 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AutoAD II: The Sequel -- Who, When, and What in Movie Audio Description
Oct 10, 2023

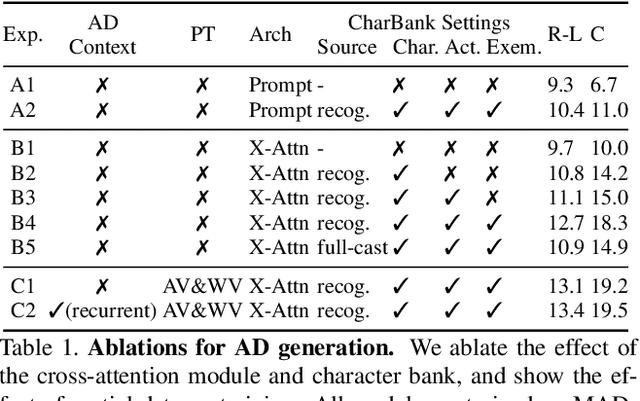
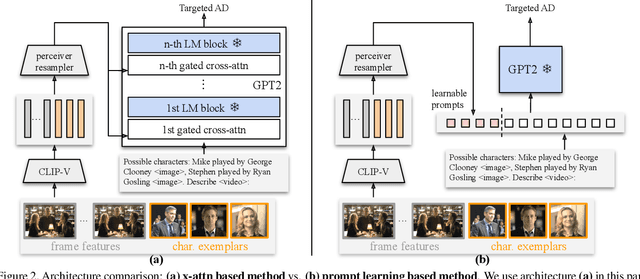

Audio Description (AD) is the task of generating descriptions of visual content, at suitable time intervals, for the benefit of visually impaired audiences. For movies, this presents notable challenges -- AD must occur only during existing pauses in dialogue, should refer to characters by name, and ought to aid understanding of the storyline as a whole. To this end, we develop a new model for automatically generating movie AD, given CLIP visual features of the frames, the cast list, and the temporal locations of the speech; addressing all three of the 'who', 'when', and 'what' questions: (i) who -- we introduce a character bank consisting of the character's name, the actor that played the part, and a CLIP feature of their face, for the principal cast of each movie, and demonstrate how this can be used to improve naming in the generated AD; (ii) when -- we investigate several models for determining whether an AD should be generated for a time interval or not, based on the visual content of the interval and its neighbours; and (iii) what -- we implement a new vision-language model for this task, that can ingest the proposals from the character bank, whilst conditioning on the visual features using cross-attention, and demonstrate how this improves over previous architectures for AD text generation in an apples-to-apples comparison.
An Emulator for Fine-Tuning Large Language Models using Small Language Models
Oct 19, 2023
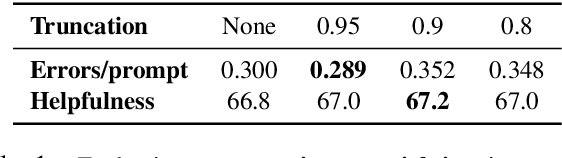
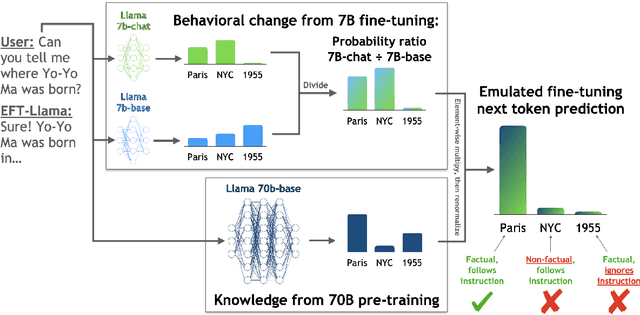
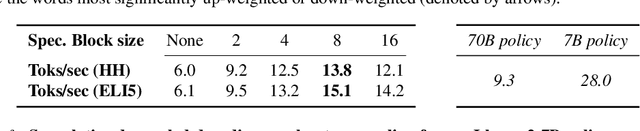
Widely used language models (LMs) are typically built by scaling up a two-stage training pipeline: a pre-training stage that uses a very large, diverse dataset of text and a fine-tuning (sometimes, 'alignment') stage that uses targeted examples or other specifications of desired behaviors. While it has been hypothesized that knowledge and skills come from pre-training, and fine-tuning mostly filters this knowledge and skillset, this intuition has not been extensively tested. To aid in doing so, we introduce a novel technique for decoupling the knowledge and skills gained in these two stages, enabling a direct answer to the question, "What would happen if we combined the knowledge learned by a large model during pre-training with the knowledge learned by a small model during fine-tuning (or vice versa)?" Using an RL-based framework derived from recent developments in learning from human preferences, we introduce emulated fine-tuning (EFT), a principled and practical method for sampling from a distribution that approximates (or 'emulates') the result of pre-training and fine-tuning at different scales. Our experiments with EFT show that scaling up fine-tuning tends to improve helpfulness, while scaling up pre-training tends to improve factuality. Beyond decoupling scale, we show that EFT enables test-time adjustment of competing behavioral traits like helpfulness and harmlessness without additional training. Finally, a special case of emulated fine-tuning, which we call LM up-scaling, avoids resource-intensive fine-tuning of large pre-trained models by ensembling them with small fine-tuned models, essentially emulating the result of fine-tuning the large pre-trained model. Up-scaling consistently improves helpfulness and factuality of instruction-following models in the Llama, Llama-2, and Falcon families, without additional hyperparameters or training.
TwinPot: Digital Twin-assisted Honeypot for Cyber-Secure Smart Seaports
Oct 19, 2023The idea of next-generation ports has become more apparent in the last ten years in response to the challenge posed by the rising demand for efficiency and the ever-increasing volume of goods. In this new era of intelligent infrastructure and facilities, it is evident that cyber-security has recently received the most significant attention from the seaport and maritime authorities, and it is a primary concern on the agenda of most ports. Traditional security solutions can be applied to safeguard IoT and Cyber-Physical Systems (CPS) from harmful entities. Nevertheless, security researchers can only watch, examine, and learn about the behaviors of attackers if these solutions operate more transparently. Herein, honeypots are potential solutions since they offer valuable information about the attackers. It can be virtual or physical. Virtual honeypots must be more realistic to entice attackers, necessitating better high-fidelity. To this end, Digital Twin (DT) technology can be employed to increase the complexity and simulation fidelity of the honeypots. Seaports can be attacked from both their existing devices and external devices at the same time. Existing mechanisms are insufficient to detect external attacks; therefore, the current systems cannot handle attacks at the desired level. DT and honeypot technologies can be used together to tackle them. Consequently, we suggest a DT-assisted honeypot, called TwinPot, for external attacks in smart seaports. Moreover, we propose an intelligent attack detection mechanism to handle different attack types using DT for internal attacks. Finally, we build an extensive smart seaport dataset for internal and external attacks using the MANSIM tool and two existing datasets to test the performance of our system. We show that under simultaneous internal and external attacks on the system, our solution successfully detects internal and external attacks.
An Optimistic-Robust Approach for Dynamic Positioning of Omnichannel Inventories
Oct 17, 2023We introduce a new class of data-driven and distribution-free optimistic-robust bimodal inventory optimization (BIO) strategy to effectively allocate inventory across a retail chain to meet time-varying, uncertain omnichannel demand. While prior Robust optimization (RO) methods emphasize the downside, i.e., worst-case adversarial demand, BIO also considers the upside to remain resilient like RO while also reaping the rewards of improved average-case performance by overcoming the presence of endogenous outliers. This bimodal strategy is particularly valuable for balancing the tradeoff between lost sales at the store and the costs of cross-channel e-commerce fulfillment, which is at the core of our inventory optimization model. These factors are asymmetric due to the heterogenous behavior of the channels, with a bias towards the former in terms of lost-sales cost and a dependence on network effects for the latter. We provide structural insights about the BIO solution and how it can be tuned to achieve a preferred tradeoff between robustness and the average-case. Our experiments show that significant benefits can be achieved by rethinking traditional approaches to inventory management, which are siloed by channel and location. Using a real-world dataset from a large American omnichannel retail chain, a business value assessment during a peak period indicates over a 15% profitability gain for BIO over RO and other baselines while also preserving the (practical) worst case performance.
Multi-point Feedback of Bandit Convex Optimization with Hard Constraints
Oct 17, 2023This paper studies bandit convex optimization with constraints, where the learner aims to generate a sequence of decisions under partial information of loss functions such that the cumulative loss is reduced as well as the cumulative constraint violation is simultaneously reduced. We adopt the cumulative \textit{hard} constraint violation as the metric of constraint violation, which is defined by $\sum_{t=1}^{T} \max\{g_t(\boldsymbol{x}_t), 0\}$. Owing to the maximum operator, a strictly feasible solution cannot cancel out the effects of violated constraints compared to the conventional metric known as \textit{long-term} constraints violation. We present a penalty-based proximal gradient descent method that attains a sub-linear growth of both regret and cumulative hard constraint violation, in which the gradient is estimated with a two-point function evaluation. Precisely, our algorithm attains $O(d^2T^{\max\{c,1-c\}})$ regret bounds and $O(d^2T^{1-\frac{c}{2}})$ cumulative hard constraint violation bounds for convex loss functions and time-varying constraints, where $d$ is the dimensionality of the feasible region and $c\in[\frac{1}{2}, 1)$ is a user-determined parameter. We also extend the result for the case where the loss functions are strongly convex and show that both regret and constraint violation bounds can be further reduced.
Accelerating Scalable Graph Neural Network Inference with Node-Adaptive Propagation
Oct 17, 2023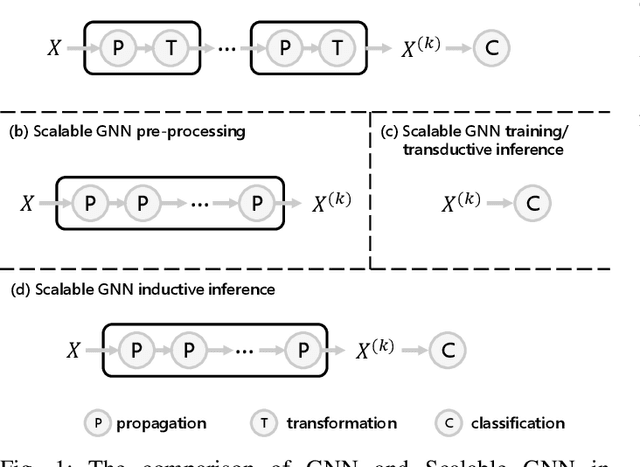
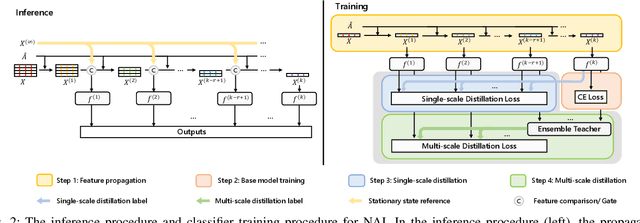
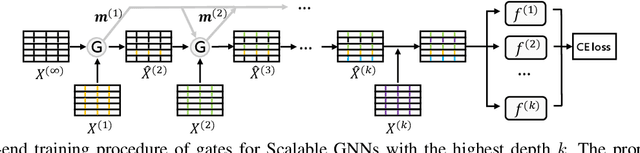
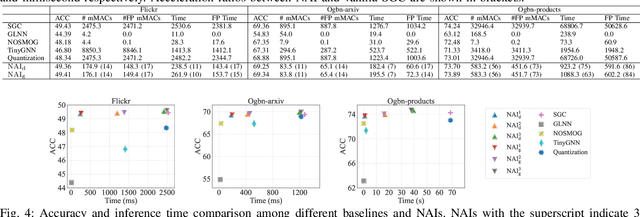
Graph neural networks (GNNs) have exhibited exceptional efficacy in a diverse array of applications. However, the sheer size of large-scale graphs presents a significant challenge to real-time inference with GNNs. Although existing Scalable GNNs leverage linear propagation to preprocess the features and accelerate the training and inference procedure, these methods still suffer from scalability issues when making inferences on unseen nodes, as the feature preprocessing requires the graph to be known and fixed. To further accelerate Scalable GNNs inference in this inductive setting, we propose an online propagation framework and two novel node-adaptive propagation methods that can customize the optimal propagation depth for each node based on its topological information and thereby avoid redundant feature propagation. The trade-off between accuracy and latency can be flexibly managed through simple hyper-parameters to accommodate various latency constraints. Moreover, to compensate for the inference accuracy loss caused by the potential early termination of propagation, we further propose Inception Distillation to exploit the multi-scale receptive field information within graphs. The rigorous and comprehensive experimental study on public datasets with varying scales and characteristics demonstrates that the proposed inference acceleration framework outperforms existing state-of-the-art graph inference acceleration methods in terms of accuracy and efficiency. Particularly, the superiority of our approach is notable on datasets with larger scales, yielding a 75x inference speedup on the largest Ogbn-products dataset.
CorrTalk: Correlation Between Hierarchical Speech and Facial Activity Variances for 3D Animation
Oct 17, 2023Speech-driven 3D facial animation is a challenging cross-modal task that has attracted growing research interest. During speaking activities, the mouth displays strong motions, while the other facial regions typically demonstrate comparatively weak activity levels. Existing approaches often simplify the process by directly mapping single-level speech features to the entire facial animation, which overlook the differences in facial activity intensity leading to overly smoothed facial movements. In this study, we propose a novel framework, CorrTalk, which effectively establishes the temporal correlation between hierarchical speech features and facial activities of different intensities across distinct regions. A novel facial activity intensity metric is defined to distinguish between strong and weak facial activity, obtained by computing the short-time Fourier transform of facial vertex displacements. Based on the variances in facial activity, we propose a dual-branch decoding framework to synchronously synthesize strong and weak facial activity, which guarantees wider intensity facial animation synthesis. Furthermore, a weighted hierarchical feature encoder is proposed to establish temporal correlation between hierarchical speech features and facial activity at different intensities, which ensures lip-sync and plausible facial expressions. Extensive qualitatively and quantitatively experiments as well as a user study indicate that our CorrTalk outperforms existing state-of-the-art methods. The source code and supplementary video are publicly available at: https://zjchu.github.io/projects/CorrTalk/
High-Fidelity Noise Reduction with Differentiable Signal Processing
Oct 17, 2023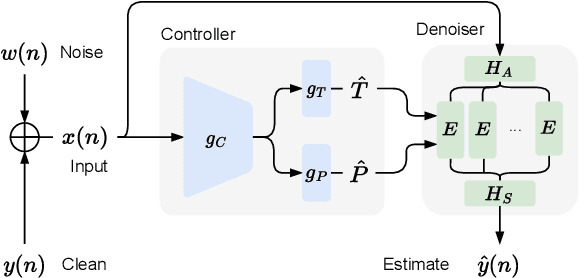
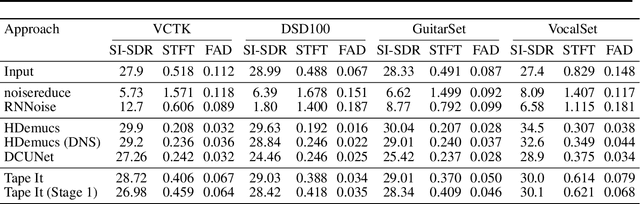
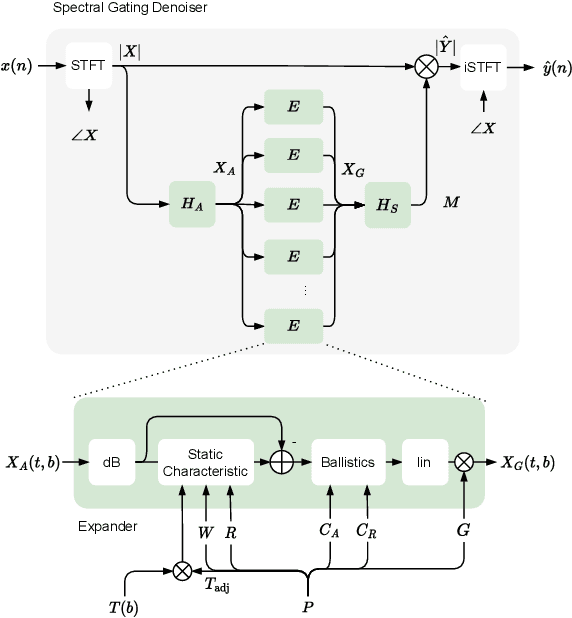

Noise reduction techniques based on deep learning have demonstrated impressive performance in enhancing the overall quality of recorded speech. While these approaches are highly performant, their application in audio engineering can be limited due to a number of factors. These include operation only on speech without support for music, lack of real-time capability, lack of interpretable control parameters, operation at lower sample rates, and a tendency to introduce artifacts. On the other hand, signal processing-based noise reduction algorithms offer fine-grained control and operation on a broad range of content, however, they often require manual operation to achieve the best results. To address the limitations of both approaches, in this work we introduce a method that leverages a signal processing-based denoiser that when combined with a neural network controller, enables fully automatic and high-fidelity noise reduction on both speech and music signals. We evaluate our proposed method with objective metrics and a perceptual listening test. Our evaluation reveals that speech enhancement models can be extended to music, however training the model to remove only stationary noise is critical. Furthermore, our proposed approach achieves performance on par with the deep learning models, while being significantly more efficient and introducing fewer artifacts in some cases. Listening examples are available online at https://tape.it/research/denoiser .
Waveformer for modelling dynamical systems
Oct 08, 2023Neural operators have gained recognition as potent tools for learning solutions of a family of partial differential equations. The state-of-the-art neural operators excel at approximating the functional relationship between input functions and the solution space, potentially reducing computational costs and enabling real-time applications. However, they often fall short when tackling time-dependent problems, particularly in delivering accurate long-term predictions. In this work, we propose "waveformer", a novel operator learning approach for learning solutions of dynamical systems. The proposed waveformer exploits wavelet transform to capture the spatial multi-scale behavior of the solution field and transformers for capturing the long horizon dynamics. We present four numerical examples involving Burgers's equation, KS-equation, Allen Cahn equation, and Navier Stokes equation to illustrate the efficacy of the proposed approach. Results obtained indicate the capability of the proposed waveformer in learning the solution operator and show that the proposed Waveformer can learn the solution operator with high accuracy, outperforming existing state-of-the-art operator learning algorithms by up to an order, with its advantage particularly visible in the extrapolation region
Distribution-Based Trajectory Clustering
Oct 08, 2023Trajectory clustering enables the discovery of common patterns in trajectory data. Current methods of trajectory clustering rely on a distance measure between two points in order to measure the dissimilarity between two trajectories. The distance measures employed have two challenges: high computational cost and low fidelity. Independent of the distance measure employed, existing clustering algorithms have another challenge: either effectiveness issues or high time complexity. In this paper, we propose to use a recent Isolation Distributional Kernel (IDK) as the main tool to meet all three challenges. The new IDK-based clustering algorithm, called TIDKC, makes full use of the distributional kernel for trajectory similarity measuring and clustering. TIDKC identifies non-linearly separable clusters with irregular shapes and varied densities in linear time. It does not rely on random initialisation and is robust to outliers. An extensive evaluation on 7 large real-world trajectory datasets confirms that IDK is more effective in capturing complex structures in trajectories than traditional and deep learning-based distance measures. Furthermore, the proposed TIDKC has superior clustering performance and efficiency to existing trajectory clustering algorithms.