 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAhaKV: Adaptive Holistic Attention-Driven KV Cache Eviction for Efficient Inference of Large Language Models
Jun 04, 2025



Large Language Models (LLMs) have significantly advanced the field of Artificial Intelligence. However, their deployment is resource-intensive, not only due to the large number of model parameters but also because the (Key-Value) KV cache consumes a lot of memory during inference. While several works propose reducing the KV cache by evicting the unnecessary tokens, these approaches rely on accumulated attention score as eviction score to quantify the importance of the token. We identify the accumulated attention score is biased and it decreases with the position of the tokens in the mathematical expectation. As a result, the retained tokens concentrate on the initial positions, limiting model's access to global contextual information. To address this issue, we propose Adaptive holistic attention KV (AhaKV), it addresses the bias of the accumulated attention score by adaptively tuning the scale of softmax according the expectation of information entropy of attention scores. To make use of the holistic attention information in self-attention mechanism, AhaKV utilize the information of value vectors, which is overlooked in previous works, to refine the adaptive score. We show theoretically that our method is well suited for bias reduction. We deployed AhaKV on different models with a fixed cache budget. Experiments show that AhaKV successfully mitigates bias and retains crucial tokens across global context and achieve state-of-the-art results against other related work on several benchmark tasks.
Understanding Attention Mechanism in Video Diffusion Models
Apr 16, 2025Text-to-video (T2V) synthesis models, such as OpenAI's Sora, have garnered significant attention due to their ability to generate high-quality videos from a text prompt. In diffusion-based T2V models, the attention mechanism is a critical component. However, it remains unclear what intermediate features are learned and how attention blocks in T2V models affect various aspects of video synthesis, such as image quality and temporal consistency. In this paper, we conduct an in-depth perturbation analysis of the spatial and temporal attention blocks of T2V models using an information-theoretic approach. Our results indicate that temporal and spatial attention maps affect not only the timing and layout of the videos but also the complexity of spatiotemporal elements and the aesthetic quality of the synthesized videos. Notably, high-entropy attention maps are often key elements linked to superior video quality, whereas low-entropy attention maps are associated with the video's intra-frame structure. Based on our findings, we propose two novel methods to enhance video quality and enable text-guided video editing. These methods rely entirely on lightweight manipulation of the attention matrices in T2V models. The efficacy and effectiveness of our methods are further validated through experimental evaluation across multiple datasets.
Shared Attention-based Autoencoder with Hierarchical Fusion-based Graph Convolution Network for sEEG SOZ Identification
Dec 17, 2024



Diagnosing seizure onset zone (SOZ) is a challenge in neurosurgery, where stereoelectroencephalography (sEEG) serves as a critical technique. In sEEG SOZ identification, the existing studies focus solely on the intra-patient representation of epileptic information, overlooking the general features of epilepsy across patients and feature interdependencies between feature elements in each contact site. In order to address the aforementioned challenges, we propose the shared attention-based autoencoder (sATAE). sATAE is trained by sEEG data across all patients, with attention blocks introduced to enhance the representation of interdependencies between feature elements. Considering the spatial diversity of sEEG across patients, we introduce graph-based method for identification SOZ of each patient. However, the current graph-based methods for sEEG SOZ identification rely exclusively on static graphs to model epileptic networks. Inspired by the finding of neuroscience that epileptic network is intricately characterized by the interplay of sophisticated equilibrium between fluctuating and stable states, we design the hierarchical fusion-based graph convolution network (HFGCN) to identify the SOZ. HFGCN integrates the dynamic and static characteristics of epileptic networks through hierarchical weighting across different hierarchies, facilitating a more comprehensive learning of epileptic features and enriching node information for sEEG SOZ identification. Combining sATAE and HFGCN, we perform comprehensive experiments with sATAE-HFGCN on the self-build sEEG dataset, which includes sEEG data from 17 patients with temporal lobe epilepsy. The results show that our method, sATAE-HFGCN, achieves superior performance for identifying the SOZ of each patient, effectively addressing the aforementioned challenges, providing an efficient solution for sEEG-based SOZ identification.
GUS-IR: Gaussian Splatting with Unified Shading for Inverse Rendering
Nov 12, 2024



Recovering the intrinsic physical attributes of a scene from images, generally termed as the inverse rendering problem, has been a central and challenging task in computer vision and computer graphics. In this paper, we present GUS-IR, a novel framework designed to address the inverse rendering problem for complicated scenes featuring rough and glossy surfaces. This paper starts by analyzing and comparing two prominent shading techniques popularly used for inverse rendering, forward shading and deferred shading, effectiveness in handling complex materials. More importantly, we propose a unified shading solution that combines the advantages of both techniques for better decomposition. In addition, we analyze the normal modeling in 3D Gaussian Splatting (3DGS) and utilize the shortest axis as normal for each particle in GUS-IR, along with a depth-related regularization, resulting in improved geometric representation and better shape reconstruction. Furthermore, we enhance the probe-based baking scheme proposed by GS-IR to achieve more accurate ambient occlusion modeling to better handle indirect illumination. Extensive experiments have demonstrated the superior performance of GUS-IR in achieving precise intrinsic decomposition and geometric representation, supporting many downstream tasks (such as relighting, retouching) in computer vision, graphics, and extended reality.
Boosting Cross-Domain Point Classification via Distilling Relational Priors from 2D Transformers
Jul 26, 2024



Semantic pattern of an object point cloud is determined by its topological configuration of local geometries. Learning discriminative representations can be challenging due to large shape variations of point sets in local regions and incomplete surface in a global perspective, which can be made even more severe in the context of unsupervised domain adaptation (UDA). In specific, traditional 3D networks mainly focus on local geometric details and ignore the topological structure between local geometries, which greatly limits their cross-domain generalization. Recently, the transformer-based models have achieved impressive performance gain in a range of image-based tasks, benefiting from its strong generalization capability and scalability stemming from capturing long range correlation across local patches. Inspired by such successes of visual transformers, we propose a novel Relational Priors Distillation (RPD) method to extract relational priors from the well-trained transformers on massive images, which can significantly empower cross-domain representations with consistent topological priors of objects. To this end, we establish a parameter-frozen pre-trained transformer module shared between 2D teacher and 3D student models, complemented by an online knowledge distillation strategy for semantically regularizing the 3D student model. Furthermore, we introduce a novel self-supervised task centered on reconstructing masked point cloud patches using corresponding masked multi-view image features, thereby empowering the model with incorporating 3D geometric information. Experiments on the PointDA-10 and the Sim-to-Real datasets verify that the proposed method consistently achieves the state-of-the-art performance of UDA for point cloud classification. The source code of this work is available at https://github.com/zou-longkun/RPD.git.
CorrTalk: Correlation Between Hierarchical Speech and Facial Activity Variances for 3D Animation
Oct 17, 2023



Speech-driven 3D facial animation is a challenging cross-modal task that has attracted growing research interest. During speaking activities, the mouth displays strong motions, while the other facial regions typically demonstrate comparatively weak activity levels. Existing approaches often simplify the process by directly mapping single-level speech features to the entire facial animation, which overlook the differences in facial activity intensity leading to overly smoothed facial movements. In this study, we propose a novel framework, CorrTalk, which effectively establishes the temporal correlation between hierarchical speech features and facial activities of different intensities across distinct regions. A novel facial activity intensity metric is defined to distinguish between strong and weak facial activity, obtained by computing the short-time Fourier transform of facial vertex displacements. Based on the variances in facial activity, we propose a dual-branch decoding framework to synchronously synthesize strong and weak facial activity, which guarantees wider intensity facial animation synthesis. Furthermore, a weighted hierarchical feature encoder is proposed to establish temporal correlation between hierarchical speech features and facial activity at different intensities, which ensures lip-sync and plausible facial expressions. Extensive qualitatively and quantitatively experiments as well as a user study indicate that our CorrTalk outperforms existing state-of-the-art methods. The source code and supplementary video are publicly available at: https://zjchu.github.io/projects/CorrTalk/
Dynamic Shuffle: An Efficient Channel Mixture Method
Oct 04, 2023



The redundancy of Convolutional neural networks not only depends on weights but also depends on inputs. Shuffling is an efficient operation for mixing channel information but the shuffle order is usually pre-defined. To reduce the data-dependent redundancy, we devise a dynamic shuffle module to generate data-dependent permutation matrices for shuffling. Since the dimension of permutation matrix is proportional to the square of the number of input channels, to make the generation process efficiently, we divide the channels into groups and generate two shared small permutation matrices for each group, and utilize Kronecker product and cross group shuffle to obtain the final permutation matrices. To make the generation process learnable, based on theoretical analysis, softmax, orthogonal regularization, and binarization are employed to asymptotically approximate the permutation matrix. Dynamic shuffle adaptively mixes channel information with negligible extra computation and memory occupancy. Experiment results on image classification benchmark datasets CIFAR-10, CIFAR-100, Tiny ImageNet and ImageNet have shown that our method significantly increases ShuffleNets' performance. Adding dynamic generated matrix with learnable static matrix, we further propose static-dynamic-shuffle and show that it can serve as a lightweight replacement of ordinary pointwise convolution.
LAPP: Layer Adaptive Progressive Pruning for Compressing CNNs from Scratch
Sep 25, 2023



Structured pruning is a commonly used convolutional neural network (CNN) compression approach. Pruning rate setting is a fundamental problem in structured pruning. Most existing works introduce too many additional learnable parameters to assign different pruning rates across different layers in CNN or cannot control the compression rate explicitly. Since too narrow network blocks information flow for training, automatic pruning rate setting cannot explore a high pruning rate for a specific layer. To overcome these limitations, we propose a novel framework named Layer Adaptive Progressive Pruning (LAPP), which gradually compresses the network during initial training of a few epochs from scratch. In particular, LAPP designs an effective and efficient pruning strategy that introduces a learnable threshold for each layer and FLOPs constraints for network. Guided by both task loss and FLOPs constraints, the learnable thresholds are dynamically and gradually updated to accommodate changes of importance scores during training. Therefore the pruning strategy can gradually prune the network and automatically determine the appropriate pruning rates for each layer. What's more, in order to maintain the expressive power of the pruned layer, before training starts, we introduce an additional lightweight bypass for each convolutional layer to be pruned, which only adds relatively few additional burdens. Our method demonstrates superior performance gains over previous compression methods on various datasets and backbone architectures. For example, on CIFAR-10, our method compresses ResNet-20 to 40.3% without accuracy drop. 55.6% of FLOPs of ResNet-18 are reduced with 0.21% top-1 accuracy increase and 0.40% top-5 accuracy increase on ImageNet.
Compact Model Training by Low-Rank Projection with Energy Transfer
Apr 12, 2022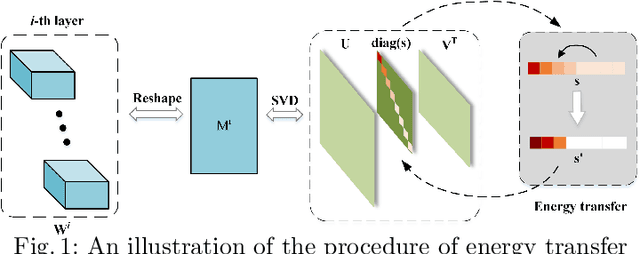
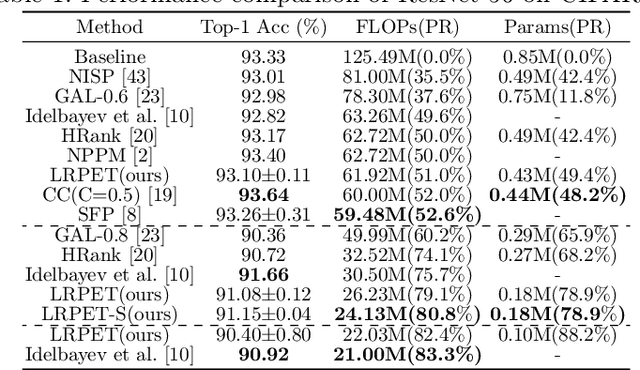
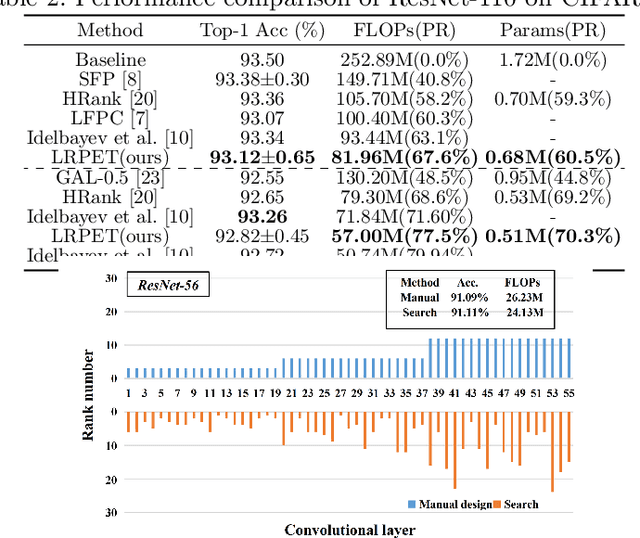
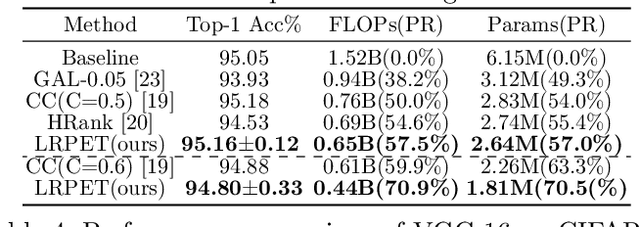
Low-rankness plays an important role in traditional machine learning, but is not so popular in deep learning. Most previous low-rank network compression methods compress the networks by approximating pre-trained models and re-training. However, optimal solution in the Euclidean space may be quite different from the one in the low-rank manifold. A well pre-trained model is not a good initialization for the model with low-rank constraint. Thus, the performance of low-rank compressed network degrades significantly. Compared to other network compression methods such as pruning, low-rank methods attracts less attention in recent years. In this paper, we devise a new training method, low-rank projection with energy transfer (LRPET), that trains low-rank compressed networks from scratch and achieves competitive performance. First, we propose to alternately perform stochastic gradient descent training and projection onto the low-rank manifold. This asymptotically approaches the optimal solution in the low-rank manifold. Compared to re-training on compact model, this enables fully utilization of model capacity since solution space is relaxed back to Euclidean space after projection. Second, the matrix energy (the sum of squares of singular values) reduction caused by projection is compensated by energy transfer. We uniformly transfer the energy of the pruned singular values to the remaining ones. We theoretically show that energy transfer eases the trend of gradient vanishing caused by projection. Comprehensive experiment on CIFAR-10 and ImageNet have justified that our method is superior to other low-rank compression methods and also outperforms recent state-of-the-art pruning methods.
Weight Evolution: Improving Deep Neural Networks Training through Evolving Inferior Weight Values
Oct 09, 2021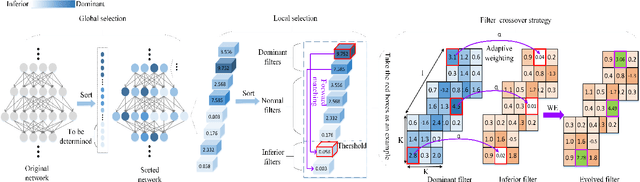
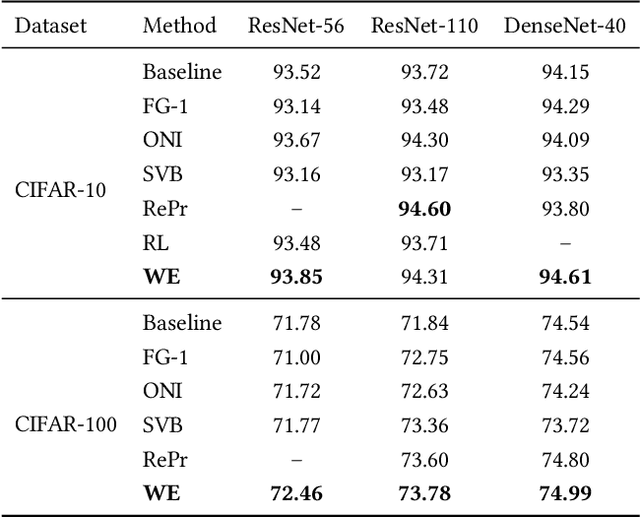
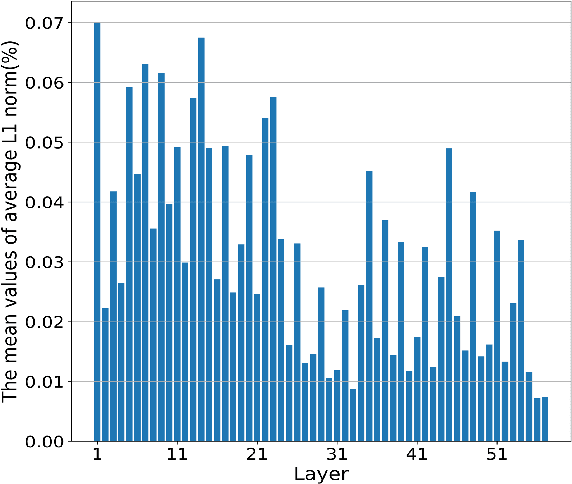
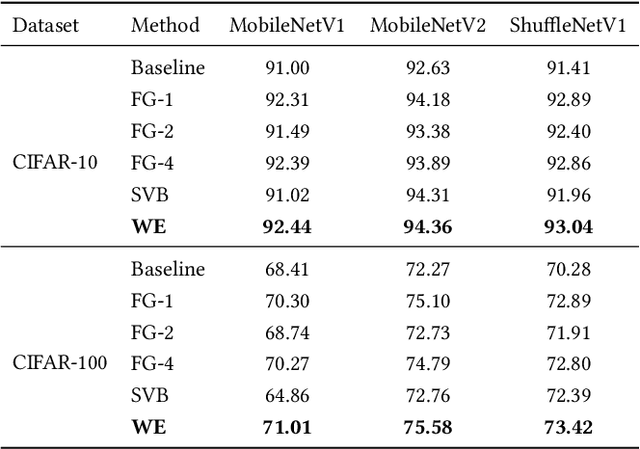
To obtain good performance, convolutional neural networks are usually over-parameterized. This phenomenon has stimulated two interesting topics: pruning the unimportant weights for compression and reactivating the unimportant weights to make full use of network capability. However, current weight reactivation methods usually reactivate the entire filters, which may not be precise enough. Looking back in history, the prosperity of filter pruning is mainly due to its friendliness to hardware implementation, but pruning at a finer structure level, i.e., weight elements, usually leads to better network performance. We study the problem of weight element reactivation in this paper. Motivated by evolution, we select the unimportant filters and update their unimportant elements by combining them with the important elements of important filters, just like gene crossover to produce better offspring, and the proposed method is called weight evolution (WE). WE is mainly composed of four strategies. We propose a global selection strategy and a local selection strategy and combine them to locate the unimportant filters. A forward matching strategy is proposed to find the matched important filters and a crossover strategy is proposed to utilize the important elements of the important filters for updating unimportant filters. WE is plug-in to existing network architectures. Comprehensive experiments show that WE outperforms the other reactivation methods and plug-in training methods with typical convolutional neural networks, especially lightweight networks. Our code is available at https://github.com/BZQLin/Weight-evolution.