 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text": models, code, and papers
Spelling convention sensitivity in neural language models
Mar 06, 2023
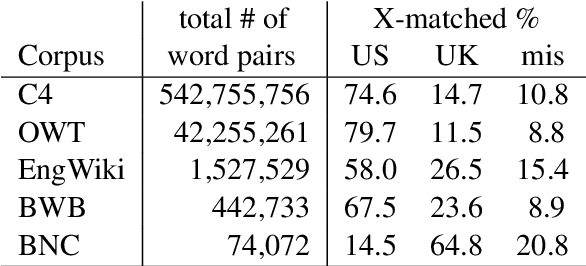
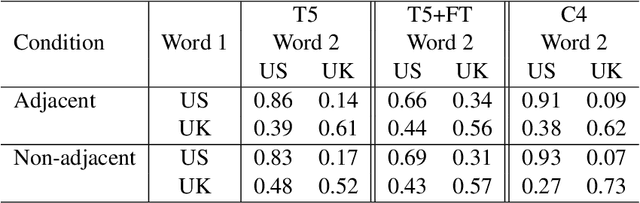
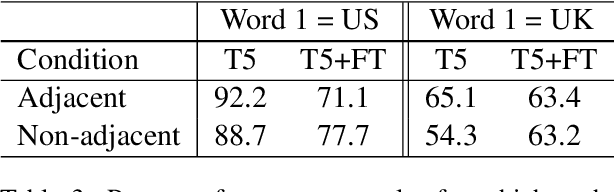
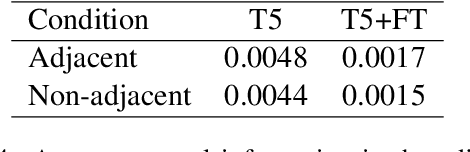
We examine whether large neural language models, trained on very large collections of varied English text, learn the potentially long-distance dependency of British versus American spelling conventions, i.e., whether spelling is consistently one or the other within model-generated strings. In contrast to long-distance dependencies in non-surface underlying structure (e.g., syntax), spelling consistency is easier to measure both in LMs and the text corpora used to train them, which can provide additional insight into certain observed model behaviors. Using a set of probe words unique to either British or American English, we first establish that training corpora exhibit substantial (though not total) consistency. A large T5 language model does appear to internalize this consistency, though only with respect to observed lexical items (not nonce words with British/American spelling patterns). We further experiment with correcting for biases in the training data by fine-tuning T5 on synthetic data that has been debiased, and find that finetuned T5 remains only somewhat sensitive to spelling consistency. Further experiments show GPT2 to be similarly limited.
ASDF: A Differential Testing Framework for Automatic Speech Recognition Systems
Feb 11, 2023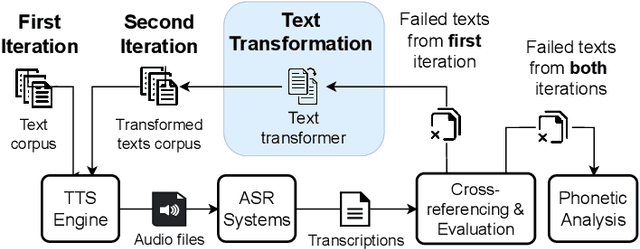
Recent years have witnessed wider adoption of Automated Speech Recognition (ASR) techniques in various domains. Consequently, evaluating and enhancing the quality of ASR systems is of great importance. This paper proposes ASDF, an Automated Speech Recognition Differential Testing Framework for testing ASR systems. ASDF extends an existing ASR testing tool, the CrossASR++, which synthesizes test cases from a text corpus. However, CrossASR++ fails to make use of the text corpus efficiently and provides limited information on how the failed test cases can improve ASR systems. To address these limitations, our tool incorporates two novel features: (1) a text transformation module to boost the number of generated test cases and uncover more errors in ASR systems and (2) a phonetic analysis module to identify on which phonemes the ASR system tend to produce errors. ASDF generates more high-quality test cases by applying various text transformation methods (e.g., change tense) to the texts in failed test cases. By doing so, ASDF can utilize a small text corpus to generate a large number of audio test cases, something which CrossASR++ is not capable of. In addition, ASDF implements more metrics to evaluate the performance of ASR systems from multiple perspectives. ASDF performs phonetic analysis on the identified failed test cases to identify the phonemes that ASR systems tend to transcribe incorrectly, providing useful information for developers to improve ASR systems. The demonstration video of our tool is made online at https://www.youtube.com/watch?v=DzVwfc3h9As. The implementation is available at https://github.com/danielyuenhx/asdf-differential-testing.
Enhancing Large Language Models with Climate Resources
Mar 31, 2023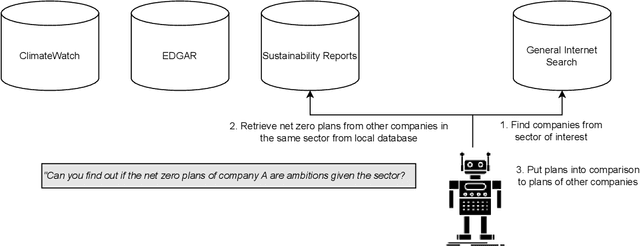
Large language models (LLMs) have significantly transformed the landscape of artificial intelligence by demonstrating their ability in generating human-like text across diverse topics. However, despite their impressive capabilities, LLMs lack recent information and often employ imprecise language, which can be detrimental in domains where accuracy is crucial, such as climate change. In this study, we make use of recent ideas to harness the potential of LLMs by viewing them as agents that access multiple sources, including databases containing recent and precise information about organizations, institutions, and companies. We demonstrate the effectiveness of our method through a prototype agent that retrieves emission data from ClimateWatch (https://www.climatewatchdata.org/) and leverages general Google search. By integrating these resources with LLMs, our approach overcomes the limitations associated with imprecise language and delivers more reliable and accurate information in the critical domain of climate change. This work paves the way for future advancements in LLMs and their application in domains where precision is of paramount importance.
ArguGPT: evaluating, understanding and identifying argumentative essays generated by GPT models
Apr 16, 2023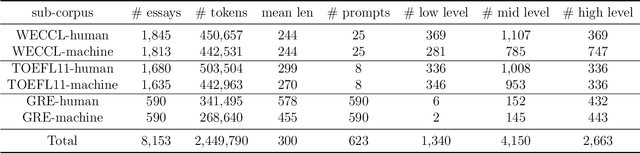
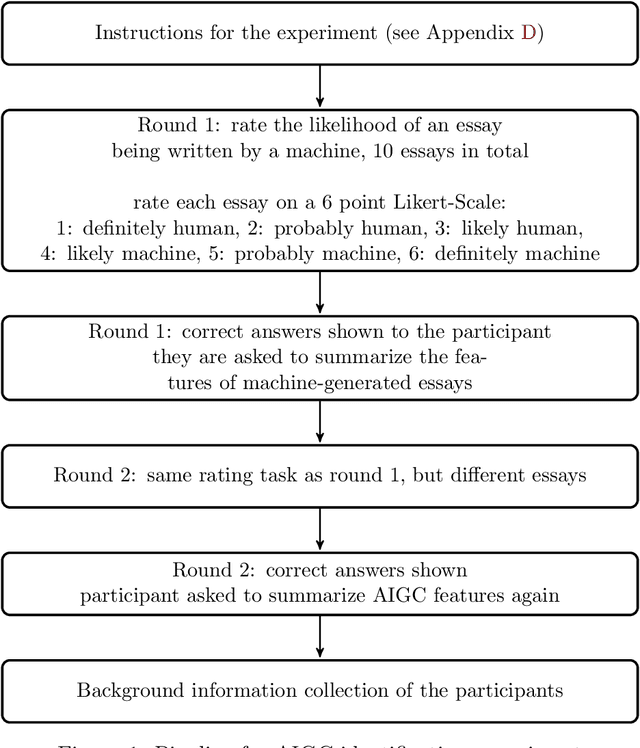

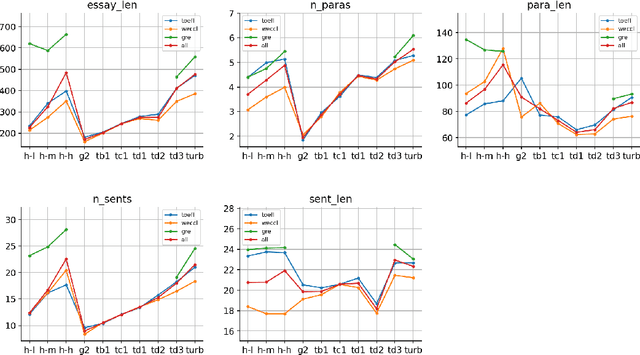
AI generated content (AIGC) presents considerable challenge to educators around the world. Instructors need to be able to detect such text generated by large language models, either with the naked eye or with the help of some tools. There is also growing need to understand the lexical, syntactic and stylistic features of AIGC. To address these challenges in English language teaching, we first present ArguGPT, a balanced corpus of 4,038 argumentative essays generated by 7 GPT models in response to essay prompts from three sources: (1) in-class or homework exercises, (2) TOEFL and (3) GRE writing tasks. Machine-generated texts are paired with roughly equal number of human-written essays with three score levels matched in essay prompts. We then hire English instructors to distinguish machine essays from human ones. Results show that when first exposed to machine-generated essays, the instructors only have an accuracy of 61% in detecting them. But the number rises to 67% after one round of minimal self-training. Next, we perform linguistic analyses of these essays, which show that machines produce sentences with more complex syntactic structures while human essays tend to be lexically more complex. Finally, we test existing AIGC detectors and build our own detectors using SVMs and RoBERTa. Results suggest that a RoBERTa fine-tuned with the training set of ArguGPT achieves above 90% accuracy in both essay- and sentence-level classification. To the best of our knowledge, this is the first comprehensive analysis of argumentative essays produced by generative large language models. Machine-authored essays in ArguGPT and our models will be made publicly available at https://github.com/huhailinguist/ArguGPT
A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers
Apr 16, 2023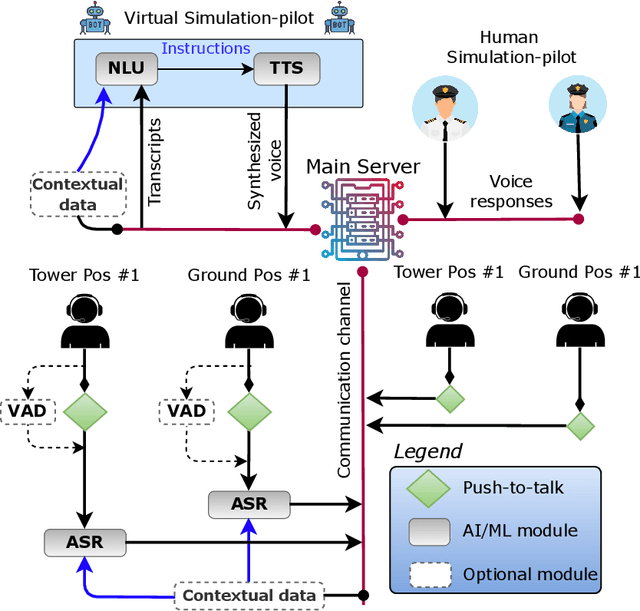
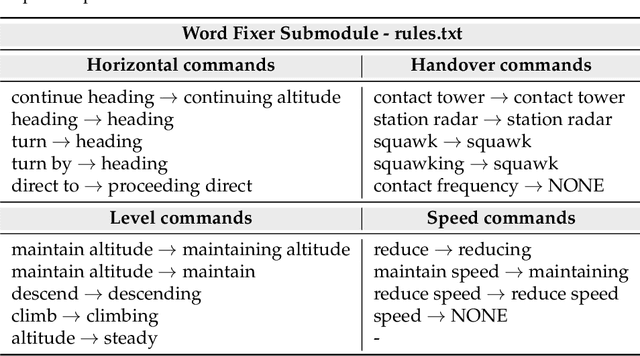
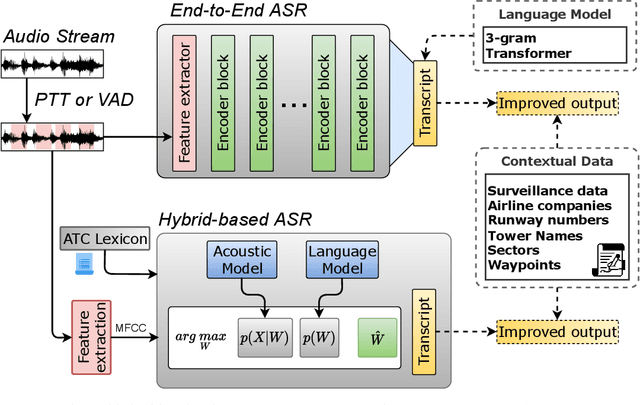
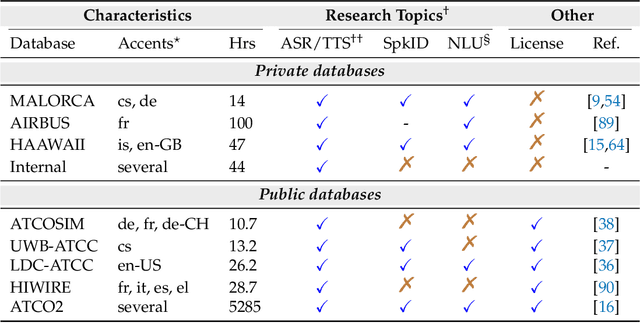
In this paper we propose a novel virtual simulation-pilot engine for speeding up air traffic controller (ATCo) training by integrating different state-of-the-art artificial intelligence (AI) based tools. The virtual simulation-pilot engine receives spoken communications from ATCo trainees, and it performs automatic speech recognition and understanding. Thus, it goes beyond only transcribing the communication and can also understand its meaning. The output is subsequently sent to a response generator system, which resembles the spoken read back that pilots give to the ATCo trainees. The overall pipeline is composed of the following submodules: (i) automatic speech recognition (ASR) system that transforms audio into a sequence of words; (ii) high-level air traffic control (ATC) related entity parser that understands the transcribed voice communication; and (iii) a text-to-speech submodule that generates a spoken utterance that resembles a pilot based on the situation of the dialogue. Our system employs state-of-the-art AI-based tools such as Wav2Vec 2.0, Conformer, BERT and Tacotron models. To the best of our knowledge, this is the first work fully based on open-source ATC resources and AI tools. In addition, we have developed a robust and modular system with optional submodules that can enhance the system's performance by incorporating real-time surveillance data, metadata related to exercises (such as sectors or runways), or even introducing a deliberate read-back error to train ATCo trainees to identify them. Our ASR system can reach as low as 5.5% and 15.9% word error rates (WER) on high and low-quality ATC audio. We also demonstrate that adding surveillance data into the ASR can yield callsign detection accuracy of more than 96%.
INFINITY: A Simple Yet Effective Unsupervised Framework for Graph-Text Mutual Conversion
Sep 22, 2022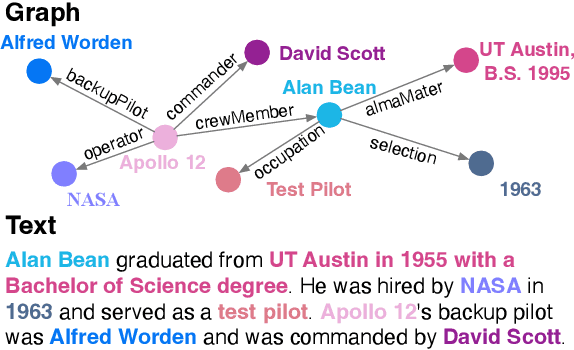

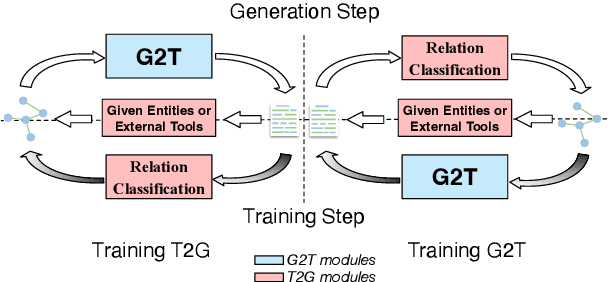
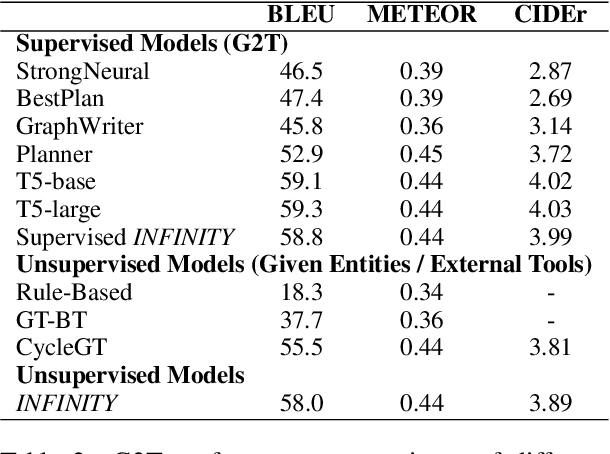
Graph-to-text (G2T) generation and text-to-graph (T2G) triple extraction are two essential tasks for constructing and applying knowledge graphs. Existing unsupervised approaches turn out to be suitable candidates for jointly learning the two tasks due to their avoidance of using graph-text parallel data. However, they are composed of multiple modules and still require both entity information and relation type in the training process. To this end, we propose INFINITY, a simple yet effective unsupervised approach that does not require external annotation tools or additional parallel information. It achieves fully unsupervised graph-text mutual conversion for the first time. Specifically, INFINITY treats both G2T and T2G as a bidirectional sequence generation task by fine-tuning only one pretrained seq2seq model. A novel back-translation-based framework is then designed to automatically generate continuous synthetic parallel data. To obtain reasonable graph sequences with structural information from source texts, INFINITY employs reward-based training loss by leveraging the advantage of reward augmented maximum likelihood. As a fully unsupervised framework, INFINITY is empirically verified to outperform state-of-the-art baselines for G2T and T2G tasks.
Global Knowledge Calibration for Fast Open-Vocabulary Segmentation
Mar 16, 2023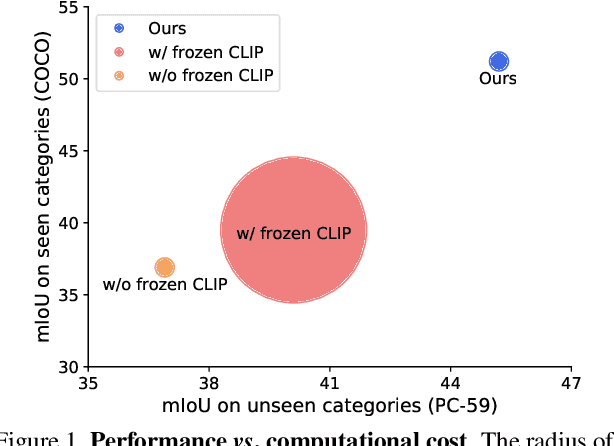
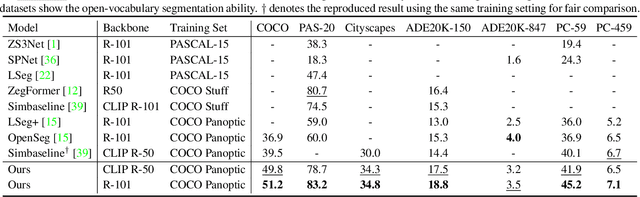
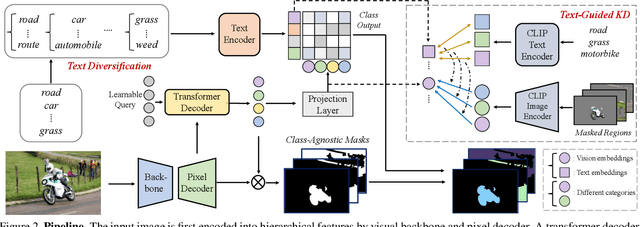

Recent advancements in pre-trained vision-language models, such as CLIP, have enabled the segmentation of arbitrary concepts solely from textual inputs, a process commonly referred to as open-vocabulary semantic segmentation (OVS). However, existing OVS techniques confront a fundamental challenge: the trained classifier tends to overfit on the base classes observed during training, resulting in suboptimal generalization performance to unseen classes. To mitigate this issue, recent studies have proposed the use of an additional frozen pre-trained CLIP for classification. Nonetheless, this approach incurs heavy computational overheads as the CLIP vision encoder must be repeatedly forward-passed for each mask, rendering it impractical for real-world applications. To address this challenge, our objective is to develop a fast OVS model that can perform comparably or better without the extra computational burden of the CLIP image encoder during inference. To this end, we propose a core idea of preserving the generalizable representation when fine-tuning on known classes. Specifically, we introduce a text diversification strategy that generates a set of synonyms for each training category, which prevents the learned representation from collapsing onto specific known category names. Additionally, we employ a text-guided knowledge distillation method to preserve the generalizable knowledge of CLIP. Extensive experiments demonstrate that our proposed model achieves robust generalization performance across various datasets. Furthermore, we perform a preliminary exploration of open-vocabulary video segmentation and present a benchmark that can facilitate future open-vocabulary research in the video domain.
DisCup: Discriminator Cooperative Unlikelihood Prompt-tuning for Controllable Text Generation
Oct 18, 2022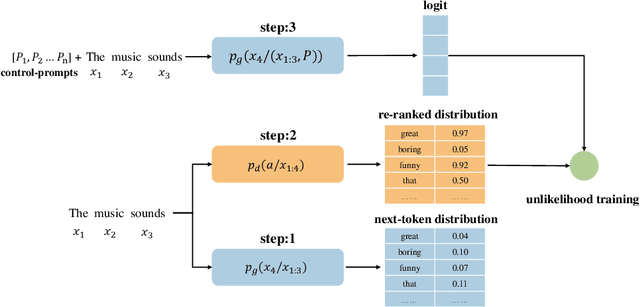
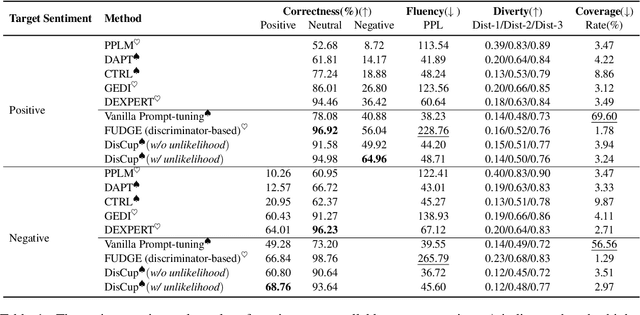

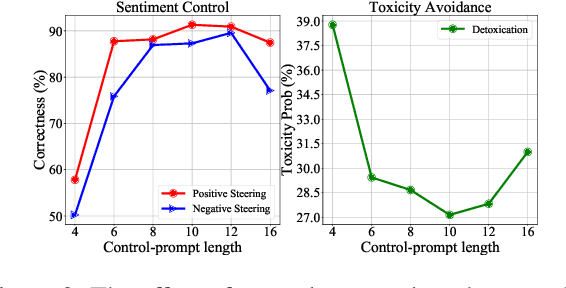
Prompt learning with immensely large Casual Language Models (CLMs) has been shown promising for attribute-controllable text generation (CTG). However, vanilla prompt tuning tends to imitate training corpus characteristics beyond the control attributes, resulting in a poor generalization ability. Moreover, it is less able to capture the relationship between different attributes, further limiting the control performance. In this paper, we propose a new CTG approach, namely DisCup, which incorporates the attribute knowledge of discriminator to optimize the control-prompts, steering a frozen CLM to produce attribute-specific texts. Specifically, the frozen CLM model, capable of producing multitudinous texts, is first used to generate the next-token candidates based on the context, so as to ensure the diversity of tokens to be predicted. Then, we leverage an attribute-discriminator to select desired/undesired tokens from those candidates, providing the inter-attribute knowledge. Finally, we bridge the above two traits by an unlikelihood objective for prompt-tuning. Extensive experimental results show that DisCup can achieve a new state-of-the-art control performance while maintaining an efficient and high-quality text generation, only relying on around 10 virtual tokens.
Nature Language Reasoning, A Survey
Mar 26, 2023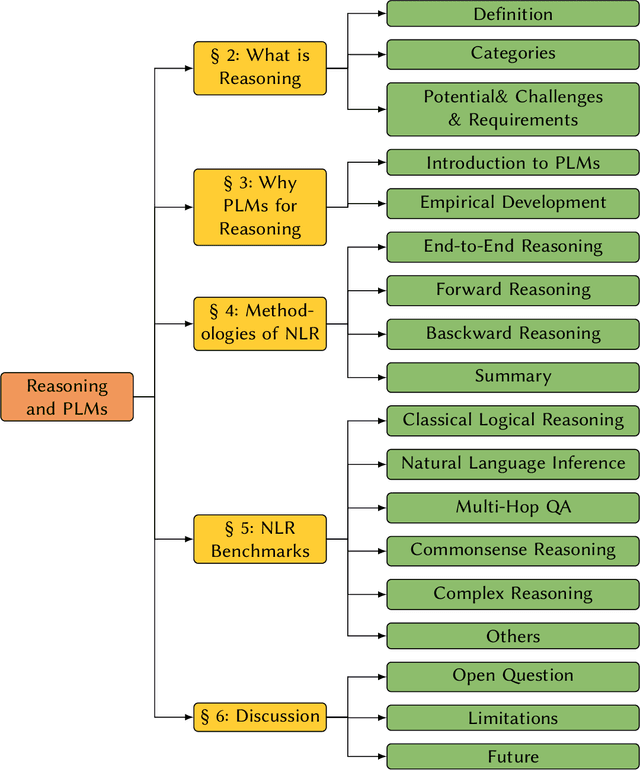



This survey paper proposes a clearer view of natural language reasoning in the field of Natural Language Processing (NLP), both conceptually and practically. Conceptually, we provide a distinct definition for natural language reasoning in NLP, based on both philosophy and NLP scenarios, discuss what types of tasks require reasoning, and introduce a taxonomy of reasoning. Practically, we conduct a comprehensive literature review on natural language reasoning in NLP, mainly covering classical logical reasoning, natural language inference, multi-hop question answering, and commonsense reasoning. The paper also identifies and views backward reasoning, a powerful paradigm for multi-step reasoning, and introduces defeasible reasoning as one of the most important future directions in natural language reasoning research. We focus on single-modality unstructured natural language text, excluding neuro-symbolic techniques and mathematical reasoning.
A Semantic Approach to Negation Detection and Word Disambiguation with Natural Language Processing
Feb 08, 2023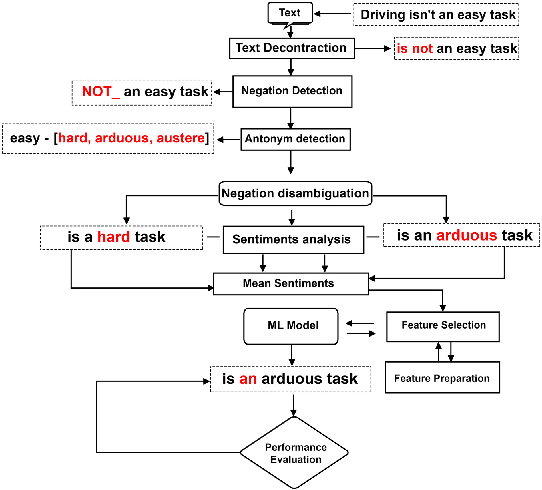
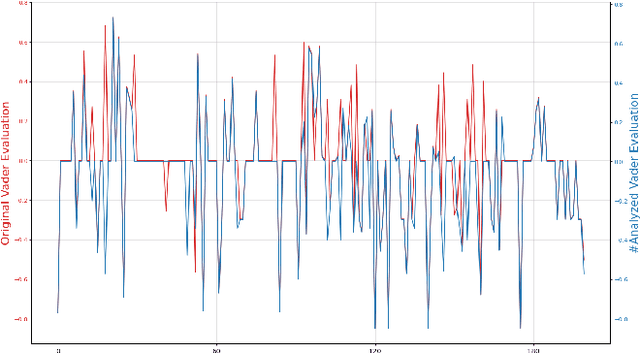
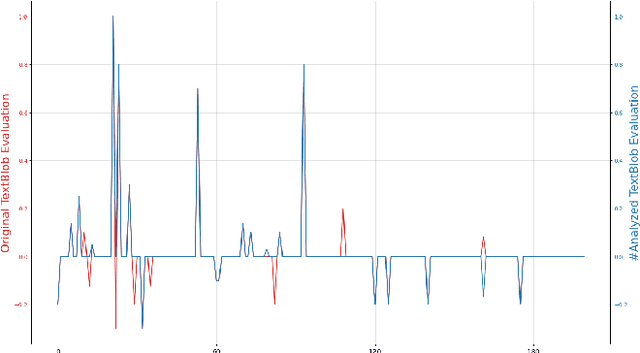
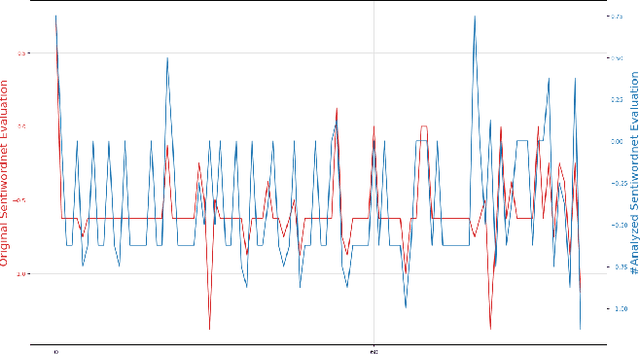
This study aims to demonstrate the methods for detecting negations in a sentence by uniquely evaluating the lexical structure of the text via word sense disambiguation. Additionally, the proposed method examined all the unique features of the related expressions within a text to resolve the contextual usage of the sentence and the effect of negation on sentiment analysis. The application of popular expression detectors skips this important step, thereby neglecting the root words caught in the web of negation, and making text classification difficult for machine learning and sentiment analysis. This study adopts the Natural Language Processing (NLP) approach to discover and antonimize words that were negated for better accuracy in text classification. This method acts as a lens that reads through a given word sequence using a knowledge base provided by an NLP library called WordHoard in order to detect negation signals. Early results show that our initial analysis improved traditional sentiment analysis that sometimes neglects word negations or assigns an inverse polarity score. The SentiWordNet analyzer was improved by 35%, the Vader analyzer by 20% and the TextBlob analyzer by 6%.