025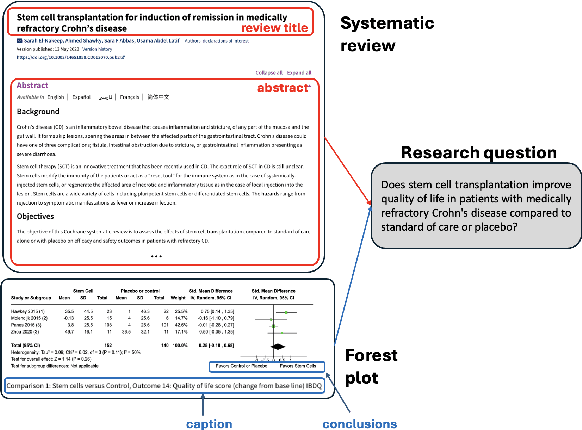
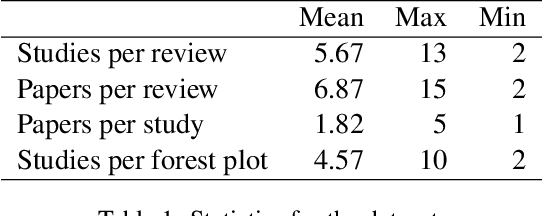
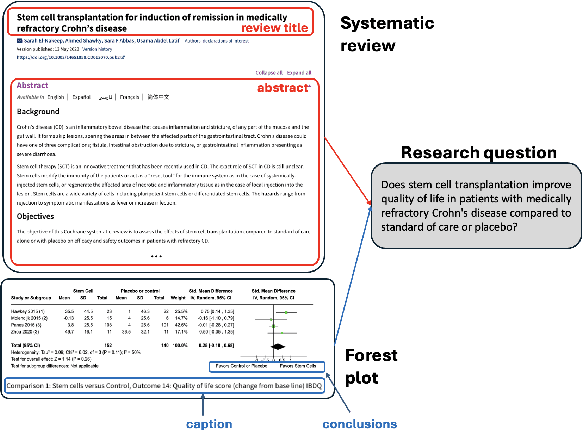
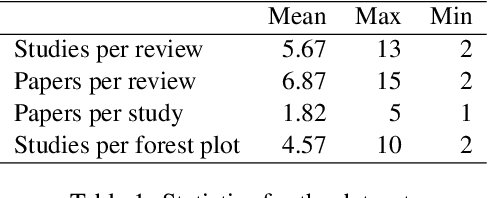
Extracting scientific evidence from biomedical studies for clinical research questions (e.g., Does stem cell transplantation improve quality of life in patients with medically refractory Crohn's disease compared to placebo?) is a crucial step in synthesising biomedical evidence. In this paper, we focus on the task of document-level scientific evidence extraction for clinical questions with conflicting evidence. To support this task, we create a dataset called CochraneForest, leveraging forest plots from Cochrane systematic reviews. It comprises 202 annotated forest plots, associated clinical research questions, full texts of studies, and study-specific conclusions. Building on CochraneForest, we propose URCA (Uniform Retrieval Clustered Augmentation), a retrieval-augmented generation framework designed to tackle the unique challenges of evidence extraction. Our experiments show that URCA outperforms the best existing methods by up to 10.3% in F1 score on this task. However, the results also underscore the complexity of CochraneForest, establishing it as a challenging testbed for advancing automated evidence synthesis systems.
FactReasoner: A Probabilistic Approach to Long-Form Factuality Assessment for Large Language Models
Feb 25, 2025



Large language models (LLMs) have demonstrated vast capabilities on generative tasks in recent years, yet they struggle with guaranteeing the factual correctness of the generated content. This makes these models unreliable in realistic situations where factually accurate responses are expected. In this paper, we propose FactReasoner, a new factuality assessor that relies on probabilistic reasoning to assess the factuality of a long-form generated response. Specifically, FactReasoner decomposes the response into atomic units, retrieves relevant contexts for them from an external knowledge source, and constructs a joint probability distribution over the atoms and contexts using probabilistic encodings of the logical relationships (entailment, contradiction) between the textual utterances corresponding to the atoms and contexts. FactReasoner then computes the posterior probability of whether atomic units in the response are supported by the retrieved contexts. Our experiments on labeled and unlabeled benchmark datasets demonstrate clearly that FactReasoner improves considerably over state-of-the-art prompt-based approaches in terms of both factual precision and recall.
WikiContradict: A Benchmark for Evaluating LLMs on Real-World Knowledge Conflicts from Wikipedia
Jun 19, 2024



Retrieval-augmented generation (RAG) has emerged as a promising solution to mitigate the limitations of large language models (LLMs), such as hallucinations and outdated information. However, it remains unclear how LLMs handle knowledge conflicts arising from different augmented retrieved passages, especially when these passages originate from the same source and have equal trustworthiness. In this work, we conduct a comprehensive evaluation of LLM-generated answers to questions that have varying answers based on contradictory passages from Wikipedia, a dataset widely regarded as a high-quality pre-training resource for most LLMs. Specifically, we introduce WikiContradict, a benchmark consisting of 253 high-quality, human-annotated instances designed to assess LLM performance when augmented with retrieved passages containing real-world knowledge conflicts. We benchmark a diverse range of both closed and open-source LLMs under different QA scenarios, including RAG with a single passage, and RAG with 2 contradictory passages. Through rigorous human evaluations on a subset of WikiContradict instances involving 5 LLMs and over 3,500 judgements, we shed light on the behaviour and limitations of these models. For instance, when provided with two passages containing contradictory facts, all models struggle to generate answers that accurately reflect the conflicting nature of the context, especially for implicit conflicts requiring reasoning. Since human evaluation is costly, we also introduce an automated model that estimates LLM performance using a strong open-source language model, achieving an F-score of 0.8. Using this automated metric, we evaluate more than 1,500 answers from seven LLMs across all WikiContradict instances. To facilitate future work, we release WikiContradict on: https://ibm.biz/wikicontradict.
Functional Graph Convolutional Networks: A unified multi-task and multi-modal learning framework to facilitate health and social-care insights
Mar 27, 2024



This paper introduces a novel Functional Graph Convolutional Network (funGCN) framework that combines Functional Data Analysis and Graph Convolutional Networks to address the complexities of multi-task and multi-modal learning in digital health and longitudinal studies. With the growing importance of health solutions to improve health care and social support, ensure healthy lives, and promote well-being at all ages, funGCN offers a unified approach to handle multivariate longitudinal data for multiple entities and ensures interpretability even with small sample sizes. Key innovations include task-specific embedding components that manage different data types, the ability to perform classification, regression, and forecasting, and the creation of a knowledge graph for insightful data interpretation. The efficacy of funGCN is validated through simulation experiments and a real-data application.
Feature Selection for Functional Data Classification
Jan 11, 2024


Functional data analysis has emerged as a crucial tool in many contemporary scientific domains that require the integration and interpretation of complex data. Moreover, the advent of new technologies has facilitated the collection of a large number of longitudinal variables, making feature selection pivotal for avoiding overfitting and improving prediction performance. This paper introduces a novel methodology called FSFC (Feature Selection for Functional Classification), that addresses the challenge of jointly performing feature selection and classification of functional data in scenarios with categorical responses and longitudinal features. Our approach tackles a newly defined optimization problem that integrates logistic loss and functional features to identify the most crucial features for classification. To address the minimization procedure, we employ functional principal components and develop a new adaptive version of the Dual Augmented Lagrangian algorithm that leverages the sparsity structure of the problem for dimensionality reduction. The computational efficiency of FSFC enables handling high-dimensional scenarios where the number of features may considerably exceed the number of statistical units. Simulation experiments demonstrate that FSFC outperforms other machine learning and deep learning methods in computational time and classification accuracy. Furthermore, the FSFC feature selection capability can be leveraged to significantly reduce the problem's dimensionality and enhance the performances of other classification algorithms. The efficacy of FSFC is also demonstrated through a real data application, analyzing relationships between four chronic diseases and other health and socio-demographic factors.