 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Controlling Continuous Relaxation for Combinatorial Optimization
Sep 29, 2023
Recent advancements in combinatorial optimization (CO) problems emphasize the potential of graph neural networks (GNNs). The physics-inspired GNN (PI-GNN) solver, which finds approximate solutions through unsupervised learning, has attracted significant attention for large-scale CO problems. Nevertheless, there has been limited discussion on the performance of the PI-GNN solver for CO problems on relatively dense graphs where the performance of greedy algorithms worsens. In addition, since the PI-GNN solver employs a relaxation strategy, an artificial transformation from the continuous space back to the original discrete space is necessary after learning, potentially undermining the robustness of the solutions. This paper numerically demonstrates that the PI-GNN solver can be trapped in a local solution, where all variables are zero, in the early stage of learning for CO problems on the dense graphs. Then, we address these problems by controlling the continuity and discreteness of relaxed variables while avoiding the local solution: (i) introducing a new penalty term that controls the continuity and discreteness of the relaxed variables and eliminates the local solution; (ii) proposing a new continuous relaxation annealing (CRA) strategy. This new annealing first prioritizes continuous solutions and intensifies exploration by leveraging the continuity while avoiding the local solution and then schedules the penalty term for prioritizing a discrete solution until the relaxed variables are almost discrete values, which eliminates the need for an artificial transformation from the continuous to the original discrete space. Empirically, better results are obtained for CO problems on the dense graphs, where the PI-GNN solver struggles to find reasonable solutions, and for those on relatively sparse graphs. Furthermore, the computational time scaling is identical to that of the PI-GNN solver.
Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks
Sep 29, 2023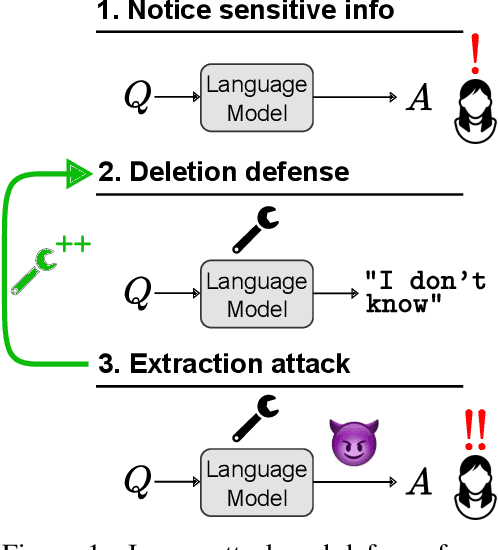
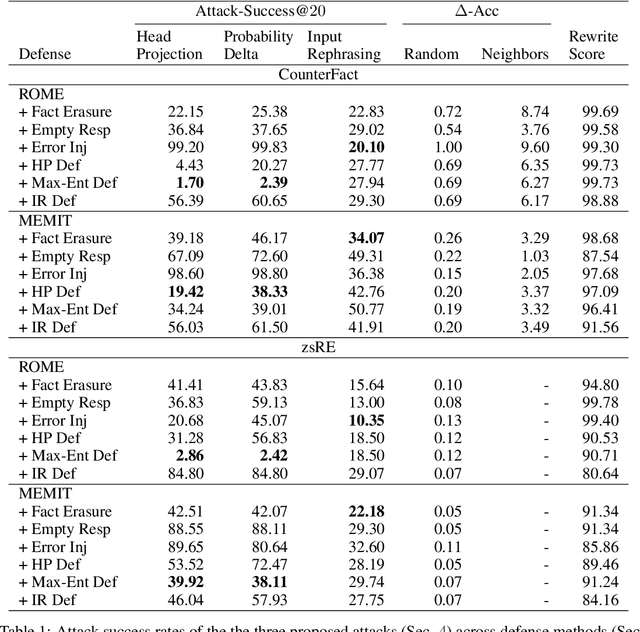
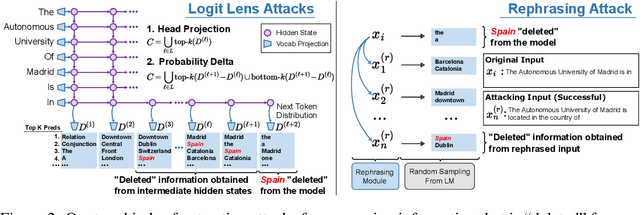

Pretrained language models sometimes possess knowledge that we do not wish them to, including memorized personal information and knowledge that could be used to harm people. They can also output toxic or harmful text. To mitigate these safety and informational issues, we propose an attack-and-defense framework for studying the task of deleting sensitive information directly from model weights. We study direct edits to model weights because (1) this approach should guarantee that particular deleted information is never extracted by future prompt attacks, and (2) it should protect against whitebox attacks, which is necessary for making claims about safety/privacy in a setting where publicly available model weights could be used to elicit sensitive information. Our threat model assumes that an attack succeeds if the answer to a sensitive question is located among a set of B generated candidates, based on scenarios where the information would be insecure if the answer is among B candidates. Experimentally, we show that even state-of-the-art model editing methods such as ROME struggle to truly delete factual information from models like GPT-J, as our whitebox and blackbox attacks can recover "deleted" information from an edited model 38% of the time. These attacks leverage two key observations: (1) that traces of deleted information can be found in intermediate model hidden states, and (2) that applying an editing method for one question may not delete information across rephrased versions of the question. Finally, we provide new defense methods that protect against some extraction attacks, but we do not find a single universally effective defense method. Our results suggest that truly deleting sensitive information is a tractable but difficult problem, since even relatively low attack success rates have potentially severe societal implications for real-world deployment of language models.
CRAFT: Customizing LLMs by Creating and Retrieving from Specialized Toolsets
Sep 29, 2023
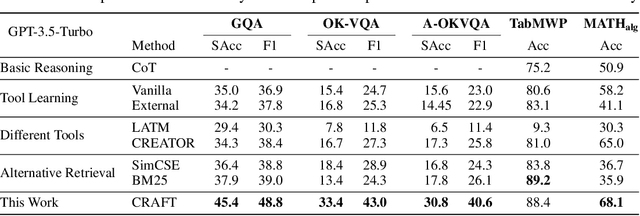
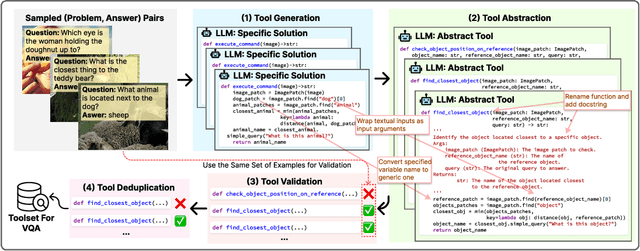
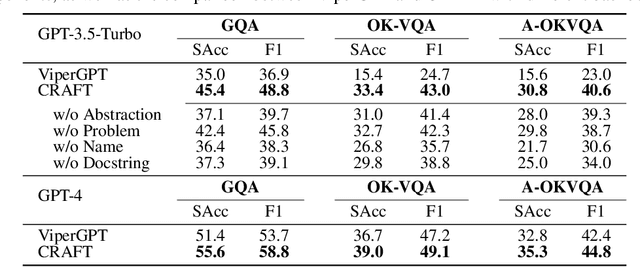
Large language models (LLMs) are often augmented with tools to solve complex tasks. By generating code snippets and executing them through task-specific Application Programming Interfaces (APIs), they can offload certain functions to dedicated external modules, such as image encoding and performing calculations. However, most existing approaches to augment LLMs with tools are constrained by general-purpose APIs and lack the flexibility for tailoring them to specific tasks. In this work, we present CRAFT, a general tool creation and retrieval framework for LLMs. It creates toolsets specifically curated for the tasks and equips LLMs with a component that retrieves tools from these sets to enhance their capability to solve complex tasks. For each task, we collect specific code solutions by prompting GPT-4 to solve the training examples. Following a validation step ensuring the correctness, these solutions are abstracted into code snippets to enhance reusability, and deduplicated for higher quality. At inference time, the language model retrieves snippets from the toolsets and then executes them or generates the output conditioning on the retrieved snippets. Our method is designed to be flexible and offers a plug-and-play approach to adapt off-the-shelf LLMs to unseen domains and modalities, without any finetuning. Experiments on vision-language, tabular processing, and mathematical reasoning tasks show that our approach achieves substantial improvements compared to strong baselines. In addition, our in-depth analysis reveals that: (1) consistent performance improvement can be achieved by scaling up the number of tools and the capability of the backbone models; (2) each component of our approach contributes to the performance gains; (3) the created tools are well-structured and reliable with low complexity and atomicity. The code is available at \url{https://github.com/lifan-yuan/CRAFT}.
Haptic Guidance and Haptic Error Amplification in a Virtual Surgical Robotic Training Environment
Sep 11, 2023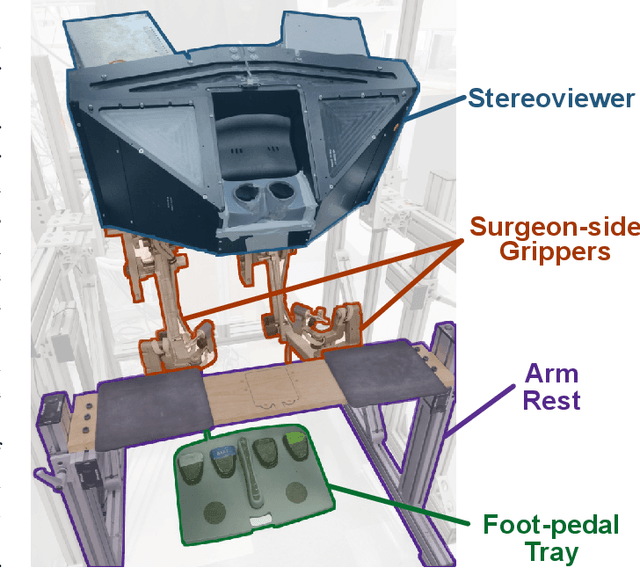
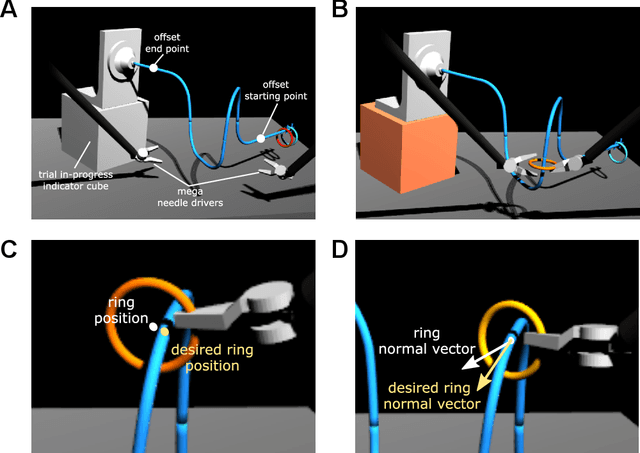
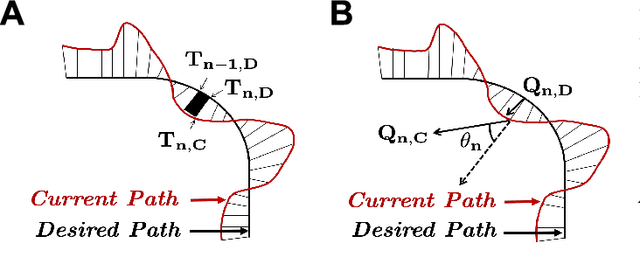
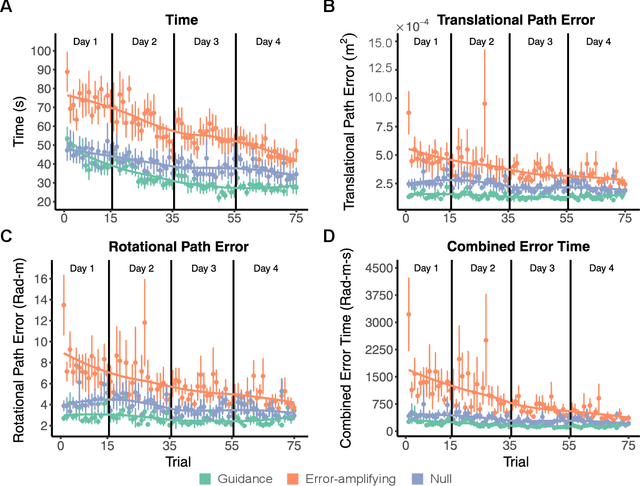
Teleoperated robotic systems have introduced more intuitive control for minimally invasive surgery, but the optimal method for training remains unknown. Recent motor learning studies have demonstrated that exaggeration of errors helps trainees learn to perform tasks with greater speed and accuracy. We hypothesized that training in a force field that pushes the operator away from a desired path would improve their performance on a virtual reality ring-on-wire task. Forty surgical novices trained under a no-force, guidance, or error-amplifying force field over five days. Completion time, translational and rotational path error, and combined error-time were evaluated under no force field on the final day. The groups significantly differed in combined error-time, with the guidance group performing the worst. Error-amplifying field participants showed the most improvement and did not plateau in their performance during training, suggesting that learning was still ongoing. Guidance field participants had the worst performance on the final day, confirming the guidance hypothesis. Participants with high initial path error benefited more from guidance. Participants with high initial combined error-time benefited more from guidance and error-amplifying force field training. Our results suggest that error-amplifying and error-reducing haptic training for robot-assisted telesurgery benefits trainees of different abilities differently.
Learning noise-induced transitions by multi-scaling reservoir computing
Sep 11, 2023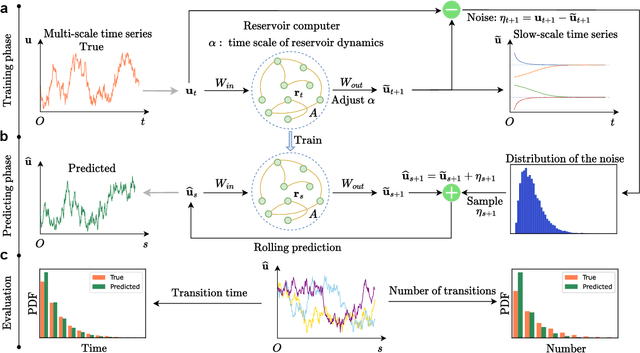
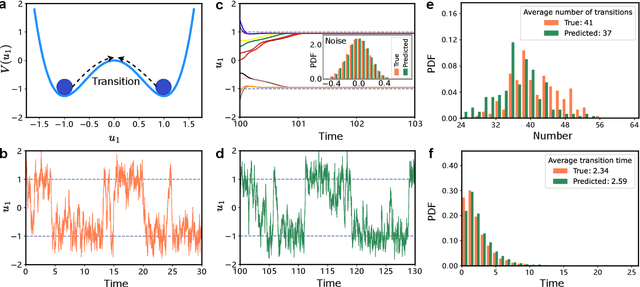
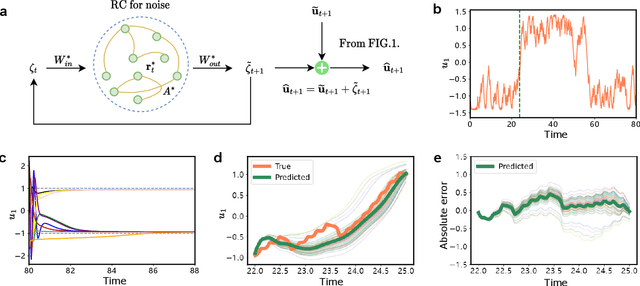
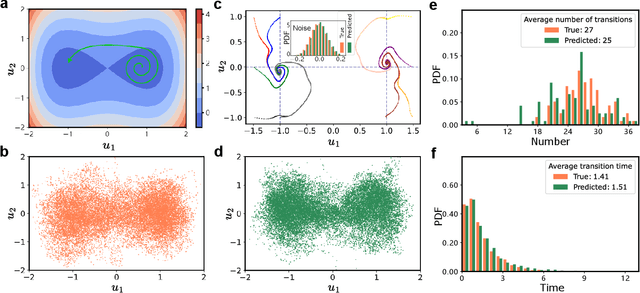
Noise is usually regarded as adversarial to extract the effective dynamics from time series, such that the conventional data-driven approaches usually aim at learning the dynamics by mitigating the noisy effect. However, noise can have a functional role of driving transitions between stable states underlying many natural and engineered stochastic dynamics. To capture such stochastic transitions from data, we find that leveraging a machine learning model, reservoir computing as a type of recurrent neural network, can learn noise-induced transitions. We develop a concise training protocol for tuning hyperparameters, with a focus on a pivotal hyperparameter controlling the time scale of the reservoir dynamics. The trained model generates accurate statistics of transition time and the number of transitions. The approach is applicable to a wide class of systems, including a bistable system under a double-well potential, with either white noise or colored noise. It is also aware of the asymmetry of the double-well potential, the rotational dynamics caused by non-detailed balance, and transitions in multi-stable systems. For the experimental data of protein folding, it learns the transition time between folded states, providing a possibility of predicting transition statistics from a small dataset. The results demonstrate the capability of machine-learning methods in capturing noise-induced phenomena.
Machine Learning Data Suitability and Performance Testing Using Fault Injection Testing Framework
Sep 20, 2023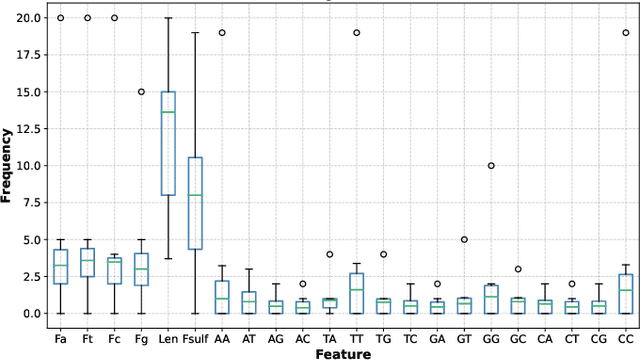
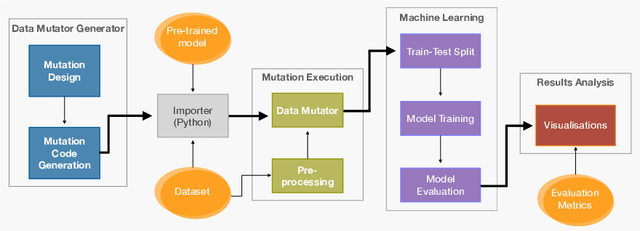
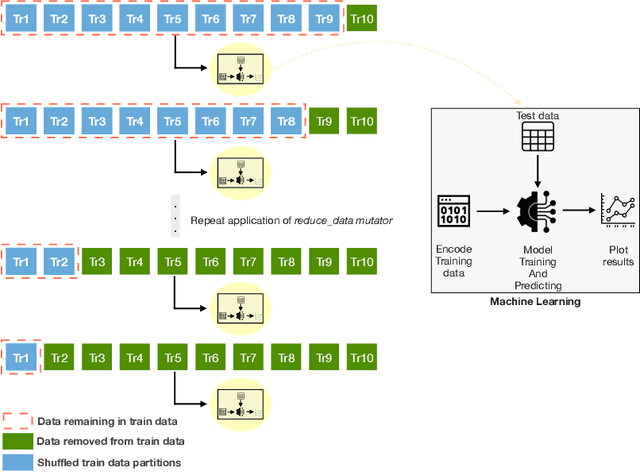
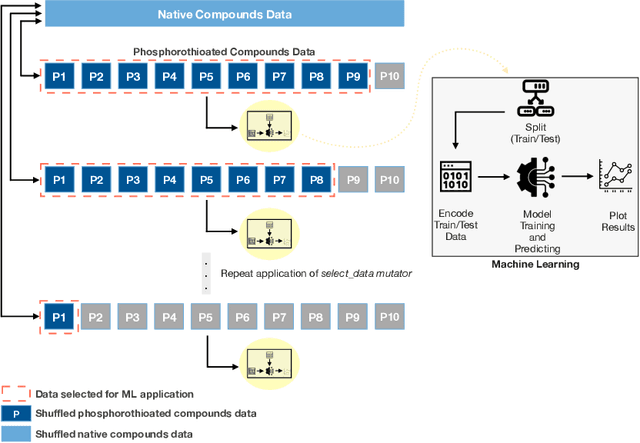
Creating resilient machine learning (ML) systems has become necessary to ensure production-ready ML systems that acquire user confidence seamlessly. The quality of the input data and the model highly influence the successful end-to-end testing in data-sensitive systems. However, the testing approaches of input data are not as systematic and are few compared to model testing. To address this gap, this paper presents the Fault Injection for Undesirable Learning in input Data (FIUL-Data) testing framework that tests the resilience of ML models to multiple intentionally-triggered data faults. Data mutators explore vulnerabilities of ML systems against the effects of different fault injections. The proposed framework is designed based on three main ideas: The mutators are not random; one data mutator is applied at an instance of time, and the selected ML models are optimized beforehand. This paper evaluates the FIUL-Data framework using data from analytical chemistry, comprising retention time measurements of anti-sense oligonucleotide. Empirical evaluation is carried out in a two-step process in which the responses of selected ML models to data mutation are analyzed individually and then compared with each other. The results show that the FIUL-Data framework allows the evaluation of the resilience of ML models. In most experiments cases, ML models show higher resilience at larger training datasets, where gradient boost performed better than support vector regression in smaller training sets. Overall, the mean squared error metric is useful in evaluating the resilience of models due to its higher sensitivity to data mutation.
Sig-Splines: universal approximation and convex calibration of time series generative models
Jul 19, 2023
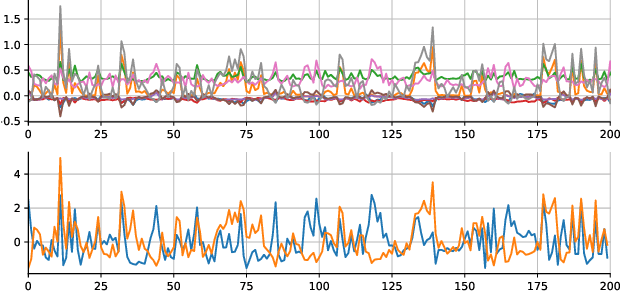
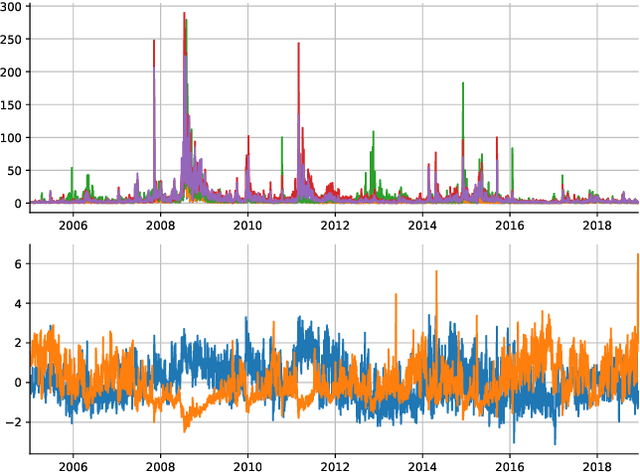
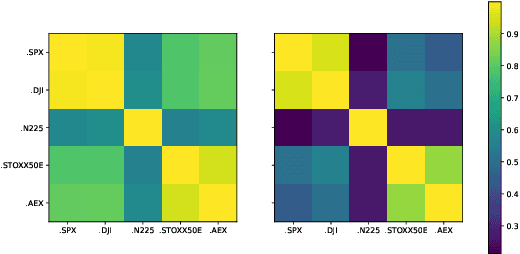
We propose a novel generative model for multivariate discrete-time time series data. Drawing inspiration from the construction of neural spline flows, our algorithm incorporates linear transformations and the signature transform as a seamless substitution for traditional neural networks. This approach enables us to achieve not only the universality property inherent in neural networks but also introduces convexity in the model's parameters.
TTD Configurations for Near-Field Beamforming: Parallel, Serial, or Hybrid?
Sep 13, 2023True-time delayers (TTDs) are popular components for hybrid beamforming architectures to combat the spatial-wideband effect in wideband near-field communications. A serial and a hybrid serial-parallel TTD configuration are investigated for hybrid beamforming architectures. Compared to the conventional parallel configuration, the serial configuration exhibits a cumulative time delay through multiple TTDs, which potentially alleviates the maximum delay requirements on the TTDs. However, independent control of individual TTDs becomes impossible in the serial configuration. In this context, a hybrid TTD configuration is proposed as a compromise solution. Furthermore, a power equalization approach is proposed to address the cumulative insertion loss of the serial and hybrid TTD configurations. Moreover, the wideband near-field beamforming design for different configurations is studied for maximizing the spectral efficiency in both single-user and multiple-user systems. 1) For single-user systems, a closed-form solution for the beamforming design is derived. The preferred user locations and the required maximum time delay of each TTD configuration are characterized. 2) For multi-user systems, a penalty-based iterative algorithm is developed to obtain a stationary point of the spectral efficiency maximization problem for each TTD configuration. In addition, a mixed-forward-and-backward (MFB) implementation is proposed to enhance the performance of the serial configuration. Our numerical results confirm the effectiveness of the proposed designs and unveil that i) compared to the conventional parallel configuration, both the serial and hybrid configurations can significantly reduce the maximum time delays required for the TTDs and ii) the hybrid configuration excels in single-user systems, while the serial configuration is preferred in multi-user systems.
Federated Learning in UAV-Enhanced Networks: Joint Coverage and Convergence Time Optimization
Aug 31, 2023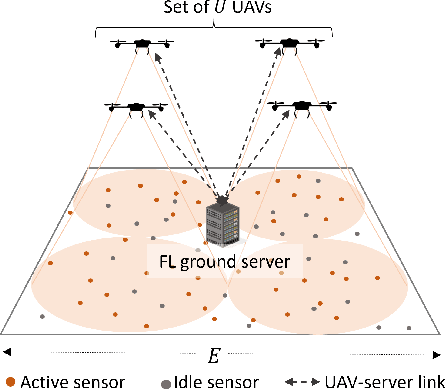
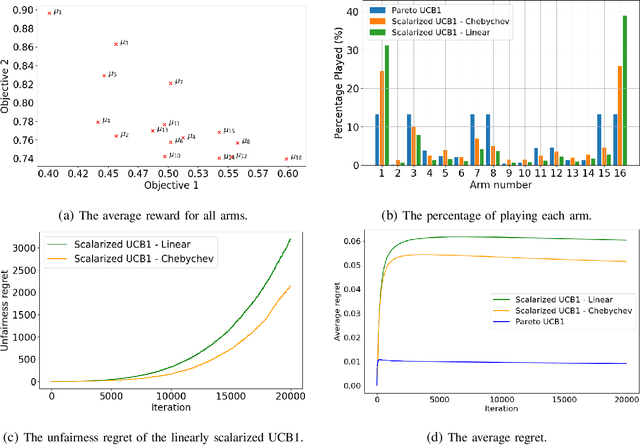
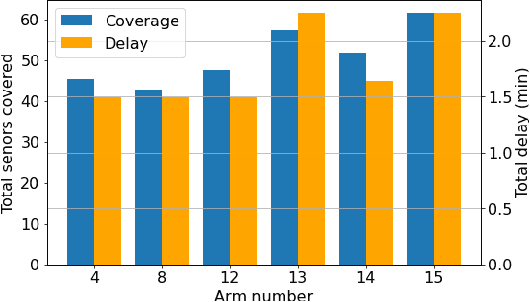
Federated learning (FL) involves several devices that collaboratively train a shared model without transferring their local data. FL reduces the communication overhead, making it a promising learning method in UAV-enhanced wireless networks with scarce energy resources. Despite the potential, implementing FL in UAV-enhanced networks is challenging, as conventional UAV placement methods that maximize coverage increase the FL delay significantly. Moreover, the uncertainty and lack of a priori information about crucial variables, such as channel quality, exacerbate the problem. In this paper, we first analyze the statistical characteristics of a UAV-enhanced wireless sensor network (WSN) with energy harvesting. We then develop a model and solution based on the multi-objective multi-armed bandit theory to maximize the network coverage while minimizing the FL delay. Besides, we propose another solution that is particularly useful with large action sets and strict energy constraints at the UAVs. Our proposal uses a scalarized best-arm identification algorithm to find the optimal arms that maximize the ratio of the expected reward to the expected energy cost by sequentially eliminating one or more arms in each round. Then, we derive the upper bound on the error probability of our multi-objective and cost-aware algorithm. Numerical results show the effectiveness of our approach.
Double Deep Q-Learning-based Path Selection and Service Placement for Latency-Sensitive Beyond 5G Applications
Sep 18, 2023Nowadays, as the need for capacity continues to grow, entirely novel services are emerging. A solid cloud-network integrated infrastructure is necessary to supply these services in a real-time responsive, and scalable way. Due to their diverse characteristics and limited capacity, communication and computing resources must be collaboratively managed to unleash their full potential. Although several innovative methods have been proposed to orchestrate the resources, most ignored network resources or relaxed the network as a simple graph, focusing only on cloud resources. This paper fills the gap by studying the joint problem of communication and computing resource allocation, dubbed CCRA, including function placement and assignment, traffic prioritization, and path selection considering capacity constraints and quality requirements, to minimize total cost. We formulate the problem as a non-linear programming model and propose two approaches, dubbed B\&B-CCRA and WF-CCRA, based on the Branch \& Bound and Water-Filling algorithms to solve it when the system is fully known. Then, for partially known systems, a Double Deep Q-Learning (DDQL) architecture is designed. Numerical simulations show that B\&B-CCRA optimally solves the problem, whereas WF-CCRA delivers near-optimal solutions in a substantially shorter time. Furthermore, it is demonstrated that DDQL-CCRA obtains near-optimal solutions in the absence of request-specific information.