 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Black-box and Gray-box Modeling of Nonlinear Audio Effects
Feb 20, 2025Audio effects are extensively used at every stage of audio and music content creation. The majority of differentiable audio effects modeling approaches fall into the black-box or gray-box paradigms; and most models have been proposed and applied to nonlinear effects like guitar amplifiers, overdrive, distortion, fuzz and compressor. Although a plethora of architectures have been introduced for the task at hand there is still lack of understanding on the state of the art, since most publications experiment with one type of nonlinear audio effect and a very small number of devices. In this work we aim to shed light on the audio effects modeling landscape by comparing black-box and gray-box architectures on a large number of nonlinear audio effects, identifying the most suitable for a wide range of devices. In the process, we also: introduce time-varying gray-box models and propose models for compressor, distortion and fuzz, publish a large dataset for audio effects research - ToneTwist AFx https://github.com/mcomunita/tonetwist-afx-dataset - that is also the first open to community contributions, evaluate models on a variety of metrics and conduct extensive subjective evaluation. Code https://github.com/mcomunita/nablafx and supplementary material https://github.com/mcomunita/nnlinafx-supp-material are also available.
ST-ITO: Controlling Audio Effects for Style Transfer with Inference-Time Optimization
Oct 28, 2024Audio production style transfer is the task of processing an input to impart stylistic elements from a reference recording. Existing approaches often train a neural network to estimate control parameters for a set of audio effects. However, these approaches are limited in that they can only control a fixed set of effects, where the effects must be differentiable or otherwise employ specialized training techniques. In this work, we introduce ST-ITO, Style Transfer with Inference-Time Optimization, an approach that instead searches the parameter space of an audio effect chain at inference. This method enables control of arbitrary audio effect chains, including unseen and non-differentiable effects. Our approach employs a learned metric of audio production style, which we train through a simple and scalable self-supervised pretraining strategy, along with a gradient-free optimizer. Due to the limited existing evaluation methods for audio production style transfer, we introduce a multi-part benchmark to evaluate audio production style metrics and style transfer systems. This evaluation demonstrates that our audio representation better captures attributes related to audio production and enables expressive style transfer via control of arbitrary audio effects.
Modeling Analog Dynamic Range Compressors using Deep Learning and State-space Models
Mar 24, 2024We describe a novel approach for developing realistic digital models of dynamic range compressors for digital audio production by analyzing their analog prototypes. While realistic digital dynamic compressors are potentially useful for many applications, the design process is challenging because the compressors operate nonlinearly over long time scales. Our approach is based on the structured state space sequence model (S4), as implementing the state-space model (SSM) has proven to be efficient at learning long-range dependencies and is promising for modeling dynamic range compressors. We present in this paper a deep learning model with S4 layers to model the Teletronix LA-2A analog dynamic range compressor. The model is causal, executes efficiently in real time, and achieves roughly the same quality as previous deep-learning models but with fewer parameters.
ATGNN: Audio Tagging Graph Neural Network
Nov 02, 2023



Deep learning models such as CNNs and Transformers have achieved impressive performance for end-to-end audio tagging. Recent works have shown that despite stacking multiple layers, the receptive field of CNNs remains severely limited. Transformers on the other hand are able to map global context through self-attention, but treat the spectrogram as a sequence of patches which is not flexible enough to capture irregular audio objects. In this work, we treat the spectrogram in a more flexible way by considering it as graph structure and process it with a novel graph neural architecture called ATGNN. ATGNN not only combines the capability of CNNs with the global information sharing ability of Graph Neural Networks, but also maps semantic relationships between learnable class embeddings and corresponding spectrogram regions. We evaluate ATGNN on two audio tagging tasks, where it achieves 0.585 mAP on the FSD50K dataset and 0.335 mAP on the AudioSet-balanced dataset, achieving comparable results to Transformer based models with significantly lower number of learnable parameters.
High-Fidelity Noise Reduction with Differentiable Signal Processing
Oct 17, 2023



Noise reduction techniques based on deep learning have demonstrated impressive performance in enhancing the overall quality of recorded speech. While these approaches are highly performant, their application in audio engineering can be limited due to a number of factors. These include operation only on speech without support for music, lack of real-time capability, lack of interpretable control parameters, operation at lower sample rates, and a tendency to introduce artifacts. On the other hand, signal processing-based noise reduction algorithms offer fine-grained control and operation on a broad range of content, however, they often require manual operation to achieve the best results. To address the limitations of both approaches, in this work we introduce a method that leverages a signal processing-based denoiser that when combined with a neural network controller, enables fully automatic and high-fidelity noise reduction on both speech and music signals. We evaluate our proposed method with objective metrics and a perceptual listening test. Our evaluation reveals that speech enhancement models can be extended to music, however training the model to remove only stationary noise is critical. Furthermore, our proposed approach achieves performance on par with the deep learning models, while being significantly more efficient and introducing fewer artifacts in some cases. Listening examples are available online at https://tape.it/research/denoiser .
General Purpose Audio Effect Removal
Aug 30, 2023



Although the design and application of audio effects is well understood, the inverse problem of removing these effects is significantly more challenging and far less studied. Recently, deep learning has been applied to audio effect removal; however, existing approaches have focused on narrow formulations considering only one effect or source type at a time. In realistic scenarios, multiple effects are applied with varying source content. This motivates a more general task, which we refer to as general purpose audio effect removal. We developed a dataset for this task using five audio effects across four different sources and used it to train and evaluate a set of existing architectures. We found that no single model performed optimally on all effect types and sources. To address this, we introduced RemFX, an approach designed to mirror the compositionality of applied effects. We first trained a set of the best-performing effect-specific removal models and then leveraged an audio effect classification model to dynamically construct a graph of our models at inference. We found our approach to outperform single model baselines, although examples with many effects present remain challenging.
Modulation Extraction for LFO-driven Audio Effects
May 22, 2023



Low frequency oscillator (LFO) driven audio effects such as phaser, flanger, and chorus, modify an input signal using time-varying filters and delays, resulting in characteristic sweeping or widening effects. It has been shown that these effects can be modeled using neural networks when conditioned with the ground truth LFO signal. However, in most cases, the LFO signal is not accessible and measurement from the audio signal is nontrivial, hindering the modeling process. To address this, we propose a framework capable of extracting arbitrary LFO signals from processed audio across multiple digital audio effects, parameter settings, and instrument configurations. Since our system imposes no restrictions on the LFO signal shape, we demonstrate its ability to extract quasiperiodic, combined, and distorted modulation signals that are relevant to effect modeling. Furthermore, we show how coupling the extraction model with a simple processing network enables training of end-to-end black-box models of unseen analog or digital LFO-driven audio effects using only dry and wet audio pairs, overcoming the need to access the audio effect or internal LFO signal. We make our code available and provide the trained audio effect models in a real-time VST plugin.
Leveraging Neural Representations for Audio Manipulation
Apr 10, 2023



We investigate applying audio manipulations using pretrained neural network-based autoencoders as an alternative to traditional signal processing methods, since the former may provide greater semantic or perceptual organization. To establish the potential of this approach, we first establish if representations from these models encode information about manipulations. We carry out experiments and produce visualizations using representations from two different pretrained autoencoders. Our findings indicate that, while some information about audio manipulations is encoded, this information is both limited and encoded in a non-trivial way. This is supported by our attempts to visualize these representations, which demonstrated that trajectories of representations for common manipulations are typically nonlinear and content dependent, even for linear signal manipulations. As a result, it is not yet clear how these pretrained autoencoders can be used to manipulate audio signals, however, our results indicate this may be due to the lack of disentanglement with respect to common audio manipulations.
Modelling black-box audio effects with time-varying feature modulation
Nov 01, 2022



Deep learning approaches for black-box modelling of audio effects have shown promise, however, the majority of existing work focuses on nonlinear effects with behaviour on relatively short time-scales, such as guitar amplifiers and distortion. While recurrent and convolutional architectures can theoretically be extended to capture behaviour at longer time scales, we show that simply scaling the width, depth, or dilation factor of existing architectures does not result in satisfactory performance when modelling audio effects such as fuzz and dynamic range compression. To address this, we propose the integration of time-varying feature-wise linear modulation into existing temporal convolutional backbones, an approach that enables learnable adaptation of the intermediate activations. We demonstrate that our approach more accurately captures long-range dependencies for a range of fuzz and compressor implementations across both time and frequency domain metrics. We provide sound examples, source code, and pretrained models to faciliate reproducibility.
Style Transfer of Audio Effects with Differentiable Signal Processing
Jul 18, 2022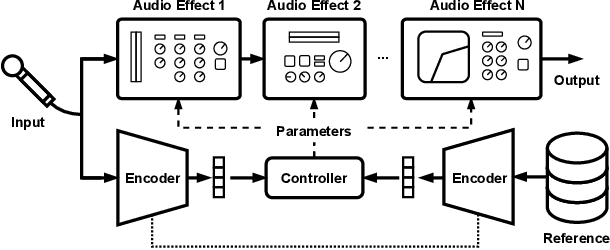
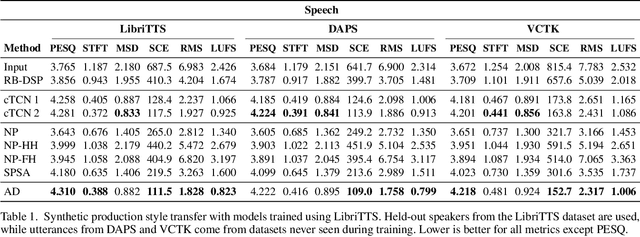
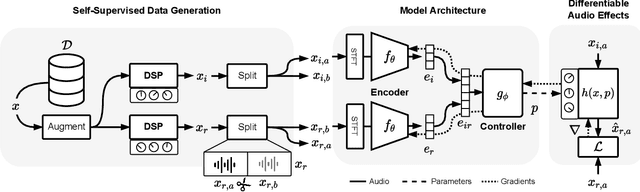
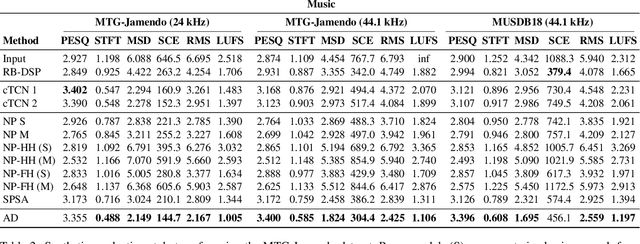
We present a framework that can impose the audio effects and production style from one recording to another by example with the goal of simplifying the audio production process. We train a deep neural network to analyze an input recording and a style reference recording, and predict the control parameters of audio effects used to render the output. In contrast to past work, we integrate audio effects as differentiable operators in our framework, perform backpropagation through audio effects, and optimize end-to-end using an audio-domain loss. We use a self-supervised training strategy enabling automatic control of audio effects without the use of any labeled or paired training data. We survey a range of existing and new approaches for differentiable signal processing, showing how each can be integrated into our framework while discussing their trade-offs. We evaluate our approach on both speech and music tasks, demonstrating that our approach generalizes both to unseen recordings and even to sample rates different than those seen during training. Our approach produces convincing production style transfer results with the ability to transform input recordings to produced recordings, yielding audio effect control parameters that enable interpretability and user interaction.