 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
nlpBDpatriots at BLP-2023 Task 1: A Two-Step Classification for Violence Inciting Text Detection in Bangla
Nov 25, 2023
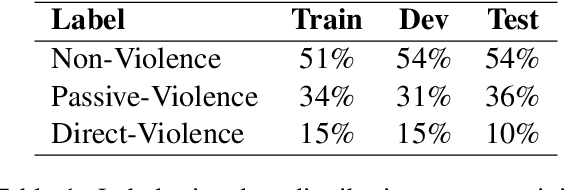
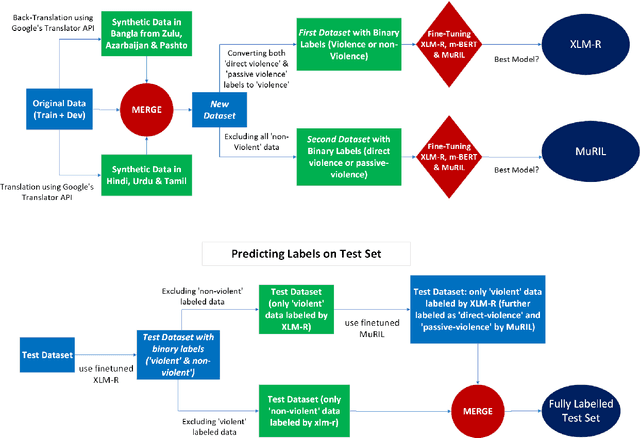
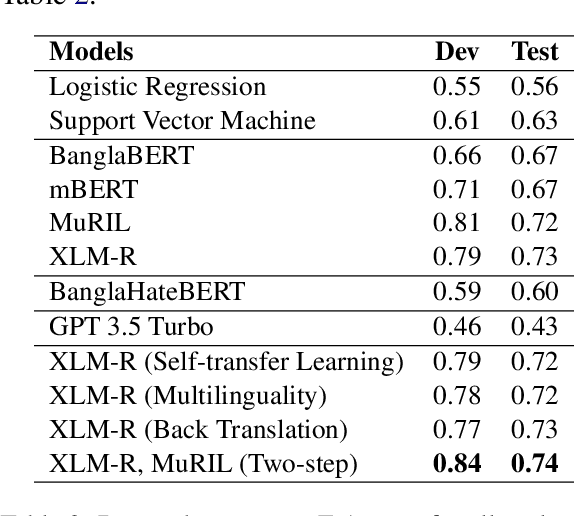
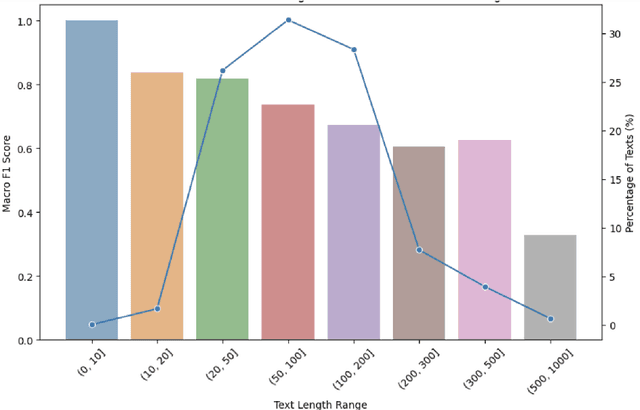
In this paper, we discuss the nlpBDpatriots entry to the shared task on Violence Inciting Text Detection (VITD) organized as part of the first workshop on Bangla Language Processing (BLP) co-located with EMNLP. The aim of this task is to identify and classify the violent threats, that provoke further unlawful violent acts. Our best-performing approach for the task is two-step classification using back translation and multilinguality which ranked 6th out of 27 teams with a macro F1 score of 0.74.
ChatGraph: Interpretable Text Classification by Converting ChatGPT Knowledge to Graphs
May 03, 2023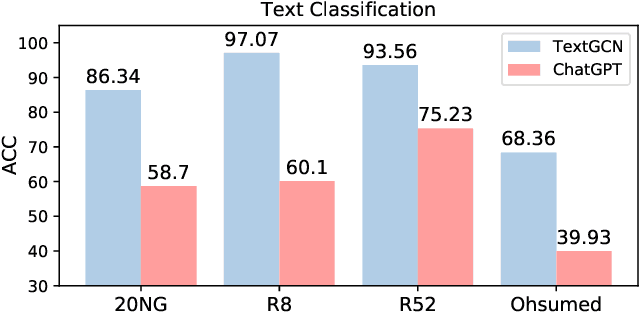
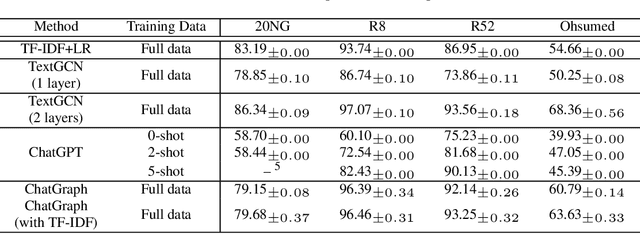
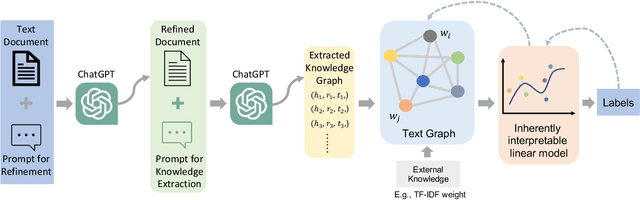

ChatGPT, as a recently launched large language model (LLM), has shown superior performance in various natural language processing (NLP) tasks. However, two major limitations hinder its potential applications: (1) the inflexibility of finetuning on downstream tasks and (2) the lack of interpretability in the decision-making process. To tackle these limitations, we propose a novel framework that leverages the power of ChatGPT for specific tasks, such as text classification, while improving its interpretability. The proposed framework conducts a knowledge graph extraction task to extract refined and structural knowledge from the raw data using ChatGPT. The rich knowledge is then converted into a graph, which is further used to train an interpretable linear classifier to make predictions. To evaluate the effectiveness of our proposed method, we conduct experiments on four datasets. The result shows that our method can significantly improve the performance compared to directly utilizing ChatGPT for text classification tasks. And our method provides a more transparent decision-making process compared with previous text classification methods.
WC-SBERT: Zero-Shot Text Classification via SBERT with Self-Training for Wikipedia Categories
Jul 28, 2023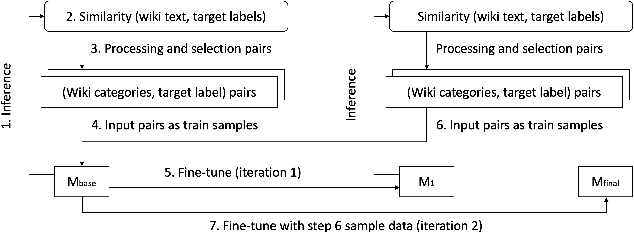

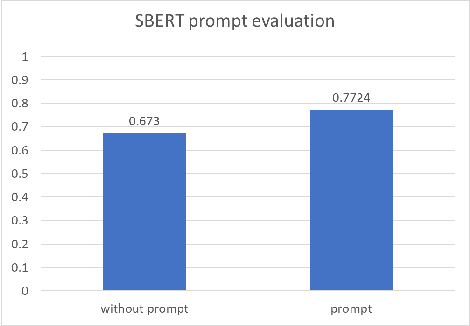
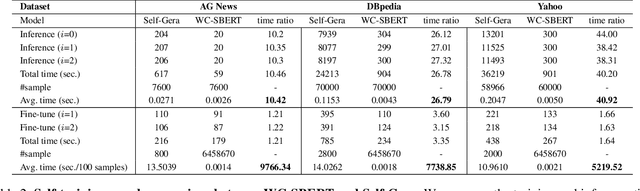
Our research focuses on solving the zero-shot text classification problem in NLP, with a particular emphasis on innovative self-training strategies. To achieve this objective, we propose a novel self-training strategy that uses labels rather than text for training, significantly reducing the model's training time. Specifically, we use categories from Wikipedia as our training set and leverage the SBERT pre-trained model to establish positive correlations between pairs of categories within the same text, facilitating associative training. For new test datasets, we have improved the original self-training approach, eliminating the need for prior training and testing data from each target dataset. Instead, we adopt Wikipedia as a unified training dataset to better approximate the zero-shot scenario. This modification allows for rapid fine-tuning and inference across different datasets, greatly reducing the time required for self-training. Our experimental results demonstrate that this method can adapt the model to the target dataset within minutes. Compared to other BERT-based transformer models, our approach significantly reduces the amount of training data by training only on labels, not the actual text, and greatly improves training efficiency by utilizing a unified training set. Additionally, our method achieves state-of-the-art results on both the Yahoo Topic and AG News datasets.
Making Scalable Meta Learning Practical
Oct 23, 2023Despite its flexibility to learn diverse inductive biases in machine learning programs, meta learning (i.e., learning to learn) has long been recognized to suffer from poor scalability due to its tremendous compute/memory costs, training instability, and a lack of efficient distributed training support. In this work, we focus on making scalable meta learning practical by introducing SAMA, which combines advances in both implicit differentiation algorithms and systems. Specifically, SAMA is designed to flexibly support a broad range of adaptive optimizers in the base level of meta learning programs, while reducing computational burden by avoiding explicit computation of second-order gradient information, and exploiting efficient distributed training techniques implemented for first-order gradients. Evaluated on multiple large-scale meta learning benchmarks, SAMA showcases up to 1.7/4.8x increase in throughput and 2.0/3.8x decrease in memory consumption respectively on single-/multi-GPU setups compared to other baseline meta learning algorithms. Furthermore, we show that SAMA-based data optimization leads to consistent improvements in text classification accuracy with BERT and RoBERTa large language models, and achieves state-of-the-art results in both small- and large-scale data pruning on image classification tasks, demonstrating the practical applicability of scalable meta learning across language and vision domains.
Statistical Depth for Ranking and Characterizing Transformer-Based Text Embeddings
Oct 23, 2023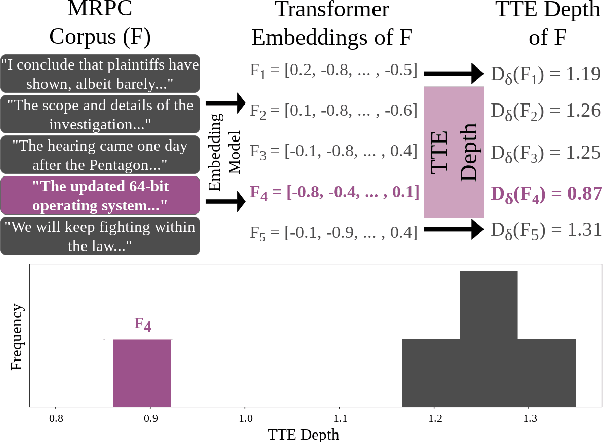
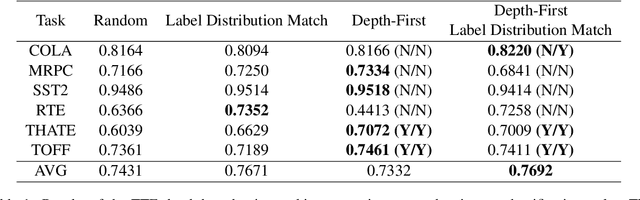
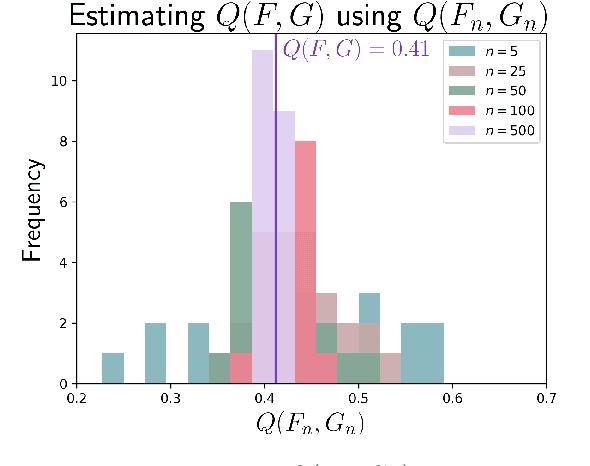
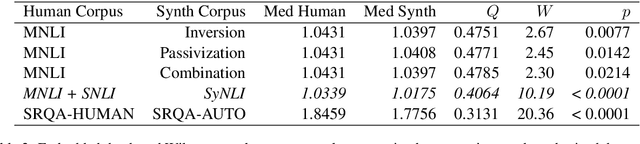
The popularity of transformer-based text embeddings calls for better statistical tools for measuring distributions of such embeddings. One such tool would be a method for ranking texts within a corpus by centrality, i.e. assigning each text a number signifying how representative that text is of the corpus as a whole. However, an intrinsic center-outward ordering of high-dimensional text representations is not trivial. A statistical depth is a function for ranking k-dimensional objects by measuring centrality with respect to some observed k-dimensional distribution. We adopt a statistical depth to measure distributions of transformer-based text embeddings, transformer-based text embedding (TTE) depth, and introduce the practical use of this depth for both modeling and distributional inference in NLP pipelines. We first define TTE depth and an associated rank sum test for determining whether two corpora differ significantly in embedding space. We then use TTE depth for the task of in-context learning prompt selection, showing that this approach reliably improves performance over statistical baseline approaches across six text classification tasks. Finally, we use TTE depth and the associated rank sum test to characterize the distributions of synthesized and human-generated corpora, showing that five recent synthetic data augmentation processes cause a measurable distributional shift away from associated human-generated text.
Transformer-based Entity Legal Form Classification
Oct 19, 2023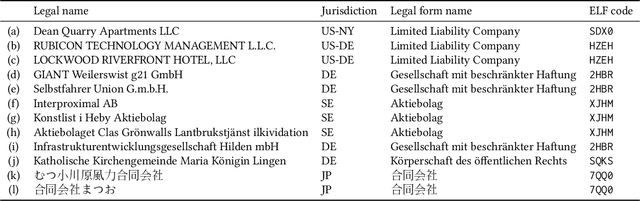
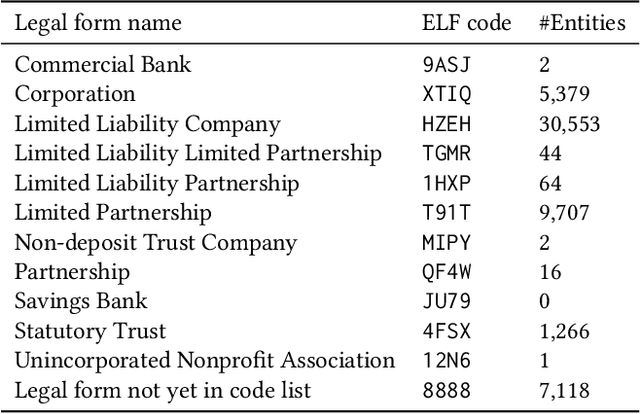
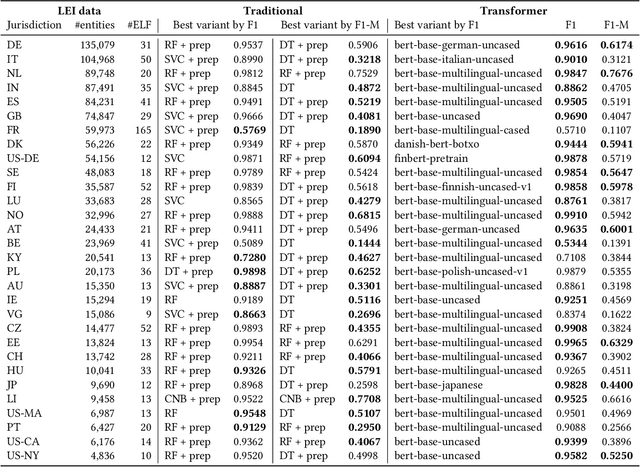
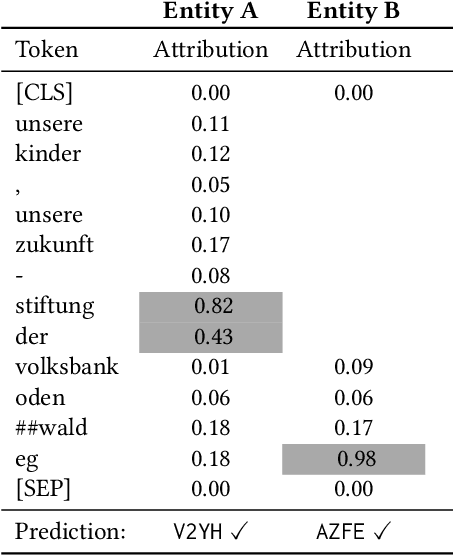
We propose the application of Transformer-based language models for classifying entity legal forms from raw legal entity names. Specifically, we employ various BERT variants and compare their performance against multiple traditional baselines. Our evaluation encompasses a substantial subset of freely available Legal Entity Identifier (LEI) data, comprising over 1.1 million legal entities from 30 different legal jurisdictions. The ground truth labels for classification per jurisdiction are taken from the Entity Legal Form (ELF) code standard (ISO 20275). Our findings demonstrate that pre-trained BERT variants outperform traditional text classification approaches in terms of F1 score, while also performing comparably well in the Macro F1 Score. Moreover, the validity of our proposal is supported by the outcome of third-party expert reviews conducted in ten selected jurisdictions. This study highlights the significant potential of Transformer-based models in advancing data standardization and data integration. The presented approaches can greatly benefit financial institutions, corporations, governments and other organizations in assessing business relationships, understanding risk exposure, and promoting effective governance.
MUSER: A Multi-View Similar Case Retrieval Dataset
Oct 24, 2023
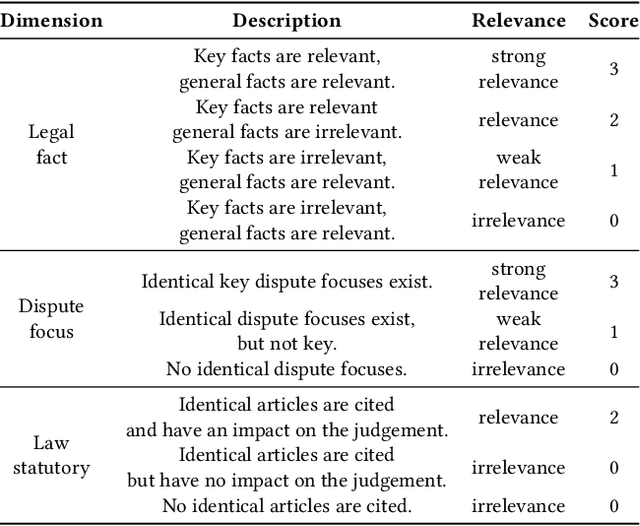

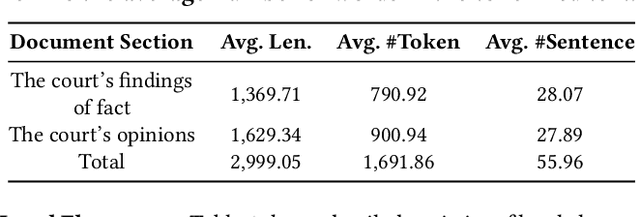
Similar case retrieval (SCR) is a representative legal AI application that plays a pivotal role in promoting judicial fairness. However, existing SCR datasets only focus on the fact description section when judging the similarity between cases, ignoring other valuable sections (e.g., the court's opinion) that can provide insightful reasoning process behind. Furthermore, the case similarities are typically measured solely by the textual semantics of the fact descriptions, which may fail to capture the full complexity of legal cases from the perspective of legal knowledge. In this work, we present MUSER, a similar case retrieval dataset based on multi-view similarity measurement and comprehensive legal element with sentence-level legal element annotations. Specifically, we select three perspectives (legal fact, dispute focus, and law statutory) and build a comprehensive and structured label schema of legal elements for each of them, to enable accurate and knowledgeable evaluation of case similarities. The constructed dataset originates from Chinese civil cases and contains 100 query cases and 4,024 candidate cases. We implement several text classification algorithms for legal element prediction and various retrieval methods for retrieving similar cases on MUSER. The experimental results indicate that incorporating legal elements can benefit the performance of SCR models, but further efforts are still required to address the remaining challenges posed by MUSER. The source code and dataset are released at https://github.com/THUlawtech/MUSER.
* Accepted by CIKM 2023 Resource Track
Linear Classifier: An Often-Forgotten Baseline for Text Classification
Jun 12, 2023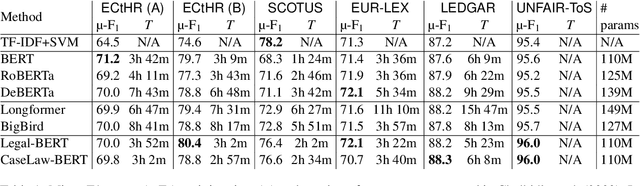
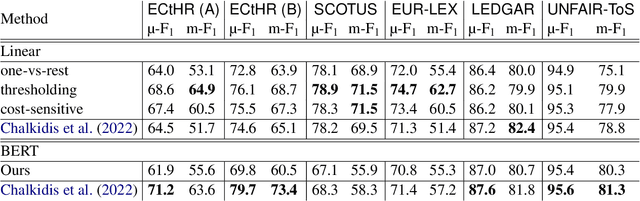
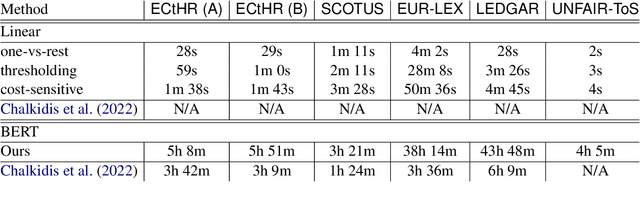

Large-scale pre-trained language models such as BERT are popular solutions for text classification. Due to the superior performance of these advanced methods, nowadays, people often directly train them for a few epochs and deploy the obtained model. In this opinion paper, we point out that this way may only sometimes get satisfactory results. We argue the importance of running a simple baseline like linear classifiers on bag-of-words features along with advanced methods. First, for many text data, linear methods show competitive performance, high efficiency, and robustness. Second, advanced models such as BERT may only achieve the best results if properly applied. Simple baselines help to confirm whether the results of advanced models are acceptable. Our experimental results fully support these points.
Rather a Nurse than a Physician -- Contrastive Explanations under Investigation
Oct 18, 2023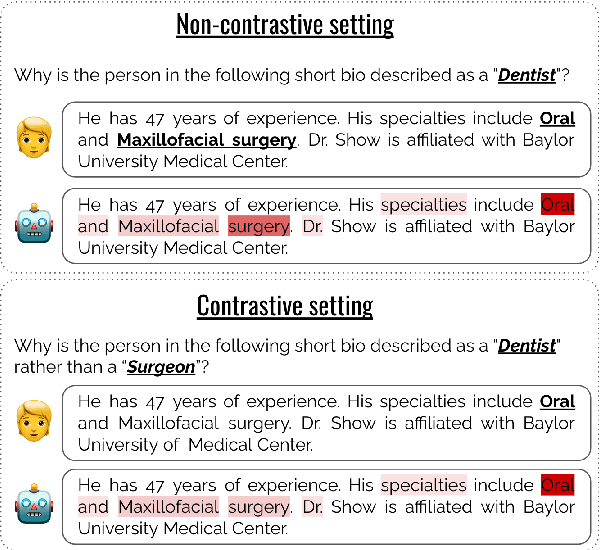


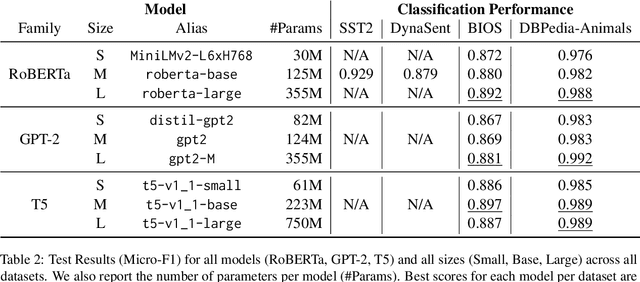
Contrastive explanations, where one decision is explained in contrast to another, are supposed to be closer to how humans explain a decision than non-contrastive explanations, where the decision is not necessarily referenced to an alternative. This claim has never been empirically validated. We analyze four English text-classification datasets (SST2, DynaSent, BIOS and DBpedia-Animals). We fine-tune and extract explanations from three different models (RoBERTa, GTP-2, and T5), each in three different sizes and apply three post-hoc explainability methods (LRP, GradientxInput, GradNorm). We furthermore collect and release human rationale annotations for a subset of 100 samples from the BIOS dataset for contrastive and non-contrastive settings. A cross-comparison between model-based rationales and human annotations, both in contrastive and non-contrastive settings, yields a high agreement between the two settings for models as well as for humans. Moreover, model-based explanations computed in both settings align equally well with human rationales. Thus, we empirically find that humans do not necessarily explain in a contrastive manner.9 pages, long paper at ACL 2022 proceedings.
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 27, 2023Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.